 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Censer: Curriculum Semi-supervised Learning for Speech Recognition Based on Self-supervised Pre-training
Jun 16, 2022
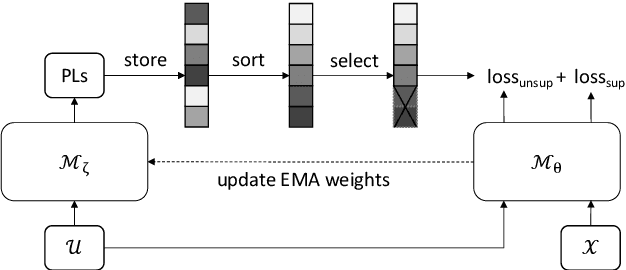

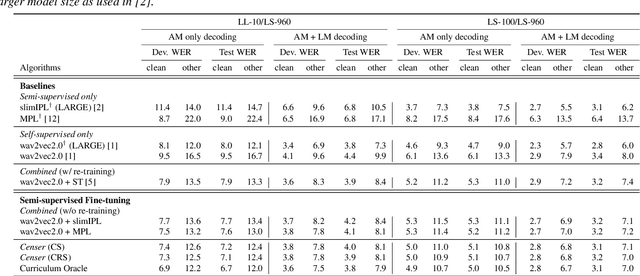
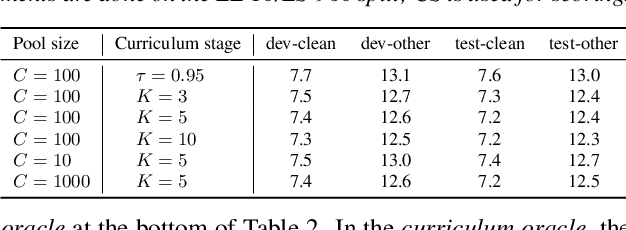
Recent studies have shown that the benefits provided by self-supervised pre-training and self-training (pseudo-labeling) are complementary. Semi-supervised fine-tuning strategies under the pre-training framework, however, remain insufficiently studied. Besides, modern semi-supervised speech recognition algorithms either treat unlabeled data indiscriminately or filter out noisy samples with a confidence threshold. The dissimilarities among different unlabeled data are often ignored. In this paper, we propose Censer, a semi-supervised speech recognition algorithm based on self-supervised pre-training to maximize the utilization of unlabeled data. The pre-training stage of Censer adopts wav2vec2.0 and the fine-tuning stage employs an improved semi-supervised learning algorithm from slimIPL, which leverages unlabeled data progressively according to their pseudo labels' qualities. We also incorporate a temporal pseudo label pool and an exponential moving average to control the pseudo labels' update frequency and to avoid model divergence. Experimental results on Libri-Light and LibriSpeech datasets manifest our proposed method achieves better performance compared to existing approaches while being more unified.
Effectiveness of text to speech pseudo labels for forced alignment and cross lingual pretrained models for low resource speech recognition
Mar 31, 2022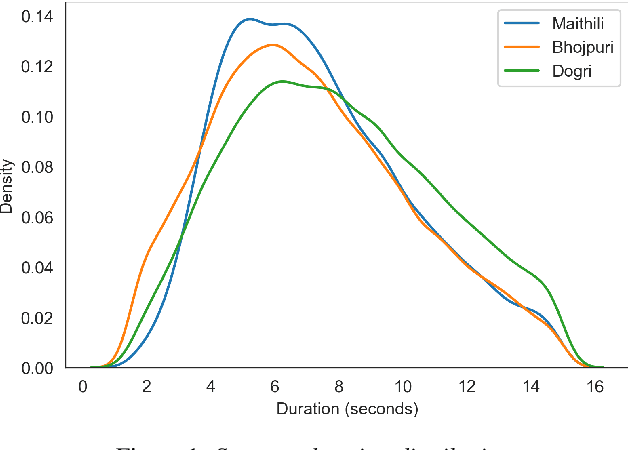
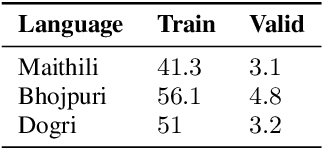
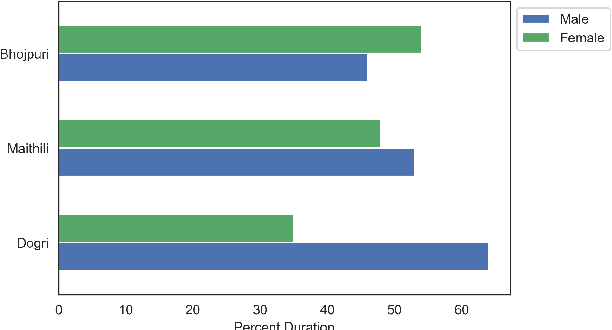
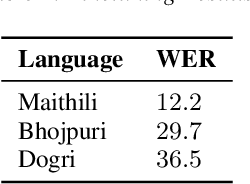
In the recent years end to end (E2E) automatic speech recognition (ASR) systems have achieved promising results given sufficient resources. Even for languages where not a lot of labelled data is available, state of the art E2E ASR systems can be developed by pretraining on huge amounts of high resource languages and finetune on low resource languages. For a lot of low resource languages the current approaches are still challenging, since in many cases labelled data is not available in open domain. In this paper we present an approach to create labelled data for Maithili, Bhojpuri and Dogri by utilising pseudo labels from text to speech for forced alignment. The created data was inspected for quality and then further used to train a transformer based wav2vec 2.0 ASR model. All data and models are available in open domain.
Blockwise Streaming Transformer for Spoken Language Understanding and Simultaneous Speech Translation
Apr 19, 2022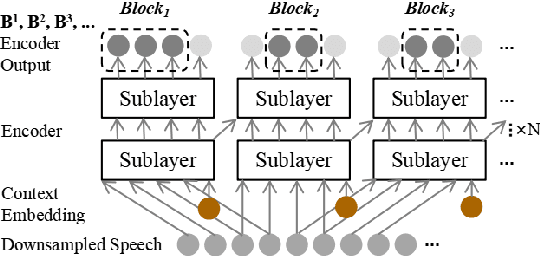
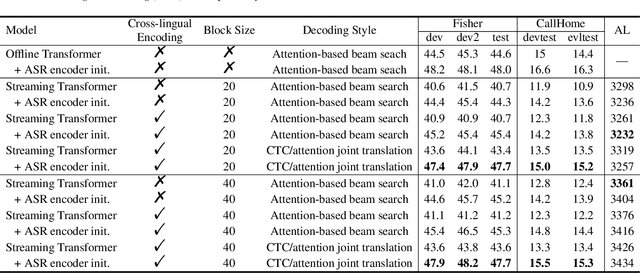
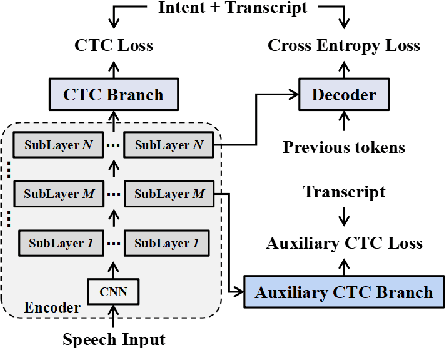
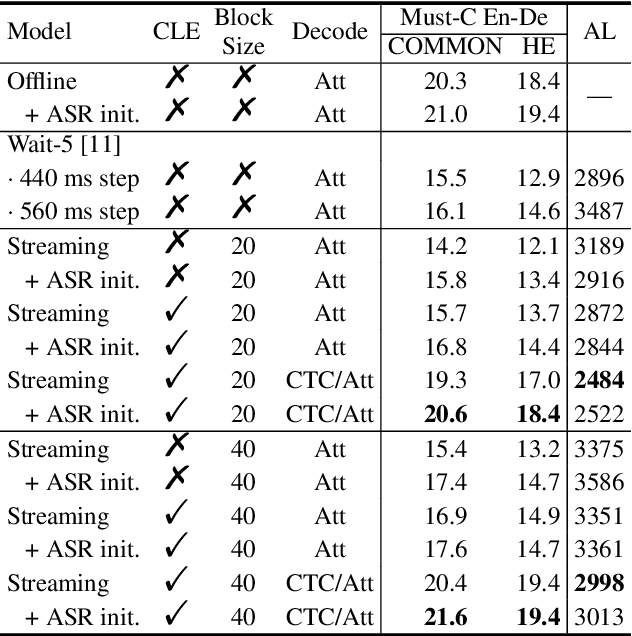
Although Transformers have gained success in several speech processing tasks like spoken language understanding (SLU) and speech translation (ST), achieving online processing while keeping competitive performance is still essential for real-world interaction. In this paper, we take the first step on streaming SLU and simultaneous ST using a blockwise streaming Transformer, which is based on contextual block processing and blockwise synchronous beam search. Furthermore, we design an automatic speech recognition (ASR)-based intermediate loss regularization for the streaming SLU task to improve the classification performance further. As for the simultaneous ST task, we propose a cross-lingual encoding method, which employs a CTC branch optimized with target language translations. In addition, the CTC translation output is also used to refine the search space with CTC prefix score, achieving joint CTC/attention simultaneous translation for the first time. Experiments for SLU are conducted on FSC and SLURP corpora, while the ST task is evaluated on Fisher-CallHome Spanish and MuST-C En-De corpora. Experimental results show that the blockwise streaming Transformer achieves competitive results compared to offline models, especially with our proposed methods that further yield a 2.4% accuracy gain on the SLU task and a 4.3 BLEU gain on the ST task over streaming baselines.
data2vec-aqc: Search for the right Teaching Assistant in the Teacher-Student training setup
Nov 02, 2022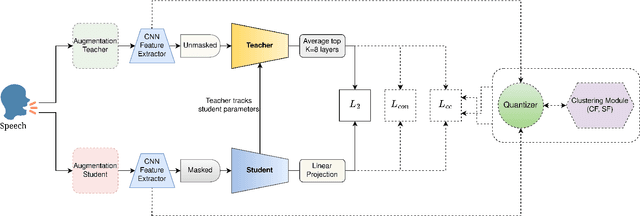
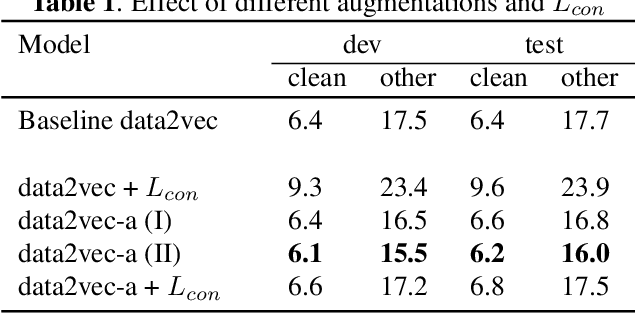
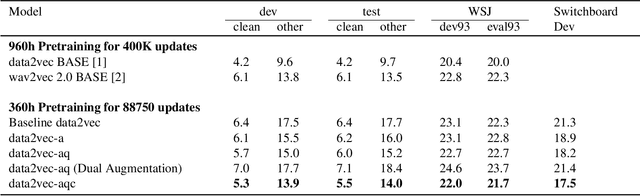
In this paper, we propose a new Self-Supervised Learning (SSL) algorithm called data2vec-aqc, for speech representation learning from unlabeled speech data. Our goal is to improve SSL for speech in domains where both unlabeled and labeled data are limited. Building on the recently introduced data2vec, we introduce additional modules to the data2vec framework that leverage the benefit of data augmentations, quantized representations, and clustering. The interaction between these modules helps solve the cross-contrastive loss as an additional self-supervised objective. data2vec-aqc achieves up to 14.1% and 20.9% relative WER improvement over the existing state-of-the-art data2vec system on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. Our proposed model also achieves up to 17.8% relative WER improvement over the baseline data2vec when fine-tuned on Switchboard data.
SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training
Oct 20, 2021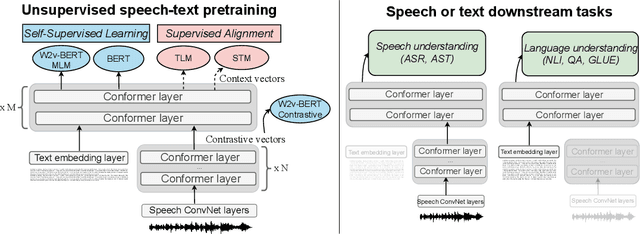
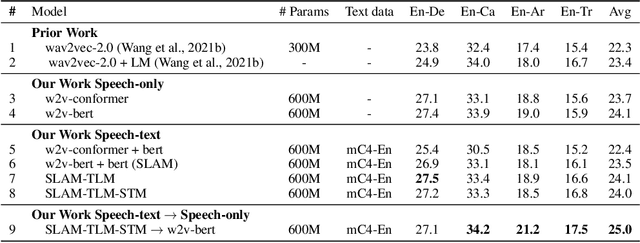
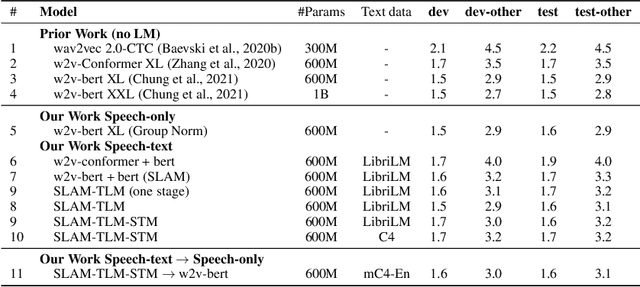
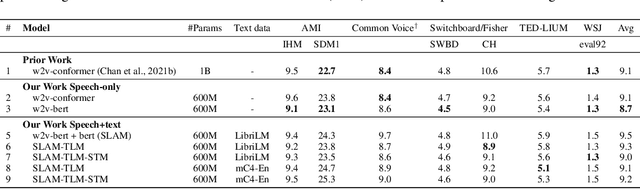
Unsupervised pre-training is now the predominant approach for both text and speech understanding. Self-attention models pre-trained on large amounts of unannotated data have been hugely successful when fine-tuned on downstream tasks from a variety of domains and languages. This paper takes the universality of unsupervised language pre-training one step further, by unifying speech and text pre-training within a single model. We build a single encoder with the BERT objective on unlabeled text together with the w2v-BERT objective on unlabeled speech. To further align our model representations across modalities, we leverage alignment losses, specifically Translation Language Modeling (TLM) and Speech Text Matching (STM) that make use of supervised speech-text recognition data. We demonstrate that incorporating both speech and text data during pre-training can significantly improve downstream quality on CoVoST~2 speech translation, by around 1 BLEU compared to single-modality pre-trained models, while retaining close to SotA performance on LibriSpeech and SpeechStew ASR tasks. On four GLUE tasks and text-normalization, we observe evidence of capacity limitations and interference between the two modalities, leading to degraded performance compared to an equivalent text-only model, while still being competitive with BERT. Through extensive empirical analysis we also demonstrate the importance of the choice of objective function for speech pre-training, and the beneficial effect of adding additional supervised signals on the quality of the learned representations.
Self-critical Sequence Training for Automatic Speech Recognition
Apr 13, 2022
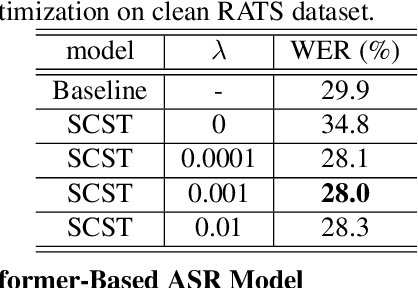
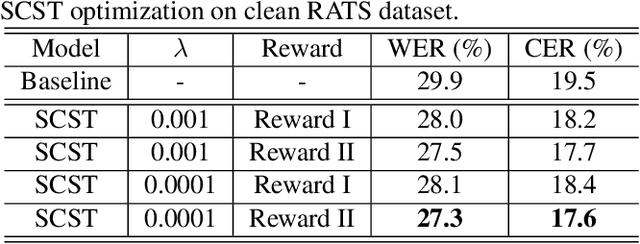
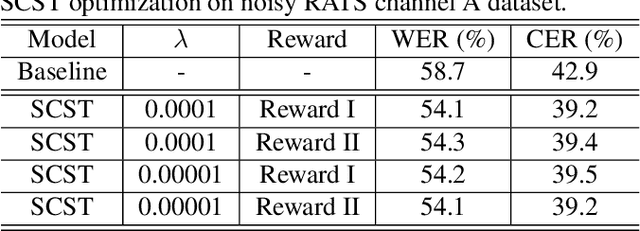
Although automatic speech recognition (ASR) task has gained remarkable success by sequence-to-sequence models, there are two main mismatches between its training and testing that might lead to performance degradation: 1) The typically used cross-entropy criterion aims to maximize log-likelihood of the training data, while the performance is evaluated by word error rate (WER), not log-likelihood; 2) The teacher-forcing method leads to the dependence on ground truth during training, which means that model has never been exposed to its own prediction before testing. In this paper, we propose an optimization method called self-critical sequence training (SCST) to make the training procedure much closer to the testing phase. As a reinforcement learning (RL) based method, SCST utilizes a customized reward function to associate the training criterion and WER. Furthermore, it removes the reliance on teacher-forcing and harmonizes the model with respect to its inference procedure. We conducted experiments on both clean and noisy speech datasets, and the results show that the proposed SCST respectively achieves 8.7% and 7.8% relative improvements over the baseline in terms of WER.
Pushing the performances of ASR models on English and Spanish accents
Dec 22, 2022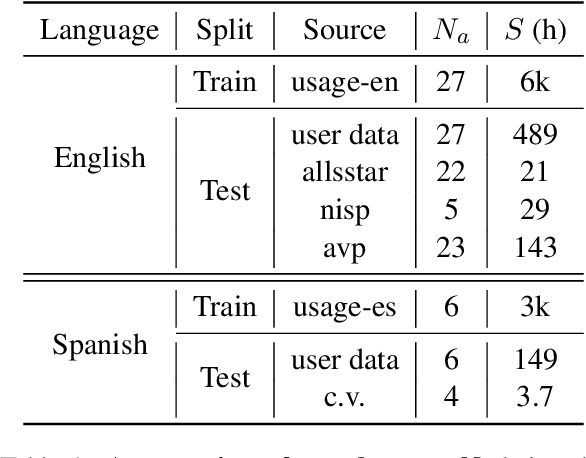
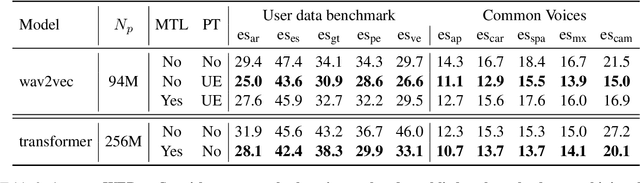
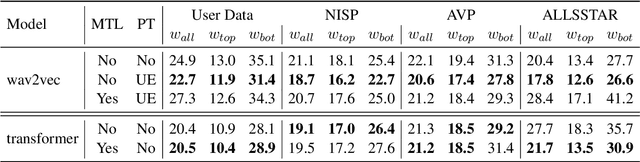
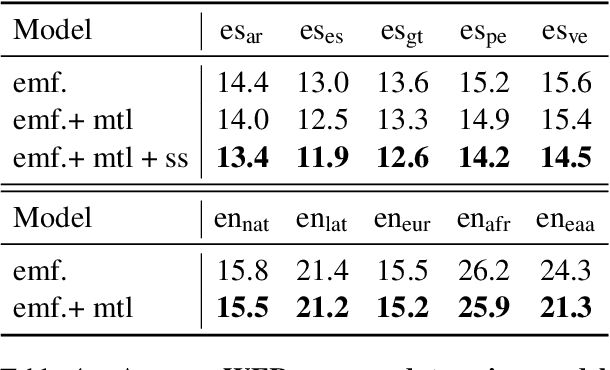
Speech to text models tend to be trained and evaluated against a single target accent. This is especially true for English for which native speakers from the United States became the main benchmark. In this work, we are going to show how two simple methods: pre-trained embeddings and auxiliary classification losses can improve the performance of ASR systems. We are looking for upgrades as universal as possible and therefore we will explore their impact on several models architectures and several languages.
Everything is Connected: Graph Neural Networks
Jan 19, 2023In many ways, graphs are the main modality of data we receive from nature. This is due to the fact that most of the patterns we see, both in natural and artificial systems, are elegantly representable using the language of graph structures. Prominent examples include molecules (represented as graphs of atoms and bonds), social networks and transportation networks. This potential has already been seen by key scientific and industrial groups, with already-impacted application areas including traffic forecasting, drug discovery, social network analysis and recommender systems. Further, some of the most successful domains of application for machine learning in previous years -- images, text and speech processing -- can be seen as special cases of graph representation learning, and consequently there has been significant exchange of information between these areas. The main aim of this short survey is to enable the reader to assimilate the key concepts in the area, and position graph representation learning in a proper context with related fields.
Equivariant and Steerable Neural Networks: A review with special emphasis on the symmetric group
Jan 08, 2023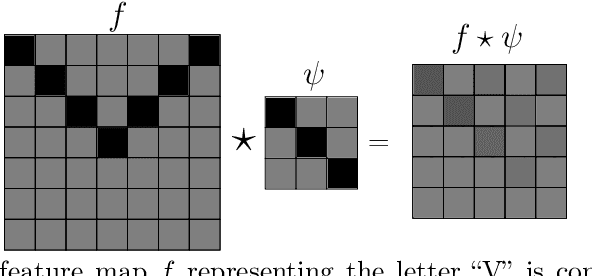

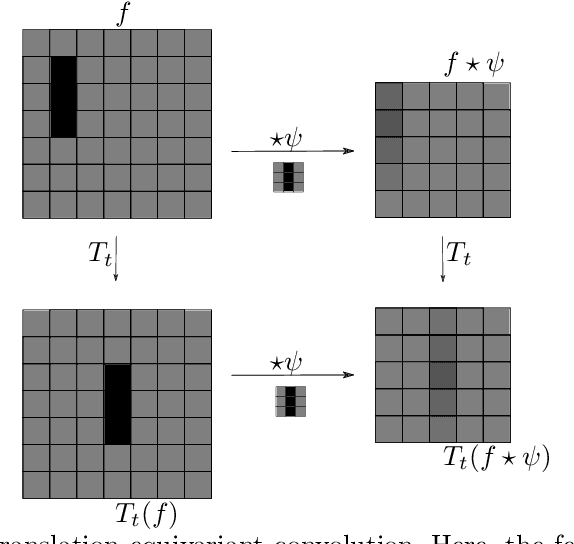

Convolutional neural networks revolutionized computer vision and natrual language processing. Their efficiency, as compared to fully connected neural networks, has its origin in the architecture, where convolutions reflect the translation invariance in space and time in pattern or speech recognition tasks. Recently, Cohen and Welling have put this in the broader perspective of invariance under symmetry groups, which leads to the concept of group equivaiant neural networks and more generally steerable neural networks. In this article, we review the architecture of such networks including equivariant layers and filter banks, activation with capsules and group pooling. We apply this formalism to the symmetric group, for which we work out a number of details on representations and capsules that are not found in the literature.
MDNet: Learning Monaural Speech Enhancement from Deep Prior Gradient
Mar 16, 2022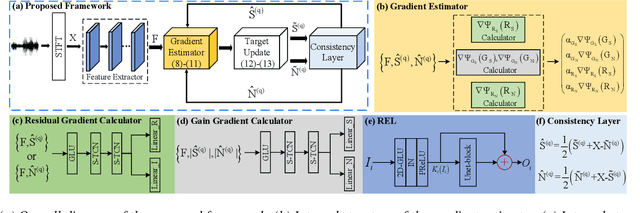
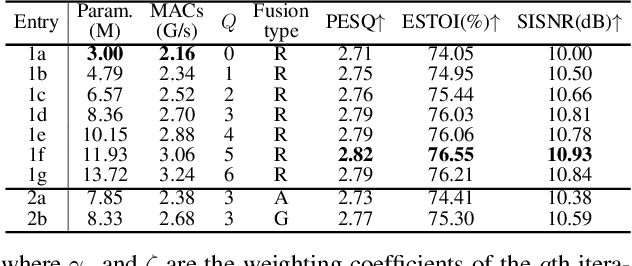
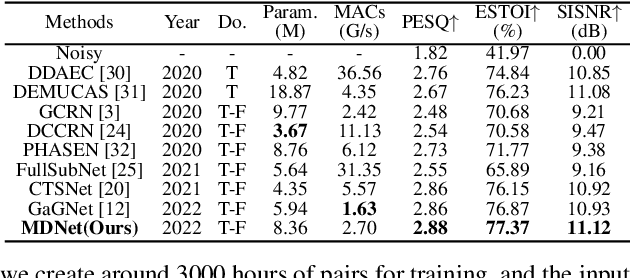
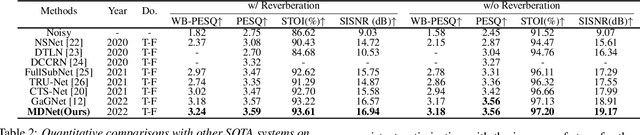
While traditional statistical signal processing model-based methods can derive the optimal estimators relying on specific statistical assumptions, current learning-based methods further promote the performance upper bound via deep neural networks but at the expense of high encapsulation and lack adequate interpretability. Standing upon the intersection between traditional model-based methods and learning-based methods, we propose a model-driven approach based on the maximum a posteriori (MAP) framework, termed as MDNet, for single-channel speech enhancement. Specifically, the original problem is formulated into the joint posterior estimation w.r.t. speech and noise components. Different from the manual assumption toward the prior terms, we propose to model the prior distribution via networks and thus can learn from training data. The framework takes the unfolding structure and in each step, the target parameters can be progressively estimated through explicit gradient descent operations. Besides, another network serves as the fusion module to further refine the previous speech estimation. The experiments are conducted on the WSJ0-SI84 and Interspeech2020 DNS-Challenge datasets, and quantitative results show that the proposed approach outshines previous state-of-the-art baselines.