 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of text to speech pseudo labels for forced alignment and cross lingual pretrained models for low resource speech recognition
Paper and Code
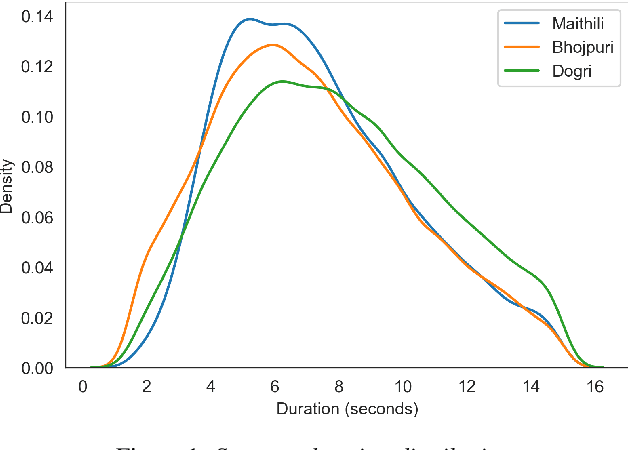
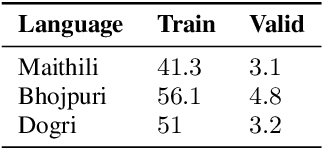
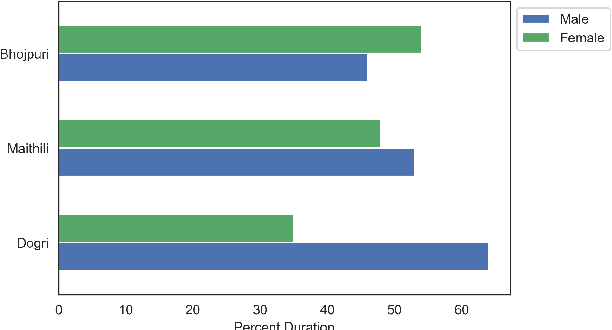
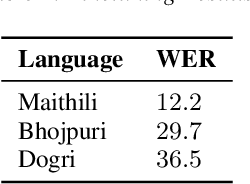
In the recent years end to end (E2E) automatic speech recognition (ASR) systems have achieved promising results given sufficient resources. Even for languages where not a lot of labelled data is available, state of the art E2E ASR systems can be developed by pretraining on huge amounts of high resource languages and finetune on low resource languages. For a lot of low resource languages the current approaches are still challenging, since in many cases labelled data is not available in open domain. In this paper we present an approach to create labelled data for Maithili, Bhojpuri and Dogri by utilising pseudo labels from text to speech for forced alignment. The created data was inspected for quality and then further used to train a transformer based wav2vec 2.0 ASR model. All data and models are available in open domain.