 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Direction-Aware Joint Adaptation of Neural Speech Enhancement and Recognition in Real Multiparty Conversational Environments
Jul 15, 2022
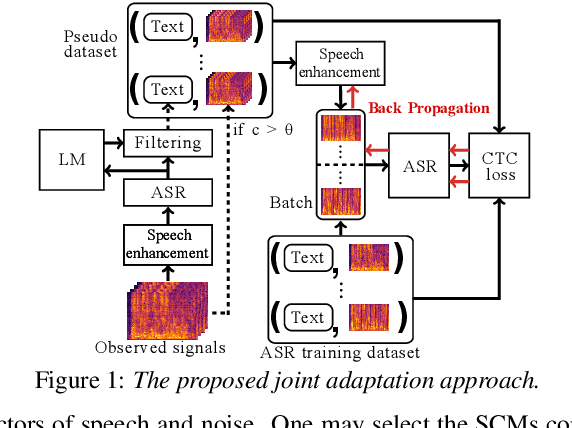
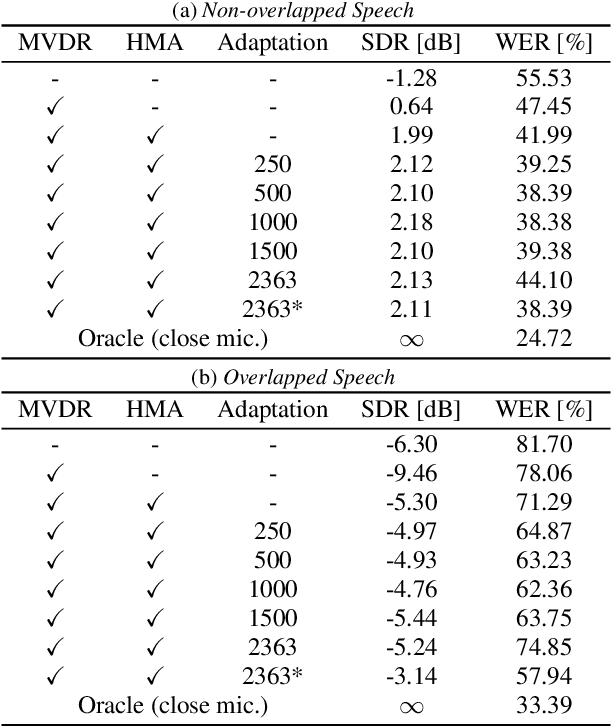
This paper describes noisy speech recognition for an augmented reality headset that helps verbal communication within real multiparty conversational environments. A major approach that has actively been studied in simulated environments is to sequentially perform speech enhancement and automatic speech recognition (ASR) based on deep neural networks (DNNs) trained in a supervised manner. In our task, however, such a pretrained system fails to work due to the mismatch between the training and test conditions and the head movements of the user. To enhance only the utterances of a target speaker, we use beamforming based on a DNN-based speech mask estimator that can adaptively extract the speech components corresponding to a head-relative particular direction. We propose a semi-supervised adaptation method that jointly updates the mask estimator and the ASR model at run-time using clean speech signals with ground-truth transcriptions and noisy speech signals with highly-confident estimated transcriptions. Comparative experiments using the state-of-the-art distant speech recognition system show that the proposed method significantly improves the ASR performance.
Text-To-Speech Data Augmentation for Low Resource Speech Recognition
Apr 01, 2022
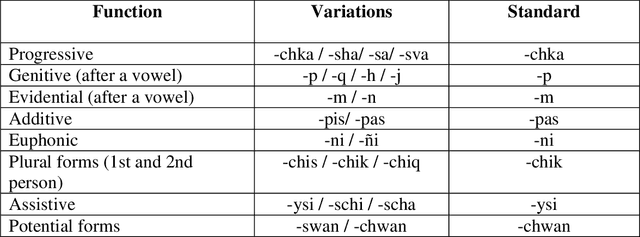
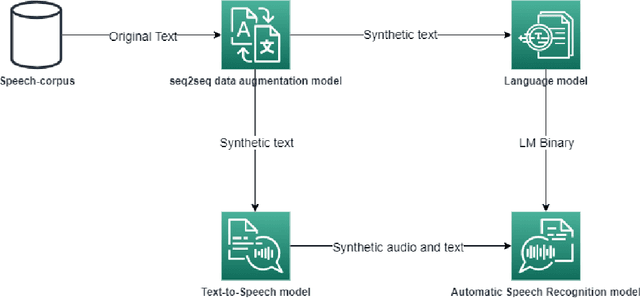
Nowadays, the main problem of deep learning techniques used in the development of automatic speech recognition (ASR) models is the lack of transcribed data. The goal of this research is to propose a new data augmentation method to improve ASR models for agglutinative and low-resource languages. This novel data augmentation method generates both synthetic text and synthetic audio. Some experiments were conducted using the corpus of the Quechua language, which is an agglutinative and low-resource language. In this study, a sequence-to-sequence (seq2seq) model was applied to generate synthetic text, in addition to generating synthetic speech using a text-to-speech (TTS) model for Quechua. The results show that the new data augmentation method works well to improve the ASR model for Quechua. In this research, an 8.73% improvement in the word-error-rate (WER) of the ASR model is obtained using a combination of synthetic text and synthetic speech.
UniCT DMI Solution for 3rd COV19D Competition on COVID-19 Detection through attention-based CNN for CT Scan
Mar 22, 2023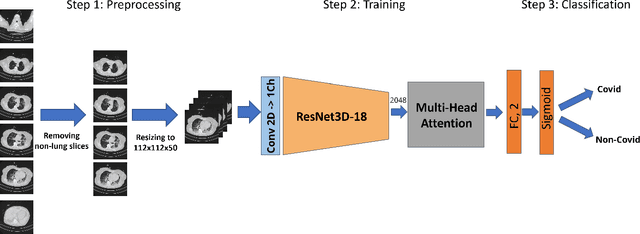
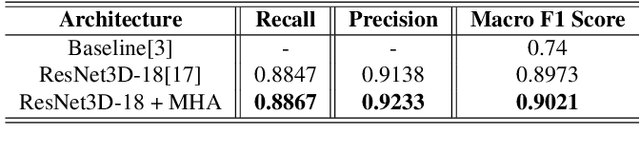
This paper presents our solution for the first challenge of the 3rd Covid-19 competition, which is part of the "AI-enabled Medical Image Analysis Workshop" organized by IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) 2023. Our proposed solution is based on a Resnet as a backbone network with the addition of attention mechanisms. The Resnet provides an effective feature extractor for the classification task, while the attention mechanisms improve the model's ability to focus on important regions of interest within the images. We conducted extensive experiments on the provided dataset and achieved promising results. Our proposed approach has the potential to assist in the accurate diagnosis of Covid-19 from chest computed tomography images, which can aid in the early detection and management of the disease.
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
Mar 11, 2023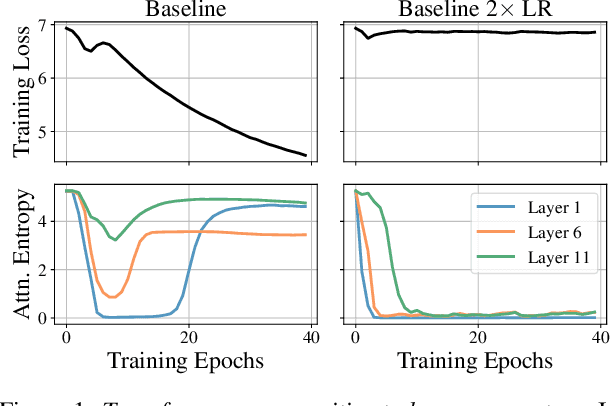
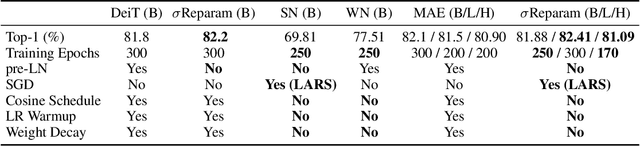
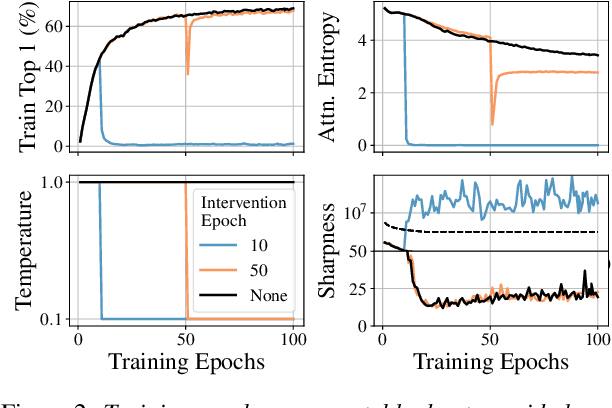
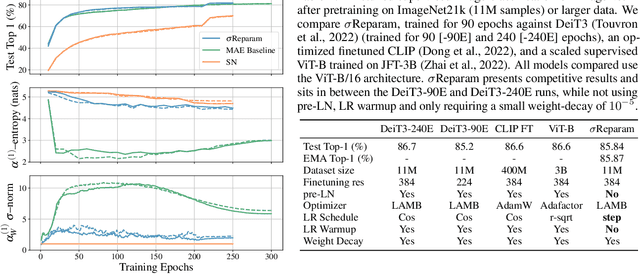
Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is accompanied by high training instability, which can take the form of oscillating loss or divergence. We denote the pathologically low attention entropy, corresponding to highly concentrated attention scores, as $\textit{entropy collapse}$. As a remedy, we propose $\sigma$Reparam, a simple and efficient solution where we reparametrize all linear layers with spectral normalization and an additional learned scalar. We demonstrate that the proposed reparameterization successfully prevents entropy collapse in the attention layers, promoting more stable training. Additionally, we prove a tight lower bound of the attention entropy, which decreases exponentially fast with the spectral norm of the attention logits, providing additional motivation for our approach. We conduct experiments with $\sigma$Reparam on image classification, image self-supervised learning, machine translation, automatic speech recognition, and language modeling tasks, across Transformer architectures. We show that $\sigma$Reparam provides stability and robustness with respect to the choice of hyperparameters, going so far as enabling training (a) a Vision Transformer to competitive performance without warmup, weight decay, layer normalization or adaptive optimizers; (b) deep architectures in machine translation and (c) speech recognition to competitive performance without warmup and adaptive optimizers.
Indian Sign Language Recognition Using Mediapipe Holistic
Apr 20, 2023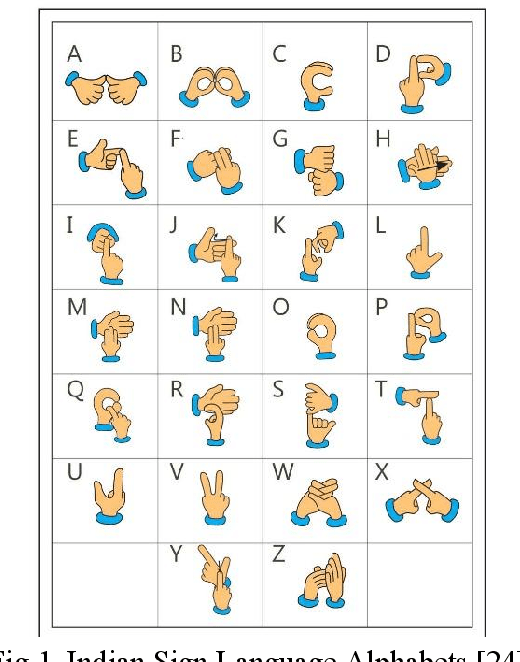


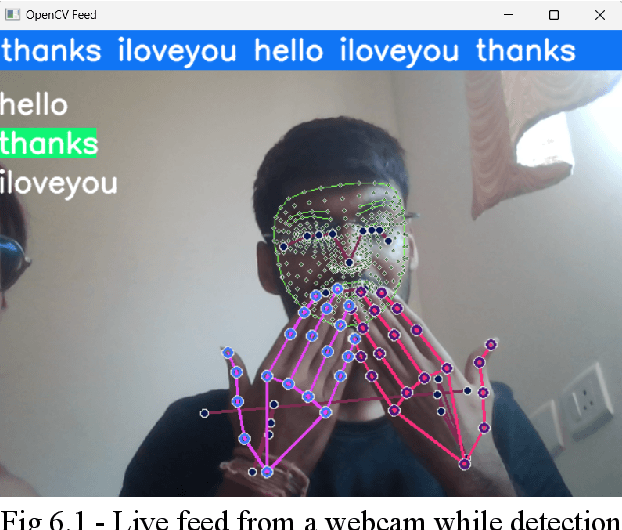
Deaf individuals confront significant communication obstacles on a daily basis. Their inability to hear makes it difficult for them to communicate with those who do not understand sign language. Moreover, it presents difficulties in educational, occupational, and social contexts. By providing alternative communication channels, technology can play a crucial role in overcoming these obstacles. One such technology that can facilitate communication between deaf and hearing individuals is sign language recognition. We will create a robust system for sign language recognition in order to convert Indian Sign Language to text or speech. We will evaluate the proposed system and compare CNN and LSTM models. Since there are both static and gesture sign languages, a robust model is required to distinguish between them. In this study, we discovered that a CNN model captures letters and characters for recognition of static sign language better than an LSTM model, but it outperforms CNN by monitoring hands, faces, and pose in gesture sign language phrases and sentences. The creation of a text-to-sign language paradigm is essential since it will enhance the sign language-dependent deaf and hard-of-hearing population's communication skills. Even though the sign-to-text translation is just one side of communication, not all deaf or hard-of-hearing people are proficient in reading or writing text. Some may have difficulty comprehending written language due to educational or literacy issues. Therefore, a text-to-sign language paradigm would allow them to comprehend text-based information and participate in a variety of social, educational, and professional settings. Keywords: deaf and hard-of-hearing, DHH, Indian sign language, CNN, LSTM, static and gesture sign languages, text-to-sign language model, MediaPipe Holistic, sign language recognition, SLR, SLT
SEM-POS: Grammatically and Semantically Correct Video Captioning
Apr 04, 2023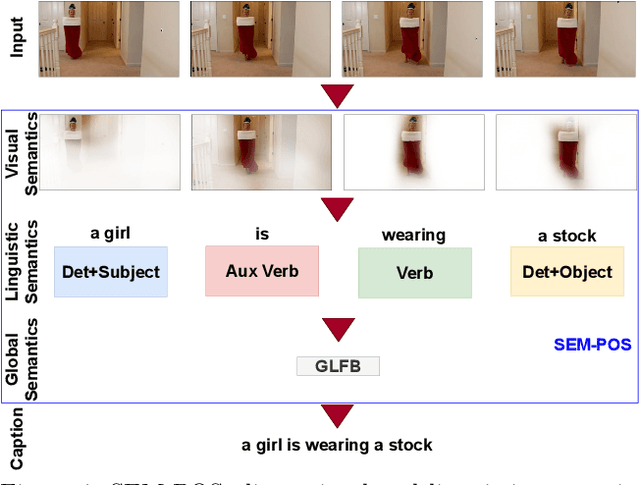
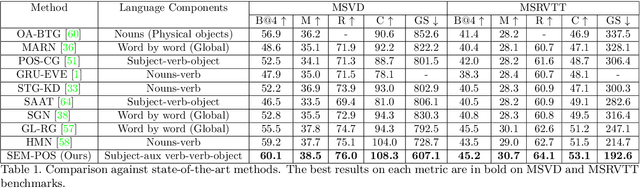
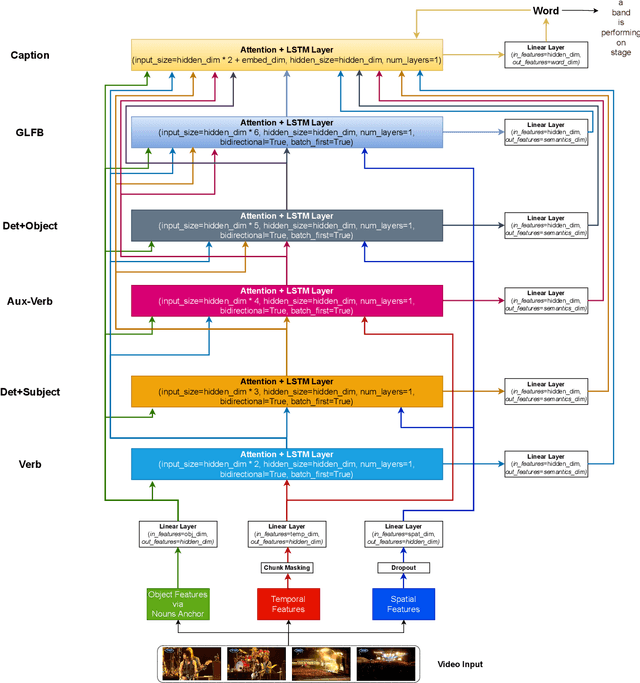
Generating grammatically and semantically correct captions in video captioning is a challenging task. The captions generated from the existing methods are either word-by-word that do not align with grammatical structure or miss key information from the input videos. To address these issues, we introduce a novel global-local fusion network, with a Global-Local Fusion Block (GLFB) that encodes and fuses features from different parts of speech (POS) components with visual-spatial features. We use novel combinations of different POS components - 'determinant + subject', 'auxiliary verb', 'verb', and 'determinant + object' for supervision of the POS blocks - Det + Subject, Aux Verb, Verb, and Det + Object respectively. The novel global-local fusion network together with POS blocks helps align the visual features with language description to generate grammatically and semantically correct captions. Extensive qualitative and quantitative experiments on benchmark MSVD and MSRVTT datasets demonstrate that the proposed approach generates more grammatically and semantically correct captions compared to the existing methods, achieving the new state-of-the-art. Ablations on the POS blocks and the GLFB demonstrate the impact of the contributions on the proposed method.
Residual Adapters for Few-Shot Text-to-Speech Speaker Adaptation
Oct 28, 2022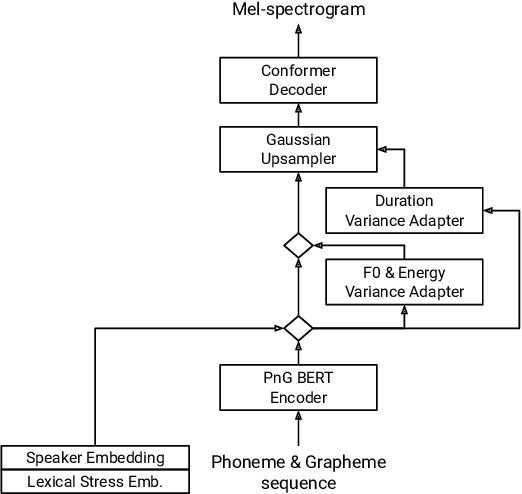

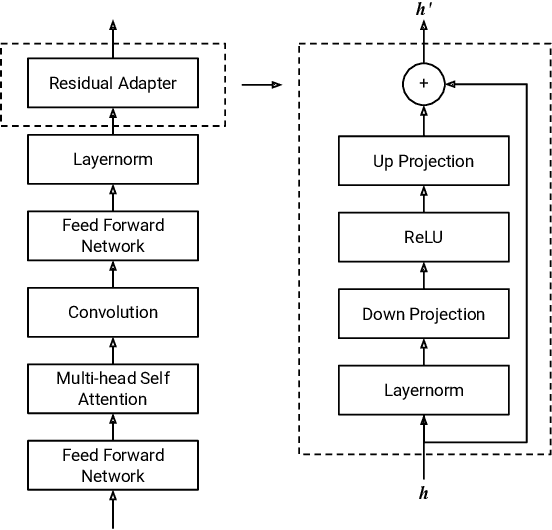
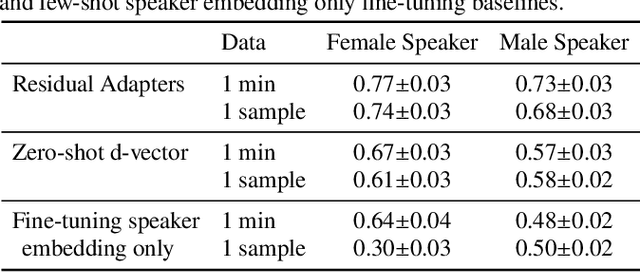
Adapting a neural text-to-speech (TTS) model to a target speaker typically involves fine-tuning most if not all of the parameters of a pretrained multi-speaker backbone model. However, serving hundreds of fine-tuned neural TTS models is expensive as each of them requires significant footprint and separate computational resources (e.g., accelerators, memory). To scale speaker adapted neural TTS voices to hundreds of speakers while preserving the naturalness and speaker similarity, this paper proposes a parameter-efficient few-shot speaker adaptation, where the backbone model is augmented with trainable lightweight modules called residual adapters. This architecture allows the backbone model to be shared across different target speakers. Experimental results show that the proposed approach can achieve competitive naturalness and speaker similarity compared to the full fine-tuning approaches, while requiring only $\sim$0.1% of the backbone model parameters for each speaker.
ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild
Oct 05, 2022
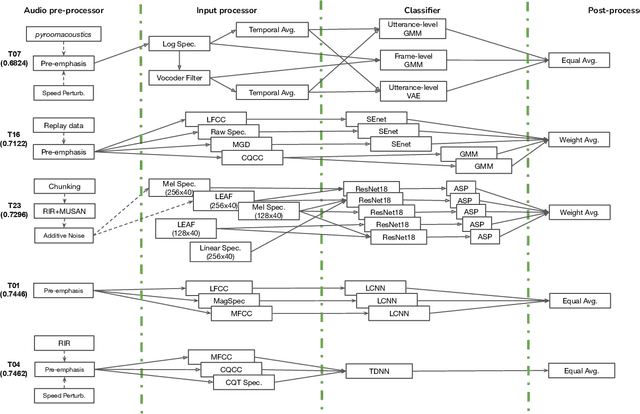
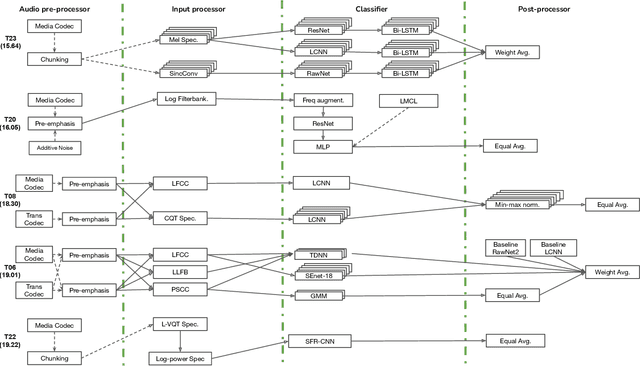
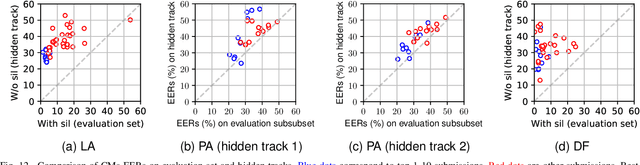
Benchmarking initiatives support the meaningful comparison of competing solutions to prominent problems in speech and language processing. Successive benchmarking evaluations typically reflect a progressive evolution from ideal lab conditions towards to those encountered in the wild. ASVspoof, the spoofing and deepfake detection initiative and challenge series, has followed the same trend. This article provides a summary of the ASVspoof 2021 challenge and the results of 37 participating teams. For the logical access task, results indicate that countermeasures solutions are robust to newly introduced encoding and transmission effects. Results for the physical access task indicate the potential to detect replay attacks in real, as opposed to simulated physical spaces, but a lack of robustness to variations between simulated and real acoustic environments. The DF task, new to the 2021 edition, targets solutions to the detection of manipulated, compressed speech data posted online. While detection solutions offer some resilience to compression effects, they lack generalization across different source datasets. In addition to a summary of the top-performing systems for each task, new analyses of influential data factors and results for hidden data subsets, the article includes a review of post-challenge results, an outline of the principal challenge limitations and a road-map for the future of ASVspoof. Link to the ASVspoof challenge and related resources: https://www.asvspoof.org/index2021.html
SoftCorrect: Error Correction with Soft Detection for Automatic Speech Recognition
Dec 02, 2022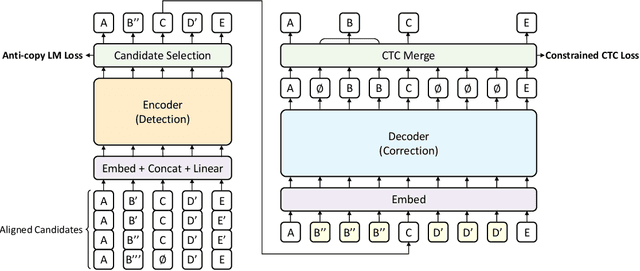
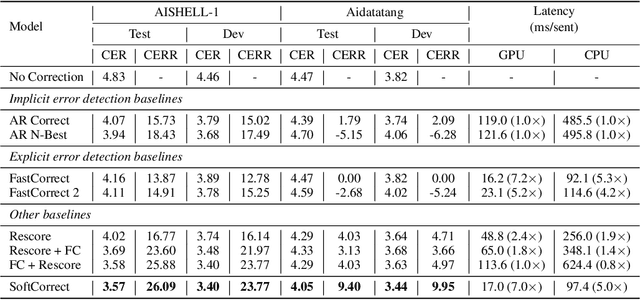
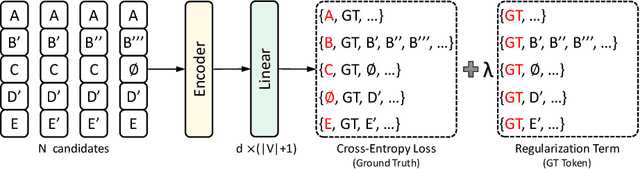
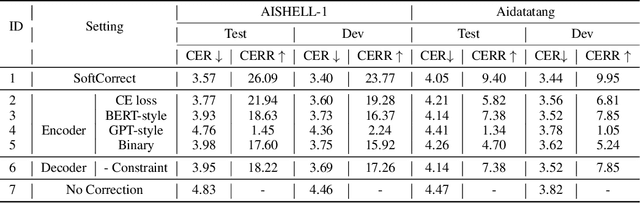
Error correction in automatic speech recognition (ASR) aims to correct those incorrect words in sentences generated by ASR models. Since recent ASR models usually have low word error rate (WER), to avoid affecting originally correct tokens, error correction models should only modify incorrect words, and therefore detecting incorrect words is important for error correction. Previous works on error correction either implicitly detect error words through target-source attention or CTC (connectionist temporal classification) loss, or explicitly locate specific deletion/substitution/insertion errors. However, implicit error detection does not provide clear signal about which tokens are incorrect and explicit error detection suffers from low detection accuracy. In this paper, we propose SoftCorrect with a soft error detection mechanism to avoid the limitations of both explicit and implicit error detection. Specifically, we first detect whether a token is correct or not through a probability produced by a dedicatedly designed language model, and then design a constrained CTC loss that only duplicates the detected incorrect tokens to let the decoder focus on the correction of error tokens. Compared with implicit error detection with CTC loss, SoftCorrect provides explicit signal about which words are incorrect and thus does not need to duplicate every token but only incorrect tokens; compared with explicit error detection, SoftCorrect does not detect specific deletion/substitution/insertion errors but just leaves it to CTC loss. Experiments on AISHELL-1 and Aidatatang datasets show that SoftCorrect achieves 26.1% and 9.4% CER reduction respectively, outperforming previous works by a large margin, while still enjoying fast speed of parallel generation.
Supervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022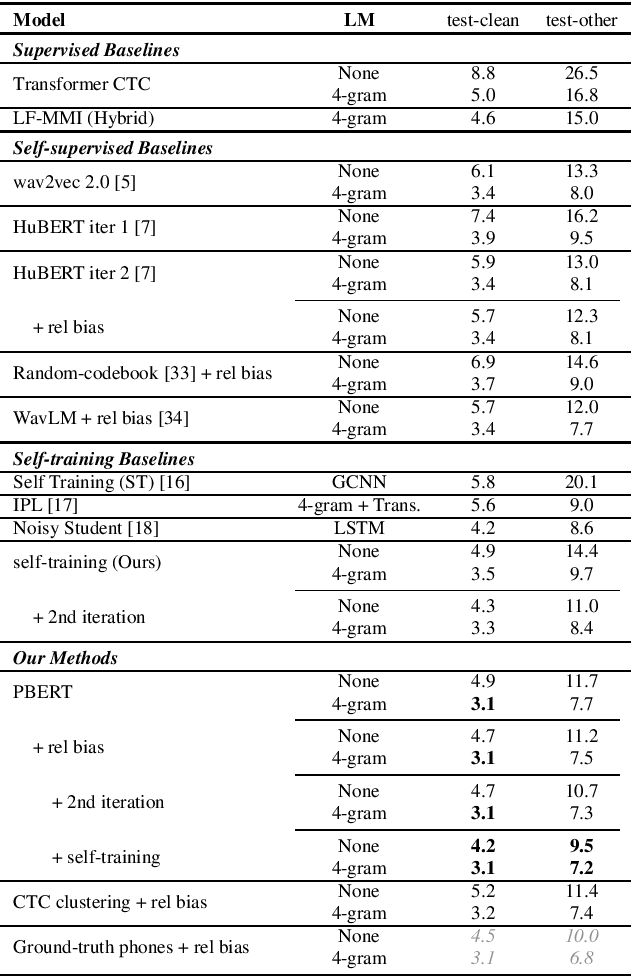
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.