 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiving Voice to the Constitution: Low-Resource Text-to-Speech for Quechua and Spanish Using a Bilingual Legal Corpus
Apr 14, 2026We present a unified pipeline for synthesizing high-quality Quechua and Spanish speech for the Peruvian Constitution using three state-of-the-art text-to-speech (TTS) architectures: XTTS v2, F5-TTS, and DiFlow-TTS. Our models are trained on independent Spanish and Quechua speech datasets with heterogeneous sizes and recording conditions, and leverage bilingual and multilingual TTS capabilities to improve synthesis quality in both languages. By exploiting cross-lingual transfer, our framework mitigates data scarcity in Quechua while preserving naturalness in Spanish. We release trained checkpoints, inference code, and synthesized audio for each constitutional article, providing a reusable resource for speech technologies in indigenous and multilingual contexts. This work contributes to the development of inclusive TTS systems for political and legal content in low-resource settings.
How Attention Shapes Emotion: A Comparative Study of Attention Mechanisms for Speech Emotion Recognition
Mar 16, 2026Speech Emotion Recognition (SER) plays a key role in advancing human-computer interaction. Attention mechanisms have become the dominant approach for modeling emotional speech due to their ability to capture long-range dependencies and emphasize salient information. However, standard self-attention suffers from quadratic computational and memory complexity, limiting its scalability. In this work, we present a systematic benchmark of optimized attention mechanisms for SER, including RetNet, LightNet, GSA, FoX, and KDA. Experiments on both MSP-Podcast benchmark versions show that while standard self-attention achieves the strongest recognition performance across test sets, efficient attention variants dramatically improve scalability, reducing inference latency and memory usage by up to an order of magnitude. These results highlight a critical trade-off between accuracy and efficiency, providing practical insights for designing scalable SER systems.
Zero-Shot TTS With Enhanced Audio Prompts: Bsc Submission For The 2026 Wildspoof Challenge TTS Track
Feb 05, 2026We evaluate two non-autoregressive architectures, StyleTTS2 and F5-TTS, to address the spontaneous nature of in-the-wild speech. Our models utilize flexible duration modeling to improve prosodic naturalness. To handle acoustic noise, we implement a multi-stage enhancement pipeline using the Sidon model, which significantly outperforms standard Demucs in signal quality. Experimental results show that finetuning enhanced audios yields superior robustness, achieving up to 4.21 UTMOS and 3.47 DNSMOS. Furthermore, we analyze the impact of reference prompt quality and length on zero-shot synthesis performance, demonstrating the effectiveness of our approach for realistic speech generation.
The First Multilingual Model For The Detection of Suicide Texts
Dec 20, 2024



Suicidal ideation is a serious health problem affecting millions of people worldwide. Social networks provide information about these mental health problems through users' emotional expressions. We propose a multilingual model leveraging transformer architectures like mBERT, XML-R, and mT5 to detect suicidal text across posts in six languages - Spanish, English, German, Catalan, Portuguese and Italian. A Spanish suicide ideation tweet dataset was translated into five other languages using SeamlessM4T. Each model was fine-tuned on this multilingual data and evaluated across classification metrics. Results showed mT5 achieving the best performance overall with F1 scores above 85%, highlighting capabilities for cross-lingual transfer learning. The English and Spanish translations also displayed high quality based on perplexity. Our exploration underscores the importance of considering linguistic diversity in developing automated multilingual tools to identify suicidal risk. Limitations exist around semantic fidelity in translations and ethical implications which provide guidance for future human-in-the-loop evaluations.
The Role of Handling Attributive Nouns in Improving Chinese-To-English Machine Translation
Dec 18, 2024Translating between languages with drastically different grammatical conventions poses challenges, not just for human interpreters but also for machine translation systems. In this work, we specifically target the translation challenges posed by attributive nouns in Chinese, which frequently cause ambiguities in English translation. By manually inserting the omitted particle X ('DE'). In news article titles from the Penn Chinese Discourse Treebank, we developed a targeted dataset to fine-tune Hugging Face Chinese to English translation models, specifically improving how this critical function word is handled. This focused approach not only complements the broader strategies suggested by previous studies but also offers a practical enhancement by specifically addressing a common error type in Chinese-English translation.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Evaluating Self-Supervised Speech Representations for Indigenous American Languages
Oct 08, 2023

The application of self-supervision to speech representation learning has garnered significant interest in recent years, due to its scalability to large amounts of unlabeled data. However, much progress, both in terms of pre-training and downstream evaluation, has remained concentrated in monolingual models that only consider English. Few models consider other languages, and even fewer consider indigenous ones. In our submission to the New Language Track of the ASRU 2023 ML-SUPERB Challenge, we present an ASR corpus for Quechua, an indigenous South American Language. We benchmark the efficacy of large SSL models on Quechua, along with 6 other indigenous languages such as Guarani and Bribri, on low-resource ASR. Our results show surprisingly strong performance by state-of-the-art SSL models, showing the potential generalizability of large-scale models to real-world data.
Data Augmentation for Low-Resource Quechua ASR Improvement
Jul 14, 2022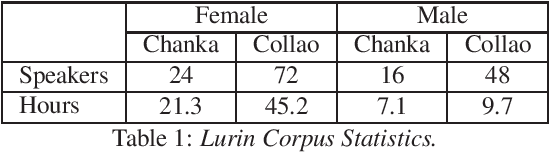
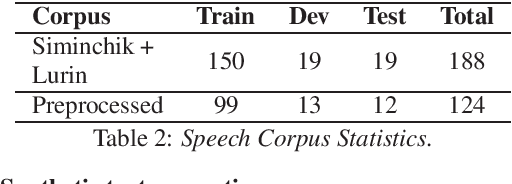
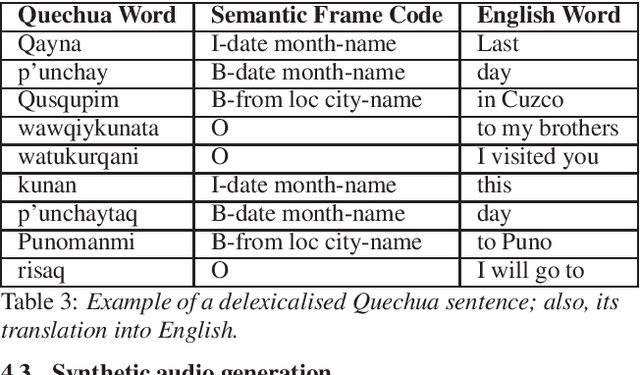
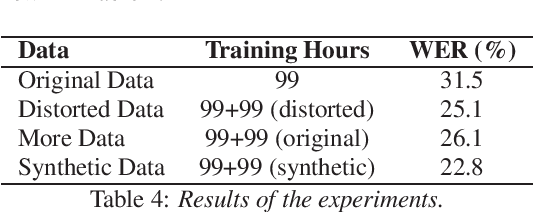
Automatic Speech Recognition (ASR) is a key element in new services that helps users to interact with an automated system. Deep learning methods have made it possible to deploy systems with word error rates below 5% for ASR of English. However, the use of these methods is only available for languages with hundreds or thousands of hours of audio and their corresponding transcriptions. For the so-called low-resource languages to speed up the availability of resources that can improve the performance of their ASR systems, methods of creating new resources on the basis of existing ones are being investigated. In this paper we describe our data augmentation approach to improve the results of ASR models for low-resource and agglutinative languages. We carry out experiments developing an ASR for Quechua using the wav2letter++ model. We reduced WER by 8.73% through our approach to the base model. The resulting ASR model obtained 22.75% WER and was trained with 99 hours of original resources and 99 hours of synthetic data obtained with a combination of text augmentation and synthetic speech generati
Huqariq: A Multilingual Speech Corpus of Native Languages of Peru for Speech Recognition
Jul 12, 2022
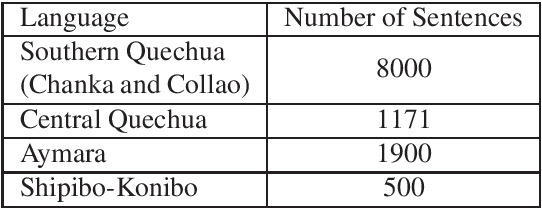
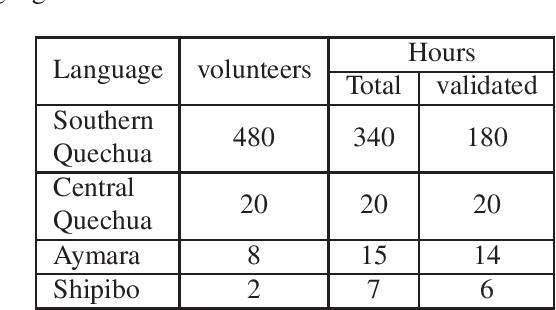
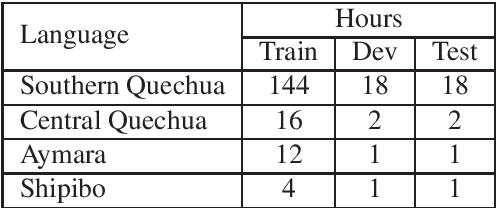
The Huqariq corpus is a multilingual collection of speech from native Peruvian languages. The transcribed corpus is intended for the research and development of speech technologies to preserve endangered languages in Peru. Huqariq is primarily designed for the development of automatic speech recognition, language identification and text-to-speech tools. In order to achieve corpus collection sustainably, we employ the crowdsourcing methodology. Huqariq includes four native languages of Peru, and it is expected that by the end of the year 2022, it can reach up to 20 native languages out of the 48 native languages in Peru. The corpus has 220 hours of transcribed audio recorded by more than 500 volunteers, making it the largest speech corpus for native languages in Peru. In order to verify the quality of the corpus, we present speech recognition experiments using 220 hours of fully transcribed audio.
Preparing an Endangered Language for the Digital Age: The Case of Judeo-Spanish
May 31, 2022

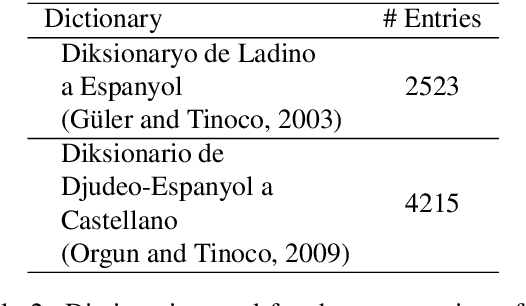

We develop machine translation and speech synthesis systems to complement the efforts of revitalizing Judeo-Spanish, the exiled language of Sephardic Jews, which survived for centuries, but now faces the threat of extinction in the digital age. Building on resources created by the Sephardic community of Turkey and elsewhere, we create corpora and tools that would help preserve this language for future generations. For machine translation, we first develop a Spanish to Judeo-Spanish rule-based machine translation system, in order to generate large volumes of synthetic parallel data in the relevant language pairs: Turkish, English and Spanish. Then, we train baseline neural machine translation engines using this synthetic data and authentic parallel data created from translations by the Sephardic community. For text-to-speech synthesis, we present a 3.5 hour single speaker speech corpus for building a neural speech synthesis engine. Resources, model weights and online inference engines are shared publicly.