 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023
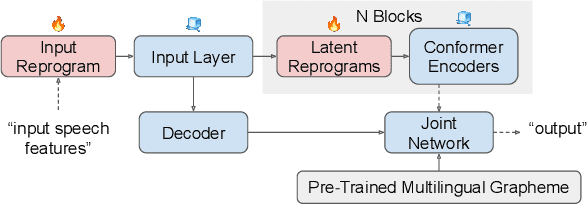

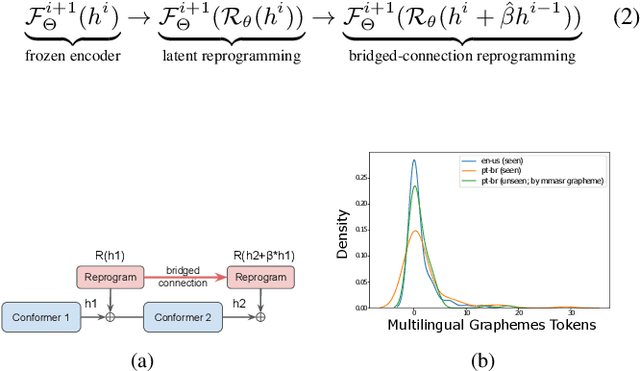
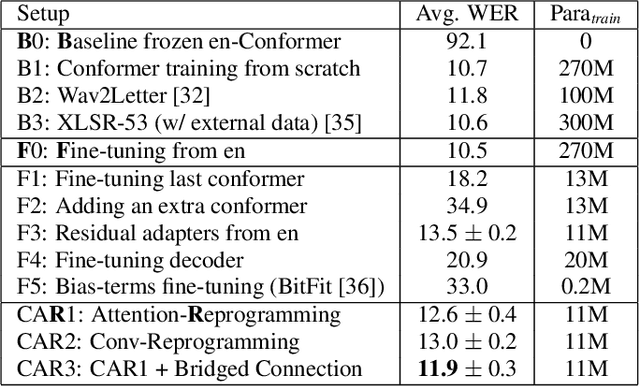
In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
DCCRN-KWS: an audio bias based model for noise robust small-footprint keyword spotting
May 23, 2023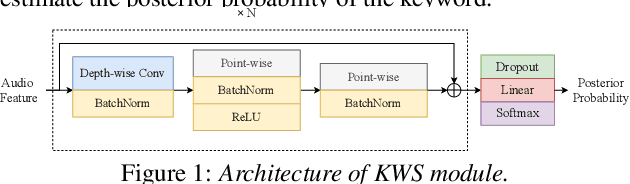

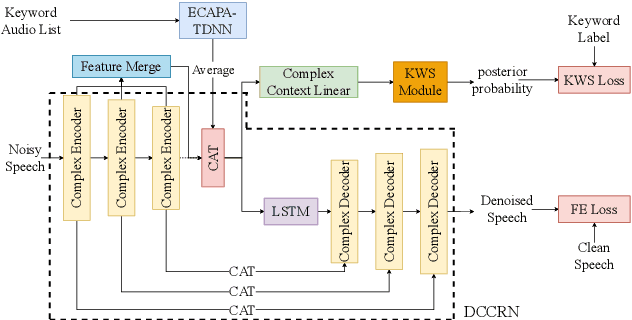
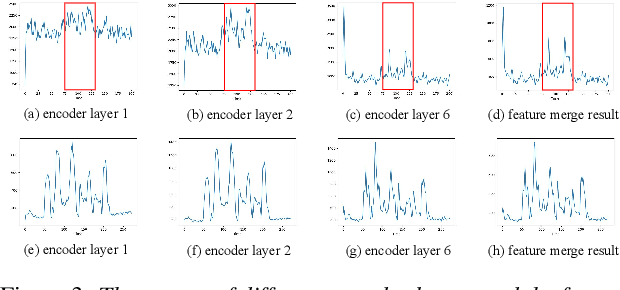
Real-world complex acoustic environments especially the ones with a low signal-to-noise ratio (SNR) will bring tremendous challenges to a keyword spotting (KWS) system. Inspired by the recent advances of neural speech enhancement and context bias in speech recognition, we propose a robust audio context bias based DCCRN-KWS model to address this challenge. We form the whole architecture as a multi-task learning framework for both denosing and keyword spotting, where the DCCRN encoder is connected with the KWS model. Helped with the denoising task, we further introduce an audio context bias module to leverage the real keyword samples and bias the network to better iscriminate keywords in noisy conditions. Feature merge and complex context linear modules are also introduced to strength such discrimination and to effectively leverage contextual information respectively. Experiments on the internal challenging dataset and the HIMIYA public dataset show that our DCCRN-KWS system is superior in performance, while ablation study demonstrates the good design of the whole model.
Towards Relation Extraction From Speech
Oct 17, 2022



Relation extraction typically aims to extract semantic relationships between entities from the unstructured text. One of the most essential data sources for relation extraction is the spoken language, such as interviews and dialogues. However, the error propagation introduced in automatic speech recognition (ASR) has been ignored in relation extraction, and the end-to-end speech-based relation extraction method has been rarely explored. In this paper, we propose a new listening information extraction task, i.e., speech relation extraction. We construct the training dataset for speech relation extraction via text-to-speech systems, and we construct the testing dataset via crowd-sourcing with native English speakers. We explore speech relation extraction via two approaches: the pipeline approach conducting text-based extraction with a pretrained ASR module, and the end2end approach via a new proposed encoder-decoder model, or what we called SpeechRE. We conduct comprehensive experiments to distinguish the challenges in speech relation extraction, which may shed light on future explorations. We share the code and data on https://github.com/wutong8023/SpeechRE.
Who is Speaking Actually? Robust and Versatile Speaker Traceability for Voice Conversion
May 09, 2023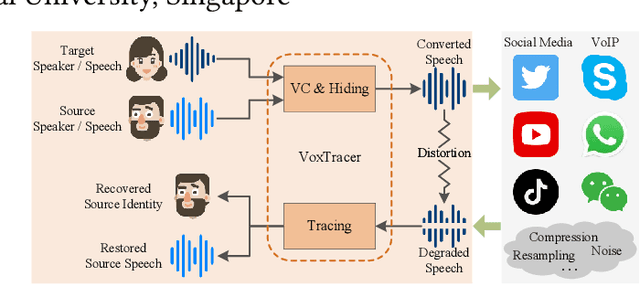
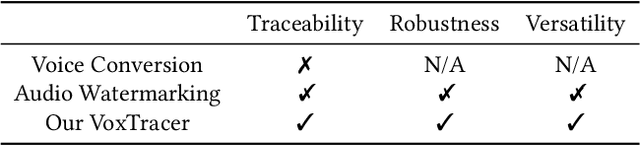
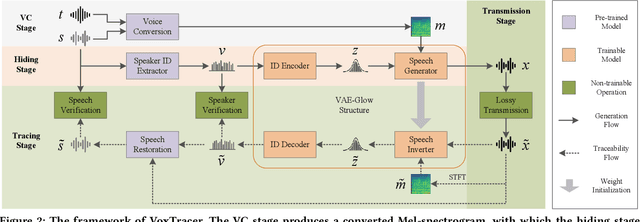
Voice conversion (VC), as a voice style transfer technology, is becoming increasingly prevalent while raising serious concerns about its illegal use. Proactively tracing the origins of VC-generated speeches, i.e., speaker traceability, can prevent the misuse of VC, but unfortunately has not been extensively studied. In this paper, we are the first to investigate the speaker traceability for VC and propose a traceable VC framework named VoxTracer. Our VoxTracer is similar to but beyond the paradigm of audio watermarking. We first use unique speaker embedding to represent speaker identity. Then we design a VAE-Glow structure, in which the hiding process imperceptibly integrates the source speaker identity into the VC, and the tracing process accurately recovers the source speaker identity and even the source speech in spite of severe speech quality degradation. To address the speech mismatch between the hiding and tracing processes affected by different distortions, we also adopt an asynchronous training strategy to optimize the VAE-Glow models. The VoxTracer is versatile enough to be applied to arbitrary VC methods and popular audio coding standards. Extensive experiments demonstrate that the VoxTracer achieves not only high imperceptibility in hiding, but also nearly 100% tracing accuracy against various types of audio lossy compressions (AAC, MP3, Opus and SILK) with a broad range of bitrates (16 kbps - 128 kbps) even in a very short time duration (0.74s). Our speech demo is available at https://anonymous.4open.science/w/DEMOofVoxTracer.
MF-PAM: Accurate Pitch Estimation through Periodicity Analysis and Multi-level Feature Fusion
Jun 16, 2023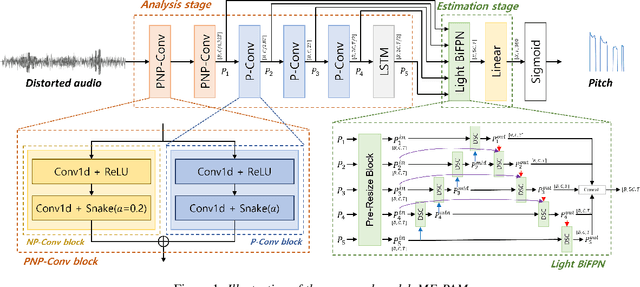
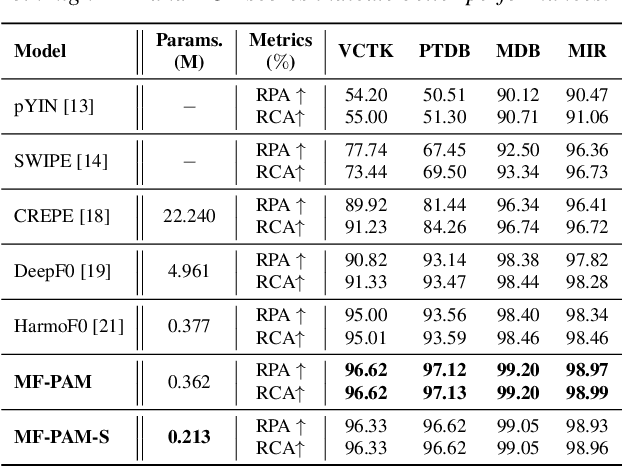
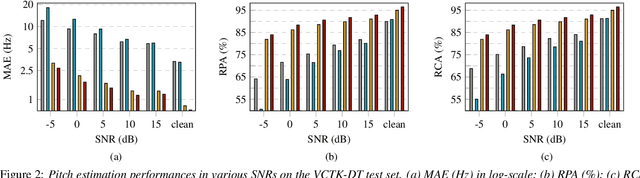
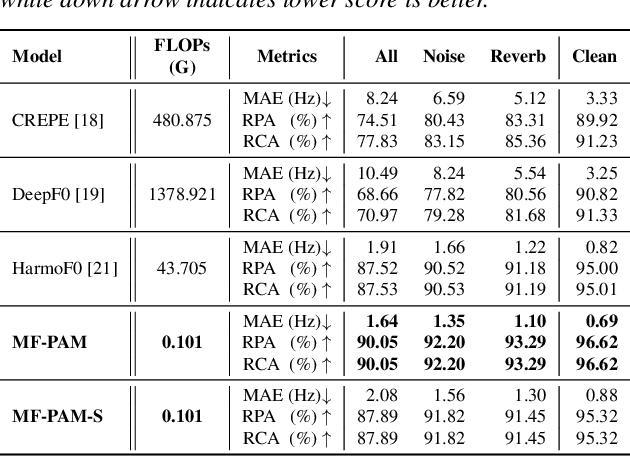
We introduce Multi-level feature Fusion-based Periodicity Analysis Model (MF-PAM), a novel deep learning-based pitch estimation model that accurately estimates pitch trajectory in noisy and reverberant acoustic environments. Our model leverages the periodic characteristics of audio signals and involves two key steps: extracting pitch periodicity using periodic non-periodic convolution (PNP-Conv) blocks and estimating pitch by aggregating multi-level features using a modified bi-directional feature pyramid network (BiFPN). We evaluate our model on speech and music datasets and achieve superior pitch estimation performance compared to state-of-the-art baselines while using fewer model parameters. Our model achieves 99.20 % accuracy in pitch estimation on a clean musical dataset. Overall, our proposed model provides a promising solution for accurate pitch estimation in challenging acoustic environments and has potential applications in audio signal processing.
FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder With Multiple STFTs
May 18, 2023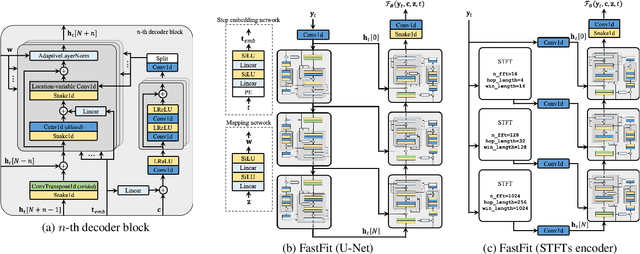
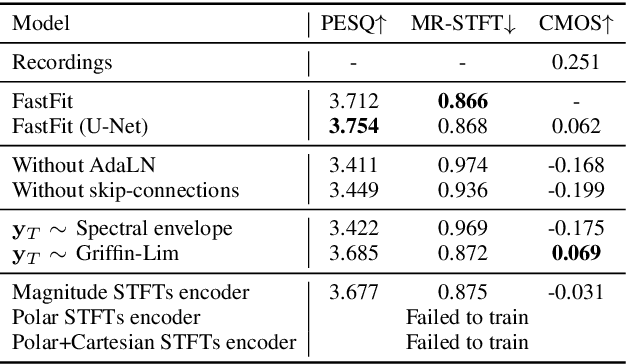
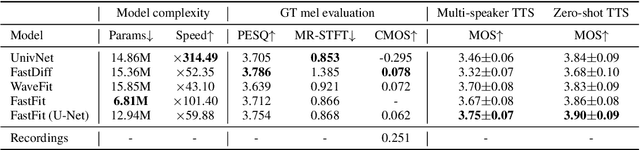
This paper presents FastFit, a novel neural vocoder architecture that replaces the U-Net encoder with multiple short-time Fourier transforms (STFTs) to achieve faster generation rates without sacrificing sample quality. We replaced each encoder block with an STFT, with parameters equal to the temporal resolution of each decoder block, leading to the skip connection. FastFit reduces the number of parameters and the generation time of the model by almost half while maintaining high fidelity. Through objective and subjective evaluations, we demonstrated that the proposed model achieves nearly twice the generation speed of baseline iteration-based vocoders while maintaining high sound quality. We further showed that FastFit produces sound qualities similar to those of other baselines in text-to-speech evaluation scenarios, including multi-speaker and zero-shot text-to-speech.
Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework
Jul 06, 2023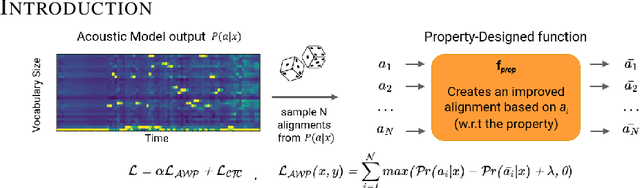

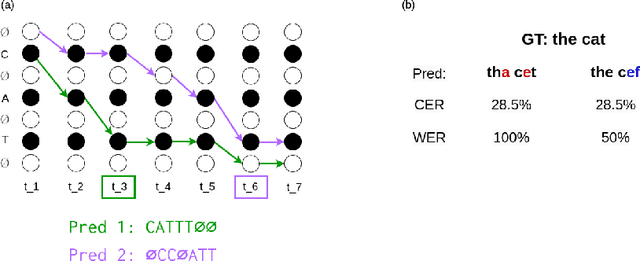
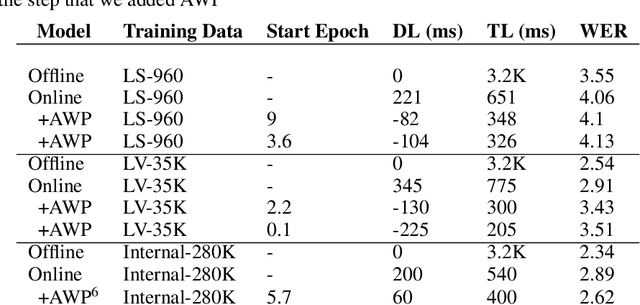
Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
MMSpeech: Multi-modal Multi-task Encoder-Decoder Pre-training for Speech Recognition
Nov 29, 2022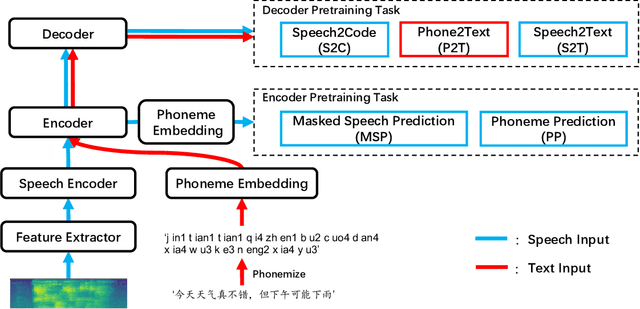
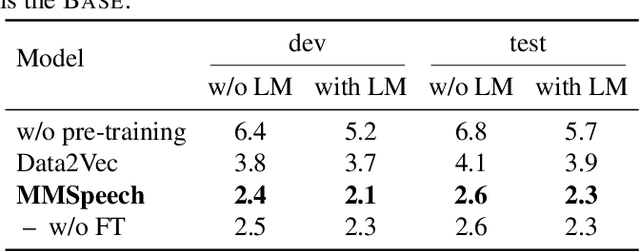
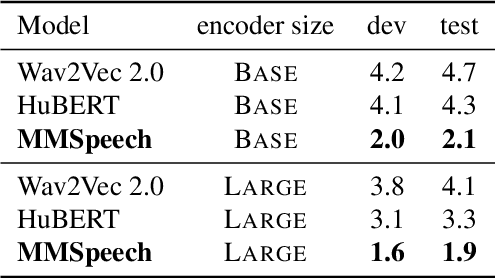

In this paper, we propose a novel multi-modal multi-task encoder-decoder pre-training framework (MMSpeech) for Mandarin automatic speech recognition (ASR), which employs both unlabeled speech and text data. The main difficulty in speech-text joint pre-training comes from the significant difference between speech and text modalities, especially for Mandarin speech and text. Unlike English and other languages with an alphabetic writing system, Mandarin uses an ideographic writing system where character and sound are not tightly mapped to one another. Therefore, we propose to introduce the phoneme modality into pre-training, which can help capture modality-invariant information between Mandarin speech and text. Specifically, we employ a multi-task learning framework including five self-supervised and supervised tasks with speech and text data. For end-to-end pre-training, we introduce self-supervised speech-to-pseudo-codes (S2C) and phoneme-to-text (P2T) tasks utilizing unlabeled speech and text data, where speech-pseudo-codes pairs and phoneme-text pairs are a supplement to the supervised speech-text pairs. To train the encoder to learn better speech representation, we introduce self-supervised masked speech prediction (MSP) and supervised phoneme prediction (PP) tasks to learn to map speech into phonemes. Besides, we directly add the downstream supervised speech-to-text (S2T) task into the pre-training process, which can further improve the pre-training performance and achieve better recognition results even without fine-tuning. Experiments on AISHELL-1 show that our proposed method achieves state-of-the-art performance, with a more than 40% relative improvement compared with other pre-training methods.
Simple and Effective Unsupervised Speech Translation
Oct 18, 2022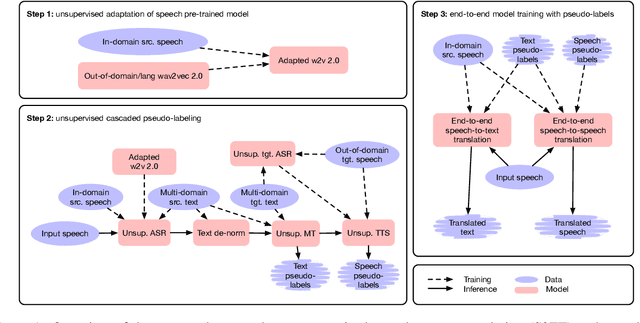
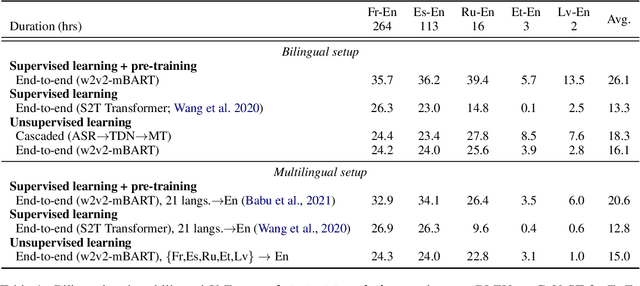
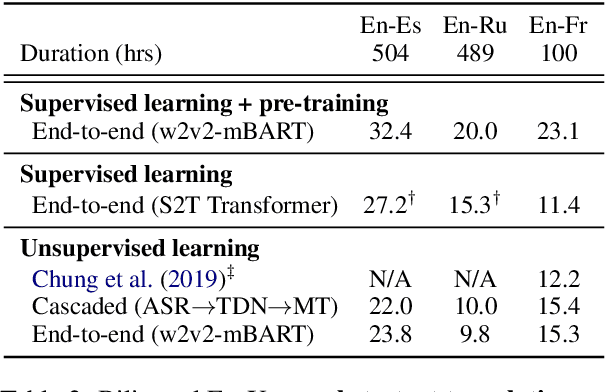
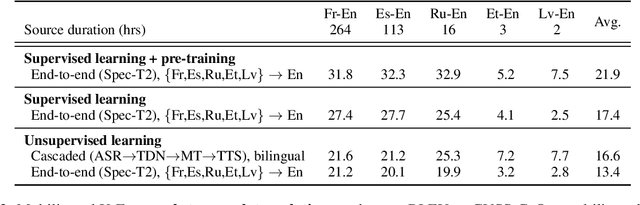
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.
Complex Dynamic Neurons Improved Spiking Transformer Network for Efficient Automatic Speech Recognition
Feb 02, 2023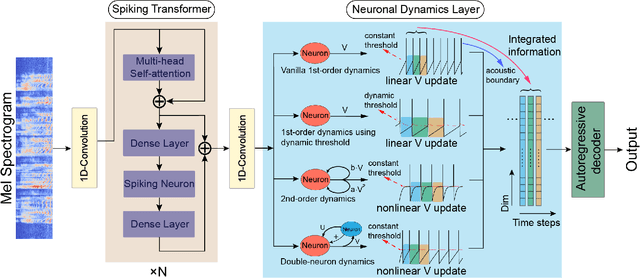

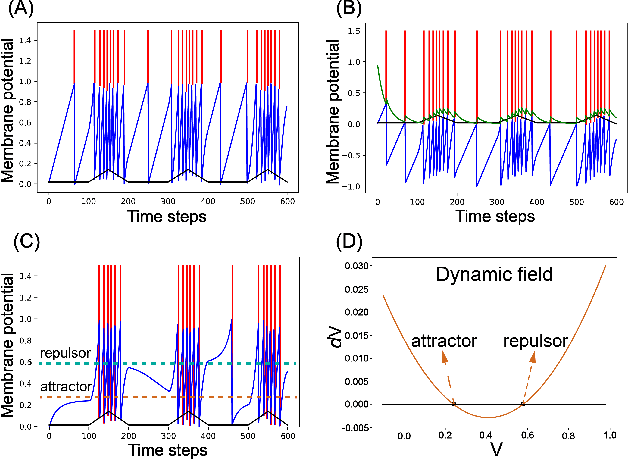
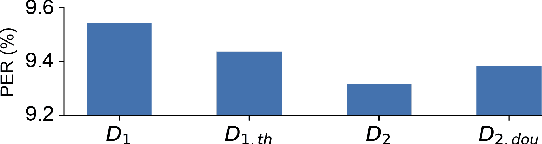
The spiking neural network (SNN) using leaky-integrated-and-fire (LIF) neurons has been commonly used in automatic speech recognition (ASR) tasks. However, the LIF neuron is still relatively simple compared to that in the biological brain. Further research on more types of neurons with different scales of neuronal dynamics is necessary. Here we introduce four types of neuronal dynamics to post-process the sequential patterns generated from the spiking transformer to get the complex dynamic neuron improved spiking transformer neural network (DyTr-SNN). We found that the DyTr-SNN could handle the non-toy automatic speech recognition task well, representing a lower phoneme error rate, lower computational cost, and higher robustness. These results indicate that the further cooperation of SNNs and neural dynamics at the neuron and network scales might have much in store for the future, especially on the ASR tasks.