 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on EEG-Based Emotion Recognition: A Graph-Based Perspective
Aug 13, 2024



Compared to other modalities, electroencephalogram (EEG) based emotion recognition can intuitively respond to emotional patterns in the human brain and, therefore, has become one of the most focused tasks in affective computing. The nature of emotions is a physiological and psychological state change in response to brain region connectivity, making emotion recognition focus more on the dependency between brain regions instead of specific brain regions. A significant trend is the application of graphs to encapsulate such dependency as dynamic functional connections between nodes across temporal and spatial dimensions. Concurrently, the neuroscientific underpinnings behind this dependency endow the application of graphs in this field with a distinctive significance. However, there is neither a comprehensive review nor a tutorial for constructing emotion-relevant graphs in EEG-based emotion recognition. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of graph-related methods in this field from a methodological perspective. We propose a unified framework for graph applications in this field and categorize these methods on this basis. Finally, based on previous studies, we also present several open challenges and future directions in this field.
Graph Neural Networks in EEG-based Emotion Recognition: A Survey
Feb 02, 2024



Compared to other modalities, EEG-based emotion recognition can intuitively respond to the emotional patterns in the human brain and, therefore, has become one of the most concerning tasks in the brain-computer interfaces field. Since dependencies within brain regions are closely related to emotion, a significant trend is to develop Graph Neural Networks (GNNs) for EEG-based emotion recognition. However, brain region dependencies in emotional EEG have physiological bases that distinguish GNNs in this field from those in other time series fields. Besides, there is neither a comprehensive review nor guidance for constructing GNNs in EEG-based emotion recognition. In the survey, our categorization reveals the commonalities and differences of existing approaches under a unified framework of graph construction. We analyze and categorize methods from three stages in the framework to provide clear guidance on constructing GNNs in EEG-based emotion recognition. In addition, we discuss several open challenges and future directions, such as Temporal full-connected graph and Graph condensation.
Who is Speaking Actually? Robust and Versatile Speaker Traceability for Voice Conversion
May 09, 2023



Voice conversion (VC), as a voice style transfer technology, is becoming increasingly prevalent while raising serious concerns about its illegal use. Proactively tracing the origins of VC-generated speeches, i.e., speaker traceability, can prevent the misuse of VC, but unfortunately has not been extensively studied. In this paper, we are the first to investigate the speaker traceability for VC and propose a traceable VC framework named VoxTracer. Our VoxTracer is similar to but beyond the paradigm of audio watermarking. We first use unique speaker embedding to represent speaker identity. Then we design a VAE-Glow structure, in which the hiding process imperceptibly integrates the source speaker identity into the VC, and the tracing process accurately recovers the source speaker identity and even the source speech in spite of severe speech quality degradation. To address the speech mismatch between the hiding and tracing processes affected by different distortions, we also adopt an asynchronous training strategy to optimize the VAE-Glow models. The VoxTracer is versatile enough to be applied to arbitrary VC methods and popular audio coding standards. Extensive experiments demonstrate that the VoxTracer achieves not only high imperceptibility in hiding, but also nearly 100% tracing accuracy against various types of audio lossy compressions (AAC, MP3, Opus and SILK) with a broad range of bitrates (16 kbps - 128 kbps) even in a very short time duration (0.74s). Our speech demo is available at https://anonymous.4open.science/w/DEMOofVoxTracer.
An EEG Channel Selection Framework for Driver Drowsiness Detection via Interpretability Guidance
Apr 26, 2023



Drowsy driving has a crucial influence on driving safety, creating an urgent demand for driver drowsiness detection. Electroencephalogram (EEG) signal can accurately reflect the mental fatigue state and thus has been widely studied in drowsiness monitoring. However, the raw EEG data is inherently noisy and redundant, which is neglected by existing works that just use single-channel EEG data or full-head channel EEG data for model training, resulting in limited performance of driver drowsiness detection. In this paper, we are the first to propose an Interpretability-guided Channel Selection (ICS) framework for the driver drowsiness detection task. Specifically, we design a two-stage training strategy to progressively select the key contributing channels with the guidance of interpretability. We first train a teacher network in the first stage using full-head channel EEG data. Then we apply the class activation mapping (CAM) to the trained teacher model to highlight the high-contributing EEG channels and further propose a channel voting scheme to select the top N contributing EEG channels. Finally, we train a student network with the selected channels of EEG data in the second stage for driver drowsiness detection. Experiments are designed on a public dataset, and the results demonstrate that our method is highly applicable and can significantly improve the performance of cross-subject driver drowsiness detection.
Interpretable and Robust AI in EEG Systems: A Survey
Apr 21, 2023



The close coupling of artificial intelligence (AI) and electroencephalography (EEG) has substantially advanced human-computer interaction (HCI) technologies in the AI era. Different from traditional EEG systems, the interpretability and robustness of AI-based EEG systems are becoming particularly crucial. The interpretability clarifies the inner working mechanisms of AI models and thus can gain the trust of users. The robustness reflects the AI's reliability against attacks and perturbations, which is essential for sensitive and fragile EEG signals. Thus the interpretability and robustness of AI in EEG systems have attracted increasing attention, and their research has achieved great progress recently. However, there is still no survey covering recent advances in this field. In this paper, we present the first comprehensive survey and summarize the interpretable and robust AI techniques for EEG systems. Specifically, we first propose a taxonomy of interpretability by characterizing it into three types: backpropagation, perturbation, and inherently interpretable methods. Then we classify the robustness mechanisms into four classes: noise and artifacts, human variability, data acquisition instability, and adversarial attacks. Finally, we identify several critical and unresolved challenges for interpretable and robust AI in EEG systems and further discuss their future directions.
Hiding Data in Colors: Secure and Lossless Deep Image Steganography via Conditional Invertible Neural Networks
Jan 19, 2022



Deep image steganography is a data hiding technology that conceal data in digital images via deep neural networks. However, existing deep image steganography methods only consider the visual similarity of container images to host images, and neglect the statistical security (stealthiness) of container images. Besides, they usually hides data limited to image type and thus relax the constraint of lossless extraction. In this paper, we address the above issues in a unified manner, and propose deep image steganography that can embed data with arbitrary types into images for secure data hiding and lossless data revealing. First, we formulate the data hiding as an image colorization problem, in which the data is binarized and further mapped into the color information for a gray-scale host image. Second, we design a conditional invertible neural network which uses gray-scale image as prior to guide the color generation and perform data hiding in a secure way. Finally, to achieve lossless data revealing, we present a multi-stage training scheme to manage the data loss due to rounding errors between hiding and revealing processes. Extensive experiments demonstrate that the proposed method can perform secure data hiding by generating realism color images and successfully resisting the detection of steganalysis. Moreover, we can achieve 100% revealing accuracy in different scenarios, indicating the practical utility of our steganography in the real-world.
Generalized Local Optimality for Video Steganalysis in Motion Vector Domain
Dec 22, 2021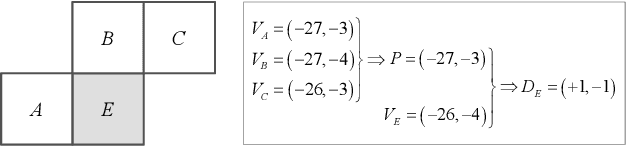
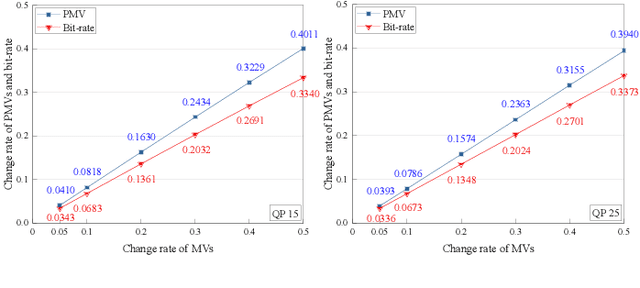
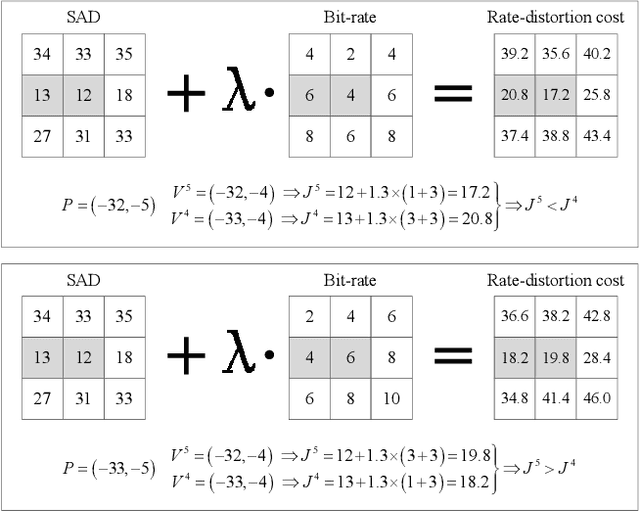
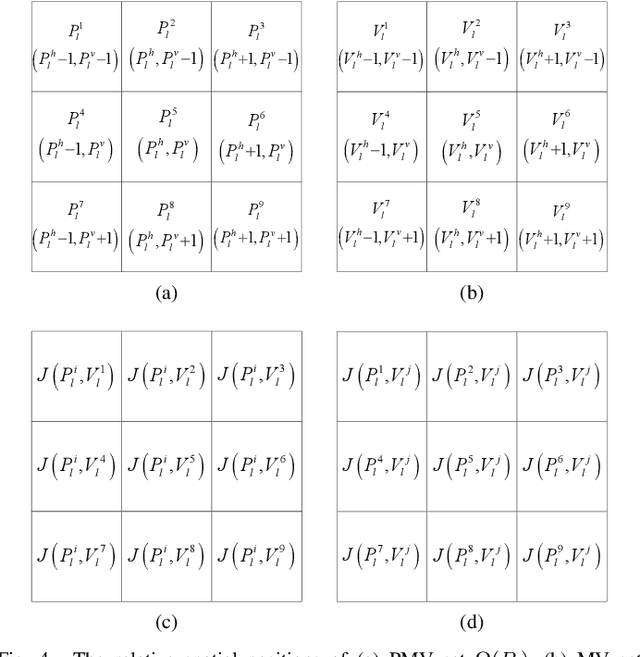
The local optimality of motion vectors (MVs) is an intrinsic property in video coding, and any modifications to the MVs will inevitably destroy this optimality, making it a sensitive indicator of steganography in the MV domain. Thus the local optimality is commonly used to design steganalytic features, and the estimation for local optimality has become a top priority in video steganalysis. However, the local optimality in existing works is often estimated inaccurately or using an unreasonable assumption, limiting its capability in steganalysis. In this paper, we propose to estimate the local optimality in a more reasonable and comprehensive fashion, and generalize the concept of local optimality in two aspects. First, the local optimality measured in a rate-distortion sense is jointly determined by MV and predicted motion vector (PMV), and the variability of PMV will affect the estimation for local optimality. Hence we generalize the local optimality from a static estimation to a dynamic one. Second, the PMV is a special case of MV, and can also reflect the embedding traces in MVs. So we generalize the local optimality from the MV domain to the PMV domain. Based on the two generalizations of local optimality, we construct new types of steganalytic features and also propose feature symmetrization rules to reduce feature dimension. Extensive experiments performed on three databases demonstrate the effectiveness of the proposed features, which achieve state-of-the-art in both accuracy and robustness in various conditions, including cover source mismatch, video prediction methods, video codecs, and video resolutions.
It's Raining Cats or Dogs? Adversarial Rain Attack on DNN Perception
Sep 19, 2020
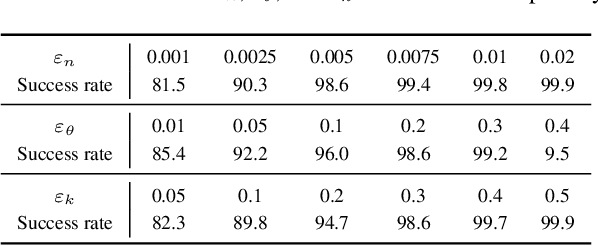
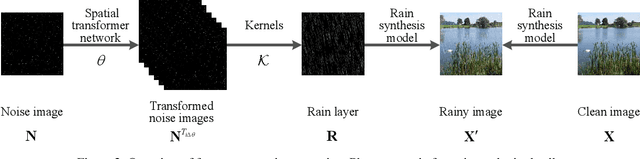
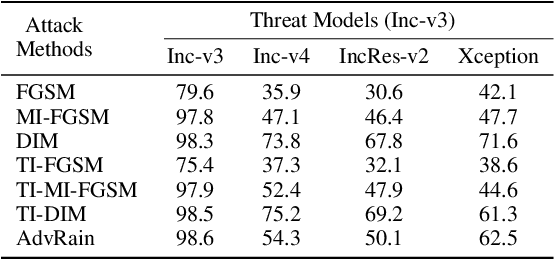
Rain is a common phenomenon in nature and an essential factor for many deep neural network (DNN) based perception systems. Rain can often post inevitable threats that must be carefully addressed especially in the context of safety and security-sensitive scenarios (e.g., autonomous driving). Therefore, a comprehensive investigation of the potential risks of the rain to a DNN is of great importance. Unfortunately, in practice, it is often rather difficult to collect or synthesize rainy images that can represent all raining situations that possibly occur in the real world. To this end, in this paper, we start from a new perspective and propose to combine two totally different studies, i.e., rainy image synthesis and adversarial attack. We present an adversarial rain attack, with which we could simulate various rainy situations with the guidance of deployed DNNs and reveal the potential threat factors that can be brought by rain, helping to develop more rain-robust DNNs. In particular, we propose a factor-aware rain generation that simulates rain steaks according to the camera exposure process and models the learnable rain factors for adversarial attack. With this generator, we further propose the adversarial rain attack against the image classification and object detection, where the rain factors are guided by the various DNNs. As a result, it enables to comprehensively study the impacts of the rain factors to DNNs. Our largescale evaluation on three datasets, i.e., NeurIPS'17 DEV, MS COCO and KITTI, demonstrates that our synthesized rainy images can not only present visually realistic appearances, but also exhibit strong adversarial capability, which builds the foundation for further rain-robust perception studies.