 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
VoxBlink: X-Large Speaker Verification Dataset on Camera
Aug 23, 2023
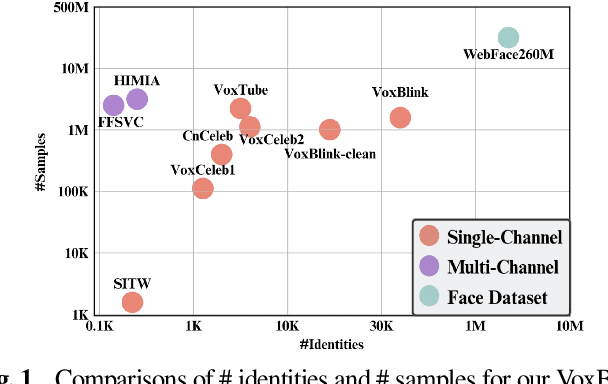
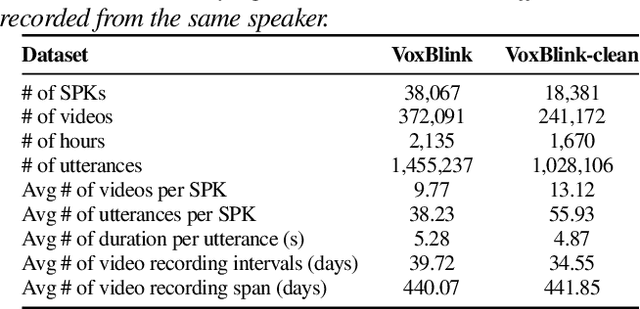
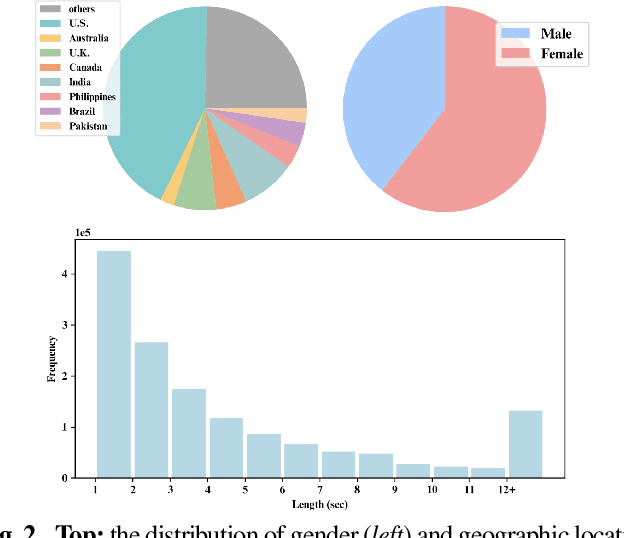
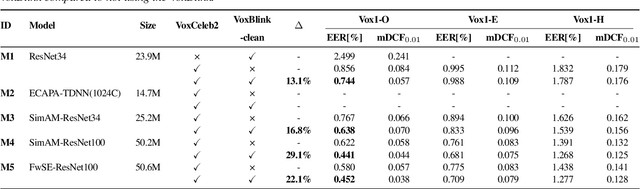
In this paper, we contribute a novel and extensive dataset for speaker verification, which contains noisy 38k identities/1.45M utterances (VoxBlink) and relatively cleaned 18k identities/1.02M (VoxBlink-Clean) utterances for training. Firstly, we accumulate a 60K+ users' list with their avatars and download their short videos on YouTube. We then established an automatic and scalable pipeline to extract relevant speech and video segments from these videos. To our knowledge, the VoxBlink dataset is one of the largest speaker recognition datasets available. Secondly, we conduct a series of experiments based on different backbones trained on a mix of the VoxCeleb2 and the VoxBlink-Clean. Our findings highlight a notable performance improvement, ranging from 13% to 30%, across different backbone architectures upon integrating our dataset for training. The dataset will be made publicly available shortly.
BAN-PL: a Novel Polish Dataset of Banned Harmful and Offensive Content from Wykop.pl web service
Aug 23, 2023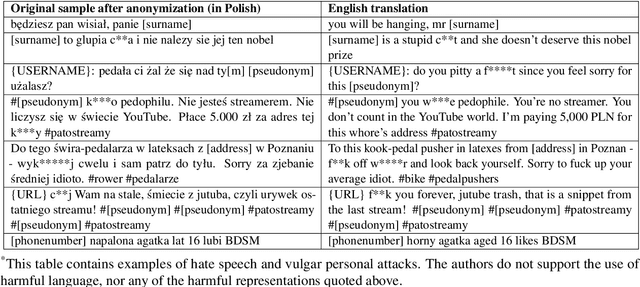

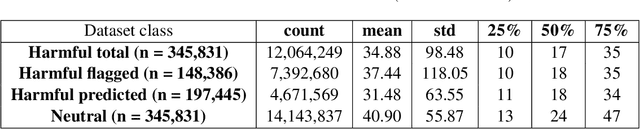
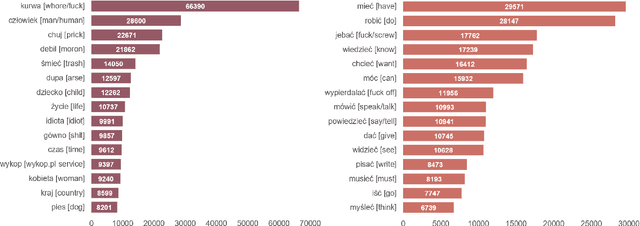
Advances in automated detection of offensive language online, including hate speech and cyberbullying, require improved access to publicly available datasets comprising social media content. In this paper, we introduce BAN-PL, the first open dataset in the Polish language that encompasses texts flagged as harmful and subsequently removed by professional moderators. The dataset encompasses a total of 691,662 pieces of content from a popular social networking service, Wykop, often referred to as the "Polish Reddit", including both posts and comments, and is evenly distributed into two distinct classes: "harmful" and "neutral". We provide a comprehensive description of the data collection and preprocessing procedures, as well as highlight the linguistic specificity of the data. The BAN-PL dataset, along with advanced preprocessing scripts for, i.a., unmasking profanities, will be publicly available.
Self-supervised Learning with Speech Modulation Dropout
Mar 22, 2023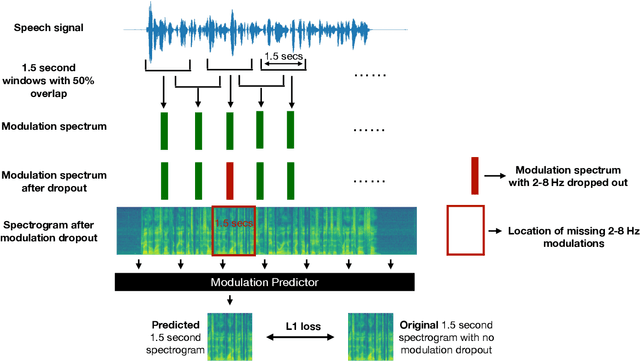

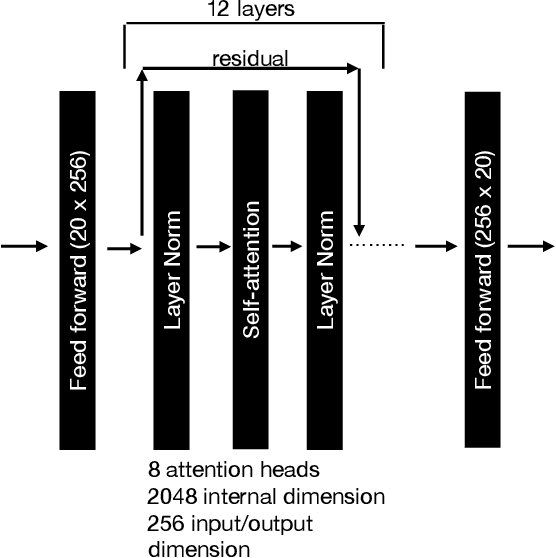
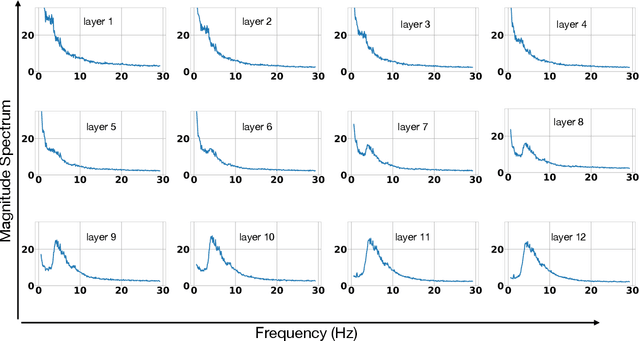
We show that training a multi-headed self-attention-based deep network to predict deleted, information-dense 2-8 Hz speech modulations over a 1.5-second section of a speech utterance is an effective way to make machines learn to extract speech modulations using time-domain contextual information. Our work exhibits that, once trained on large volumes of unlabelled data, the outputs of the self-attention layers vary in time with a modulation peak at 4 Hz. These pre-trained layers can be used to initialize parts of an Automatic Speech Recognition system to reduce its reliance on labeled speech data greatly.
TranUSR: Phoneme-to-word Transcoder Based Unified Speech Representation Learning for Cross-lingual Speech Recognition
May 23, 2023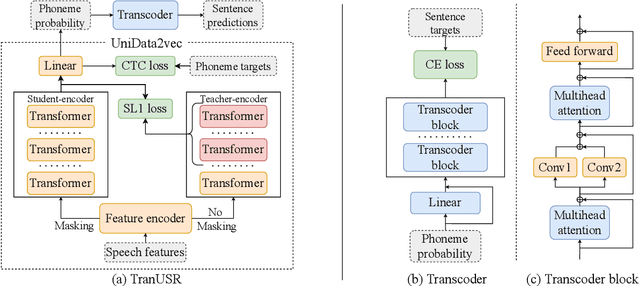
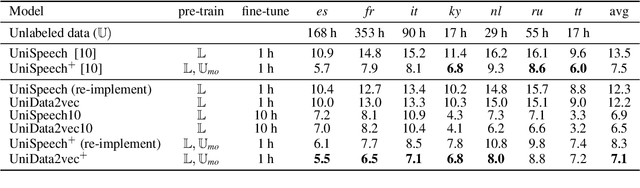

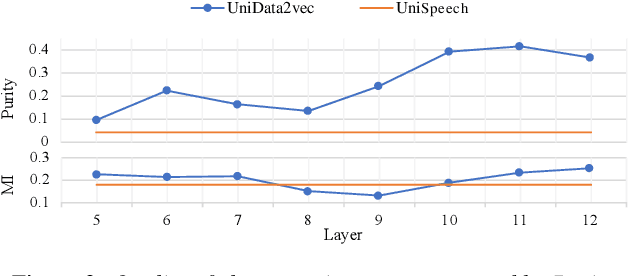
UniSpeech has achieved superior performance in cross-lingual automatic speech recognition (ASR) by explicitly aligning latent representations to phoneme units using multi-task self-supervised learning. While the learned representations transfer well from high-resource to low-resource languages, predicting words directly from these phonetic representations in downstream ASR is challenging. In this paper, we propose TranUSR, a two-stage model comprising a pre-trained UniData2vec and a phoneme-to-word Transcoder. Different from UniSpeech, UniData2vec replaces the quantized discrete representations with continuous and contextual representations from a teacher model for phonetically-aware pre-training. Then, Transcoder learns to translate phonemes to words with the aid of extra texts, enabling direct word generation. Experiments on Common Voice show that UniData2vec reduces PER by 5.3\% compared to UniSpeech, while Transcoder yields a 14.4\% WER reduction compared to grapheme fine-tuning.
On-Device Speaker Anonymization of Acoustic Embeddings for ASR based onFlexible Location Gradient Reversal Layer
Jul 25, 2023Smart devices serviced by large-scale AI models necessitates user data transfer to the cloud for inference. For speech applications, this means transferring private user information, e.g., speaker identity. Our paper proposes a privacy-enhancing framework that targets speaker identity anonymization while preserving speech recognition accuracy for our downstream task~-~Automatic Speech Recognition (ASR). The proposed framework attaches flexible gradient reversal based speaker adversarial layers to target layers within an ASR model, where speaker adversarial training anonymizes acoustic embeddings generated by the targeted layers to remove speaker identity. We propose on-device deployment by execution of initial layers of the ASR model, and transmitting anonymized embeddings to the cloud, where the rest of the model is executed while preserving privacy. Experimental results show that our method efficiently reduces speaker recognition relative accuracy by 33%, and improves ASR performance by achieving 6.2% relative Word Error Rate (WER) reduction.
Miipher: A Robust Speech Restoration Model Integrating Self-Supervised Speech and Text Representations
Mar 03, 2023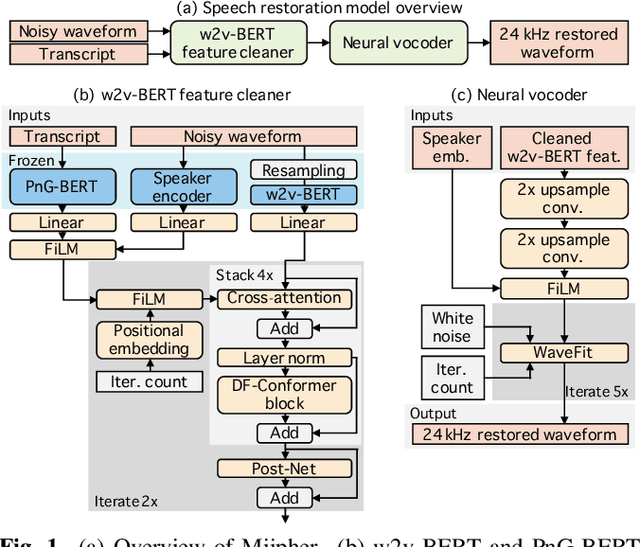
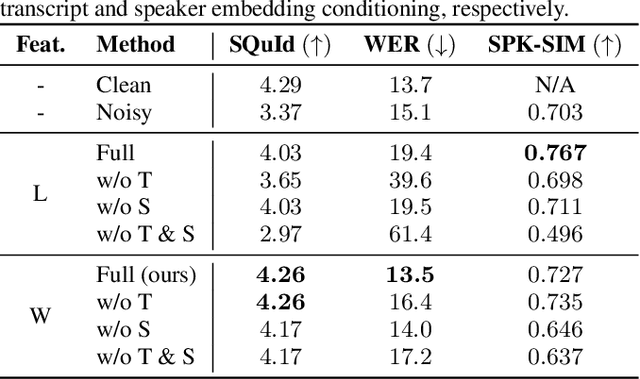
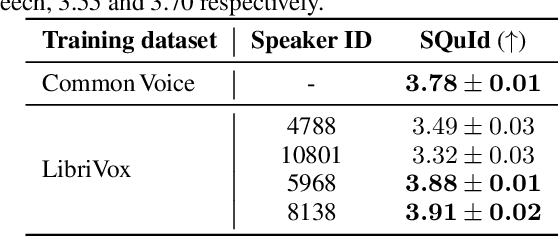
Speech restoration (SR) is a task of converting degraded speech signals into high-quality ones. In this study, we propose a robust SR model called Miipher, and apply Miipher to a new SR application: increasing the amount of high-quality training data for speech generation by converting speech samples collected from the Web to studio-quality. To make our SR model robust against various degradation, we use (i) a speech representation extracted from w2v-BERT for the input feature, and (ii) a text representation extracted from transcripts via PnG-BERT as a linguistic conditioning feature. Experiments show that Miipher (i) is robust against various audio degradation and (ii) enable us to train a high-quality text-to-speech (TTS) model from restored speech samples collected from the Web. Audio samples are available at our demo page: google.github.io/df-conformer/miipher/
Evaluating quantum generative models via imbalanced data classification benchmarks
Aug 21, 2023A limited set of tools exist for assessing whether the behavior of quantum machine learning models diverges from conventional models, outside of abstract or theoretical settings. We present a systematic application of explainable artificial intelligence techniques to analyze synthetic data generated from a hybrid quantum-classical neural network adapted from twenty different real-world data sets, including solar flares, cardiac arrhythmia, and speech data. Each of these data sets exhibits varying degrees of complexity and class imbalance. We benchmark the quantum-generated data relative to state-of-the-art methods for mitigating class imbalance for associated classification tasks. We leverage this approach to elucidate the qualities of a problem that make it more or less likely to be amenable to a hybrid quantum-classical generative model.
DinoSR: Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning
May 17, 2023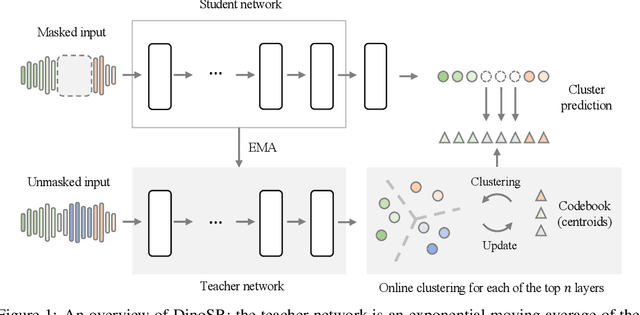
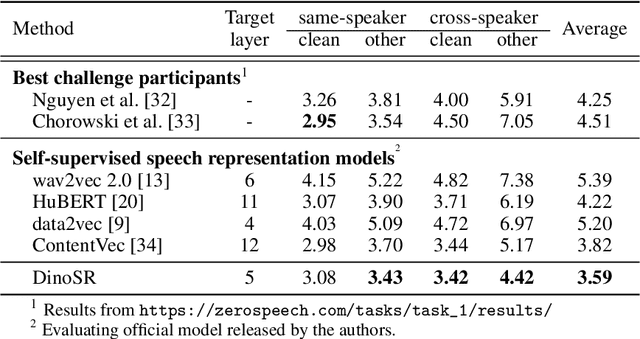
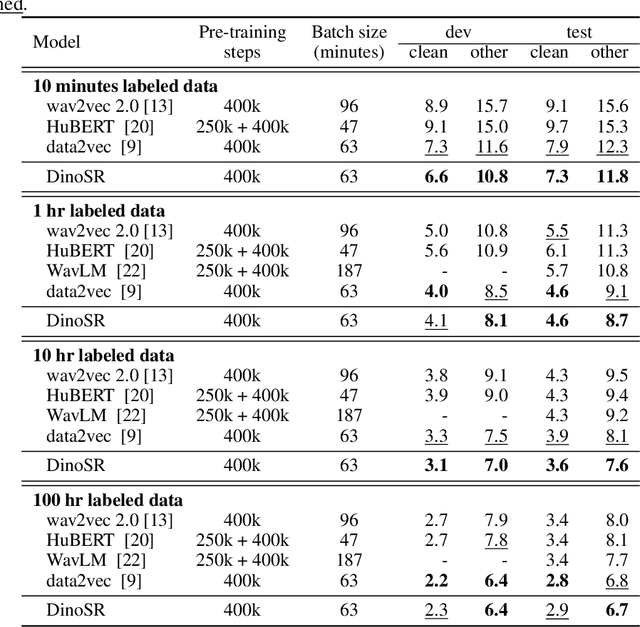
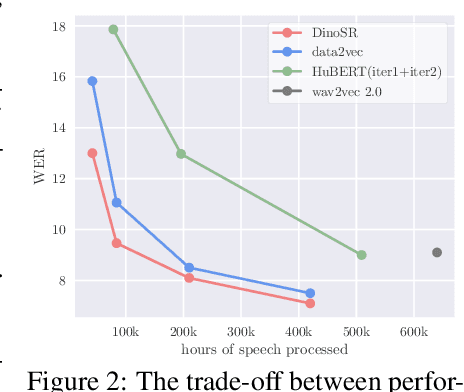
In this paper, we introduce self-distillation and online clustering for self-supervised speech representation learning (DinoSR) which combines masked language modeling, self-distillation, and online clustering. We show that these concepts complement each other and result in a strong representation learning model for speech. DinoSR first extracts contextualized embeddings from the input audio with a teacher network, then runs an online clustering system on the embeddings to yield a machine-discovered phone inventory, and finally uses the discretized tokens to guide a student network. We show that DinoSR surpasses previous state-of-the-art performance in several downstream tasks, and provide a detailed analysis of the model and the learned discrete units. The source code will be made available after the anonymity period.
Ensemble prosody prediction for expressive speech synthesis
Apr 03, 2023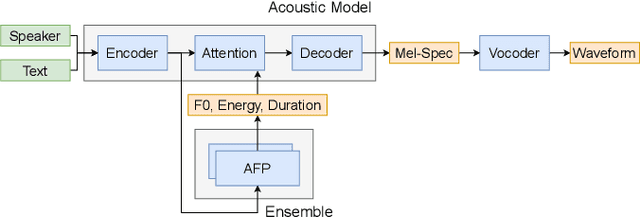

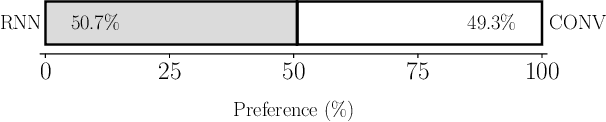
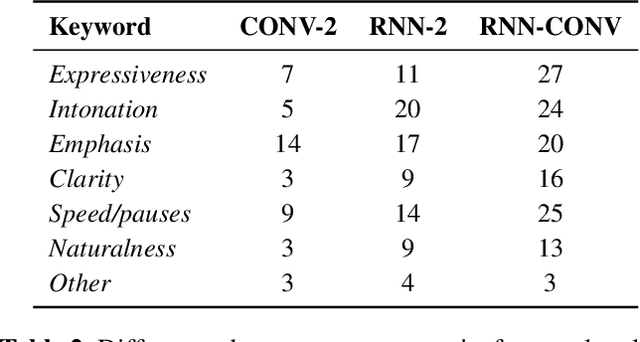
Generating expressive speech with rich and varied prosody continues to be a challenge for Text-to-Speech. Most efforts have focused on sophisticated neural architectures intended to better model the data distribution. Yet, in evaluations it is generally found that no single model is preferred for all input texts. This suggests an approach that has rarely been used before for Text-to-Speech: an ensemble of models. We apply ensemble learning to prosody prediction. We construct simple ensembles of prosody predictors by varying either model architecture or model parameter values. To automatically select amongst the models in the ensemble when performing Text-to-Speech, we propose a novel, and computationally trivial, variance-based criterion. We demonstrate that even a small ensemble of prosody predictors yields useful diversity, which, combined with the proposed selection criterion, outperforms any individual model from the ensemble.
Wav2code: Restore Clean Speech Representations via Codebook Lookup for Noise-Robust ASR
Apr 23, 2023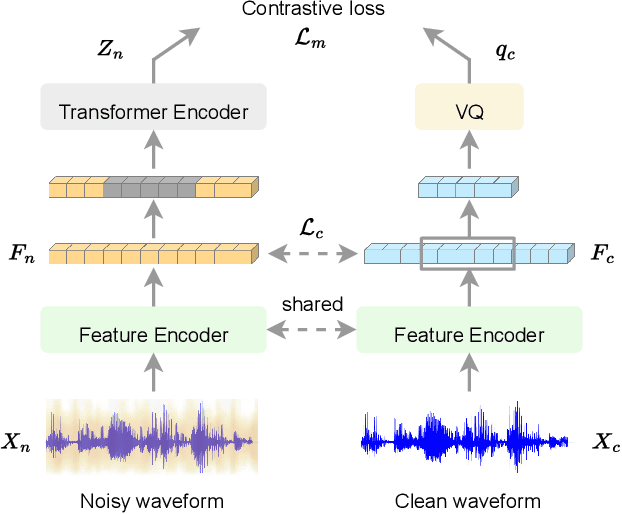
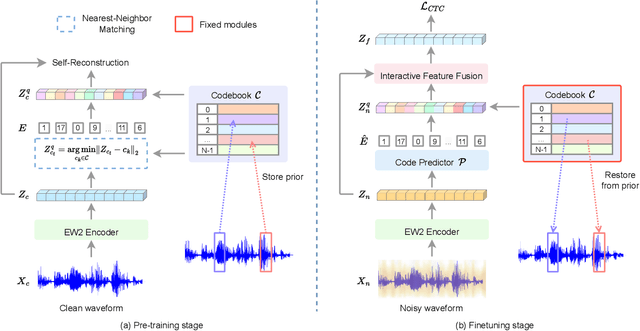
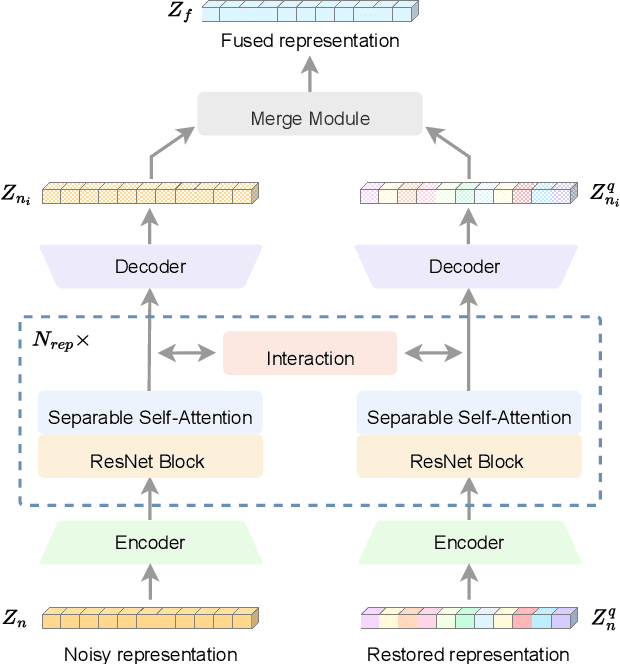
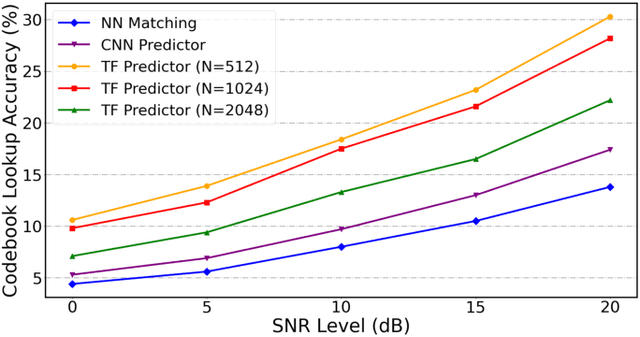
Automatic speech recognition (ASR) has gained a remarkable success thanks to recent advances of deep learning, but it usually degrades significantly under real-world noisy conditions. Recent works introduce speech enhancement (SE) as front-end to improve speech quality, which is proved effective but may not be optimal for downstream ASR due to speech distortion problem. Based on that, latest works combine SE and currently popular self-supervised learning (SSL) to alleviate distortion and improve noise robustness. Despite the effectiveness, the speech distortion caused by conventional SE still cannot be completely eliminated. In this paper, we propose a self-supervised framework named Wav2code to implement a generalized SE without distortions for noise-robust ASR. First, in pre-training stage the clean speech representations from SSL model are sent to lookup a discrete codebook via nearest-neighbor feature matching, the resulted code sequence are then exploited to reconstruct the original clean representations, in order to store them in codebook as prior. Second, during finetuning we propose a Transformer-based code predictor to accurately predict clean codes by modeling the global dependency of input noisy representations, which enables discovery and restoration of high-quality clean representations without distortions. Furthermore, we propose an interactive feature fusion network to combine original noisy and the restored clean representations to consider both fidelity and quality, resulting in even more informative features for downstream ASR. Finally, experiments on both synthetic and real noisy datasets demonstrate that Wav2code can solve the speech distortion and improve ASR performance under various noisy conditions, resulting in stronger robustness.