 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing
Jun 09, 2025The performance of automatic speaker verification (ASV) and anti-spoofing drops seriously under real-world domain mismatch conditions. The relaxed instance frequency-wise normalization (RFN), which normalizes the frequency components based on the feature statistics along the time and channel axes, is a promising approach to reducing the domain dependence in the feature maps of a speaker embedding network. We advocate that the different frequencies should receive different weights and that the weights' uncertainty due to domain shift should be accounted for. To these ends, we propose leveraging variational inference to model the posterior distribution of the weights, which results in Bayesian weighted RFN (BWRFN). This approach overcomes the limitations of fixed-weight RFN, making it more effective under domain mismatch conditions. Extensive experiments on cross-dataset ASV, cross-TTS anti-spoofing, and spoofing-robust ASV show that BWRFN is significantly better than WRFN and RFN.
Self-supervised Learning with Speech Modulation Dropout
Mar 22, 2023



We show that training a multi-headed self-attention-based deep network to predict deleted, information-dense 2-8 Hz speech modulations over a 1.5-second section of a speech utterance is an effective way to make machines learn to extract speech modulations using time-domain contextual information. Our work exhibits that, once trained on large volumes of unlabelled data, the outputs of the self-attention layers vary in time with a modulation peak at 4 Hz. These pre-trained layers can be used to initialize parts of an Automatic Speech Recognition system to reduce its reliance on labeled speech data greatly.
Stabilized training of joint energy-based models and their practical applications
Mar 07, 2023



The recently proposed Joint Energy-based Model (JEM) interprets discriminatively trained classifier $p(y|x)$ as an energy model, which is also trained as a generative model describing the distribution of the input observations $p(x)$. The JEM training relies on "positive examples" (i.e. examples from the training data set) as well as on "negative examples", which are samples from the modeled distribution $p(x)$ generated by means of Stochastic Gradient Langevin Dynamics (SGLD). Unfortunately, SGLD often fails to deliver negative samples of sufficient quality during the standard JEM training, which causes a very unbalanced contribution from the positive and negative examples when calculating gradients for JEM updates. As a consequence, the standard JEM training is quite unstable requiring careful tuning of hyper-parameters and frequent restarts when the training starts diverging. This makes it difficult to apply JEM to different neural network architectures, modalities, and tasks. In this work, we propose a training procedure that stabilizes SGLD-based JEM training (ST-JEM) by balancing the contribution from the positive and negative examples. We also propose to add an additional "regularization" term to the training objective -- MI between the input observations $x$ and output labels $y$ -- which encourages the JEM classifier to make more certain decisions about output labels. We demonstrate the effectiveness of our approach on the CIFAR10 and CIFAR100 tasks. We also consider the task of classifying phonemes in a speech signal, for which we were not able to train JEM without the proposed stabilization. We show that a convincing speech can be generated from the trained model. Alternatively, corrupted speech can be de-noised by bringing it closer to the modeled speech distribution using a few SGLD iterations. We also propose and discuss additional applications of the trained model.
Blind Signal Dereverberation for Machine Speech Recognition
Sep 30, 2022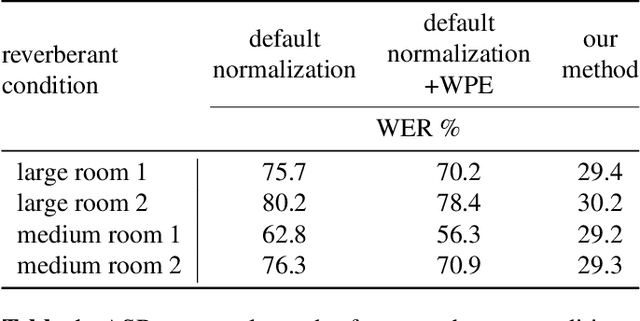
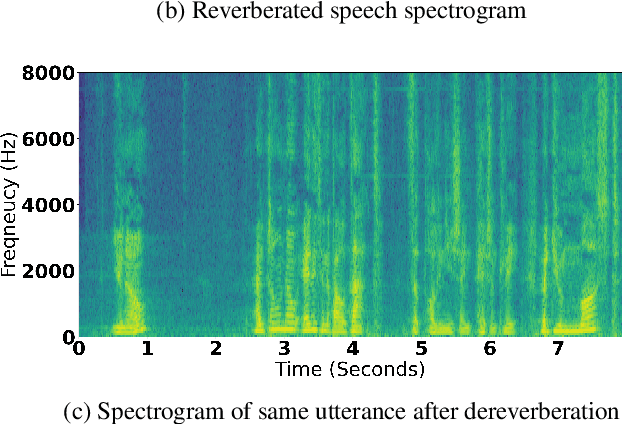
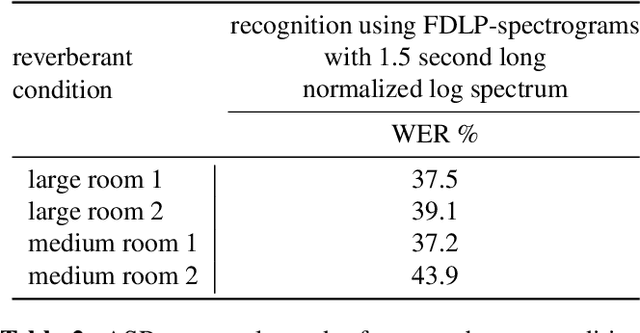
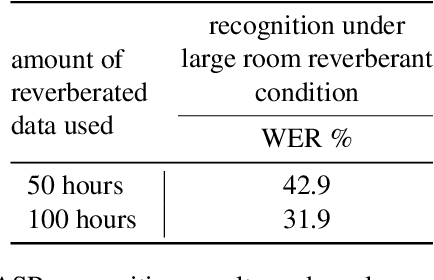
We present a method to remove unknown convolutive noise introduced to speech by reverberations of recording environments, utilizing some amount of training speech data from the reverberant environment, and any available non-reverberant speech data. Using Fourier transform computed over long temporal windows, which ideally cover the entire room impulse response, we convert room induced convolution to additions in the log spectral domain. Next, we compute a spectral normalization vector from statistics gathered over reverberated as well as over clean speech in the log spectral domain. During operation, this normalization vectors are used to alleviate reverberations from complex speech spectra recorded under the same reverberant conditions . Such dereverberated complex speech spectra are used to compute complex FDLP-spectrograms for use in automatic speech recognition.
Importance of Different Temporal Modulations of Speech: A Tale of Two Perspectives
Mar 31, 2022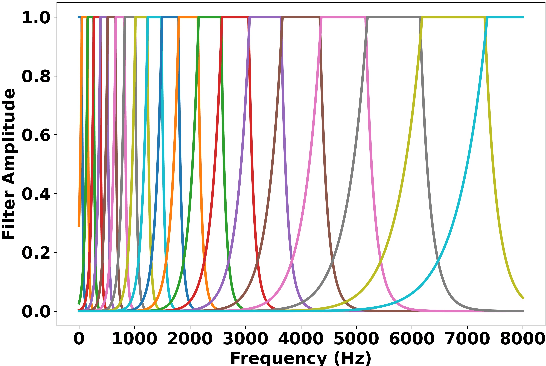

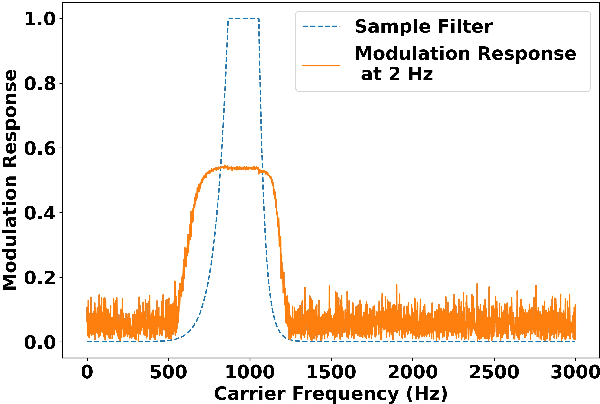
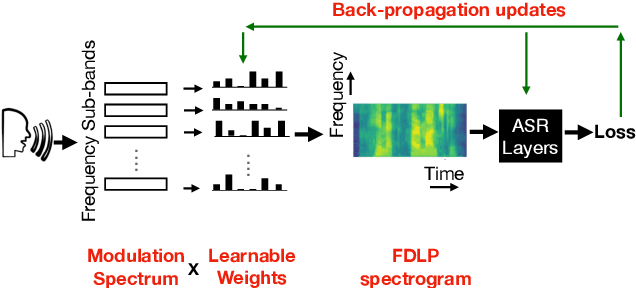
How important are different temporal speech modulations for speech recognition? We answer this question from two complementary perspectives. Firstly, we quantify the amount of phonetic information in the modulation spectrum of speech by computing the mutual information between temporal modulations with frame-wise phoneme labels. Looking from another perspective, we ask - which speech modulations does an Automatic Speech Recognition (ASR) system prefer for its operation. Data-driven weights are learnt over the modulation spectrum and optimized for an end-to-end ASR task. Both methods unanimously agree that speech information is mostly contained in slow modulation. Maximum mutual information occurs around 3-6 Hz which also happens to be the range of modulations most preferred by the ASR. In addition, we show that incorporation of this knowledge into ASRs significantly reduces its dependency on the amount of training data.
Complex Frequency Domain Linear Prediction: A Tool to Compute Modulation Spectrum of Speech
Mar 31, 2022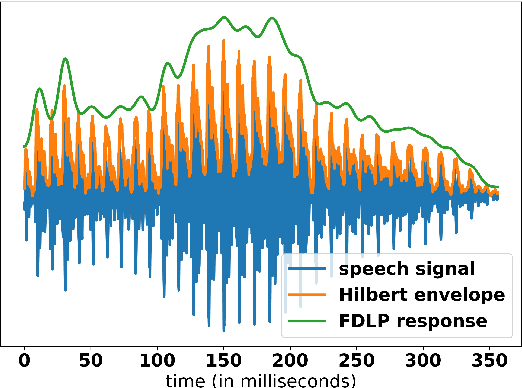

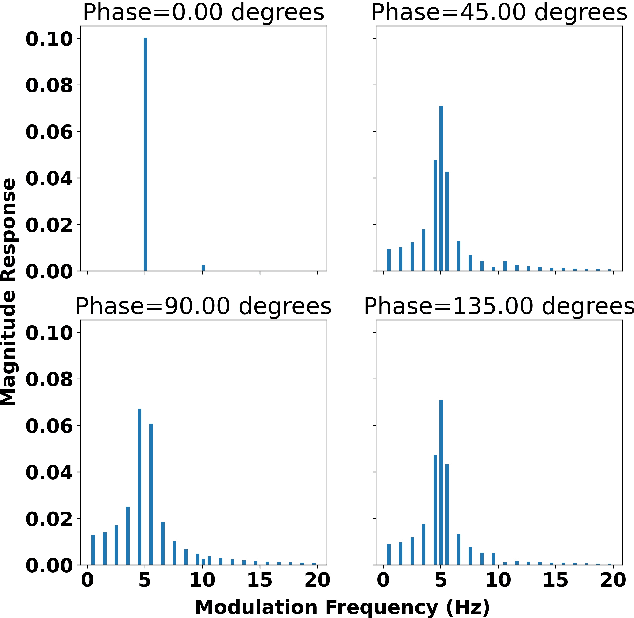
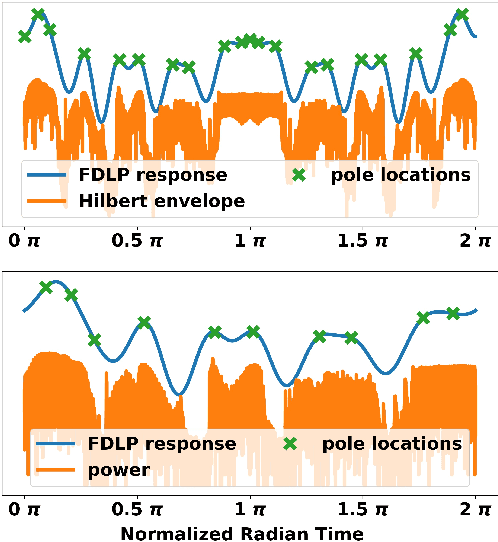
Conventional Frequency Domain Linear Prediction (FDLP) technique models the squared Hilbert envelope of speech with varied degrees of approximation which can be sampled at the required frame rate and used as features for Automatic Speech Recognition (ASR). Although previously the complex cepstrum of the conventional FDLP model has been used as compact frame-wise speech features, it has lacked interpretability in the context of the Hilbert envelope. In this paper, we propose a modification of the conventional FDLP model that allows easy interpretability of the complex cepstrum as temporal modulations in an all-pole model approximation of the power of the speech signal. Additionally, our "complex" FDLP yields significant speed-ups in comparison to conventional FDLP for the same degree of approximation.
Radically Old Way of Computing Spectra: Applications in End-to-End ASR
Apr 02, 2021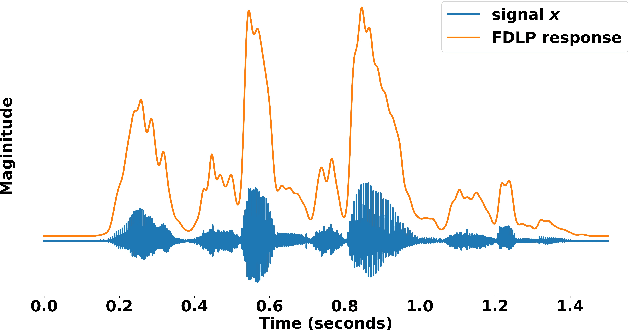

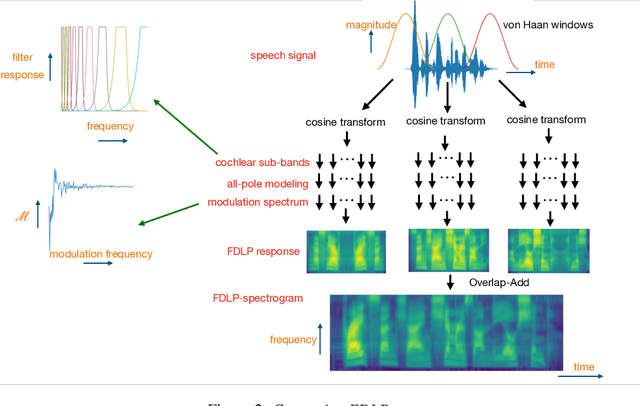

We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the squared Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. A long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP spectrogram performs on par with the standard mel spectrogram features for clean read speech training and test data. For more realistic speech data with train-test domain mismatches or reverberations, FDLP spectrogram shows up to 25% and 22% relative WER improvements over mel spectrogram respectively.
Two-Stage Augmentation and Adaptive CTC Fusion for Improved Robustness of Multi-Stream End-to-End ASR
Feb 05, 2021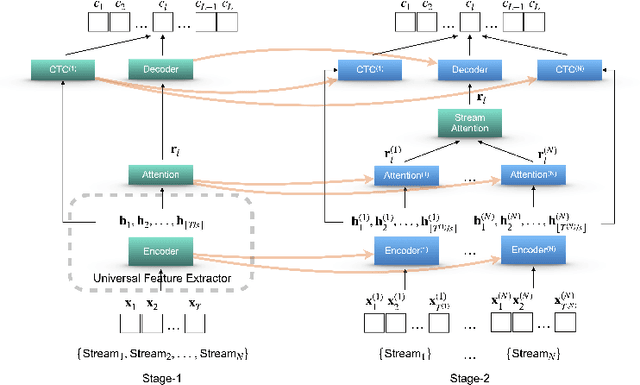


Performance degradation of an Automatic Speech Recognition (ASR) system is commonly observed when the test acoustic condition is different from training. Hence, it is essential to make ASR systems robust against various environmental distortions, such as background noises and reverberations. In a multi-stream paradigm, improving robustness takes account of handling a variety of unseen single-stream conditions and inter-stream dynamics. Previously, a practical two-stage training strategy was proposed within multi-stream end-to-end ASR, where Stage-2 formulates the multi-stream model with features from Stage-1 Universal Feature Extractor (UFE). In this paper, as an extension, we introduce a two-stage augmentation scheme focusing on mismatch scenarios: Stage-1 Augmentation aims to address single-stream input varieties with data augmentation techniques; Stage-2 Time Masking applies temporal masks on UFE features of randomly selected streams to simulate diverse stream combinations. During inference, we also present adaptive Connectionist Temporal Classification (CTC) fusion with the help of hierarchical attention mechanisms. Experiments have been conducted on two datasets, DIRHA and AMI, as a multi-stream scenario. Compared with the previous training strategy, substantial improvements are reported with relative word error rate reductions of 29.7-59.3% across several unseen stream combinations.
A practical two-stage training strategy for multi-stream end-to-end speech recognition
Oct 23, 2019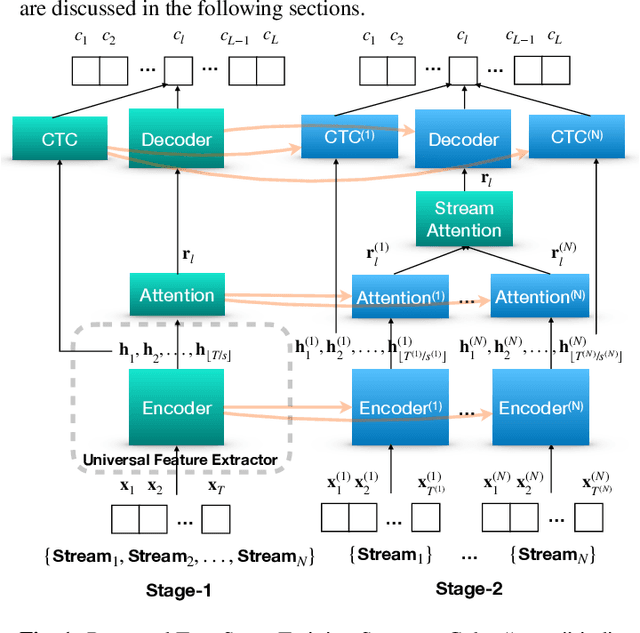
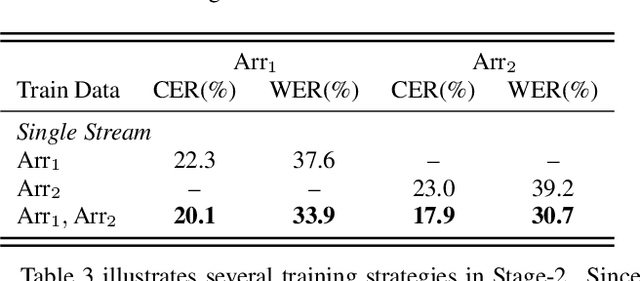
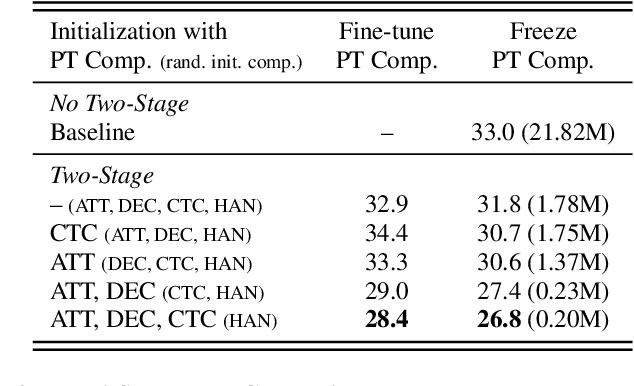
The multi-stream paradigm of audio processing, in which several sources are simultaneously considered, has been an active research area for information fusion. Our previous study offered a promising direction within end-to-end automatic speech recognition, where parallel encoders aim to capture diverse information followed by a stream-level fusion based on attention mechanisms to combine the different views. However, with an increasing number of streams resulting in an increasing number of encoders, the previous approach could require substantial memory and massive amounts of parallel data for joint training. In this work, we propose a practical two-stage training scheme. Stage-1 is to train a Universal Feature Extractor (UFE), where encoder outputs are produced from a single-stream model trained with all data. Stage-2 formulates a multi-stream scheme intending to solely train the attention fusion module using the UFE features and pretrained components from Stage-1. Experiments have been conducted on two datasets, DIRHA and AMI, as a multi-stream scenario. Compared with our previous method, this strategy achieves relative word error rate reductions of 8.2--32.4%, while consistently outperforming several conventional combination methods.
Multi-Stream End-to-End Speech Recognition
Jun 17, 2019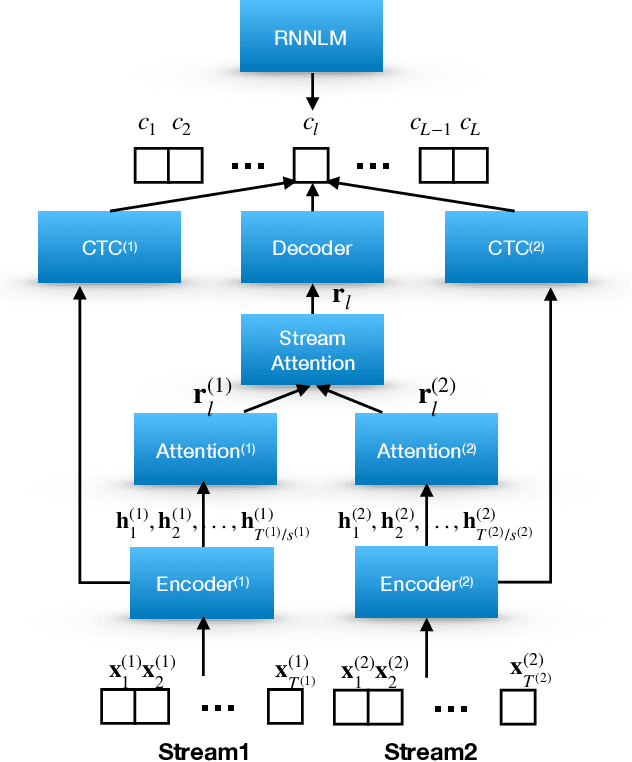
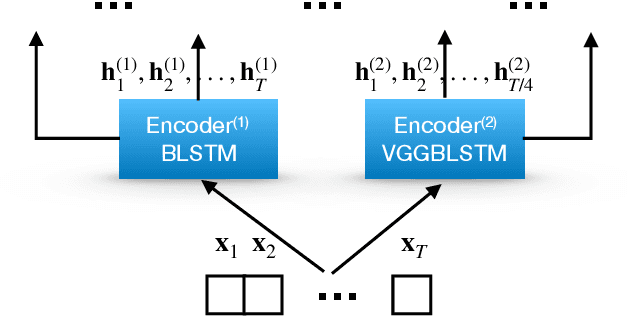
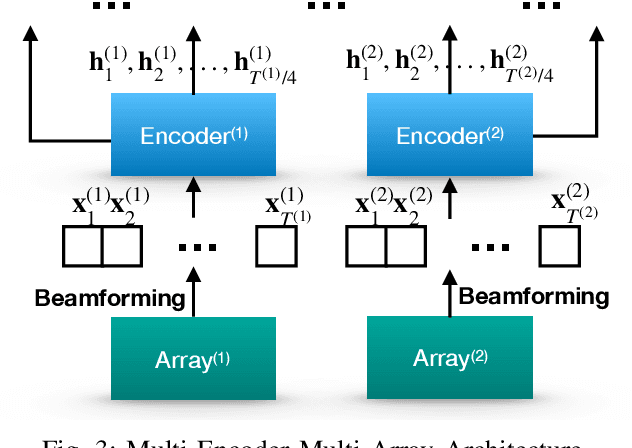
Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end (E2E) Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a multi-stream framework based on joint CTC/Attention E2E ASR with parallel streams represented by separate encoders aiming to capture diverse information. On top of the regular attention networks, the Hierarchical Attention Network (HAN) is introduced to steer the decoder toward the most informative encoders. A separate CTC network is assigned to each stream to force monotonic alignments. Two representative framework have been proposed and discussed, which are Multi-Encoder Multi-Resolution (MEM-Res) framework and Multi-Encoder Multi-Array (MEM-Array) framework, respectively. In MEM-Res framework, two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary information from same acoustics. Experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1% and the best WER of 3.6% in the WSJ eval92 test set. The MEM-Array framework aims at improving the far-field ASR robustness using multiple microphone arrays which are activated by separate encoders. Compared with the best single-array results, the proposed framework has achieved relative WER reduction of 3.7% and 9.7% in AMI and DIRHA multi-array corpora, respectively, which also outperforms conventional fusion strategies.