 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTA-Vid: Generalized Test-Time Adaptation for Video Reasoning
Apr 01, 2026Recent video reasoning models have shown strong results on temporal and multimodal understanding, yet they depend on large-scale supervised data and multi-stage training pipelines, making them costly to train and difficult to adapt to new domains. In this work, we leverage the paradigm of Test-Time Reinforcement Learning on video-language data to allow for adapting a pretrained model to incoming video samples at test-time without explicit labels. The proposed test-time adaptation for video approach (TTA-Vid) combines two components that work simultaneously: (1) a test-time adaptation that performs step-by-step reasoning at inference time on multiple frame subsets. We then use a batch-aware frequency-based reward computed across different frame subsets as pseudo ground truth to update the model. It shows that the resulting model trained on a single batch or even a single sample from a dataset, is able to generalize at test-time to the whole dataset and even across datasets. Because the adaptation occurs entirely at test time, our method requires no ground-truth annotations or dedicated training splits. Additionally, we propose a multi-armed bandit strategy for adaptive frame selection that learns to prioritize informative frames, guided by the same reward formulation. Our evaluation shows that TTA-Vid yields consistent improvements across various video reasoning tasks and is able to outperform current state-of-the-art methods trained on large-scale data. This highlights the potential of test-time reinforcement learning for temporal multimodal understanding.
CALM: Class-Conditional Sparse Attention Vectors for Large Audio-Language Models
Feb 06, 2026Large audio-language models (LALMs) exhibit strong zero-shot capabilities in multiple downstream tasks, such as audio question answering (AQA) and abstract reasoning; however, these models still lag behind specialized models for certain discriminative tasks (e.g., audio classification). Recent studies show that sparse subsets of attention heads within an LALM can serve as strong discriminative feature extractors for downstream tasks such as classification via simple voting schemes. However, these methods assign uniform weights to all selected heads, implicitly assuming that each head contributes equally across all semantic categories. In this work, we propose Class-Conditional Sparse Attention Vectors for Large Audio-Language Models, a few-shot classification method that learns class-dependent importance weights over attention heads. This formulation allows individual heads to specialize in distinct semantic categories and to contribute to ensemble predictions proportionally to their estimated reliability. Experiments on multiple few-shot audio and audiovisual classification benchmarks and tasks demonstrate that our method consistently outperforms state-of-the-art uniform voting-based approaches by up to 14.52%, 1.53%, 8.35% absolute gains for audio classification, audio-visual classification, and spoofing detection respectively.
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
May 02, 2025Recent advances in audio-visual learning have shown promising results in learning representations across modalities. However, most approaches rely on global audio representations that fail to capture fine-grained temporal correspondences with visual frames. Additionally, existing methods often struggle with conflicting optimization objectives when trying to jointly learn reconstruction and cross-modal alignment. In this work, we propose CAV-MAE Sync as a simple yet effective extension of the original CAV-MAE framework for self-supervised audio-visual learning. We address three key challenges: First, we tackle the granularity mismatch between modalities by treating audio as a temporal sequence aligned with video frames, rather than using global representations. Second, we resolve conflicting optimization goals by separating contrastive and reconstruction objectives through dedicated global tokens. Third, we improve spatial localization by introducing learnable register tokens that reduce semantic load on patch tokens. We evaluate the proposed approach on AudioSet, VGG Sound, and the ADE20K Sound dataset on zero-shot retrieval, classification and localization tasks demonstrating state-of-the-art performance and outperforming more complex architectures.
Can Diffusion Models Disentangle? A Theoretical Perspective
Mar 31, 2025This paper presents a novel theoretical framework for understanding how diffusion models can learn disentangled representations. Within this framework, we establish identifiability conditions for general disentangled latent variable models, analyze training dynamics, and derive sample complexity bounds for disentangled latent subspace models. To validate our theory, we conduct disentanglement experiments across diverse tasks and modalities, including subspace recovery in latent subspace Gaussian mixture models, image colorization, image denoising, and voice conversion for speech classification. Additionally, our experiments show that training strategies inspired by our theory, such as style guidance regularization, consistently enhance disentanglement performance.
DinoSR: Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning
May 17, 2023



In this paper, we introduce self-distillation and online clustering for self-supervised speech representation learning (DinoSR) which combines masked language modeling, self-distillation, and online clustering. We show that these concepts complement each other and result in a strong representation learning model for speech. DinoSR first extracts contextualized embeddings from the input audio with a teacher network, then runs an online clustering system on the embeddings to yield a machine-discovered phone inventory, and finally uses the discretized tokens to guide a student network. We show that DinoSR surpasses previous state-of-the-art performance in several downstream tasks, and provide a detailed analysis of the model and the learned discrete units. The source code will be made available after the anonymity period.
Learning Word-Like Units from Joint Audio-Visual Analysis
May 24, 2017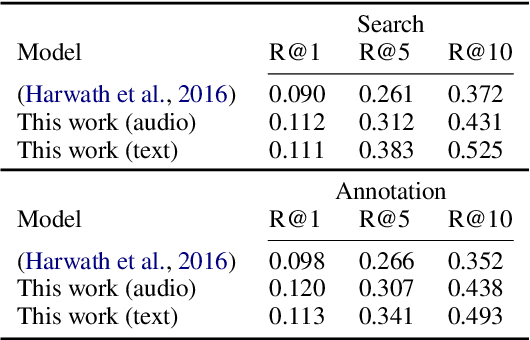

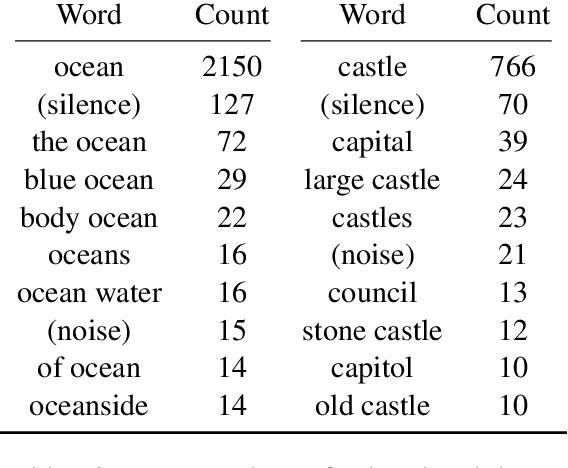
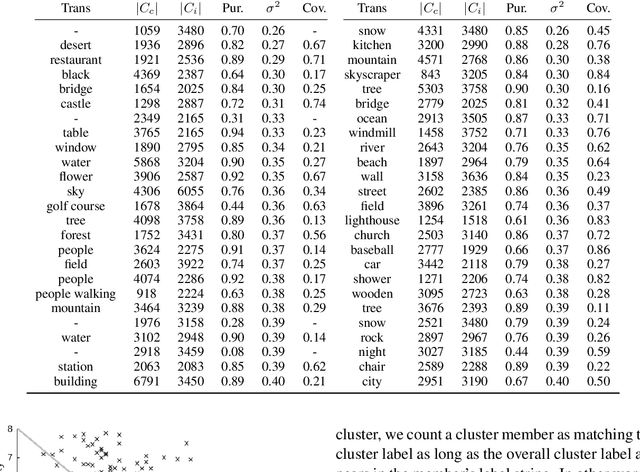
Given a collection of images and spoken audio captions, we present a method for discovering word-like acoustic units in the continuous speech signal and grounding them to semantically relevant image regions. For example, our model is able to detect spoken instances of the word 'lighthouse' within an utterance and associate them with image regions containing lighthouses. We do not use any form of conventional automatic speech recognition, nor do we use any text transcriptions or conventional linguistic annotations. Our model effectively implements a form of spoken language acquisition, in which the computer learns not only to recognize word categories by sound, but also to enrich the words it learns with semantics by grounding them in images.