 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble prosody prediction for expressive speech synthesis
Apr 03, 2023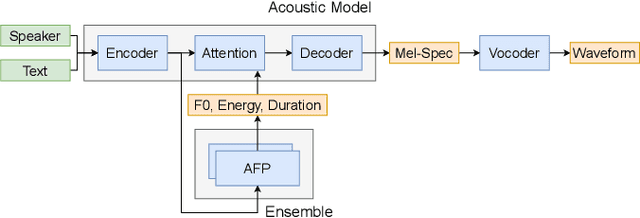

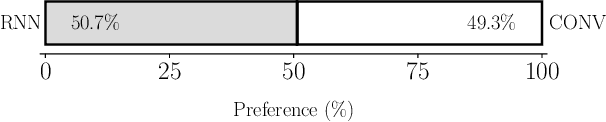

Generating expressive speech with rich and varied prosody continues to be a challenge for Text-to-Speech. Most efforts have focused on sophisticated neural architectures intended to better model the data distribution. Yet, in evaluations it is generally found that no single model is preferred for all input texts. This suggests an approach that has rarely been used before for Text-to-Speech: an ensemble of models. We apply ensemble learning to prosody prediction. We construct simple ensembles of prosody predictors by varying either model architecture or model parameter values. To automatically select amongst the models in the ensemble when performing Text-to-Speech, we propose a novel, and computationally trivial, variance-based criterion. We demonstrate that even a small ensemble of prosody predictors yields useful diversity, which, combined with the proposed selection criterion, outperforms any individual model from the ensemble.
Controlling High-Dimensional Data With Sparse Input
Mar 14, 2023We address the problem of human-in-the-loop control for generating highly-structured data. This task is challenging because existing generative models lack an efficient interface through which users can modify the output. Users have the option to either manually explore a non-interpretable latent space, or to laboriously annotate the data with conditioning labels. To solve this, we introduce a novel framework whereby an encoder maps a sparse, human interpretable control space onto the latent space of a generative model. We apply this framework to the task of controlling prosody in text-to-speech synthesis. We propose a model, called Multiple-Instance CVAE (MICVAE), that is specifically designed to encode sparse prosodic features and output complete waveforms. We show empirically that MICVAE displays desirable qualities of a sparse human-in-the-loop control mechanism: efficiency, robustness, and faithfulness. With even a very small number of input values (~4), MICVAE enables users to improve the quality of the output significantly, in terms of listener preference (4:1).
Prosodic Representation Learning and Contextual Sampling for Neural Text-to-Speech
Nov 04, 2020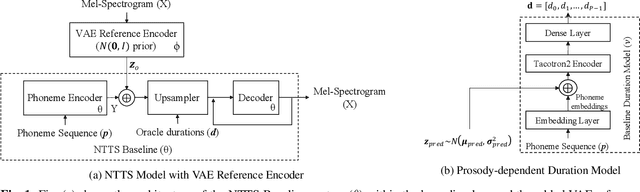
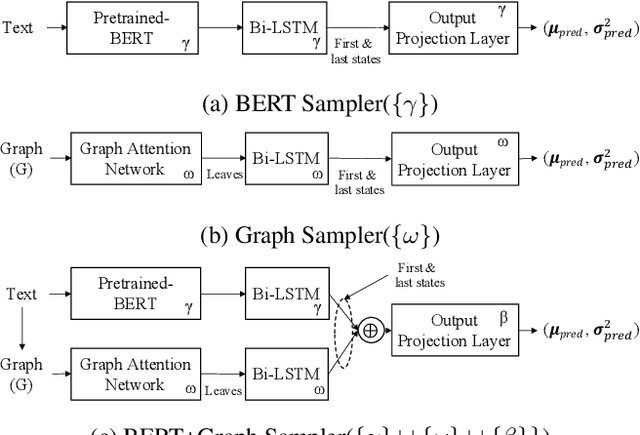
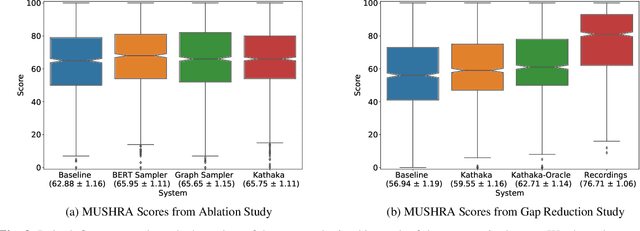
In this paper, we introduce Kathaka, a model trained with a novel two-stage training process for neural speech synthesis with contextually appropriate prosody. In Stage I, we learn a prosodic distribution at the sentence level from mel-spectrograms available during training. In Stage II, we propose a novel method to sample from this learnt prosodic distribution using the contextual information available in text. To do this, we use BERT on text, and graph-attention networks on parse trees extracted from text. We show a statistically significant relative improvement of $13.2\%$ in naturalness over a strong baseline when compared to recordings. We also conduct an ablation study on variations of our sampling technique, and show a statistically significant improvement over the baseline in each case.
Perception of prosodic variation for speech synthesis using an unsupervised discrete representation of F0
Mar 14, 2020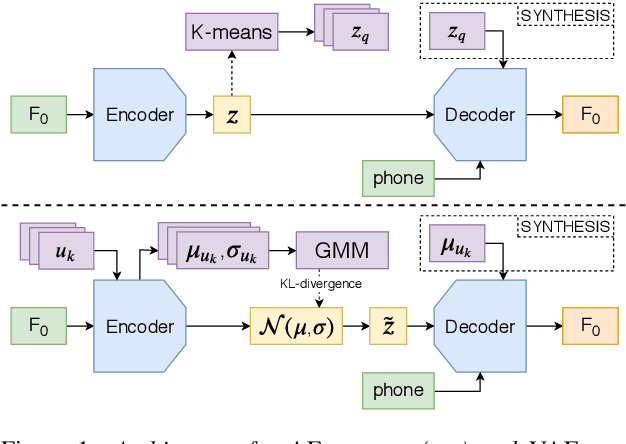

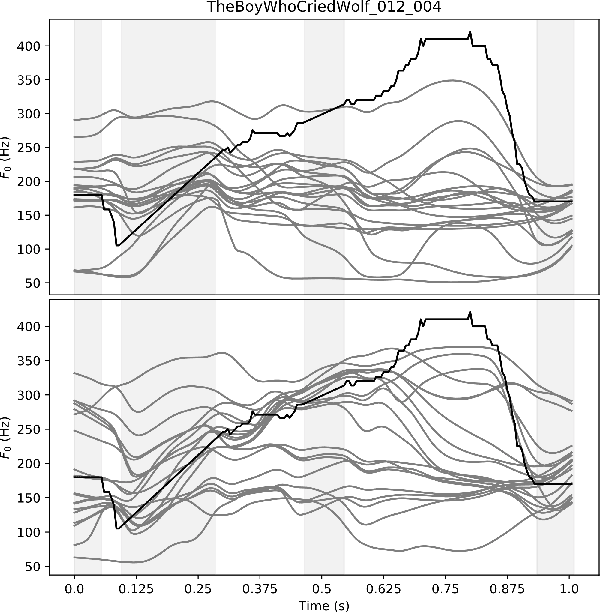
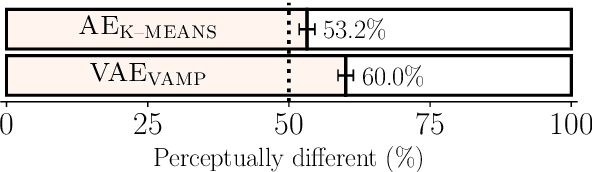
In English, prosody adds a broad range of information to segment sequences, from information structure (e.g. contrast) to stylistic variation (e.g. expression of emotion). However, when learning to control prosody in text-to-speech voices, it is not clear what exactly the control is modifying. Existing research on discrete representation learning for prosody has demonstrated high naturalness, but no analysis has been performed on what these representations capture, or if they can generate meaningfully-distinct variants of an utterance. We present a phrase-level variational autoencoder with a multi-modal prior, using the mode centres as "intonation codes". Our evaluation establishes which intonation codes are perceptually distinct, finding that the intonation codes from our multi-modal latent model were significantly more distinct than a baseline using k-means clustering. We carry out a follow-up qualitative study to determine what information the codes are carrying. Most commonly, listeners commented on the intonation codes having a statement or question style. However, many other affect-related styles were also reported, including: emotional, uncertain, surprised, sarcastic, passive aggressive, and upset.
Using generative modelling to produce varied intonation for speech synthesis
Jun 10, 2019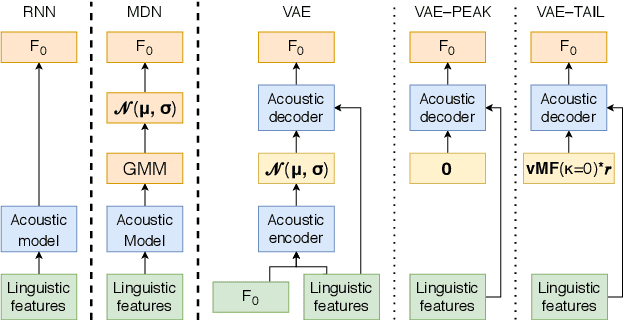
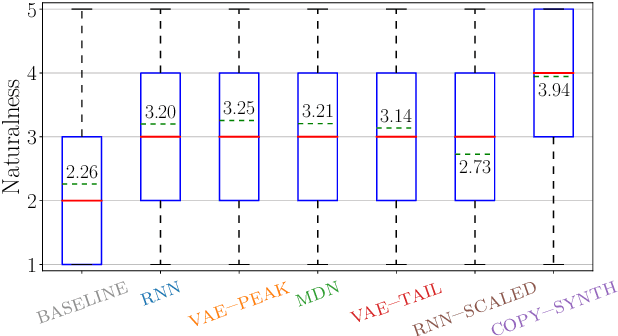
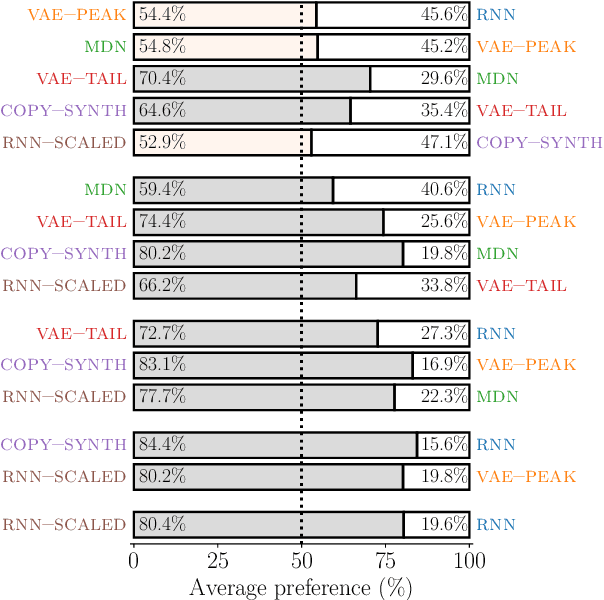

Unlike human speakers, typical text-to-speech (TTS) systems are unable to produce multiple distinct renditions of a given sentence. This has previously been addressed by adding explicit external control. In contrast, generative models are able to capture a distribution over multiple renditions and thus produce varied renditions using sampling. Typical neural TTS models learn the average of the data because they minimise mean squared error. In the context of prosody, taking the average produces flatter, more boring speech: an "average prosody". A generative model that can synthesise multiple prosodies will, by design, not model average prosody. We use variational autoencoders (VAE) which explicitly place the most "average" data close to the mean of the Gaussian prior. We propose that by moving towards the tails of the prior distribution, the model will transition towards generating more idiosyncratic, varied renditions. Focusing here on intonation, we investigate the trade-off between naturalness and intonation variation and find that typical acoustic models can either be natural, or varied, but not both. However, sampling from the tails of the VAE prior produces much more varied intonation than the traditional approaches, whilst maintaining the same level of naturalness.