 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ELITR-Bench: A Meeting Assistant Benchmark for Long-Context Language Models
Mar 29, 2024
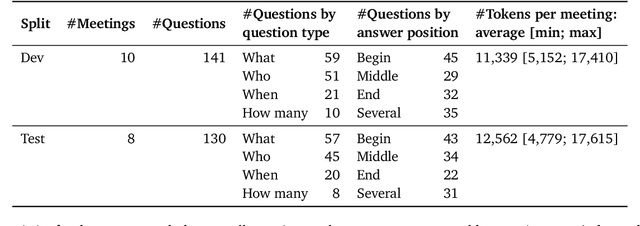
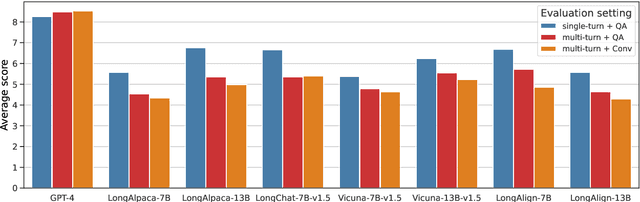
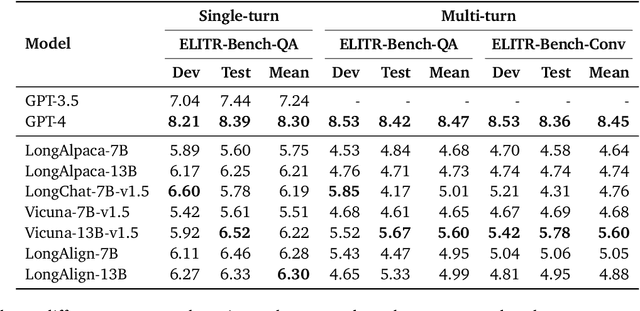
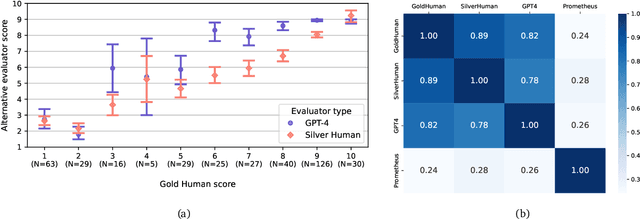
Research on Large Language Models (LLMs) has recently witnessed an increasing interest in extending models' context size to better capture dependencies within long documents. While benchmarks have been proposed to assess long-range abilities, existing efforts primarily considered generic tasks that are not necessarily aligned with real-world applications. In contrast, our work proposes a new benchmark for long-context LLMs focused on a practical meeting assistant scenario. In this scenario, the long contexts consist of transcripts obtained by automatic speech recognition, presenting unique challenges for LLMs due to the inherent noisiness and oral nature of such data. Our benchmark, named ELITR-Bench, augments the existing ELITR corpus' transcripts with 271 manually crafted questions and their ground-truth answers. Our experiments with recent long-context LLMs on ELITR-Bench highlight a gap between open-source and proprietary models, especially when questions are asked sequentially within a conversation. We also provide a thorough analysis of our GPT-4-based evaluation method, encompassing insights from a crowdsourcing study. Our findings suggest that while GPT-4's evaluation scores are correlated with human judges', its ability to differentiate among more than three score levels may be limited.
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Mar 21, 2024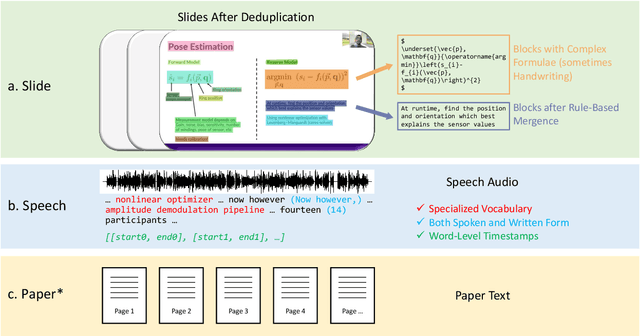
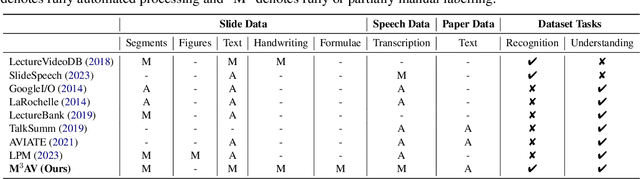
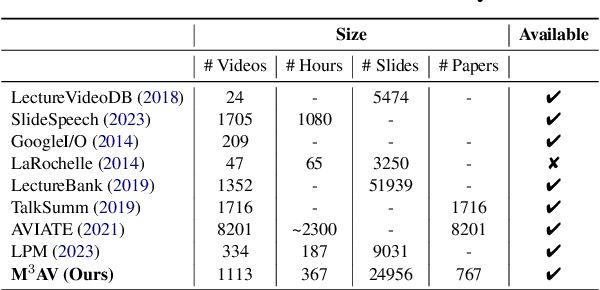
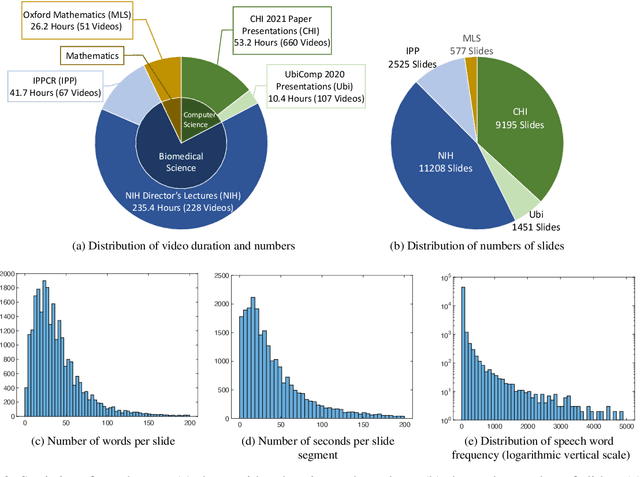
Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the spoken and written words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.
Text-guided HuBERT: Self-Supervised Speech Pre-training via Generative Adversarial Networks
Feb 28, 2024Human language can be expressed in either written or spoken form, i.e. text or speech. Humans can acquire knowledge from text to improve speaking and listening. However, the quest for speech pre-trained models to leverage unpaired text has just started. In this paper, we investigate a new way to pre-train such a joint speech-text model to learn enhanced speech representations and benefit various speech-related downstream tasks. Specifically, we propose a novel pre-training method, text-guided HuBERT, or T-HuBERT, which performs self-supervised learning over speech to derive phoneme-like discrete representations. And these phoneme-like pseudo-label sequences are firstly derived from speech via the generative adversarial networks (GAN) to be statistically similar to those from additional unpaired textual data. In this way, we build a bridge between unpaired speech and text in an unsupervised manner. Extensive experiments demonstrate the significant superiority of our proposed method over various strong baselines, which achieves up to 15.3% relative Word Error Rate (WER) reduction on the LibriSpeech dataset.
NatSGD: A Dataset with Speech, Gestures, and Demonstrations for Robot Learning in Natural Human-Robot Interaction
Mar 04, 2024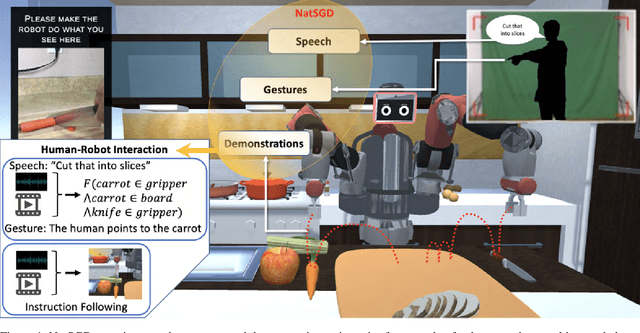

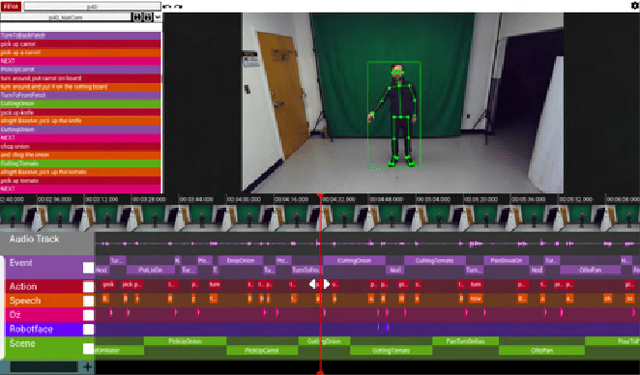

Recent advancements in multimodal Human-Robot Interaction (HRI) datasets have highlighted the fusion of speech and gesture, expanding robots' capabilities to absorb explicit and implicit HRI insights. However, existing speech-gesture HRI datasets often focus on elementary tasks, like object pointing and pushing, revealing limitations in scaling to intricate domains and prioritizing human command data over robot behavior records. To bridge these gaps, we introduce NatSGD, a multimodal HRI dataset encompassing human commands through speech and gestures that are natural, synchronized with robot behavior demonstrations. NatSGD serves as a foundational resource at the intersection of machine learning and HRI research, and we demonstrate its effectiveness in training robots to understand tasks through multimodal human commands, emphasizing the significance of jointly considering speech and gestures. We have released our dataset, simulator, and code to facilitate future research in human-robot interaction system learning; access these resources at https://www.snehesh.com/natsgd/
KunquDB: An Attempt for Speaker Verification in the Chinese Opera Scenario
Mar 20, 2024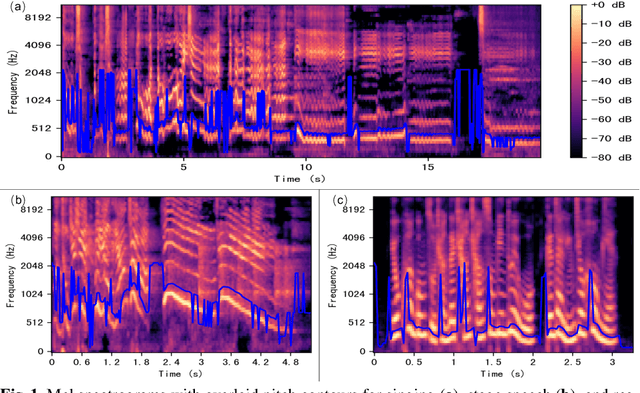
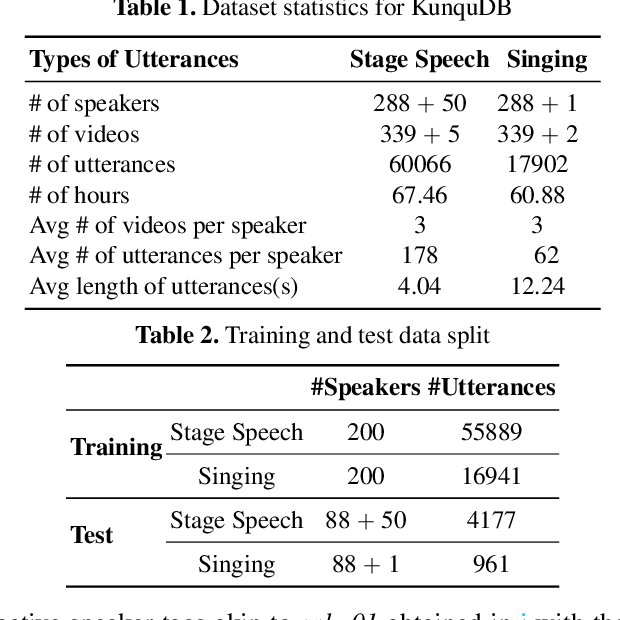
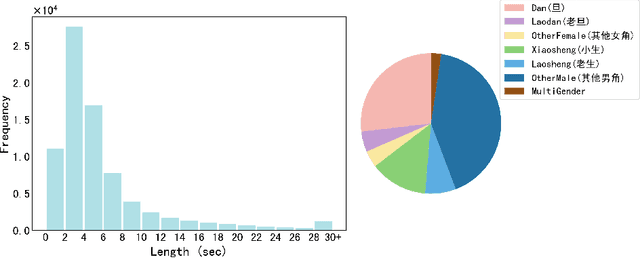
This work aims to promote Chinese opera research in both musical and speech domains, with a primary focus on overcoming the data limitations. We introduce KunquDB, a relatively large-scale, well-annotated audio-visual dataset comprising 339 speakers and 128 hours of content. Originating from the Kunqu Opera Art Canon (Kunqu yishu dadian), KunquDB is meticulously structured by dialogue lines, providing explicit annotations including character names, speaker names, gender information, vocal manner classifications, and accompanied by preliminary text transcriptions. KunquDB provides a versatile foundation for role-centric acoustic studies and advancements in speech-related research, including Automatic Speaker Verification (ASV). Beyond enriching opera research, this dataset bridges the gap between artistic expression and technological innovation. Pioneering the exploration of ASV in Chinese opera, we construct four test trials considering two distinct vocal manners in opera voices: stage speech (ST) and singing (S). Implementing domain adaptation methods effectively mitigates domain mismatches induced by these vocal manner variations while there is still room for further improvement as a benchmark.
Direct Punjabi to English speech translation using discrete units
Feb 25, 2024Speech-to-speech translation is yet to reach the same level of coverage as text-to-text translation systems. The current speech technology is highly limited in its coverage of over 7000 languages spoken worldwide, leaving more than half of the population deprived of such technology and shared experiences. With voice-assisted technology (such as social robots and speech-to-text apps) and auditory content (such as podcasts and lectures) on the rise, ensuring that the technology is available for all is more important than ever. Speech translation can play a vital role in mitigating technological disparity and creating a more inclusive society. With a motive to contribute towards speech translation research for low-resource languages, our work presents a direct speech-to-speech translation model for one of the Indic languages called Punjabi to English. Additionally, we explore the performance of using a discrete representation of speech called discrete acoustic units as input to the Transformer-based translation model. The model, abbreviated as Unit-to-Unit Translation (U2UT), takes a sequence of discrete units of the source language (the language being translated from) and outputs a sequence of discrete units of the target language (the language being translated to). Our results show that the U2UT model performs better than the Speech-to-Unit Translation (S2UT) model by a 3.69 BLEU score.
Multilingual Speech Models for Automatic Speech Recognition Exhibit Gender Performance Gaps
Feb 28, 2024Current voice recognition approaches use multi-task, multilingual models for speech tasks like Automatic Speech Recognition (ASR) to make them applicable to many languages without substantial changes. However, broad language coverage can still mask performance gaps within languages, for example, across genders. We systematically evaluate multilingual ASR systems on gendered performance gaps. Using two popular models on three datasets in 19 languages across seven language families, we find clear gender disparities. However, the advantaged group varies between languages. While there are no significant differences across groups in phonetic variables (pitch, speaking rate, etc.), probing the model's internal states reveals a negative correlation between probe performance and the gendered performance gap. I.e., the easier to distinguish speaker gender in a language, the more the models favor female speakers. Our results show that group disparities remain unsolved despite great progress on multi-tasking and multilinguality. We provide first valuable insights for evaluating gender gaps in multilingual ASR systems. We release all code and artifacts at https://github.com/g8a9/multilingual-asr-gender-gap.
VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis
Mar 01, 2024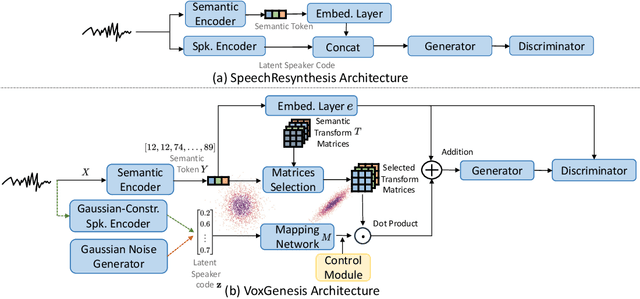
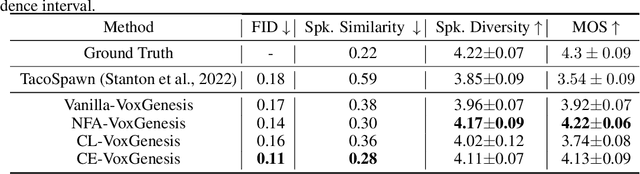
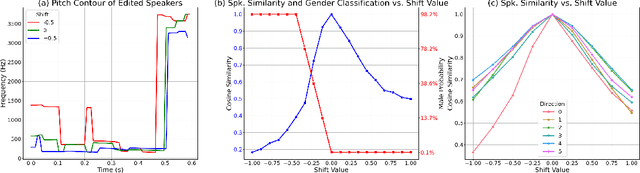

Achieving nuanced and accurate emulation of human voice has been a longstanding goal in artificial intelligence. Although significant progress has been made in recent years, the mainstream of speech synthesis models still relies on supervised speaker modeling and explicit reference utterances. However, there are many aspects of human voice, such as emotion, intonation, and speaking style, for which it is hard to obtain accurate labels. In this paper, we propose VoxGenesis, a novel unsupervised speech synthesis framework that can discover a latent speaker manifold and meaningful voice editing directions without supervision. VoxGenesis is conceptually simple. Instead of mapping speech features to waveforms deterministically, VoxGenesis transforms a Gaussian distribution into speech distributions conditioned and aligned by semantic tokens. This forces the model to learn a speaker distribution disentangled from the semantic content. During the inference, sampling from the Gaussian distribution enables the creation of novel speakers with distinct characteristics. More importantly, the exploration of latent space uncovers human-interpretable directions associated with specific speaker characteristics such as gender attributes, pitch, tone, and emotion, allowing for voice editing by manipulating the latent codes along these identified directions. We conduct extensive experiments to evaluate the proposed VoxGenesis using both subjective and objective metrics, finding that it produces significantly more diverse and realistic speakers with distinct characteristics than the previous approaches. We also show that latent space manipulation produces consistent and human-identifiable effects that are not detrimental to the speech quality, which was not possible with previous approaches. Audio samples of VoxGenesis can be found at: \url{https://bit.ly/VoxGenesis}.
Exploring language relations through syntactic distances and geographic proximity
Mar 27, 2024Languages are grouped into families that share common linguistic traits. While this approach has been successful in understanding genetic relations between diverse languages, more analyses are needed to accurately quantify their relatedness, especially in less studied linguistic levels such as syntax. Here, we explore linguistic distances using series of parts of speech (POS) extracted from the Universal Dependencies dataset. Within an information-theoretic framework, we show that employing POS trigrams maximizes the possibility of capturing syntactic variations while being at the same time compatible with the amount of available data. Linguistic connections are then established by assessing pairwise distances based on the POS distributions. Intriguingly, our analysis reveals definite clusters that correspond to well known language families and groups, with exceptions explained by distinct morphological typologies. Furthermore, we obtain a significant correlation between language similarity and geographic distance, which underscores the influence of spatial proximity on language kinships.
Advanced Artificial Intelligence Algorithms in Cochlear Implants: Review of Healthcare Strategies, Challenges, and Perspectives
Mar 17, 2024Automatic speech recognition (ASR) plays a pivotal role in our daily lives, offering utility not only for interacting with machines but also for facilitating communication for individuals with either partial or profound hearing impairments. The process involves receiving the speech signal in analogue form, followed by various signal processing algorithms to make it compatible with devices of limited capacity, such as cochlear implants (CIs). Unfortunately, these implants, equipped with a finite number of electrodes, often result in speech distortion during synthesis. Despite efforts by researchers to enhance received speech quality using various state-of-the-art signal processing techniques, challenges persist, especially in scenarios involving multiple sources of speech, environmental noise, and other circumstances. The advent of new artificial intelligence (AI) methods has ushered in cutting-edge strategies to address the limitations and difficulties associated with traditional signal processing techniques dedicated to CIs. This review aims to comprehensively review advancements in CI-based ASR and speech enhancement, among other related aspects. The primary objective is to provide a thorough overview of metrics and datasets, exploring the capabilities of AI algorithms in this biomedical field, summarizing and commenting on the best results obtained. Additionally, the review will delve into potential applications and suggest future directions to bridge existing research gaps in this domain.