 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonological distances for linguistic typology and the origin of Indo-European languages
Apr 13, 2026We show that short-range phoneme dependencies encode large-scale patterns of linguistic relatedness, with direct implications for quantitative typology and evolutionary linguistics. Specifically, using an information-theoretic framework, we argue that phoneme sequences modeled as second-order Markov chains essentially capture the statistical correlations of a phonological system. This finding enables us to quantify distances among 67 modern languages from a multilingual parallel corpus employing a distance metric that incorporates articulatory features of phonemes. The resulting phonological distance matrix recovers major language families and reveals signatures of contact-induced convergence. Remarkably, we obtain a clear correlation with geographic distance, allowing us to constrain a plausible homeland region for the Indo-European family, consistent with the Steppe hypothesis.
Exploring language relations through syntactic distances and geographic proximity
Mar 27, 2024Languages are grouped into families that share common linguistic traits. While this approach has been successful in understanding genetic relations between diverse languages, more analyses are needed to accurately quantify their relatedness, especially in less studied linguistic levels such as syntax. Here, we explore linguistic distances using series of parts of speech (POS) extracted from the Universal Dependencies dataset. Within an information-theoretic framework, we show that employing POS trigrams maximizes the possibility of capturing syntactic variations while being at the same time compatible with the amount of available data. Linguistic connections are then established by assessing pairwise distances based on the POS distributions. Intriguingly, our analysis reveals definite clusters that correspond to well known language families and groups, with exceptions explained by distinct morphological typologies. Furthermore, we obtain a significant correlation between language similarity and geographic distance, which underscores the influence of spatial proximity on language kinships.
Universality and diversity in word patterns
Aug 23, 2022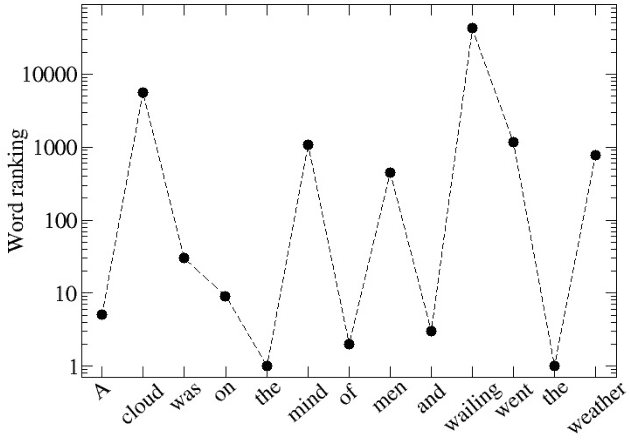
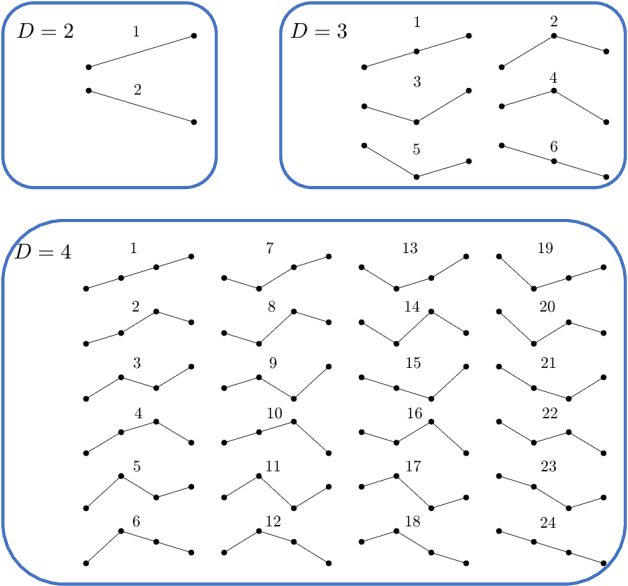
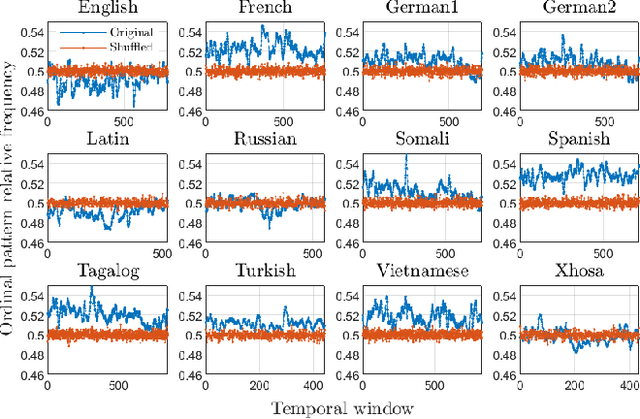
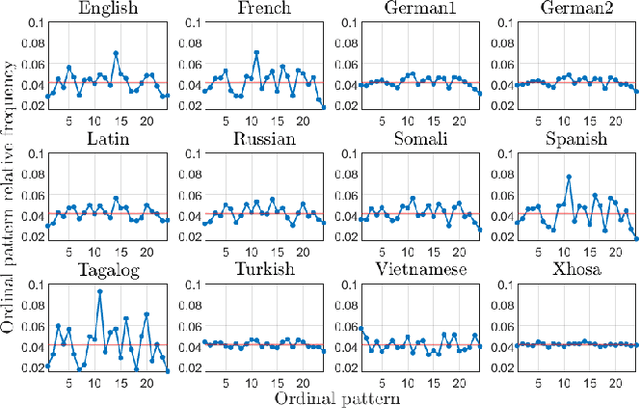
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.