 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Transcribing Educational Videos Using Whisper: A preliminary study on using AI for transcribing educational videos
Jul 04, 2023
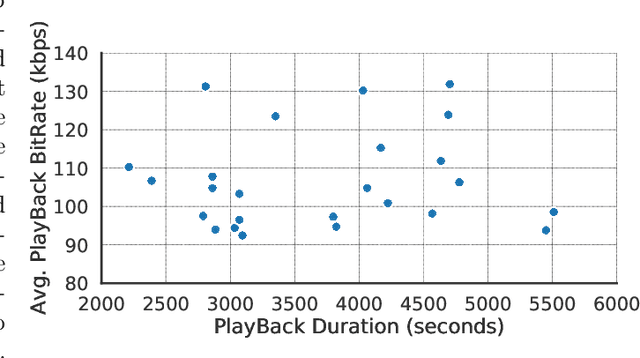

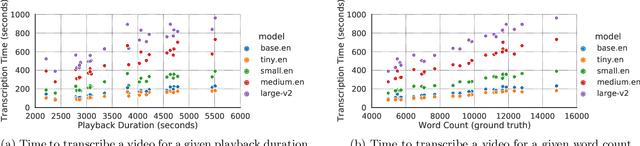
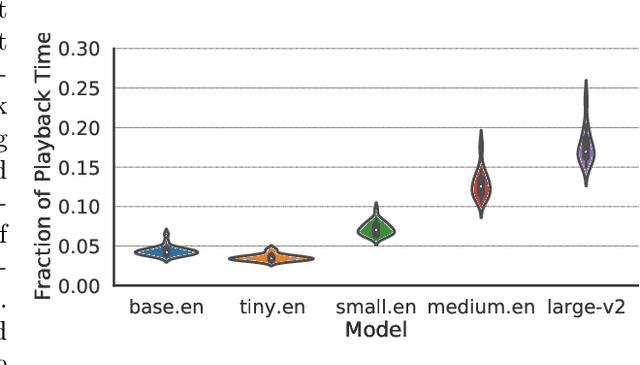
Videos are increasingly being used for e-learning, and transcripts are vital to enhance the learning experience. The costs and delays of generating transcripts can be alleviated by automatic speech recognition (ASR) systems. In this article, we quantify the transcripts generated by whisper for 25 educational videos and identify some open avenues of research when leveraging ASR for transcribing educational videos.
Improving Continuous Sign Language Recognition with Cross-Lingual Signs
Aug 21, 2023



This work dedicates to continuous sign language recognition (CSLR), which is a weakly supervised task dealing with the recognition of continuous signs from videos, without any prior knowledge about the temporal boundaries between consecutive signs. Data scarcity heavily impedes the progress of CSLR. Existing approaches typically train CSLR models on a monolingual corpus, which is orders of magnitude smaller than that of speech recognition. In this work, we explore the feasibility of utilizing multilingual sign language corpora to facilitate monolingual CSLR. Our work is built upon the observation of cross-lingual signs, which originate from different sign languages but have similar visual signals (e.g., hand shape and motion). The underlying idea of our approach is to identify the cross-lingual signs in one sign language and properly leverage them as auxiliary training data to improve the recognition capability of another. To achieve the goal, we first build two sign language dictionaries containing isolated signs that appear in two datasets. Then we identify the sign-to-sign mappings between two sign languages via a well-optimized isolated sign language recognition model. At last, we train a CSLR model on the combination of the target data with original labels and the auxiliary data with mapped labels. Experimentally, our approach achieves state-of-the-art performance on two widely-used CSLR datasets: Phoenix-2014 and Phoenix-2014T.
Syllable Subword Tokens for Open Vocabulary Speech Recognition in Malayalam
Jan 17, 2023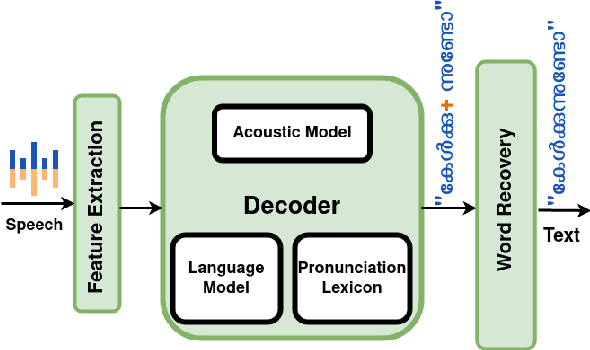

In a hybrid automatic speech recognition (ASR) system, a pronunciation lexicon (PL) and a language model (LM) are essential to correctly retrieve spoken word sequences. Being a morphologically complex language, the vocabulary of Malayalam is so huge and it is impossible to build a PL and an LM that cover all diverse word forms. Usage of subword tokens to build PL and LM, and combining them to form words after decoding, enables the recovery of many out of vocabulary words. In this work we investigate the impact of using syllables as subword tokens instead of words in Malayalam ASR, and evaluate the relative improvement in lexicon size, model memory requirement and word error rate.
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 17, 2023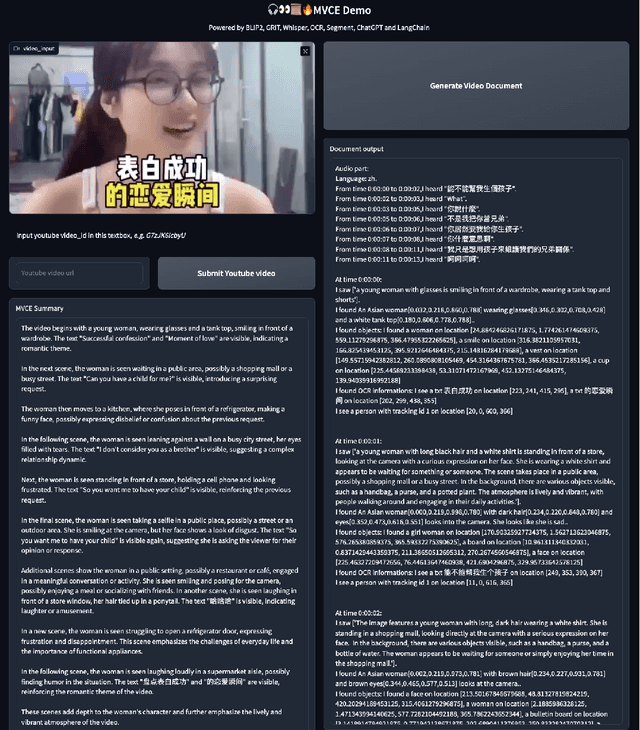
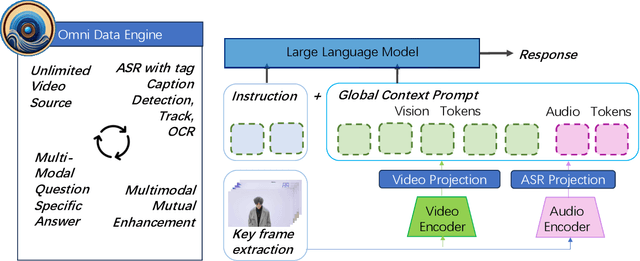

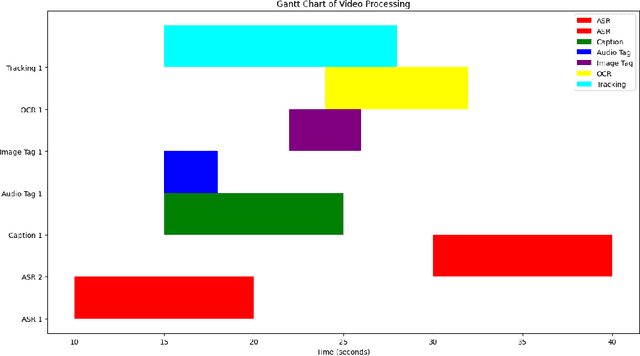
This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
ApproBiVT: Lead ASR Models to Generalize Better Using Approximated Bias-Variance Tradeoff Guided Early Stopping and Checkpoint Averaging
Aug 05, 2023
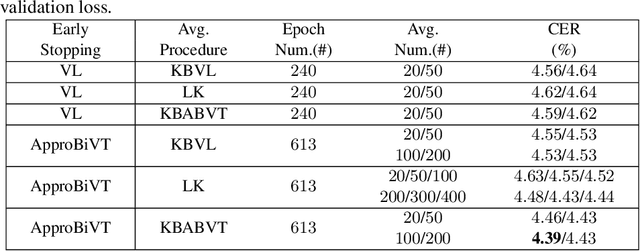
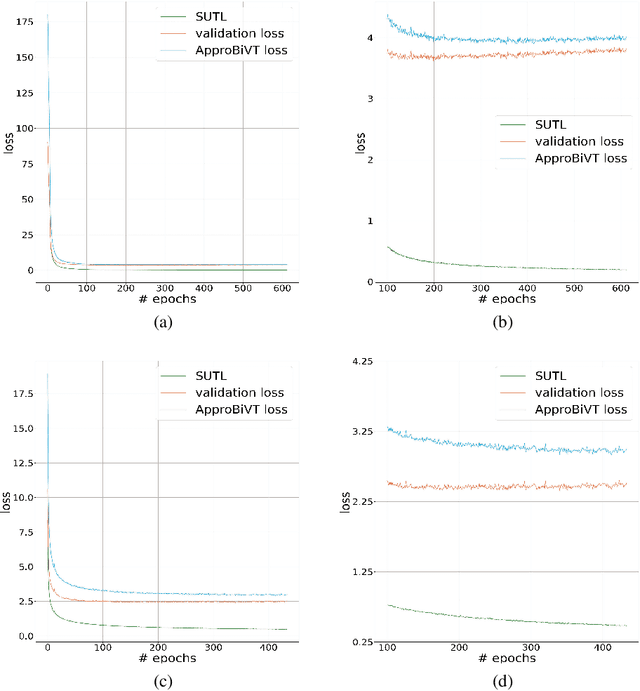
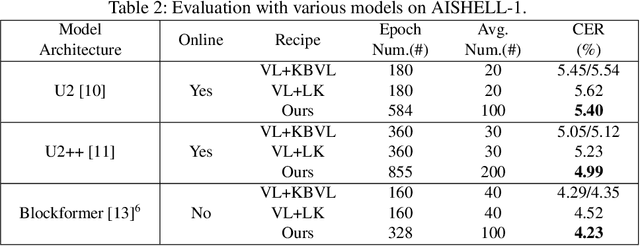
The conventional recipe for Automatic Speech Recognition (ASR) models is to 1) train multiple checkpoints on a training set while relying on a validation set to prevent overfitting using early stopping and 2) average several last checkpoints or that of the lowest validation losses to obtain the final model. In this paper, we rethink and update the early stopping and checkpoint averaging from the perspective of the bias-variance tradeoff. Theoretically, the bias and variance represent the fitness and variability of a model and the tradeoff of them determines the overall generalization error. But, it's impractical to evaluate them precisely. As an alternative, we take the training loss and validation loss as proxies of bias and variance and guide the early stopping and checkpoint averaging using their tradeoff, namely an Approximated Bias-Variance Tradeoff (ApproBiVT). When evaluating with advanced ASR models, our recipe provides 2.5%-3.7% and 3.1%-4.6% CER reduction on the AISHELL-1 and AISHELL-2, respectively.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
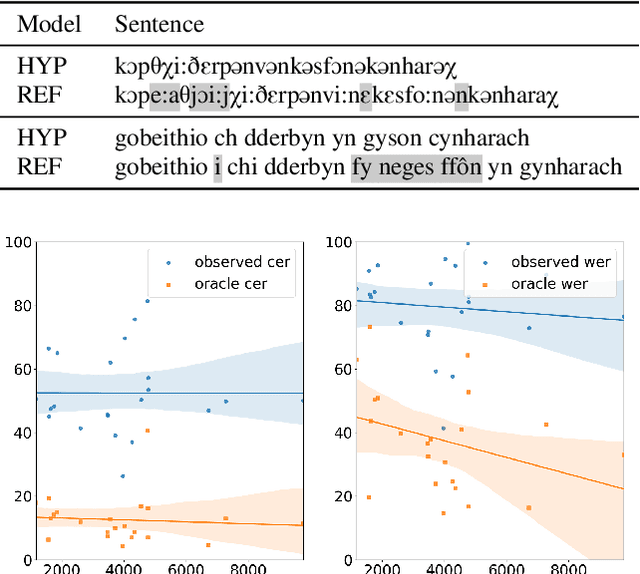
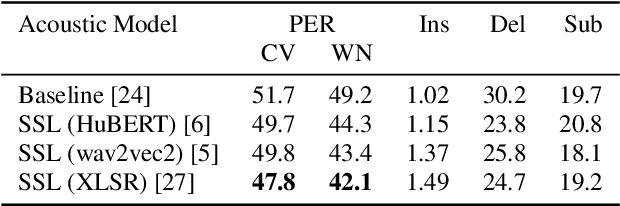
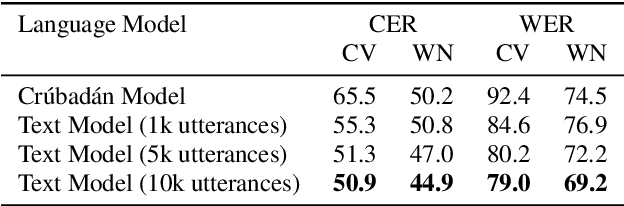
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
Continual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 02, 2022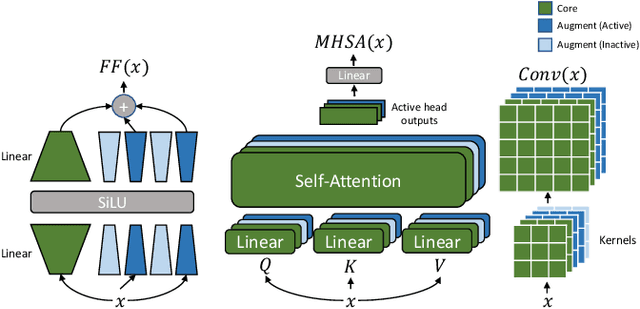
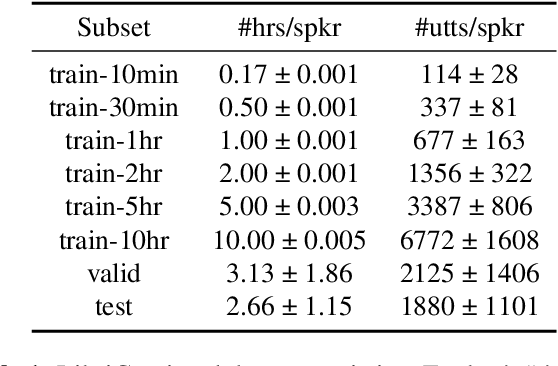
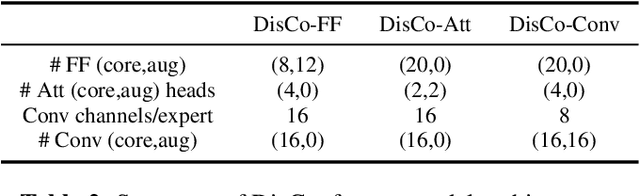
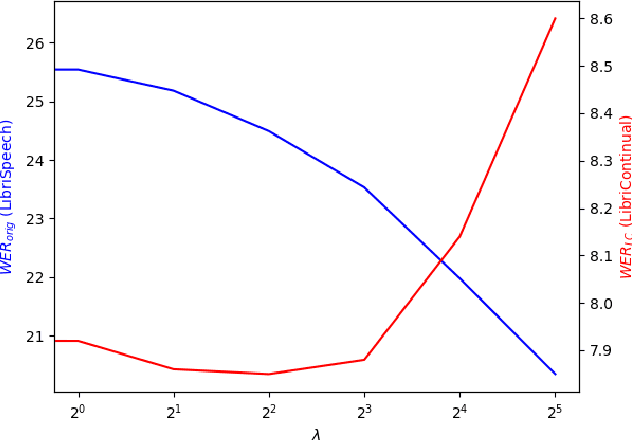
Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
LAMASSU: Streaming Language-Agnostic Multilingual Speech Recognition and Translation Using Neural Transducers
Nov 05, 2022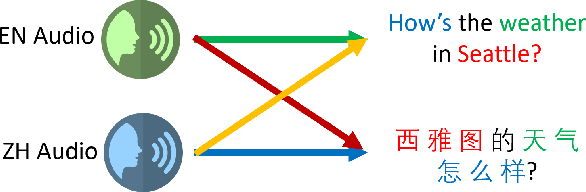
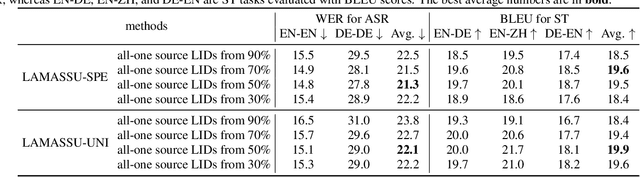
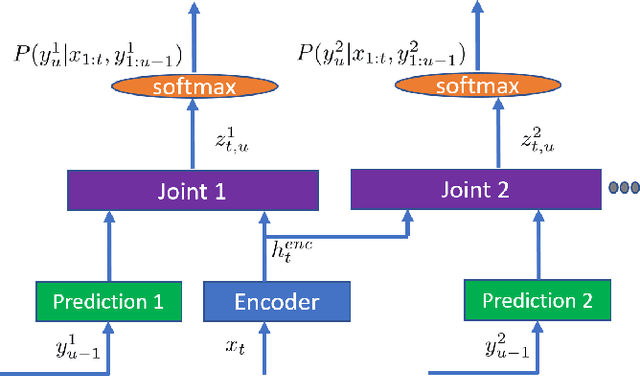
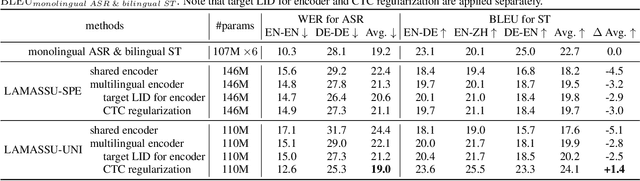
End-to-end formulation of automatic speech recognition (ASR) and speech translation (ST) makes it easy to use a single model for both multilingual ASR and many-to-many ST. In this paper, we propose streaming language-agnostic multilingual speech recognition and translation using neural transducers (LAMASSU). To enable multilingual text generation in LAMASSU, we conduct a systematic comparison between specified and unified prediction and joint networks. We leverage a language-agnostic multilingual encoder that substantially outperforms shared encoders. To enhance LAMASSU, we propose to feed target LID to encoders. We also apply connectionist temporal classification regularization to transducer training. Experimental results show that LAMASSU not only drastically reduces the model size but also outperforms monolingual ASR and bilingual ST models.
Speaker Diarization of Scripted Audiovisual Content
Aug 04, 2023The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023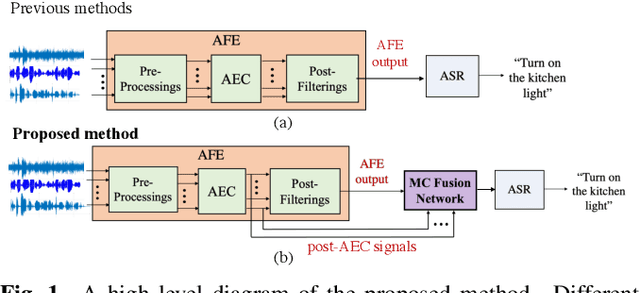

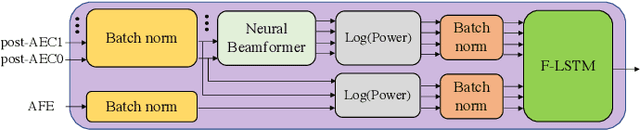
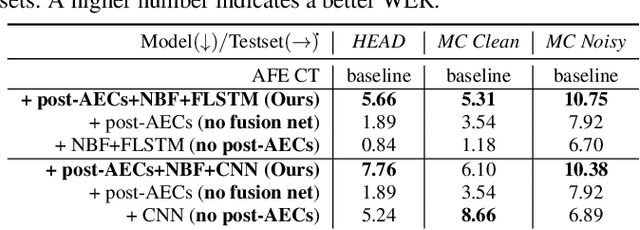
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.