 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speech Diarization and ASR with GMM
Jul 11, 2023

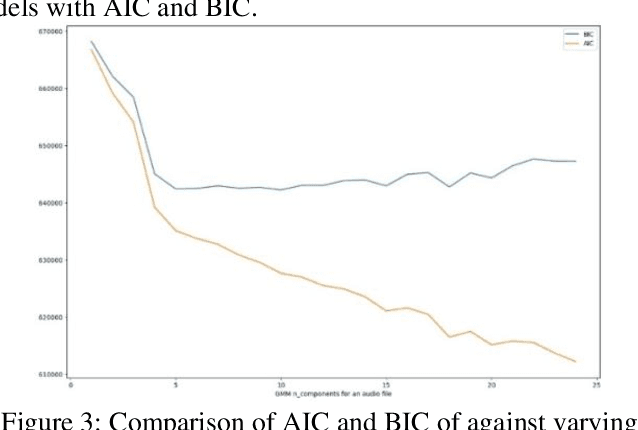
In this research paper, we delve into the topics of Speech Diarization and Automatic Speech Recognition (ASR). Speech diarization involves the separation of individual speakers within an audio stream. By employing the ASR transcript, the diarization process aims to segregate each speaker's utterances, grouping them based on their unique audio characteristics. On the other hand, Automatic Speech Recognition refers to the capability of a machine or program to identify and convert spoken words and phrases into a machine-readable format. In our speech diarization approach, we utilize the Gaussian Mixer Model (GMM) to represent speech segments. The inter-cluster distance is computed based on the GMM parameters, and the distance threshold serves as the stopping criterion. ASR entails the conversion of an unknown speech waveform into a corresponding written transcription. The speech signal is analyzed using synchronized algorithms, taking into account the pitch frequency. Our primary objective typically revolves around developing a model that minimizes the Word Error Rate (WER) metric during speech transcription.
Meeting Recognition with Continuous Speech Separation and Transcription-Supported Diarization
Sep 28, 2023
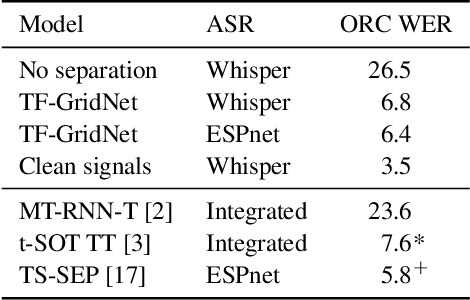

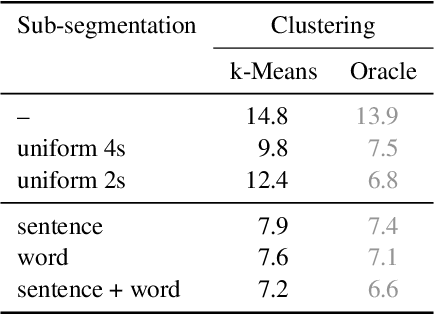
We propose a modular pipeline for the single-channel separation, recognition, and diarization of meeting-style recordings and evaluate it on the Libri-CSS dataset. Using a Continuous Speech Separation (CSS) system with a TF-GridNet separation architecture, followed by a speaker-agnostic speech recognizer, we achieve state-of-the-art recognition performance in terms of Optimal Reference Combination Word Error Rate (ORC WER). Then, a d-vector-based diarization module is employed to extract speaker embeddings from the enhanced signals and to assign the CSS outputs to the correct speaker. Here, we propose a syntactically informed diarization using sentence- and word-level boundaries of the ASR module to support speaker turn detection. This results in a state-of-the-art Concatenated minimum-Permutation Word Error Rate (cpWER) for the full meeting recognition pipeline.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023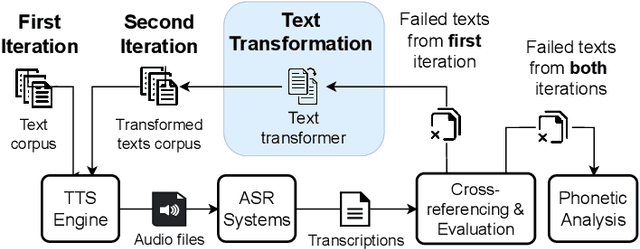
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.
Crowdsourced and Automatic Speech Prominence Estimation
Oct 12, 2023
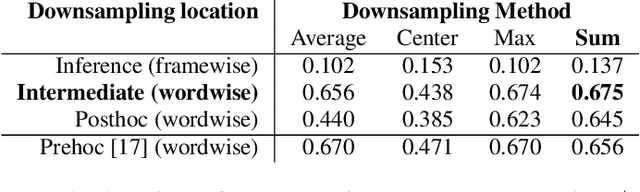
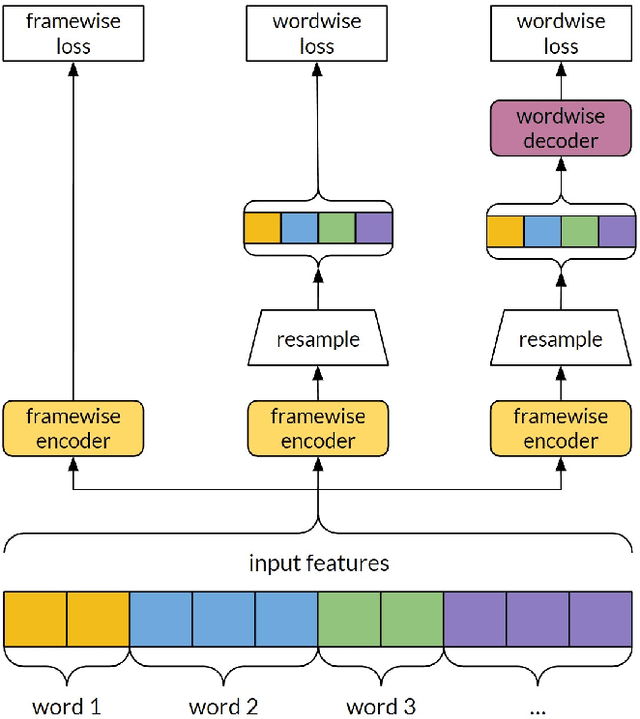
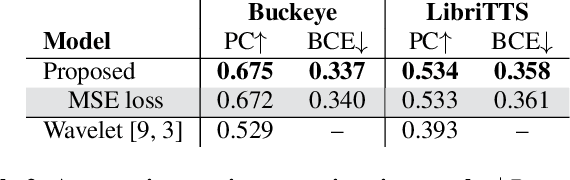
The prominence of a spoken word is the degree to which an average native listener perceives the word as salient or emphasized relative to its context. Speech prominence estimation is the process of assigning a numeric value to the prominence of each word in an utterance. These prominence labels are useful for linguistic analysis, as well as training automated systems to perform emphasis-controlled text-to-speech or emotion recognition. Manually annotating prominence is time-consuming and expensive, which motivates the development of automated methods for speech prominence estimation. However, developing such an automated system using machine-learning methods requires human-annotated training data. Using our system for acquiring such human annotations, we collect and open-source crowdsourced annotations of a portion of the LibriTTS dataset. We use these annotations as ground truth to train a neural speech prominence estimator that generalizes to unseen speakers, datasets, and speaking styles. We investigate design decisions for neural prominence estimation as well as how neural prominence estimation improves as a function of two key factors of annotation cost: dataset size and the number of annotations per utterance.
A Sidecar Separator Can Convert a Single-Speaker Speech Recognition System to a Multi-Speaker One
Feb 20, 2023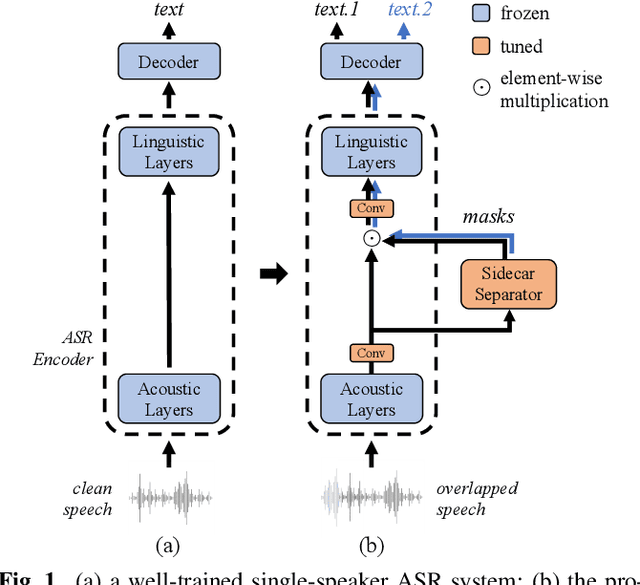
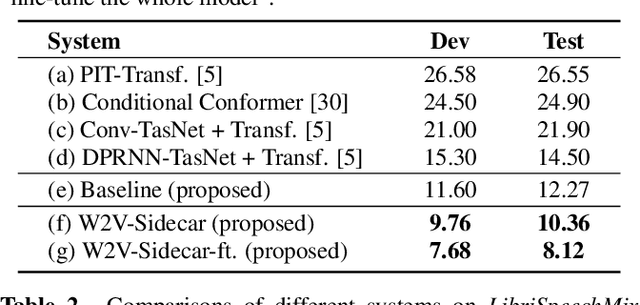
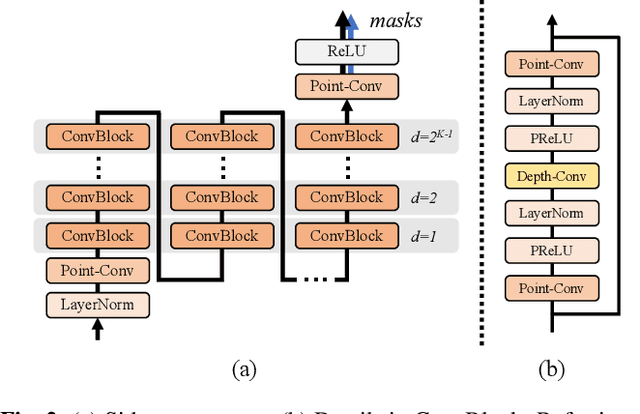
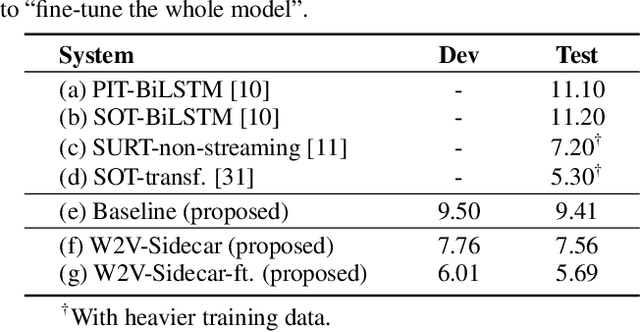
Although automatic speech recognition (ASR) can perform well in common non-overlapping environments, sustaining performance in multi-speaker overlapping speech recognition remains challenging. Recent research revealed that ASR model's encoder captures different levels of information with different layers -- the lower layers tend to have more acoustic information, and the upper layers more linguistic. This inspires us to develop a Sidecar separator to empower a well-trained ASR model for multi-speaker scenarios by separating the mixed speech embedding between two suitable layers. We experimented with a wav2vec 2.0-based ASR model with a Sidecar mounted. By freezing the parameters of the original model and training only the Sidecar (8.7 M, 8.4% of all parameters), the proposed approach outperforms the previous state-of-the-art by a large margin for the 2-speaker mixed LibriMix dataset, reaching a word error rate (WER) of 10.36%; and obtains comparable results (7.56%) for LibriSpeechMix dataset when limited training.
Improving CTC-AED model with integrated-CTC and auxiliary loss regularization
Aug 15, 2023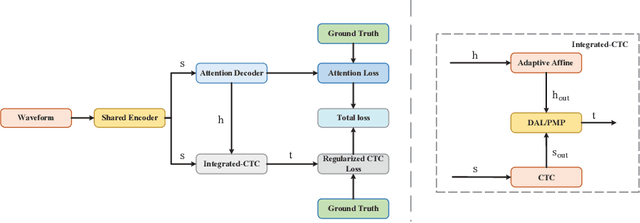

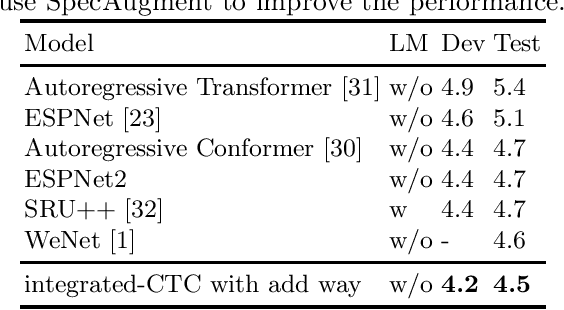

Connectionist temporal classification (CTC) and attention-based encoder decoder (AED) joint training has been widely applied in automatic speech recognition (ASR). Unlike most hybrid models that separately calculate the CTC and AED losses, our proposed integrated-CTC utilizes the attention mechanism of AED to guide the output of CTC. In this paper, we employ two fusion methods, namely direct addition of logits (DAL) and preserving the maximum probability (PMP). We achieve dimensional consistency by adaptively affine transforming the attention results to match the dimensions of CTC. To accelerate model convergence and improve accuracy, we introduce auxiliary loss regularization for accelerated convergence. Experimental results demonstrate that the DAL method performs better in attention rescoring, while the PMP method excels in CTC prefix beam search and greedy search.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 17, 2023English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available\footnote{\url{https://huggingface.co/uitnlp/visobert}} only for research purposes.
Improving Code-Switching and Named Entity Recognition in ASR with Speech Editing based Data Augmentation
Jun 14, 2023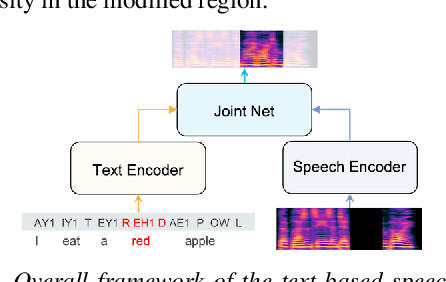
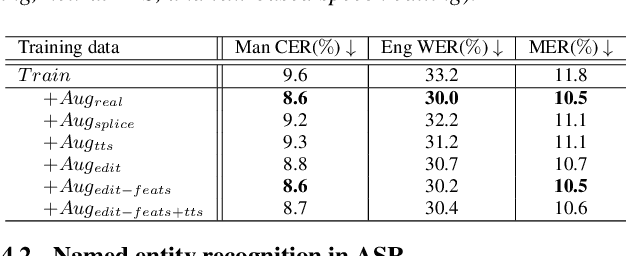

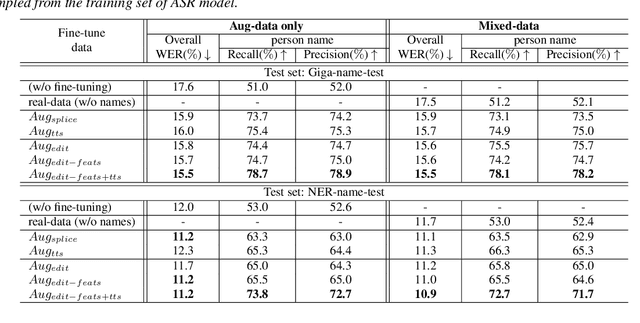
Recently, end-to-end (E2E) automatic speech recognition (ASR) models have made great strides and exhibit excellent performance in general speech recognition. However, there remain several challenging scenarios that E2E models are not competent in, such as code-switching and named entity recognition (NER). Data augmentation is a common and effective practice for these two scenarios. However, the current data augmentation methods mainly rely on audio splicing and text-to-speech (TTS) models, which might result in discontinuous, unrealistic, and less diversified speech. To mitigate these potential issues, we propose a novel data augmentation method by applying the text-based speech editing model. The augmented speech from speech editing systems is more coherent and diversified, also more akin to real speech. The experimental results on code-switching and NER tasks show that our proposed method can significantly outperform the audio splicing and neural TTS based data augmentation systems.
PROCTER: PROnunciation-aware ConTextual adaptER for personalized speech recognition in neural transducers
Mar 30, 2023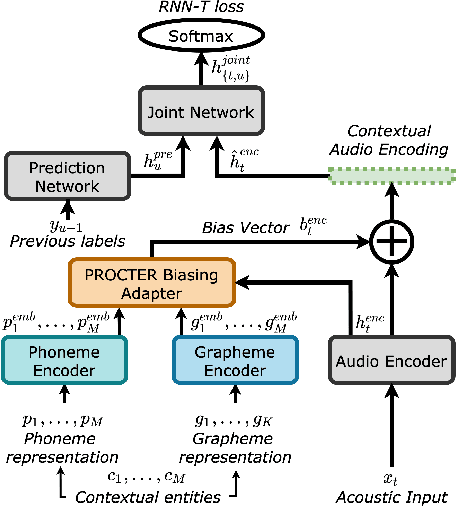
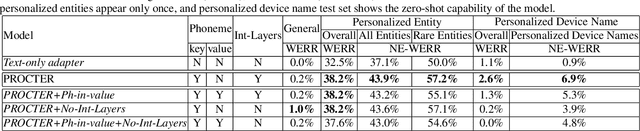

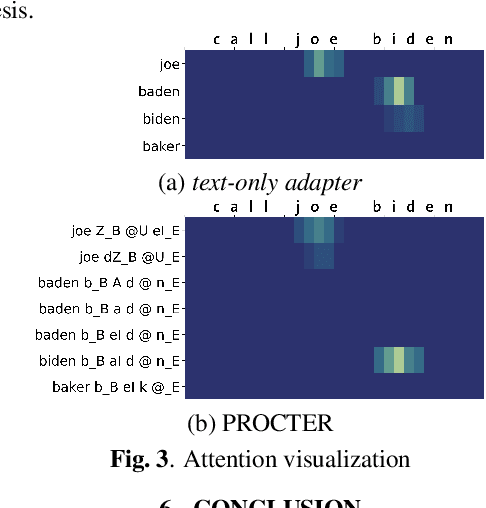
End-to-End (E2E) automatic speech recognition (ASR) systems used in voice assistants often have difficulties recognizing infrequent words personalized to the user, such as names and places. Rare words often have non-trivial pronunciations, and in such cases, human knowledge in the form of a pronunciation lexicon can be useful. We propose a PROnunCiation-aware conTextual adaptER (PROCTER) that dynamically injects lexicon knowledge into an RNN-T model by adding a phonemic embedding along with a textual embedding. The experimental results show that the proposed PROCTER architecture outperforms the baseline RNN-T model by improving the word error rate (WER) by 44% and 57% when measured on personalized entities and personalized rare entities, respectively, while increasing the model size (number of trainable parameters) by only 1%. Furthermore, when evaluated in a zero-shot setting to recognize personalized device names, we observe 7% WER improvement with PROCTER, as compared to only 1% WER improvement with text-only contextual attention
AdVerb: Visually Guided Audio Dereverberation
Aug 23, 2023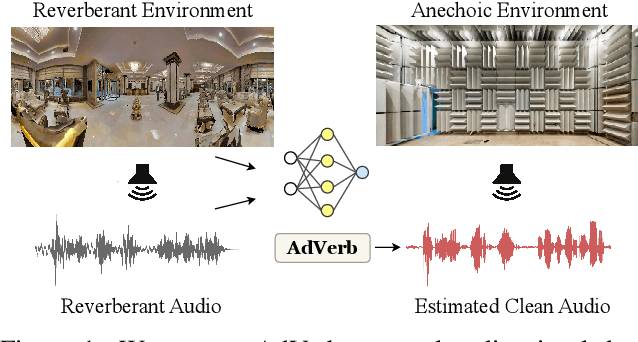
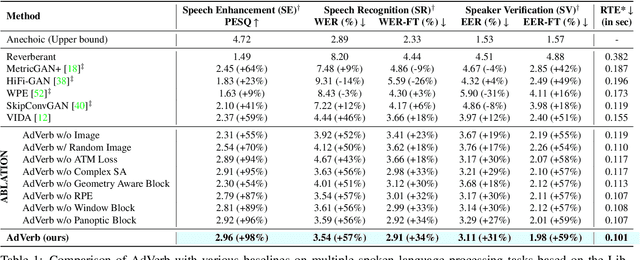
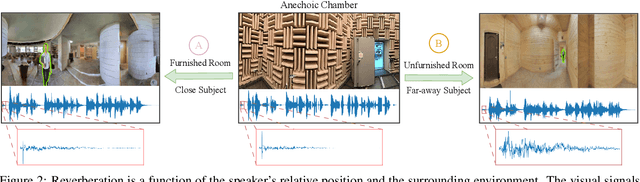
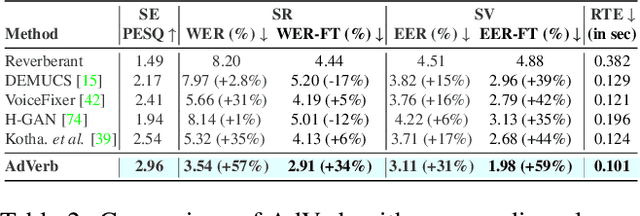
We present AdVerb, a novel audio-visual dereverberation framework that uses visual cues in addition to the reverberant sound to estimate clean audio. Although audio-only dereverberation is a well-studied problem, our approach incorporates the complementary visual modality to perform audio dereverberation. Given an image of the environment where the reverberated sound signal has been recorded, AdVerb employs a novel geometry-aware cross-modal transformer architecture that captures scene geometry and audio-visual cross-modal relationship to generate a complex ideal ratio mask, which, when applied to the reverberant audio predicts the clean sound. The effectiveness of our method is demonstrated through extensive quantitative and qualitative evaluations. Our approach significantly outperforms traditional audio-only and audio-visual baselines on three downstream tasks: speech enhancement, speech recognition, and speaker verification, with relative improvements in the range of 18% - 82% on the LibriSpeech test-clean set. We also achieve highly satisfactory RT60 error scores on the AVSpeech dataset.