 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Unified Modeling of Multi-Domain Multi-Device ASR Systems
May 13, 2022
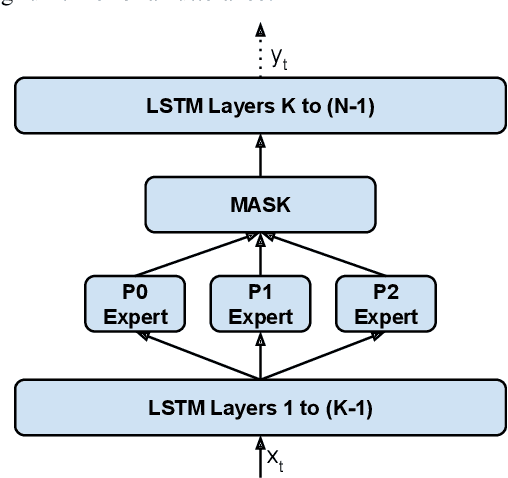
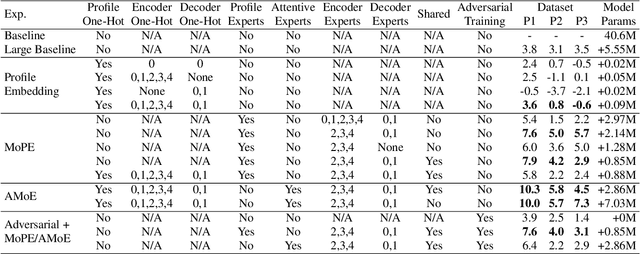
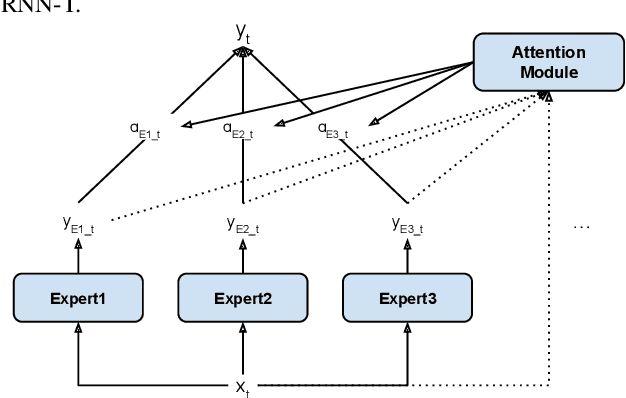
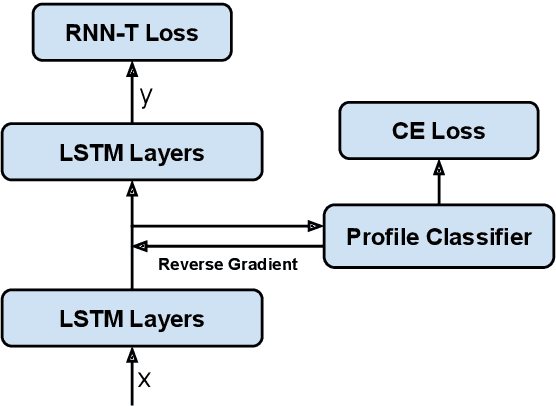
Modern Automatic Speech Recognition (ASR) systems often use a portfolio of domain-specific models in order to get high accuracy for distinct user utterance types across different devices. In this paper, we propose an innovative approach that integrates the different per-domain per-device models into a unified model, using a combination of domain embedding, domain experts, mixture of experts and adversarial training. We run careful ablation studies to show the benefit of each of these innovations in contributing to the accuracy of the overall unified model. Experiments show that our proposed unified modeling approach actually outperforms the carefully tuned per-domain models, giving relative gains of up to 10% over a baseline model with negligible increase in the number of parameters.
Bytes are All You Need: End-to-End Multilingual Speech Recognition and Synthesis with Bytes
Nov 22, 2018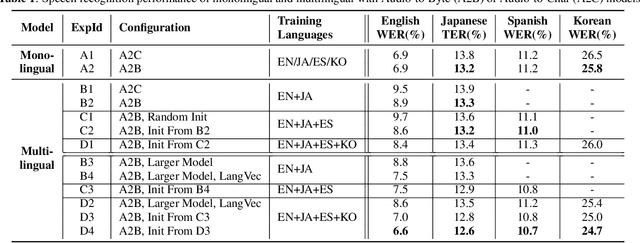

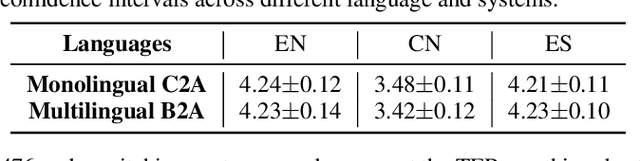
We present two end-to-end models: Audio-to-Byte (A2B) and Byte-to-Audio (B2A), for multilingual speech recognition and synthesis. Prior work has predominantly used characters, sub-words or words as the unit of choice to model text. These units are difficult to scale to languages with large vocabularies, particularly in the case of multilingual processing. In this work, we model text via a sequence of Unicode bytes, specifically, the UTF-8 variable length byte sequence for each character. Bytes allow us to avoid large softmaxes in languages with large vocabularies, and share representations in multilingual models. We show that bytes are superior to grapheme characters over a wide variety of languages in monolingual end-to-end speech recognition. Additionally, our multilingual byte model outperform each respective single language baseline on average by 4.4% relatively. In Japanese-English code-switching speech, our multilingual byte model outperform our monolingual baseline by 38.6% relatively. Finally, we present an end-to-end multilingual speech synthesis model using byte representations which matches the performance of our monolingual baselines.
ATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems
Feb 17, 2021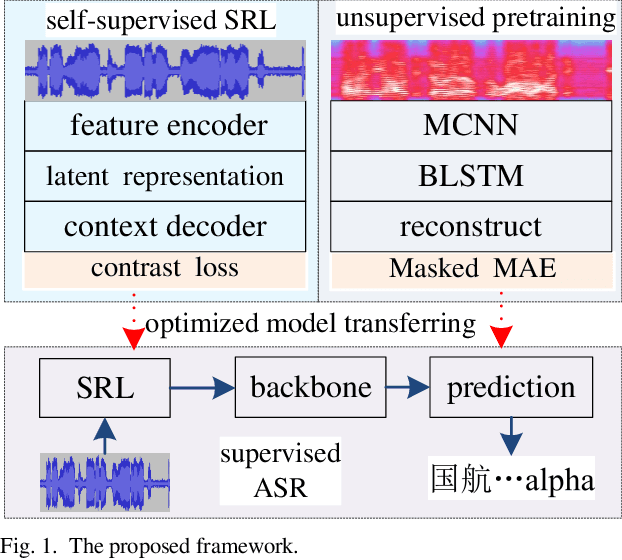
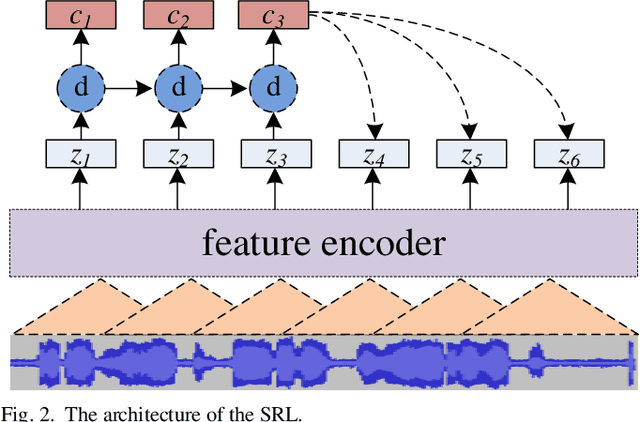
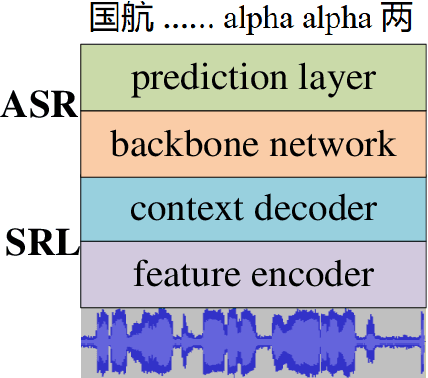
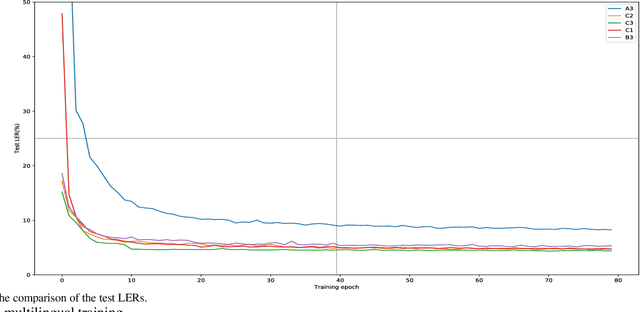
In this paper, a multilingual end-to-end framework, called as ATCSpeechNet, is proposed to tackle the issue of translating communication speech into human-readable text in air traffic control (ATC) systems. In the proposed framework, we focus on integrating the multilingual automatic speech recognition (ASR) into one model, in which an end-to-end paradigm is developed to convert speech waveform into text directly, without any feature engineering or lexicon. In order to make up for the deficiency of the handcrafted feature engineering caused by ATC challenges, a speech representation learning (SRL) network is proposed to capture robust and discriminative speech representations from the raw wave. The self-supervised training strategy is adopted to optimize the SRL network from unlabeled data, and further to predict the speech features, i.e., wave-to-feature. An end-to-end architecture is improved to complete the ASR task, in which a grapheme-based modeling unit is applied to address the multilingual ASR issue. Facing the problem of small transcribed samples in the ATC domain, an unsupervised approach with mask prediction is applied to pre-train the backbone network of the ASR model on unlabeled data by a feature-to-feature process. Finally, by integrating the SRL with ASR, an end-to-end multilingual ASR framework is formulated in a supervised manner, which is able to translate the raw wave into text in one model, i.e., wave-to-text. Experimental results on the ATCSpeech corpus demonstrate that the proposed approach achieves a high performance with a very small labeled corpus and less resource consumption, only 4.20% label error rate on the 58-hour transcribed corpus. Compared to the baseline model, the proposed approach obtains over 100% relative performance improvement which can be further enhanced with the increasing of the size of the transcribed samples.
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019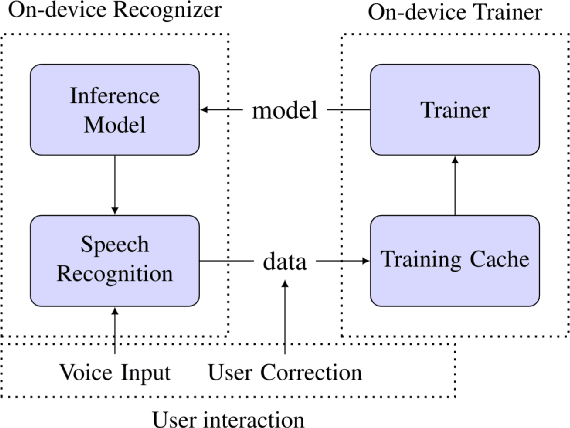
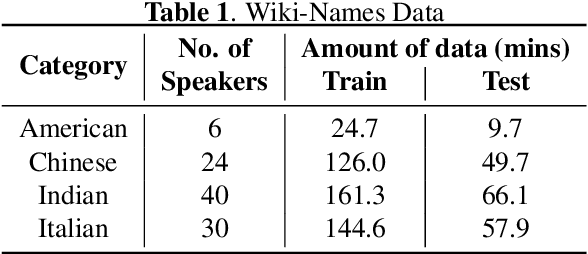
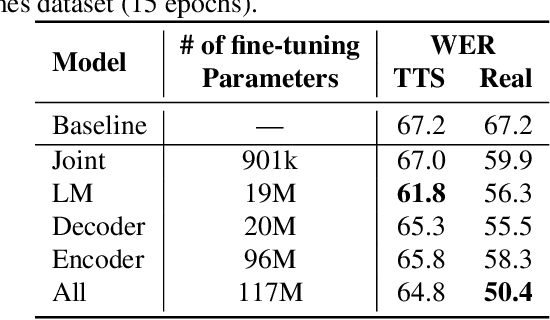
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.
Joint Speech Recognition and Speaker Diarization via Sequence Transduction
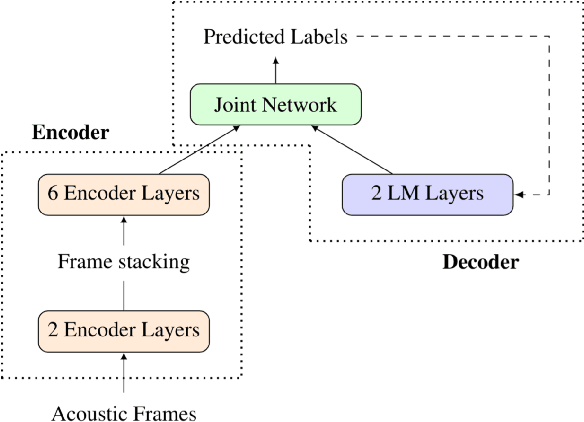
Jul 09, 2019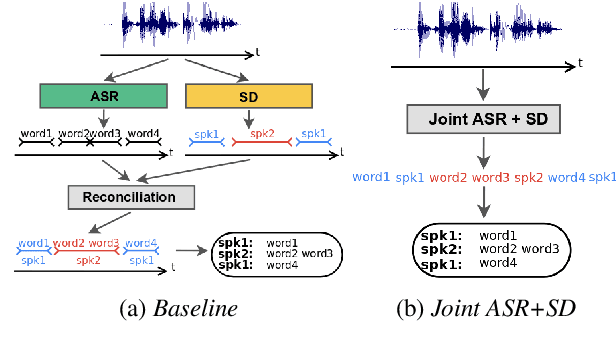

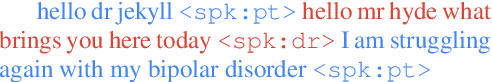
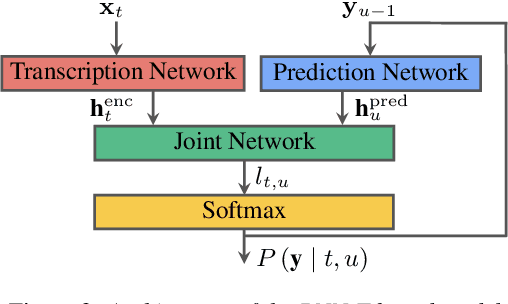
Speech applications dealing with conversations require not only recognizing the spoken words, but also determining who spoke when. The task of assigning words to speakers is typically addressed by merging the outputs of two separate systems, namely, an automatic speech recognition (ASR) system and a speaker diarization (SD) system. The two systems are trained independently with different objective functions. Often the SD systems operate directly on the acoustics and are not constrained to respect word boundaries and this deficiency is overcome in an ad hoc manner. Motivated by recent advances in sequence to sequence learning, we propose a novel approach to tackle the two tasks by a joint ASR and SD system using a recurrent neural network transducer. Our approach utilizes both linguistic and acoustic cues to infer speaker roles, as opposed to typical SD systems, which only use acoustic cues. We evaluated the performance of our approach on a large corpus of medical conversations between physicians and patients. Compared to a competitive conventional baseline, our approach improves word-level diarization error rate from 15.8% to 2.2%.
Rnn-transducer with language bias for end-to-end Mandarin-English code-switching speech recognition
Feb 19, 2020
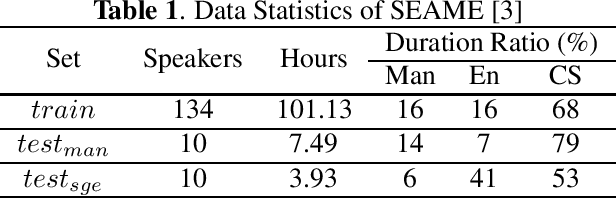
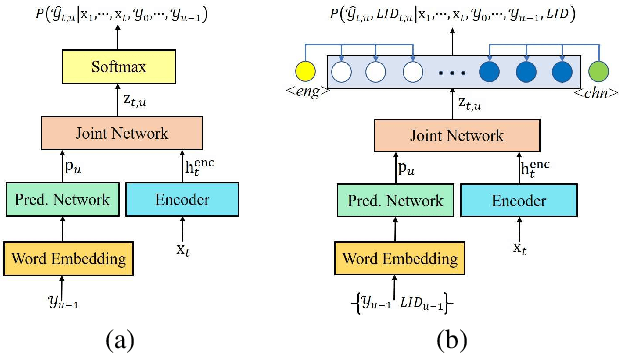
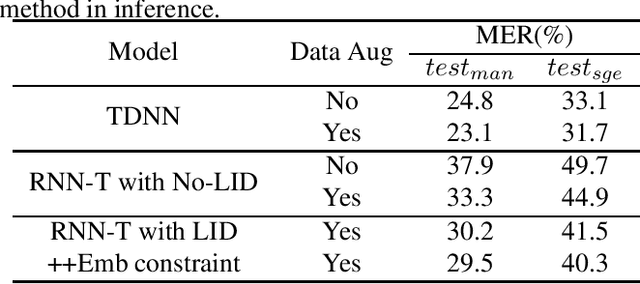
Recently, language identity information has been utilized to improve the performance of end-to-end code-switching (CS) speech recognition. However, previous works use an additional language identification (LID) model as an auxiliary module, which causes the system complex. In this work, we propose an improved recurrent neural network transducer (RNN-T) model with language bias to alleviate the problem. We use the language identities to bias the model to predict the CS points. This promotes the model to learn the language identity information directly from transcription, and no additional LID model is needed. We evaluate the approach on a Mandarin-English CS corpus SEAME. Compared to our RNN-T baseline, the proposed method can achieve 16.2% and 12.9% relative error reduction on two test sets, respectively.
First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
Dec 08, 2014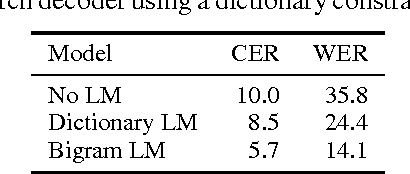

We present a method to perform first-pass large vocabulary continuous speech recognition using only a neural network and language model. Deep neural network acoustic models are now commonplace in HMM-based speech recognition systems, but building such systems is a complex, domain-specific task. Recent work demonstrated the feasibility of discarding the HMM sequence modeling framework by directly predicting transcript text from audio. This paper extends this approach in two ways. First, we demonstrate that a straightforward recurrent neural network architecture can achieve a high level of accuracy. Second, we propose and evaluate a modified prefix-search decoding algorithm. This approach to decoding enables first-pass speech recognition with a language model, completely unaided by the cumbersome infrastructure of HMM-based systems. Experiments on the Wall Street Journal corpus demonstrate fairly competitive word error rates, and the importance of bi-directional network recurrence.
Semi-FedSER: Semi-supervised Learning for Speech Emotion Recognition On Federated Learning using Multiview Pseudo-Labeling
Mar 15, 2022
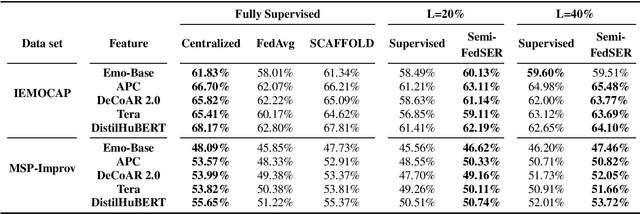
Speech Emotion Recognition (SER) application is frequently associated with privacy concerns as it often acquires and transmits speech data at the client-side to remote cloud platforms for further processing. These speech data can reveal not only speech content and affective information but the speaker's identity, demographic traits, and health status. Federated learning (FL) is a distributed machine learning algorithm that coordinates clients to train a model collaboratively without sharing local data. This algorithm shows enormous potential for SER applications as sharing raw speech or speech features from a user's device is vulnerable to privacy attacks. However, a major challenge in FL is limited availability of high-quality labeled data samples. In this work, we propose a semi-supervised federated learning framework, Semi-FedSER, that utilizes both labeled and unlabeled data samples to address the challenge of limited labeled data samples in FL. We show that our Semi-FedSER can generate desired SER performance even when the local label rate l=20 using two SER benchmark datasets: IEMOCAP and MSP-Improv.
Updating Only Encoders Prevents Catastrophic Forgetting of End-to-End ASR Models
Jul 01, 2022
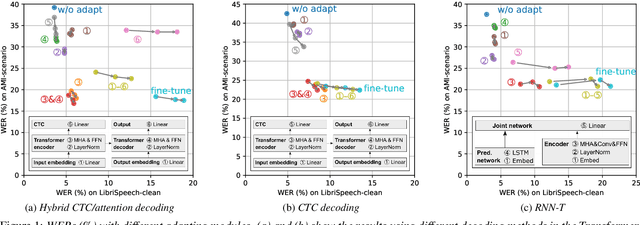
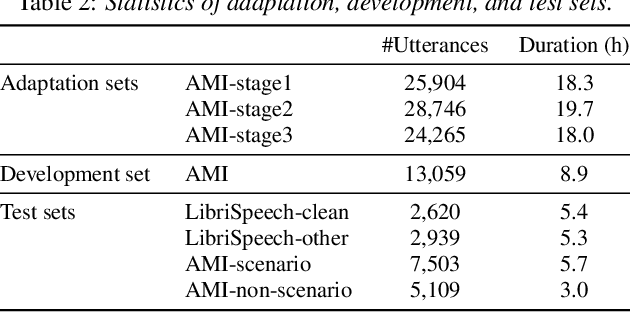
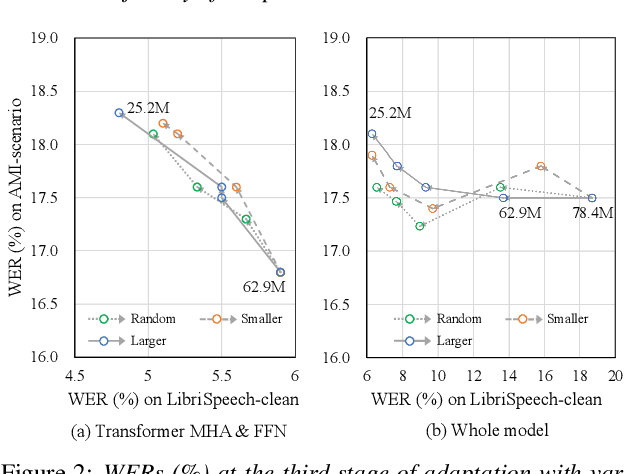
In this paper, we present an incremental domain adaptation technique to prevent catastrophic forgetting for an end-to-end automatic speech recognition (ASR) model. Conventional approaches require extra parameters of the same size as the model for optimization, and it is difficult to apply these approaches to end-to-end ASR models because they have a huge amount of parameters. To solve this problem, we first investigate which parts of end-to-end ASR models contribute to high accuracy in the target domain while preventing catastrophic forgetting. We conduct experiments on incremental domain adaptation from the LibriSpeech dataset to the AMI meeting corpus with two popular end-to-end ASR models and found that adapting only the linear layers of their encoders can prevent catastrophic forgetting. Then, on the basis of this finding, we develop an element-wise parameter selection focused on specific layers to further reduce the number of fine-tuning parameters. Experimental results show that our approach consistently prevents catastrophic forgetting compared to parameter selection from the whole model.
OC16-CE80: A Chinese-English Mixlingual Database and A Speech Recognition Baseline
Sep 27, 2016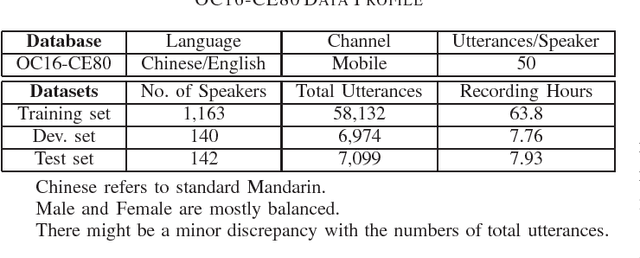
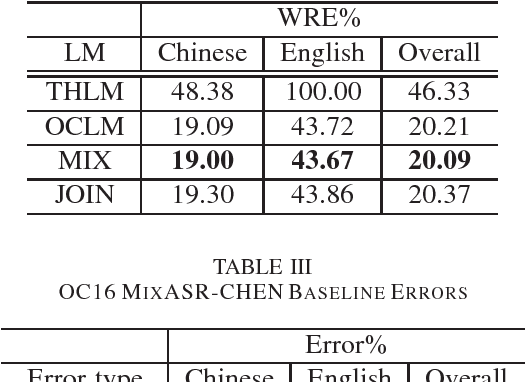
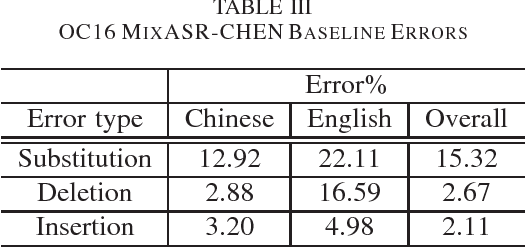
We present the OC16-CE80 Chinese-English mixlingual speech database which was released as a main resource for training, development and test for the Chinese-English mixlingual speech recognition (MixASR-CHEN) challenge on O-COCOSDA 2016. This database consists of 80 hours of speech signals recorded from more than 1,400 speakers, where the utterances are in Chinese but each involves one or several English words. Based on the database and another two free data resources (THCHS30 and the CMU dictionary), a speech recognition (ASR) baseline was constructed with the deep neural network-hidden Markov model (DNN-HMM) hybrid system. We then report the baseline results following the MixASR-CHEN evaluation rules and demonstrate that OC16-CE80 is a reasonable data resource for mixlingual research.