 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuRep: Dual-Mode Speech Representation Learning via ASR-Aware Distillation
May 26, 2025Recent advancements in speech encoders have drawn attention due to their integration with Large Language Models for various speech tasks. While most research has focused on either causal or full-context speech encoders, there's limited exploration to effectively handle both streaming and non-streaming applications, while achieving state-of-the-art performance. We introduce DuRep, a Dual-mode Speech Representation learning setup, which enables a single speech encoder to function efficiently in both offline and online modes without additional parameters or mode-specific adjustments, across downstream tasks. DuRep-200M, our 200M parameter dual-mode encoder, achieves 12% and 11.6% improvements in streaming and non-streaming modes, over baseline encoders on Multilingual ASR. Scaling this approach to 2B parameters, DuRep-2B sets new performance benchmarks across ASR and non-ASR tasks. Our analysis reveals interesting trade-offs between acoustic and semantic information across encoder layers.
Unified Modeling of Multi-Domain Multi-Device ASR Systems
May 13, 2022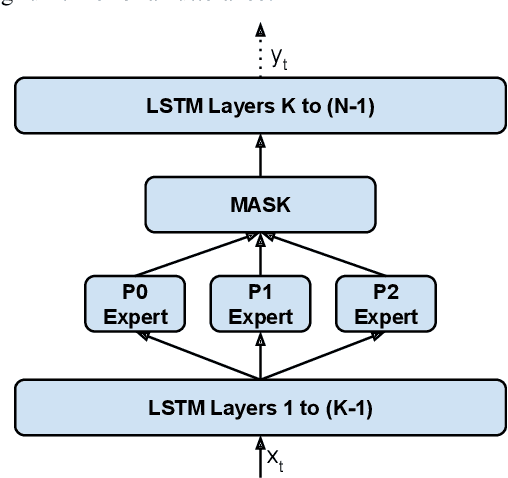
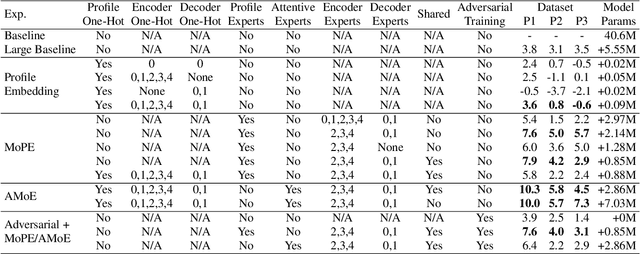
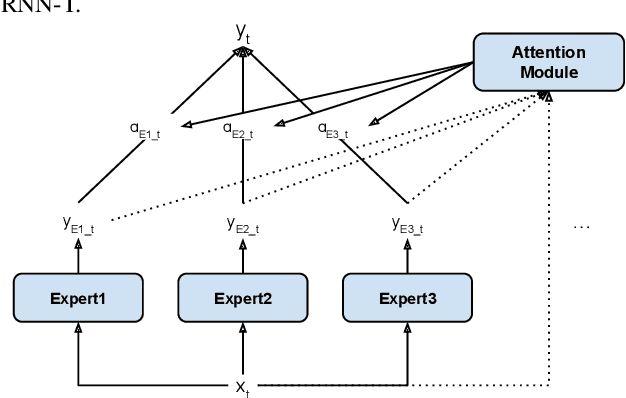
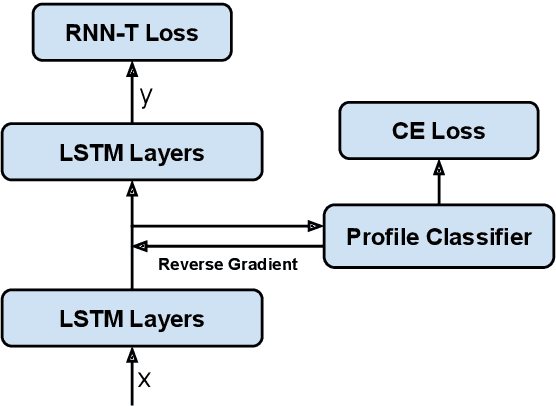
Modern Automatic Speech Recognition (ASR) systems often use a portfolio of domain-specific models in order to get high accuracy for distinct user utterance types across different devices. In this paper, we propose an innovative approach that integrates the different per-domain per-device models into a unified model, using a combination of domain embedding, domain experts, mixture of experts and adversarial training. We run careful ablation studies to show the benefit of each of these innovations in contributing to the accuracy of the overall unified model. Experiments show that our proposed unified modeling approach actually outperforms the carefully tuned per-domain models, giving relative gains of up to 10% over a baseline model with negligible increase in the number of parameters.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021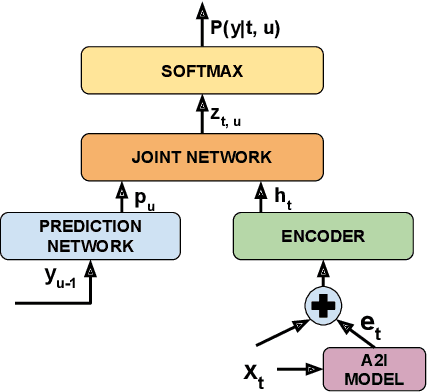
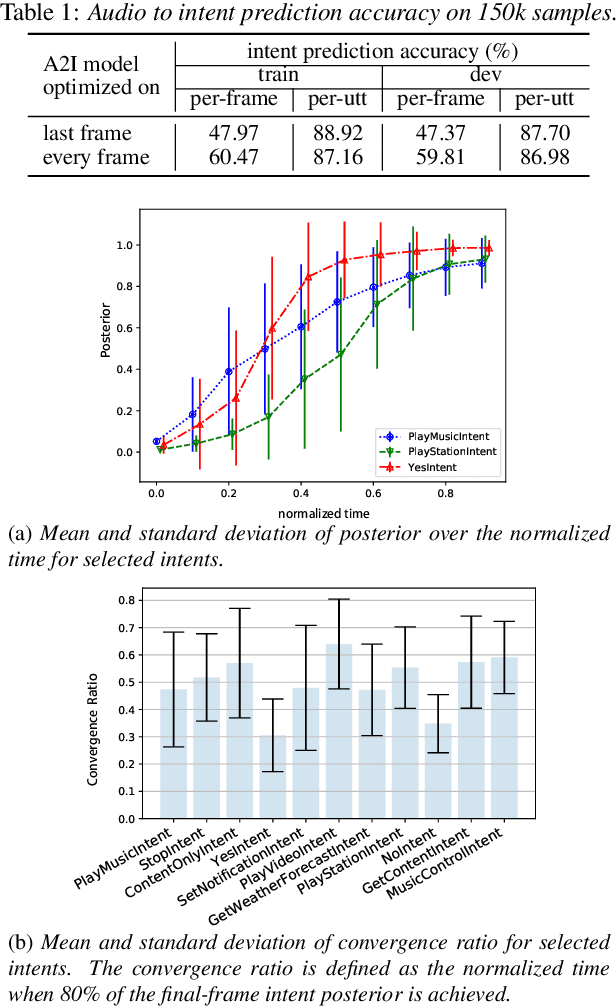
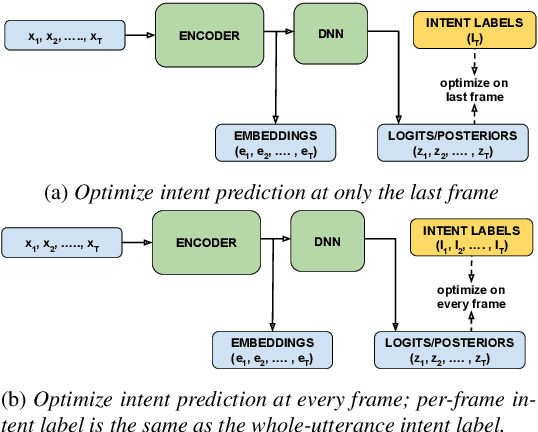
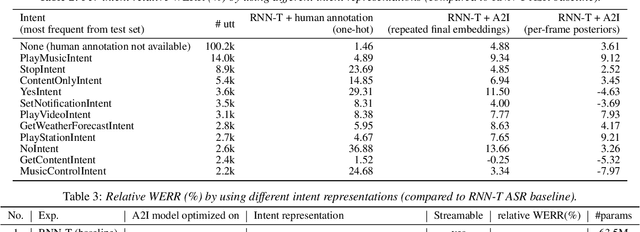
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
REDAT: Accent-Invariant Representation for End-to-End ASR by Domain Adversarial Training with Relabeling
Dec 14, 2020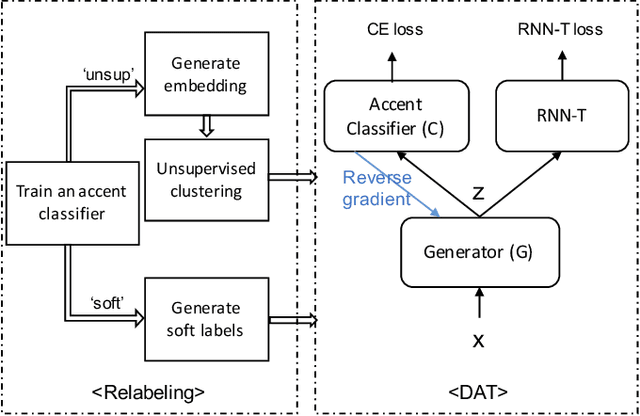
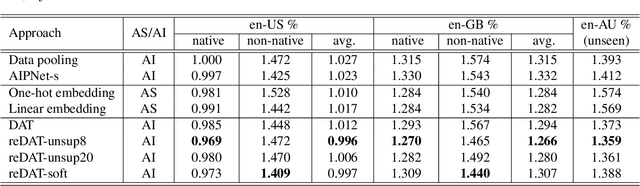
Accents mismatching is a critical problem for end-to-end ASR. This paper aims to address this problem by building an accent-robust RNN-T system with domain adversarial training (DAT). We unveil the magic behind DAT and provide, for the first time, a theoretical guarantee that DAT learns accent-invariant representations. We also prove that performing the gradient reversal in DAT is equivalent to minimizing the Jensen-Shannon divergence between domain output distributions. Motivated by the proof of equivalence, we introduce reDAT, a novel technique based on DAT, which relabels data using either unsupervised clustering or soft labels. Experiments on 23K hours of multi-accent data show that DAT achieves competitive results over accent-specific baselines on both native and non-native English accents but up to 13% relative WER reduction on unseen accents; our reDAT yields further improvements over DAT by 3% and 8% relatively on non-native accents of American and British English.
Knowledge Distillation and Data Selection for Semi-Supervised Learning in CTC Acoustic Models
Aug 10, 2020
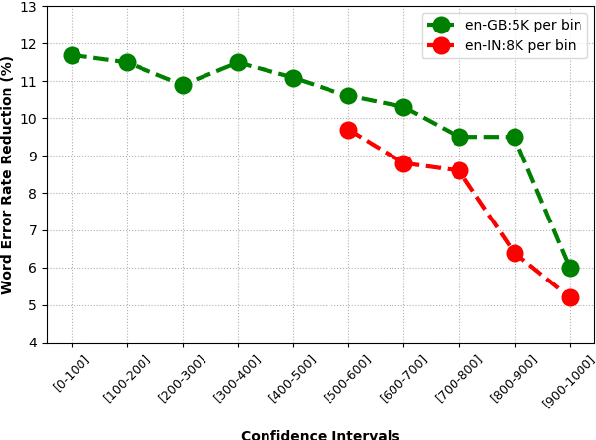
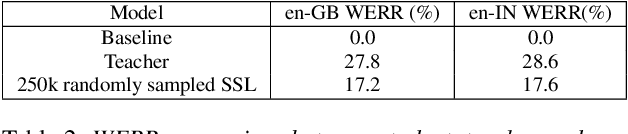

Semi-supervised learning (SSL) is an active area of research which aims to utilize unlabelled data in order to improve the accuracy of speech recognition systems. The current study proposes a methodology for integration of two key ideas: 1) SSL using connectionist temporal classification (CTC) objective and teacher-student based learning 2) Designing effective data-selection mechanisms for leveraging unlabelled data to boost performance of student models. Our aim is to establish the importance of good criteria in selecting samples from a large pool of unlabelled data based on attributes like confidence measure, speaker and content variability. The question we try to answer is: Is it possible to design a data selection mechanism which reduces dependence on a large set of randomly selected unlabelled samples without compromising on Word Error Rate (WER)? We perform empirical investigations of different data selection methods to answer this question and quantify the effect of different sampling strategies. On a semi-supervised ASR setting with 40000 hours of carefully selected unlabelled data, our CTC-SSL approach gives 17% relative WER improvement over a baseline CTC system trained with labelled data. It also achieves on-par performance with CTC-SSL system trained on order of magnitude larger unlabeled data based on random sampling.
Streaming End-to-End Bilingual ASR Systems with Joint Language Identification
Jul 08, 2020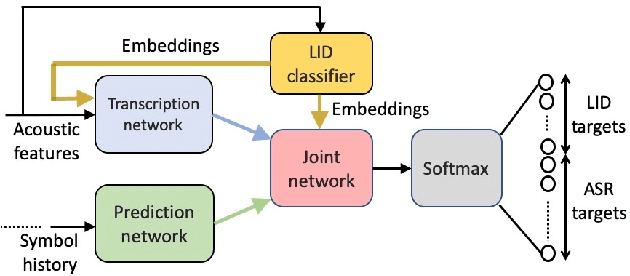
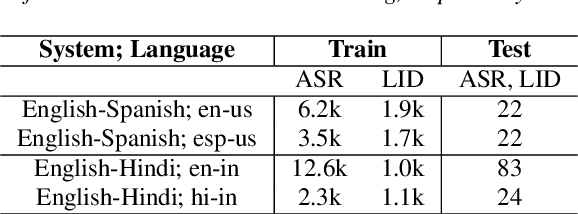
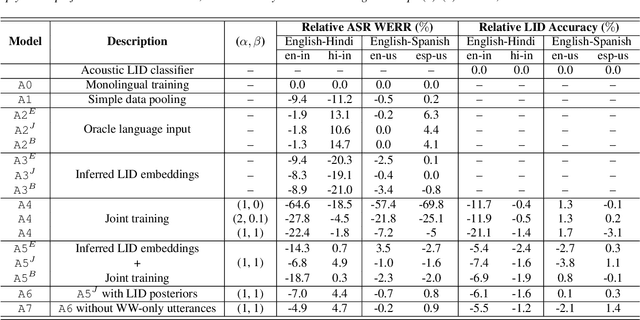
Multilingual ASR technology simplifies model training and deployment, but its accuracy is known to depend on the availability of language information at runtime. Since language identity is seldom known beforehand in real-world scenarios, it must be inferred on-the-fly with minimum latency. Furthermore, in voice-activated smart assistant systems, language identity is also required for downstream processing of ASR output. In this paper, we introduce streaming, end-to-end, bilingual systems that perform both ASR and language identification (LID) using the recurrent neural network transducer (RNN-T) architecture. On the input side, embeddings from pretrained acoustic-only LID classifiers are used to guide RNN-T training and inference, while on the output side, language targets are jointly modeled with ASR targets. The proposed method is applied to two language pairs: English-Spanish as spoken in the United States, and English-Hindi as spoken in India. Experiments show that for English-Spanish, the bilingual joint ASR-LID architecture matches monolingual ASR and acoustic-only LID accuracies. For the more challenging (owing to within-utterance code switching) case of English-Hindi, English ASR and LID metrics show degradation. Overall, in scenarios where users switch dynamically between languages, the proposed architecture offers a promising simplification over running multiple monolingual ASR models and an LID classifier in parallel.
Language Model Bootstrapping Using Neural Machine Translation For Conversational Speech Recognition
Dec 02, 2019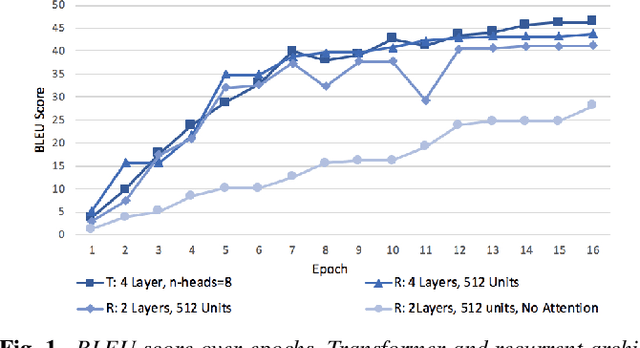


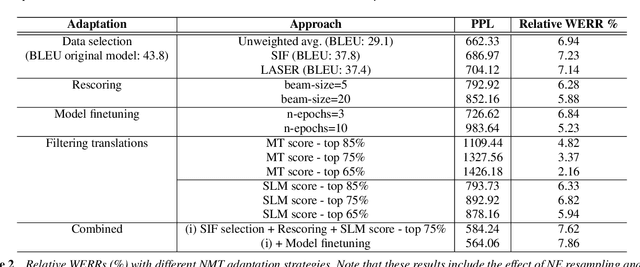
Building conversational speech recognition systems for new languages is constrained by the availability of utterances that capture user-device interactions. Data collection is both expensive and limited by the speed of manual transcription. In order to address this, we advocate the use of neural machine translation as a data augmentation technique for bootstrapping language models. Machine translation (MT) offers a systematic way of incorporating collections from mature, resource-rich conversational systems that may be available for a different language. However, ingesting raw translations from a general purpose MT system may not be effective owing to the presence of named entities, intra sentential code-switching and the domain mismatch between the conversational data being translated and the parallel text used for MT training. To circumvent this, we explore the following domain adaptation techniques: (a) sentence embedding based data selection for MT training, (b) model finetuning, and (c) rescoring and filtering translated hypotheses. Using Hindi as the experimental testbed, we translate US English utterances to supplement the transcribed collections. We observe a relative word error rate reduction of 7.8-15.6%, depending on the bootstrapping phase. Fine grained analysis reveals that translation particularly aids the interaction scenarios which are underrepresented in the transcribed data.