 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRnn-transducer with language bias for end-to-end Mandarin-English code-switching speech recognition
Paper and Code
Feb 19, 2020
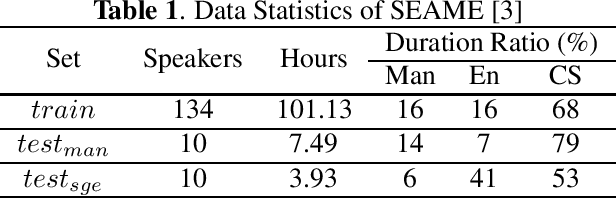
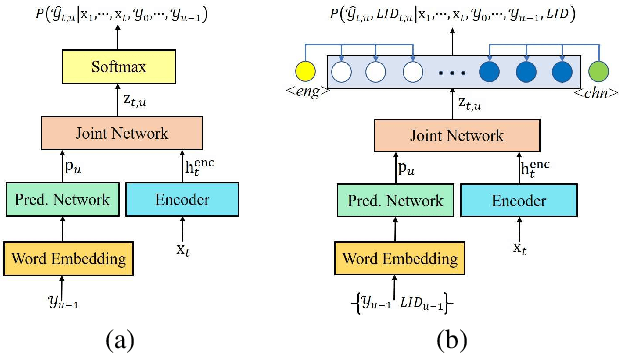
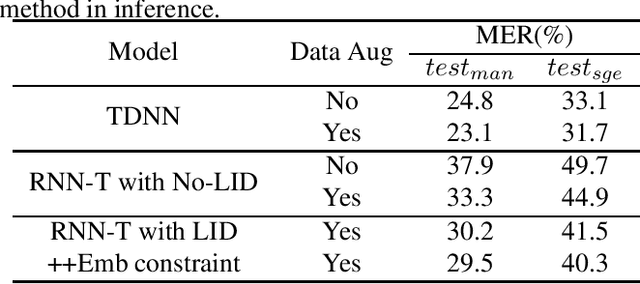
Recently, language identity information has been utilized to improve the performance of end-to-end code-switching (CS) speech recognition. However, previous works use an additional language identification (LID) model as an auxiliary module, which causes the system complex. In this work, we propose an improved recurrent neural network transducer (RNN-T) model with language bias to alleviate the problem. We use the language identities to bias the model to predict the CS points. This promotes the model to learn the language identity information directly from transcription, and no additional LID model is needed. We evaluate the approach on a Mandarin-English CS corpus SEAME. Compared to our RNN-T baseline, the proposed method can achieve 16.2% and 12.9% relative error reduction on two test sets, respectively.