 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Extending Recurrent Neural Aligner for Streaming End-to-End Speech Recognition in Mandarin
Jun 17, 2018
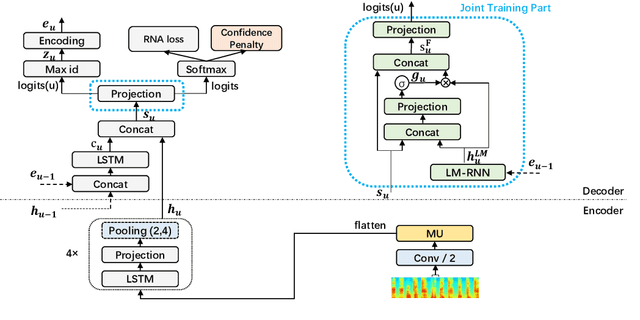



End-to-end models have been showing superiority in Automatic Speech Recognition (ASR). At the same time, the capacity of streaming recognition has become a growing requirement for end-to-end models. Following these trends, an encoder-decoder recurrent neural network called Recurrent Neural Aligner (RNA) has been freshly proposed and shown its competitiveness on two English ASR tasks. However, it is not clear if RNA can be further improved and applied to other spoken language. In this work, we explore the applicability of RNA in Mandarin Chinese and present four effective extensions: In the encoder, we redesign the temporal down-sampling and introduce a powerful convolutional structure. In the decoder, we utilize a regularizer to smooth the output distribution and conduct joint training with a language model. On two Mandarin Chinese conversational telephone speech recognition (MTS) datasets, our Extended-RNA obtains promising performance. Particularly, it achieves 27.7% character error rate (CER), which is superior to current state-of-the-art result on the popular HKUST task.
Exploring End-to-End Techniques for Low-Resource Speech Recognition
Jul 02, 2018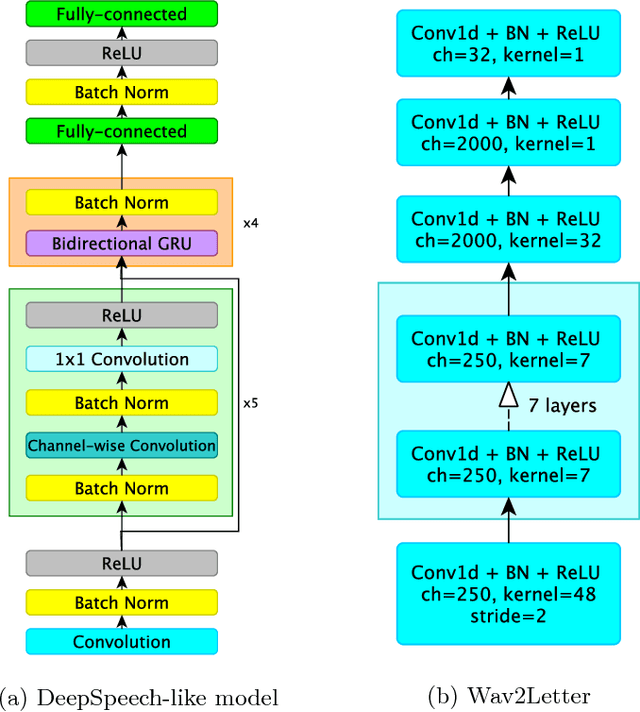
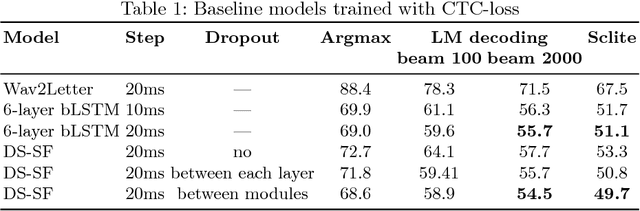
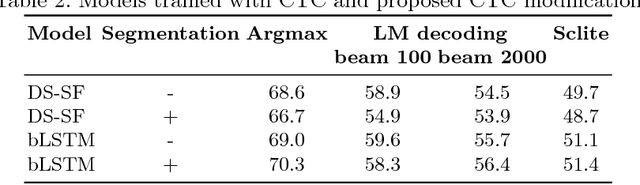
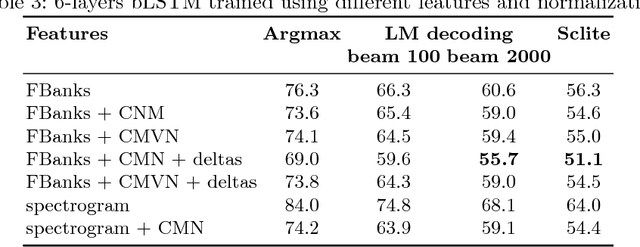
In this work we present simple grapheme-based system for low-resource speech recognition using Babel data for Turkish spontaneous speech (80 hours). We have investigated different neural network architectures performance, including fully-convolutional, recurrent and ResNet with GRU. Different features and normalization techniques are compared as well. We also proposed CTC-loss modification using segmentation during training, which leads to improvement while decoding with small beam size. Our best model achieved word error rate of 45.8%, which is the best reported result for end-to-end systems using in-domain data for this task, according to our knowledge.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
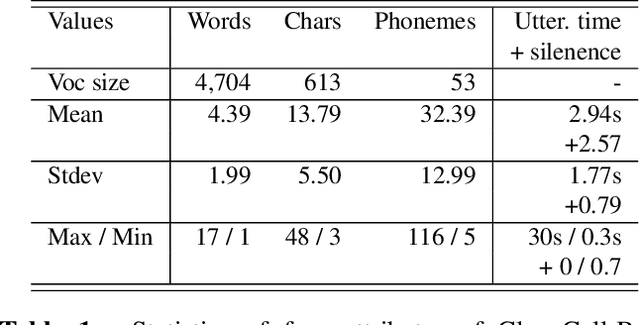
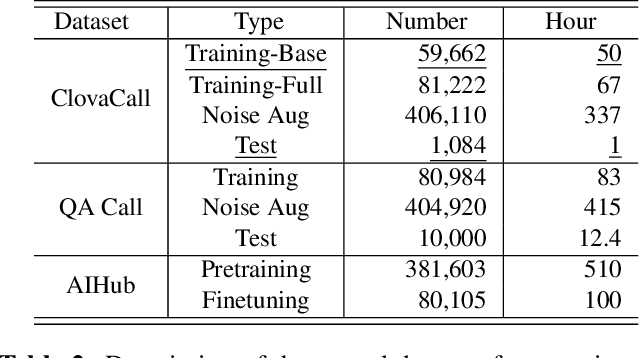
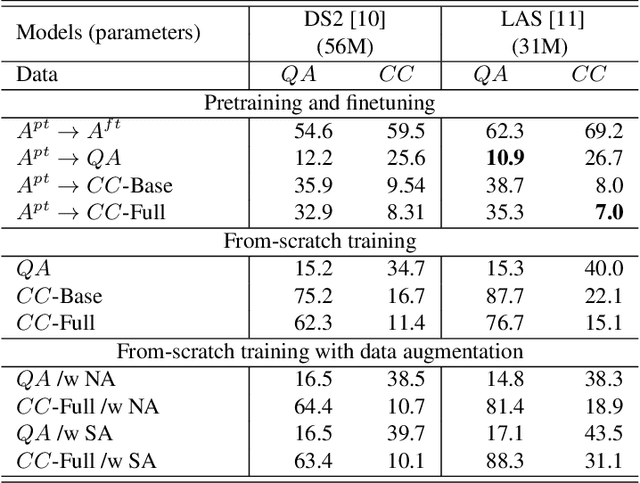
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
Fully Quantizing a Simplified Transformer for End-to-end Speech Recognition
Nov 09, 2019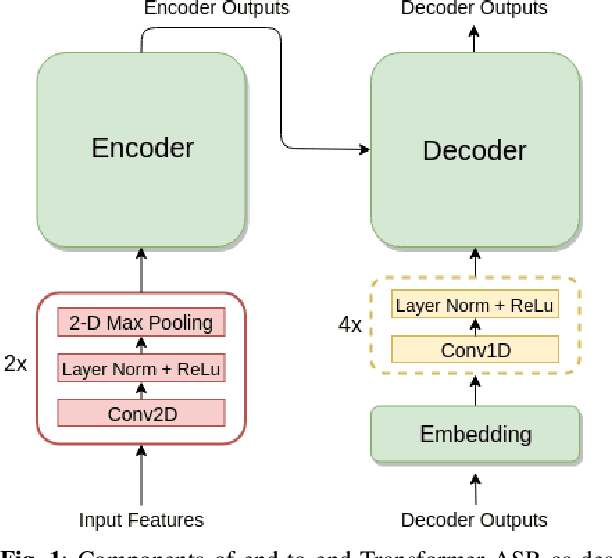
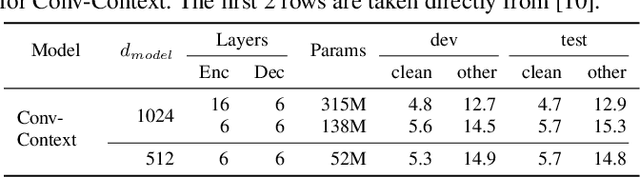
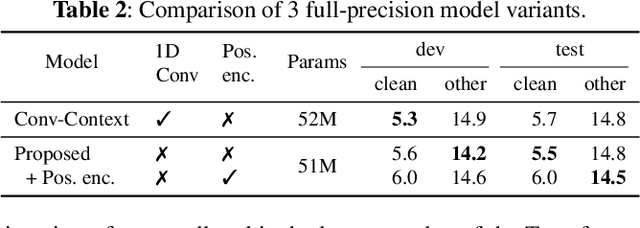
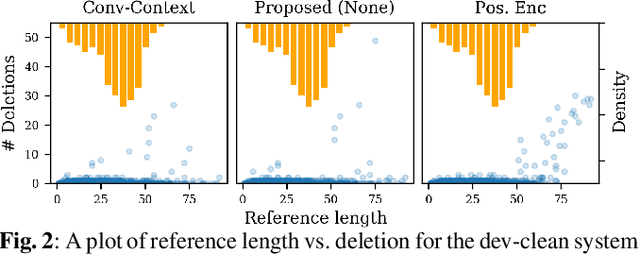
While significant improvements have been made in recent years in terms of end-to-end automatic speech recognition (ASR) performance, such improvements were obtained through the use of very large neural networks, unfit for embedded use on edge devices. That being said, in this paper, we work on simplifying and compressing Transformer-based encoder-decoder architectures for the end-to-end ASR task. We empirically introduce a more compact Speech-Transformer by investigating the impact of discarding particular modules on the performance of the model. Moreover, we evaluate reducing the numerical precision of our network's weights and activations while maintaining the performance of the full-precision model. Our experiments show that we can reduce the number of parameters of the full-precision model and then further compress the model 4x by fully quantizing to 8-bit fixed point precision.
Semi-Supervised Model Training for Unbounded Conversational Speech Recognition
May 26, 2017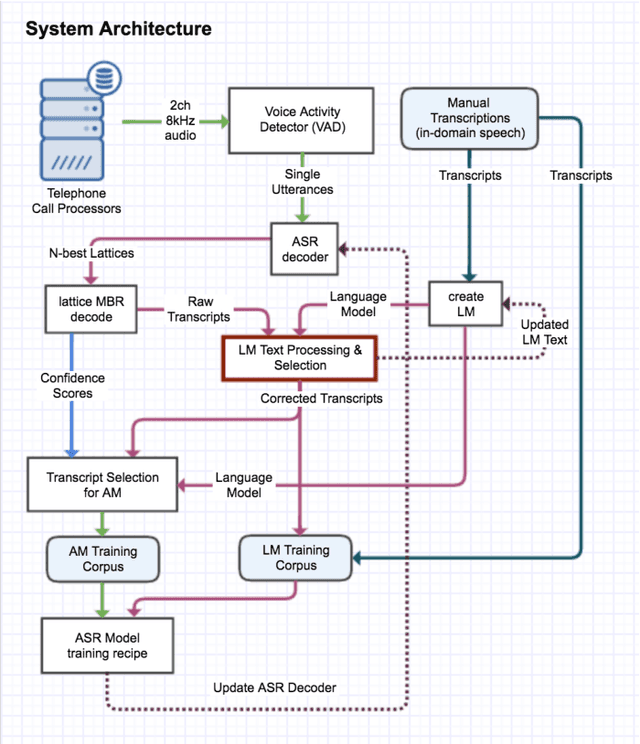
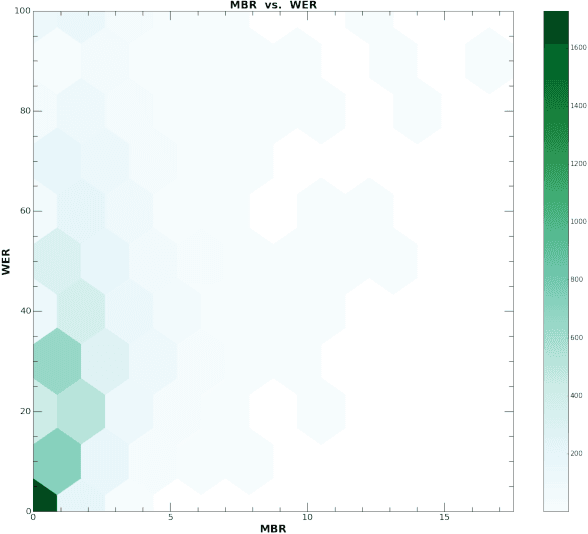
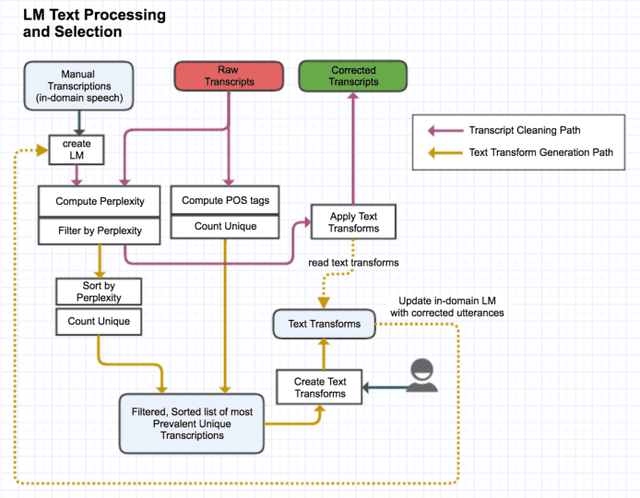
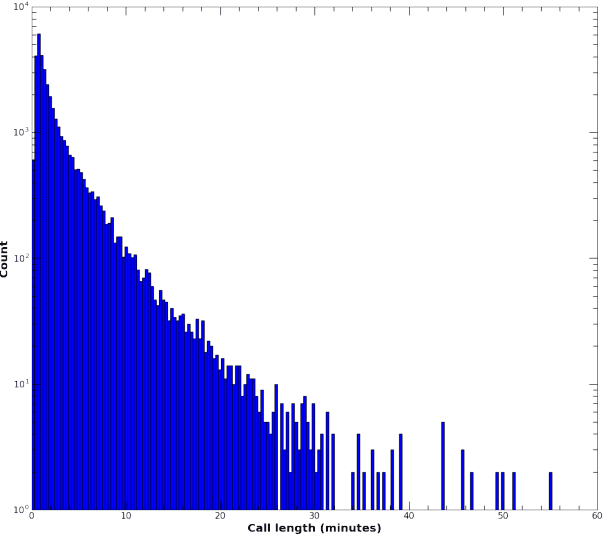
For conversational large-vocabulary continuous speech recognition (LVCSR) tasks, up to about two thousand hours of audio is commonly used to train state of the art models. Collection of labeled conversational audio however, is prohibitively expensive, laborious and error-prone. Furthermore, academic corpora like Fisher English (2004) or Switchboard (1992) are inadequate to train models with sufficient accuracy in the unbounded space of conversational speech. These corpora are also timeworn due to dated acoustic telephony features and the rapid advancement of colloquial vocabulary and idiomatic speech over the last decades. Utilizing the colossal scale of our unlabeled telephony dataset, we propose a technique to construct a modern, high quality conversational speech training corpus on the order of hundreds of millions of utterances (or tens of thousands of hours) for both acoustic and language model training. We describe the data collection, selection and training, evaluating the results of our updated speech recognition system on a test corpus of 7K manually transcribed utterances. We show relative word error rate (WER) reductions of {35%, 19%} on {agent, caller} utterances over our seed model and 5% absolute WER improvements over IBM Watson STT on this conversational speech task.
When Is TTS Augmentation Through a Pivot Language Useful?
Jul 20, 2022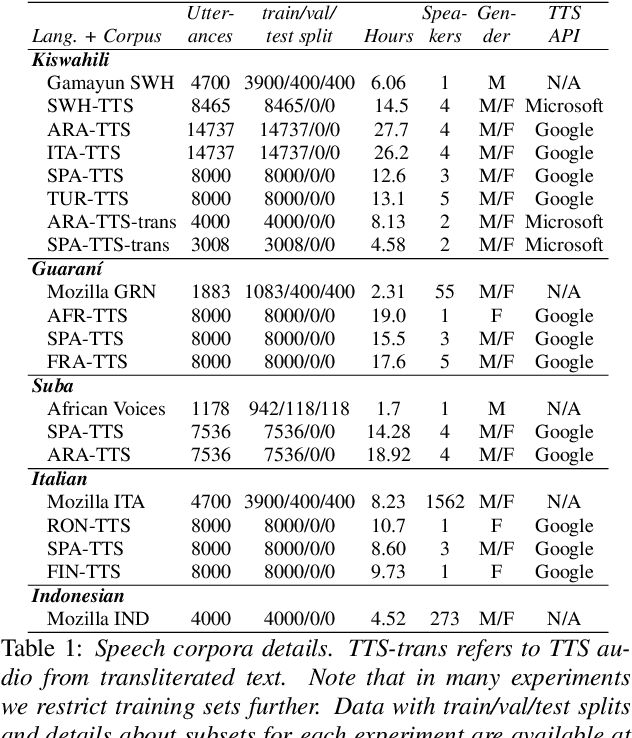
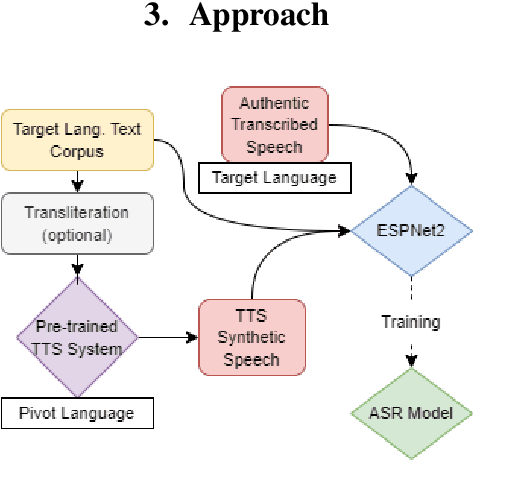
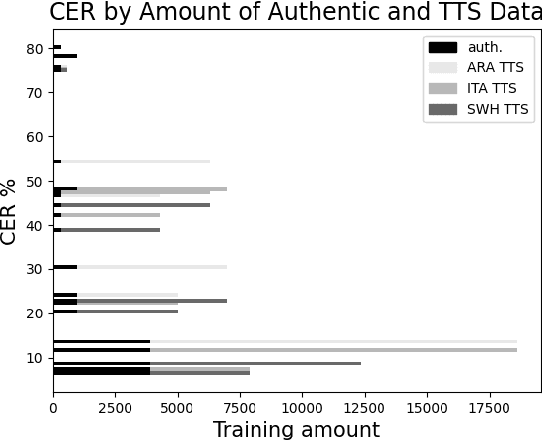
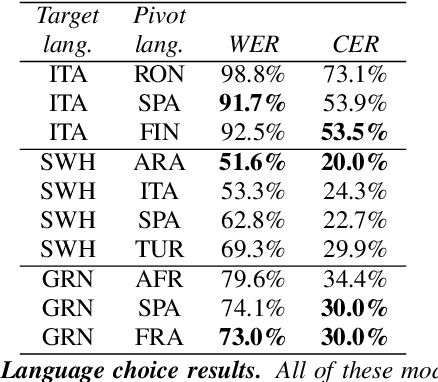
Developing Automatic Speech Recognition (ASR) for low-resource languages is a challenge due to the small amount of transcribed audio data. For many such languages, audio and text are available separately, but not audio with transcriptions. Using text, speech can be synthetically produced via text-to-speech (TTS) systems. However, many low-resource languages do not have quality TTS systems either. We propose an alternative: produce synthetic audio by running text from the target language through a trained TTS system for a higher-resource pivot language. We investigate when and how this technique is most effective in low-resource settings. In our experiments, using several thousand synthetic TTS text-speech pairs and duplicating authentic data to balance yields optimal results. Our findings suggest that searching over a set of candidate pivot languages can lead to marginal improvements and that, surprisingly, ASR performance can by harmed by increases in measured TTS quality. Application of these findings improves ASR by 64.5\% and 45.0\% character error reduction rate (CERR) respectively for two low-resource languages: Guaran\'i and Suba.
A new Speech Feature Fusion method with cross gate parallel CNN for Speaker Recognition
Nov 24, 2022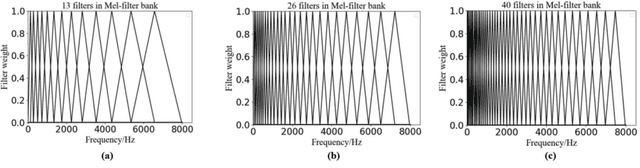
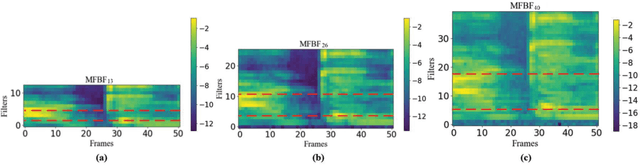
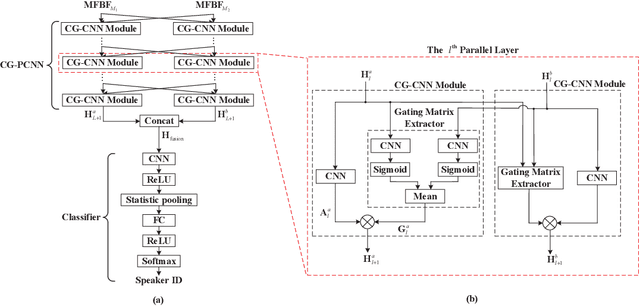
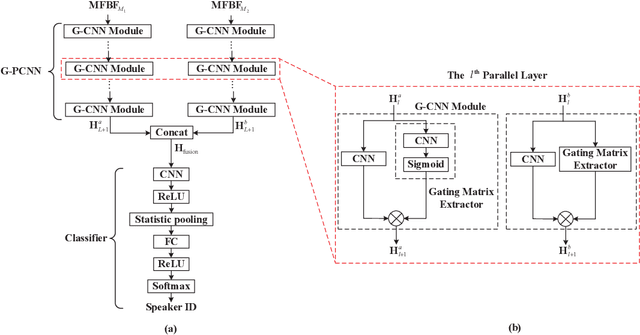
In this paper, a new speech feature fusion method is proposed for speaker recognition on the basis of the cross gate parallel convolutional neural network (CG-PCNN). The Mel filter bank features (MFBFs) of different frequency resolutions can be extracted from each speech frame of a speaker's speech by several Mel filter banks, where the numbers of the triangular filters in the Mel filter banks are different. Due to the frequency resolutions of these MFBFs are different, there are some complementaries for these MFBFs. The CG-PCNN is utilized to extract the deep features from these MFBFs, which applies a cross gate mechanism to capture the complementaries for improving the performance of the speaker recognition system. Then, the fusion feature can be obtained by concatenating these deep features for speaker recognition. The experimental results show that the speaker recognition system with the proposed speech feature fusion method is effective, and marginally outperforms the existing state-of-the-art systems.
Towards Transfer Learning of wav2vec 2.0 for Automatic Lyric Transcription
Jul 20, 2022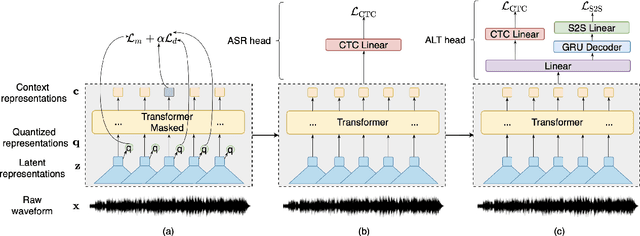
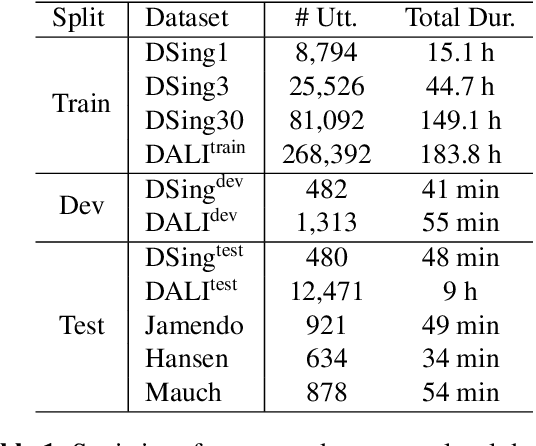
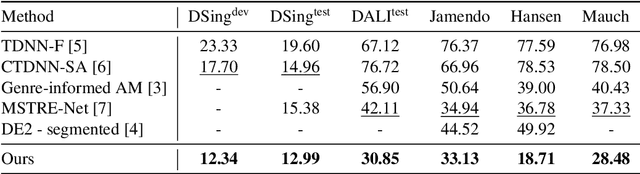
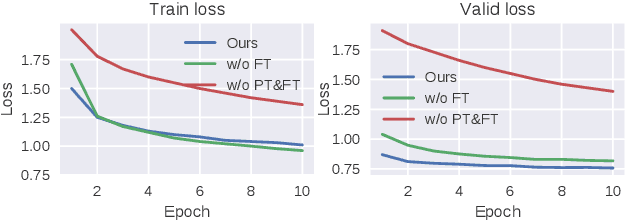
Automatic speech recognition (ASR) has progressed significantly in recent years due to large-scale datasets and the paradigm of self-supervised learning (SSL) methods. However, as its counterpart problem in the singing domain, automatic lyric transcription (ALT) suffers from limited data and degraded intelligibility of sung lyrics, which has caused it to develop at a slower pace. To fill in the performance gap between ALT and ASR, we attempt to exploit the similarities between speech and singing. In this work, we propose a transfer-learning-based ALT solution that takes advantage of these similarities by adapting wav2vec 2.0, an SSL ASR model, to the singing domain. We maximize the effectiveness of transfer learning by exploring the influence of different transfer starting points. We further enhance the performance by extending the original CTC model to a hybrid CTC/attention model. Our method surpasses previous approaches by a large margin on various ALT benchmark datasets. Further experiment shows that, with even a tiny proportion of training data, our method still achieves competitive performance.
Phonological modeling for continuous speech recognition in Korean
Jul 18, 1996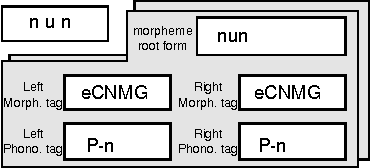

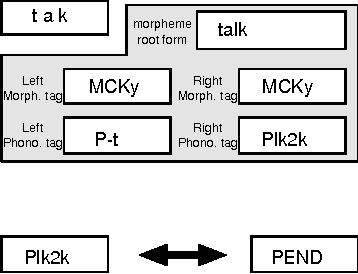
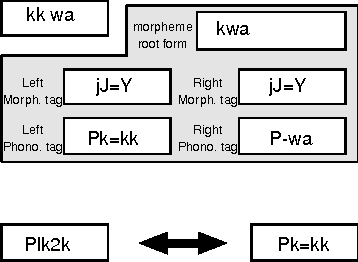
A new scheme to represent phonological changes during continuous speech recognition is suggested. A phonological tag coupled with its morphological tag is designed to represent the conditions of Korean phonological changes. A pairwise language model of these morphological and phonological tags is implemented in Korean speech recognition system. Performance of the model is verified through the TDNN-based speech recognition experiments.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 16, 2020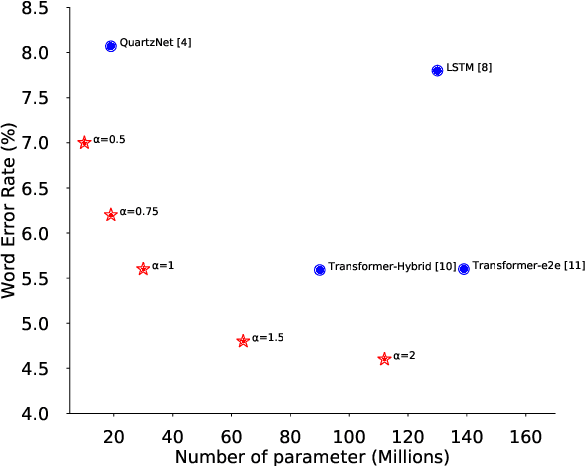
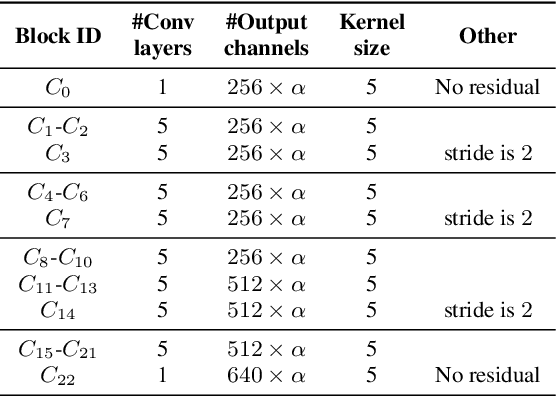
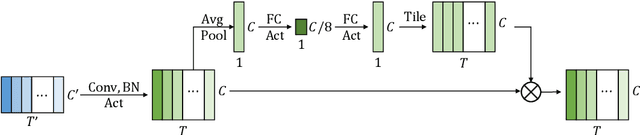
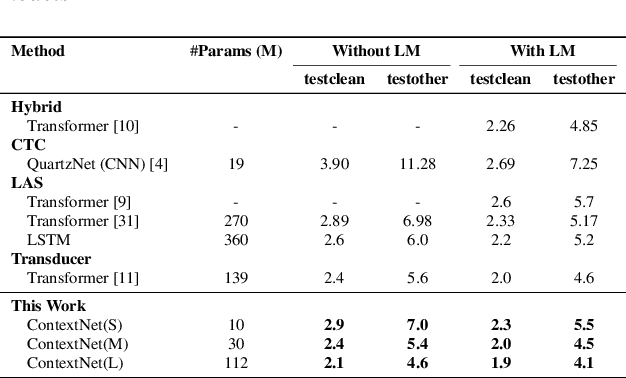
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.