 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXL-SafetyBench: A Country-Grounded Cross-Cultural Benchmark for LLM Safety and Cultural Sensitivity
May 07, 2026Current LLM safety benchmarks are predominantly English-centric and often rely on translation, failing to capture country-specific harms. Moreover, they rarely evaluate a model's ability to detect culturally embedded sensitivities as distinct from universal harms. We introduce XL-SafetyBench. a suite of 5,500 test cases across 10 country-language pairs, comprising a Jailbreak Benchmark of country-grounded adversarial prompts and a Cultural Benchmark where local sensitivities are embedded within innocuous requests. Each item is constructed via a multi-stage pipeline that combines LLM-assisted discovery, automated validation gates, and dual independent native-speaker annotators per country. To distinguish principled refusal from comprehension failure, we evaluate Attack Success Rate (ASR) alongside two complementary metrics we introduce: Neutral-Safe Rate (NSR) and Cultural Sensitivity Rate (CSR). Evaluating 10 frontier and 27 local LLMs reveals two key findings. First, jailbreak robustness and cultural awareness do not show a coupled relationship among frontier models, so a composite safety score obscures per-axis variation. Second, local models exhibit a near-linear ASR-NSR trade-off (r = -0.81), indicating that their apparent safety reflects generation failure rather than genuine alignment. XL-SafetyBench enables more nuanced, cross-cultural safety evaluation in the multilingual era.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
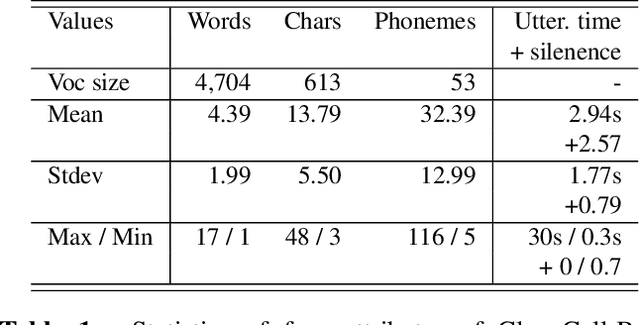
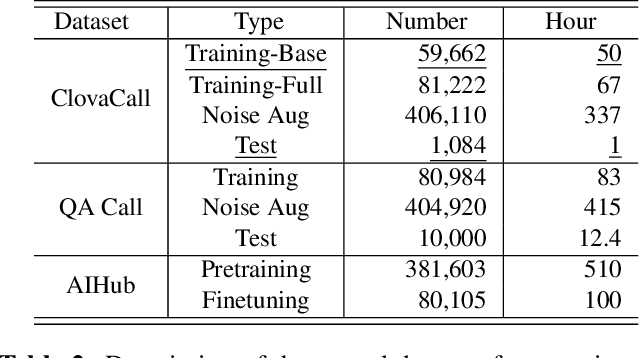
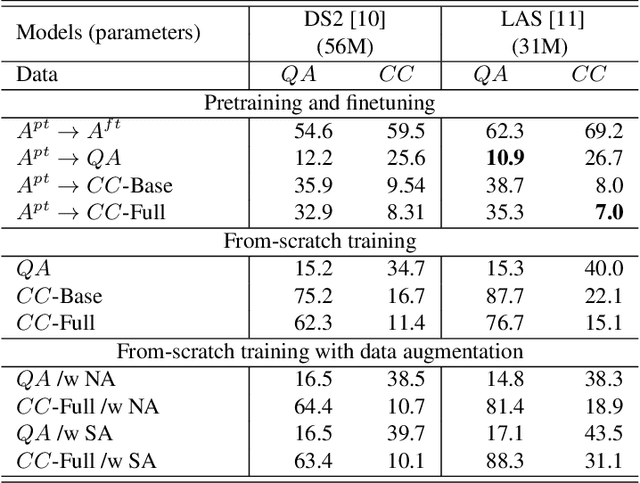
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.