 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens
Sep 10, 2024



We propose Sortformer, a novel neural model for speaker diarization, trained with unconventional objectives compared to existing end-to-end diarization models. The permutation problem in speaker diarization has long been regarded as a critical challenge. Most prior end-to-end diarization systems employ permutation invariant loss (PIL), which optimizes for the permutation that yields the lowest error. In contrast, we introduce Sort Loss, which enables a diarization model to autonomously resolve permutation, with or without PIL. We demonstrate that combining Sort Loss and PIL achieves performance competitive with state-of-the-art end-to-end diarization models trained exclusively with PIL. Crucially, we present a streamlined multispeaker ASR architecture that leverages Sortformer as a speaker supervision model, embedding speaker label estimation within the ASR encoder state using a sinusoidal kernel function. This approach resolves the speaker permutation problem through sorted objectives, effectively bridging speaker-label timestamps and speaker tokens. In our experiments, we show that the proposed multispeaker ASR architecture, enhanced with speaker supervision, improves performance via adapter techniques. Code and trained models will be made publicly available via the NVIDIA NeMo framework
Resource-Efficient Adaptation of Speech Foundation Models for Multi-Speaker ASR
Sep 02, 2024
Speech foundation models have achieved state-of-the-art (SoTA) performance across various tasks, such as automatic speech recognition (ASR) in hundreds of languages. However, multi-speaker ASR remains a challenging task for these models due to data scarcity and sparsity. In this paper, we present approaches to enable speech foundation models to process and understand multi-speaker speech with limited training data. Specifically, we adapt a speech foundation model for the multi-speaker ASR task using only telephonic data. Remarkably, the adapted model also performs well on meeting data without any fine-tuning, demonstrating the generalization ability of our approach. We conduct several ablation studies to analyze the impact of different parameters and strategies on model performance. Our findings highlight the effectiveness of our methods. Results show that less parameters give better overall cpWER, which, although counter-intuitive, provides insights into adapting speech foundation models for multi-speaker ASR tasks with minimal annotated data.
NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks
Aug 23, 2024



Self-supervised learning has been proved to benefit a wide range of speech processing tasks, such as speech recognition/translation, speaker verification and diarization, etc. However, most of these approaches are computationally intensive due to using transformer encoder and lack of sub-sampling. In this paper, we propose a new self-supervised learning model termed as Neural Encoder for Self-supervised Training (NEST). Specifically, we adopt the FastConformer architecture, which has an 8x sub-sampling rate and is faster than Transformer or Conformer architectures. Instead of clustering-based token generation, we resort to fixed random projection for its simplicity and effectiveness. We also propose a generalized noisy speech augmentation that teaches the model to disentangle the main speaker from noise or other speakers. Experiments show that the proposed NEST model improves over existing self-supervised models on a variety of speech processing tasks. Code and checkpoints will be publicly available via NVIDIA NeMo toolkit.
LT-LM: a novel non-autoregressive language model for single-shot lattice rescoring
Apr 06, 2021
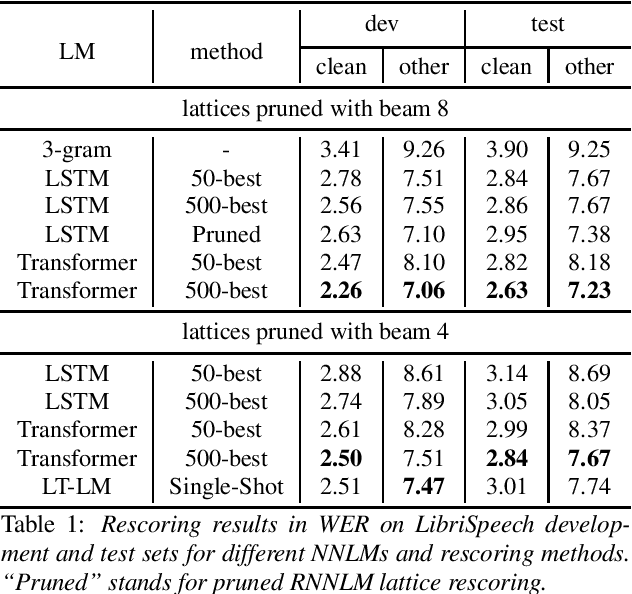
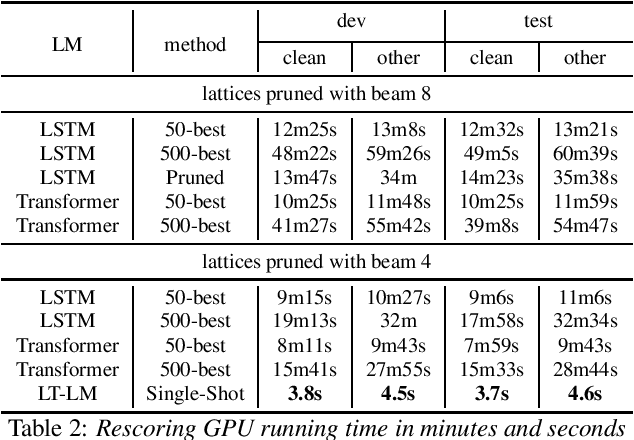
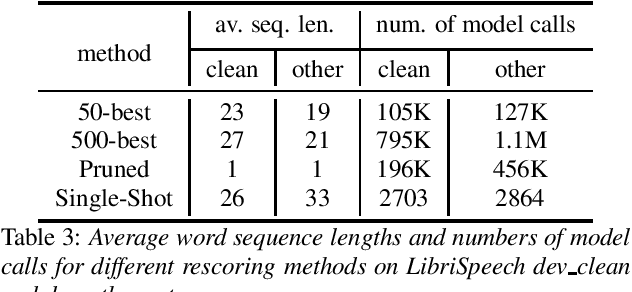
Neural network-based language models are commonly used in rescoring approaches to improve the quality of modern automatic speech recognition (ASR) systems. Most of the existing methods are computationally expensive since they use autoregressive language models. We propose a novel rescoring approach, which processes the entire lattice in a single call to the model. The key feature of our rescoring policy is a novel non-autoregressive Lattice Transformer Language Model (LT-LM). This model takes the whole lattice as an input and predicts a new language score for each arc. Additionally, we propose the artificial lattices generation approach to incorporate a large amount of text data in the LT-LM training process. Our single-shot rescoring performs orders of magnitude faster than other rescoring methods in our experiments. It is more than 300 times faster than pruned RNNLM lattice rescoring and N-best rescoring while slightly inferior in terms of WER.
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021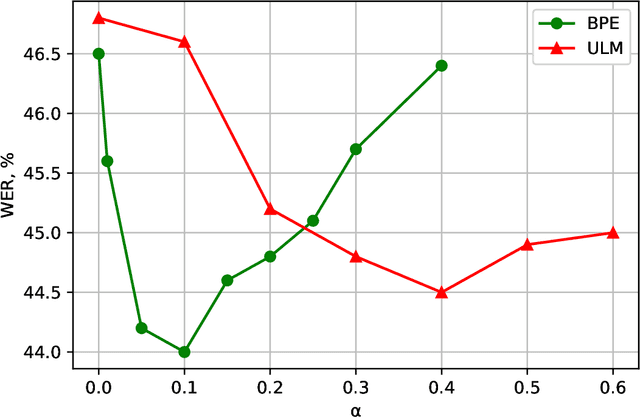
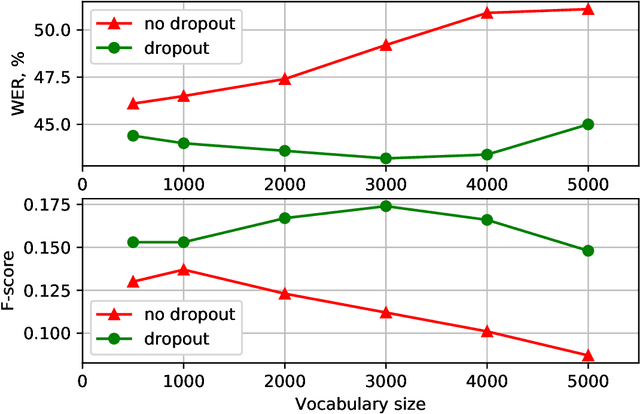
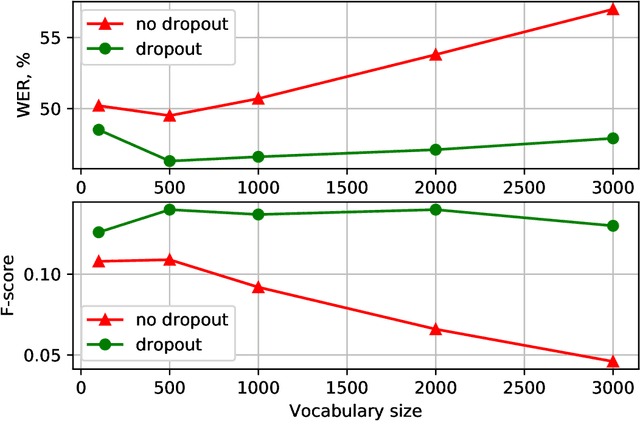
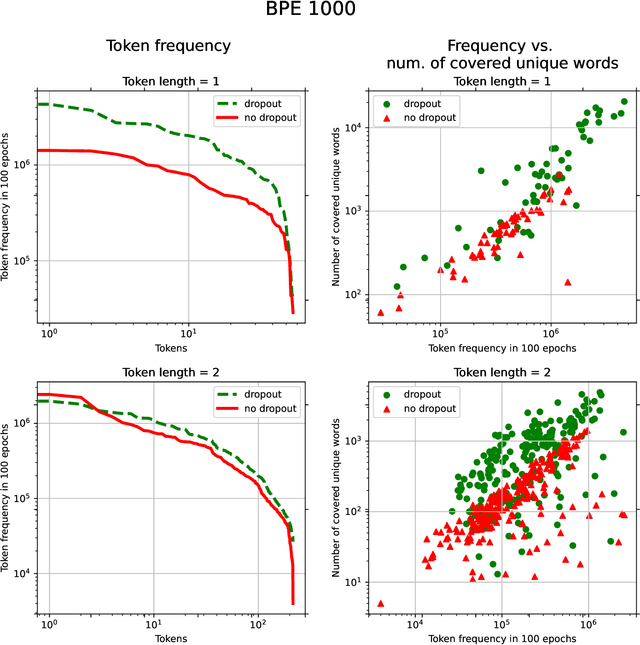
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
Exploration of End-to-End ASR for OpenSTT -- Russian Open Speech-to-Text Dataset
Jun 15, 2020
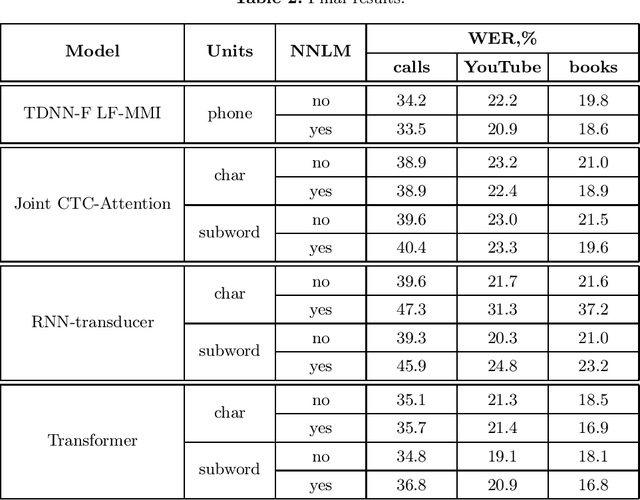
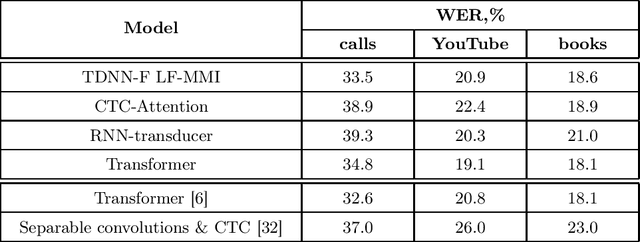
This paper presents an exploration of end-to-end automatic speech recognition systems (ASR) for the largest open-source Russian language data set -- OpenSTT. We evaluate different existing end-to-end approaches such as joint CTC/Attention, RNN-Transducer, and Transformer. All of them are compared with the strong hybrid ASR system based on LF-MMI TDNN-F acoustic model. For the three available validation sets (phone calls, YouTube, and books), our best end-to-end model achieves word error rate (WER) of 34.8%, 19.1%, and 18.1%, respectively. Under the same conditions, the hybridASR system demonstrates 33.5%, 20.9%, and 18.6% WER.
Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario
May 14, 2020
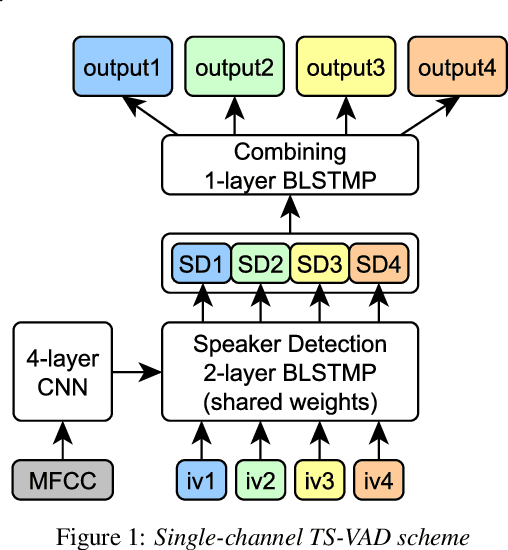
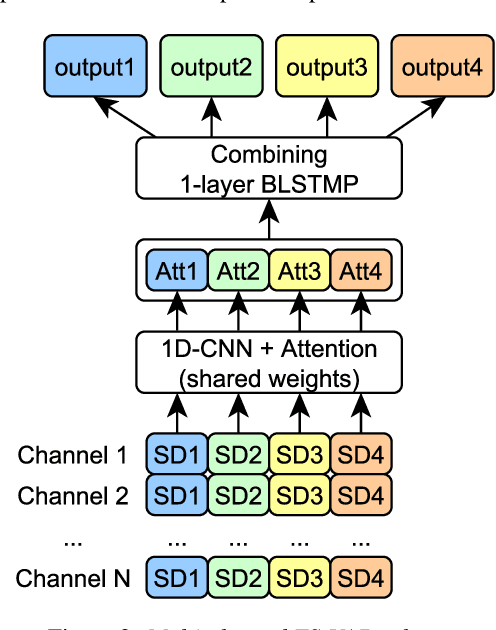
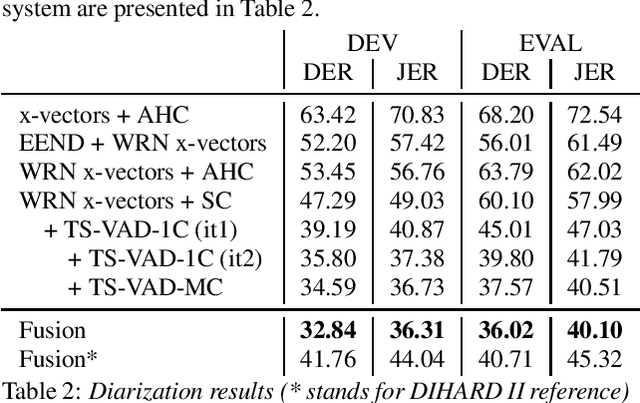
Speaker diarization for real-life scenarios is an extremely challenging problem. Widely used clustering-based diarization approaches perform rather poorly in such conditions, mainly due to the limited ability to handle overlapping speech. We propose a novel Target-Speaker Voice Activity Detection (TS-VAD) approach, which directly predicts an activity of each speaker on each time frame. TS-VAD model takes conventional speech features (e.g., MFCC) along with i-vectors for each speaker as inputs. A set of binary classification output layers produces activities of each speaker. I-vectors can be estimated iteratively, starting with a strong clustering-based diarization. We also extend the TS-VAD approach to the multi-microphone case using a simple attention mechanism on top of hidden representations extracted from the single-channel TS-VAD model. Moreover, post-processing strategies for the predicted speaker activity probabilities are investigated. Experiments on the CHiME-6 unsegmented data show that TS-VAD achieves state-of-the-art results outperforming the baseline x-vector-based system by more than 30% Diarization Error Rate (DER) abs.
You Do Not Need More Data: Improving End-To-End Speech Recognition by Text-To-Speech Data Augmentation
May 14, 2020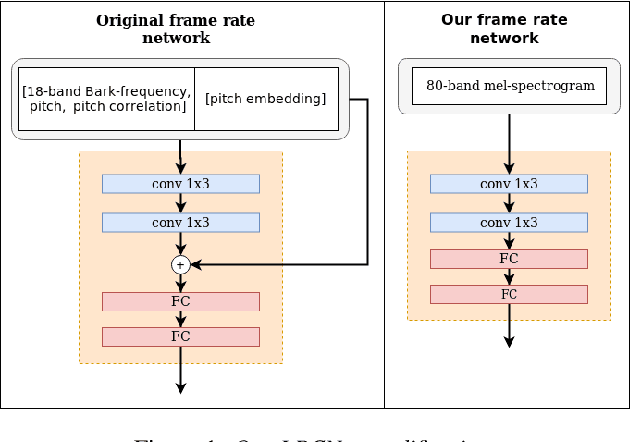
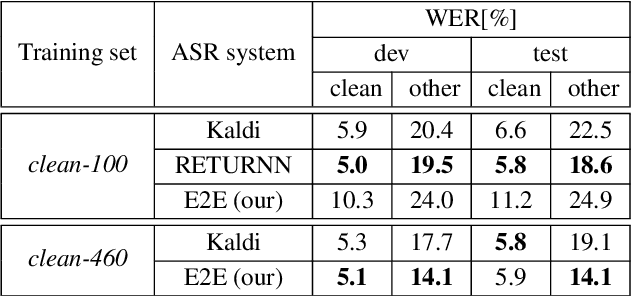
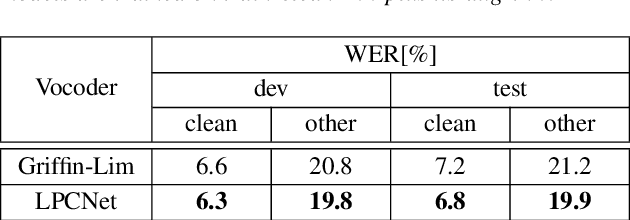
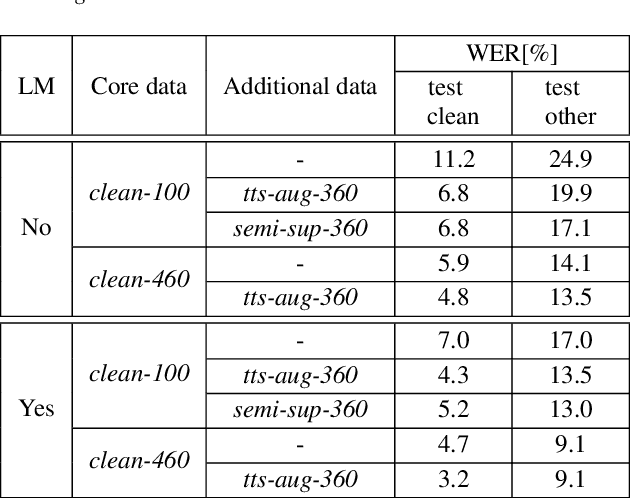
Data augmentation is one of the most effective ways to make end-to-end automatic speech recognition (ASR) perform close to the conventional hybrid approach, especially when dealing with low-resource tasks. Using recent advances in speech synthesis (text-to-speech, or TTS), we build our TTS system on an ASR training database and then extend the data with synthesized speech to train a recognition model. We argue that, when the training data amount is low, this approach can allow an end-to-end model to reach hybrid systems' quality. For an artificial low-resource setup, we compare the proposed augmentation with the semi-supervised learning technique. We also investigate the influence of vocoder usage on final ASR performance by comparing Griffin-Lim algorithm with our modified LPCNet. An external language model allows our approach to reach the quality of a comparable supervised setup and outperform a semi-supervised setup (both on test-clean). We establish a state-of-the-art result for end-to-end ASR trained on LibriSpeech train-clean-100 set with WER 4.3% on test-clean and 13.5% on test-other.
Towards a Competitive End-to-End Speech Recognition for CHiME-6 Dinner Party Transcription
Apr 24, 2020

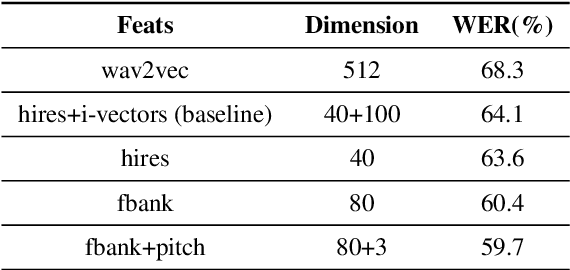

While end-to-end ASR systems have proven competitive with the conventional hybrid approach, they are prone to accuracy degradation when it comes to noisy and low-resource conditions. In this paper, we argue that, even in such difficult cases, some end-to-end approaches show performance close to the hybrid baseline. To demonstrate this, we use the CHiME-6 Challenge data as an example of challenging environments and noisy conditions of everyday speech. We experimentally compare and analyze CTC-Attention versus RNN-Transducer approaches along with RNN versus Transformer architectures. We also provide a comparison of acoustic features and speech enhancements. Besides, we evaluate the effectiveness of neural network language models for hypothesis re-scoring in low-resource conditions. Our best end-to-end model based on RNN-Transducer, together with improved beam search, reaches quality by only 3.8% WER abs. worse than the LF-MMI TDNN-F CHiME-6 Challenge baseline. With the Guided Source Separation based training data augmentation, this approach outperforms the hybrid baseline system by 2.7% WER abs. and the end-to-end system best known before by 25.7% WER abs.
Exploring End-to-End Techniques for Low-Resource Speech Recognition
Jul 02, 2018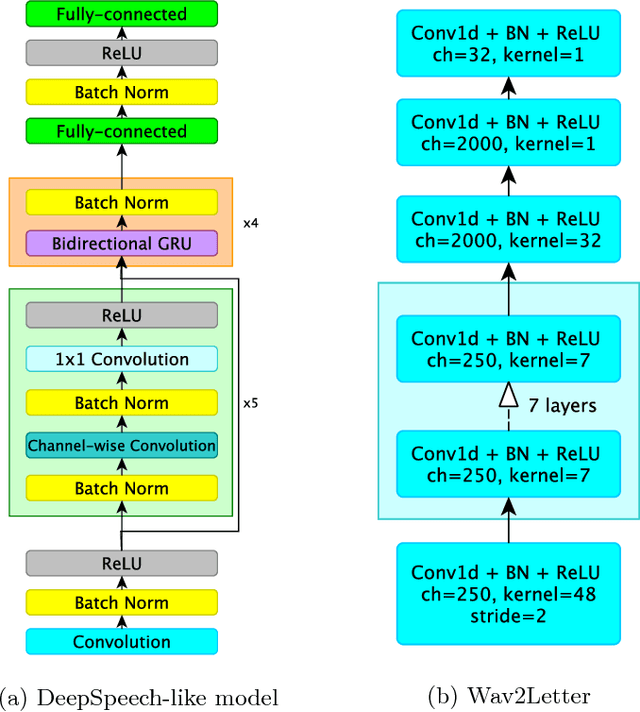
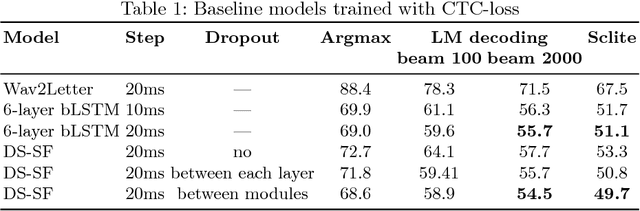
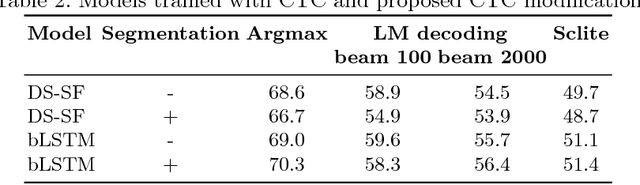
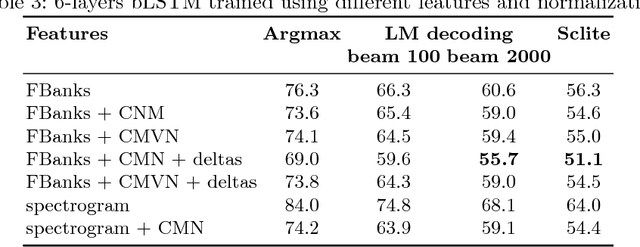
In this work we present simple grapheme-based system for low-resource speech recognition using Babel data for Turkish spontaneous speech (80 hours). We have investigated different neural network architectures performance, including fully-convolutional, recurrent and ResNet with GRU. Different features and normalization techniques are compared as well. We also proposed CTC-loss modification using segmentation during training, which leads to improvement while decoding with small beam size. Our best model achieved word error rate of 45.8%, which is the best reported result for end-to-end systems using in-domain data for this task, according to our knowledge.