 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023
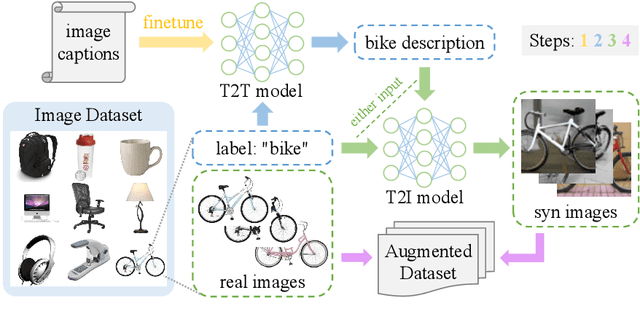
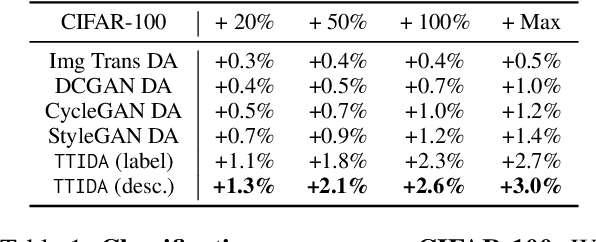
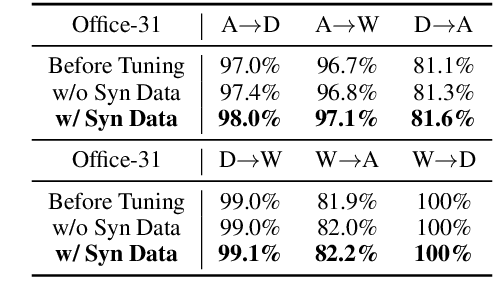
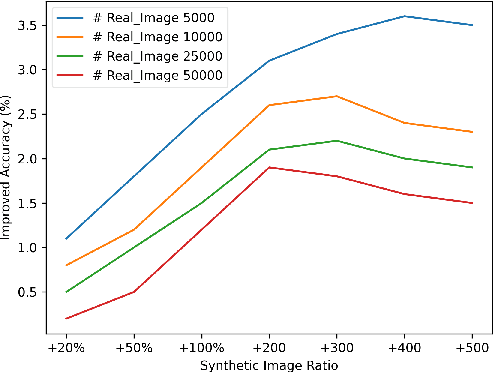
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
Adversarial Open Domain Adaption Framework (AODA): Sketch-to-Photo Synthesis
Jul 28, 2021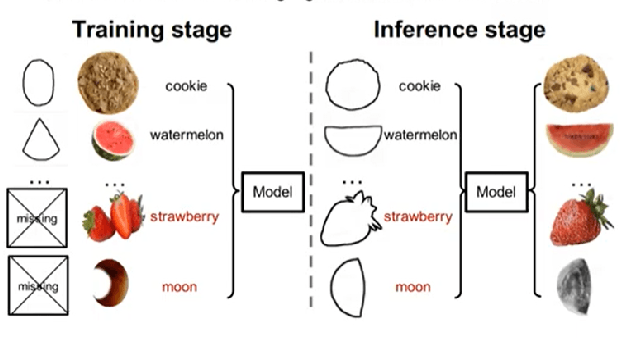

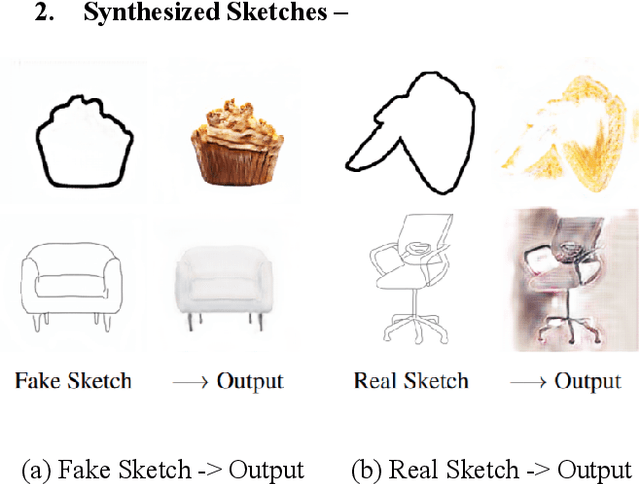
This paper aims to demonstrate the efficiency of the Adversarial Open Domain Adaption framework for sketch-to-photo synthesis. The unsupervised open domain adaption for generating realistic photos from a hand-drawn sketch is challenging as there is no such sketch of that class for training data. The absence of learning supervision and the huge domain gap between both the freehand drawing and picture domains make it hard. We present an approach that learns both sketch-to-photo and photo-to-sketch generation to synthesise the missing freehand drawings from pictures. Due to the domain gap between synthetic sketches and genuine ones, the generator trained on false drawings may produce unsatisfactory results when dealing with drawings of lacking classes. To address this problem, we offer a simple but effective open-domain sampling and optimization method that tricks the generator into considering false drawings as genuine. Our approach generalises the learnt sketch-to-photo and photo-to-sketch mappings from in-domain input to open-domain categories. On the Scribble and SketchyCOCO datasets, we compared our technique to the most current competing methods. For many types of open-domain drawings, our model outperforms impressive results in synthesising accurate colour, substance, and retaining the structural layout.
MF-NeRF: Memory Efficient NeRF with Mixed-Feature Hash Table
Apr 27, 2023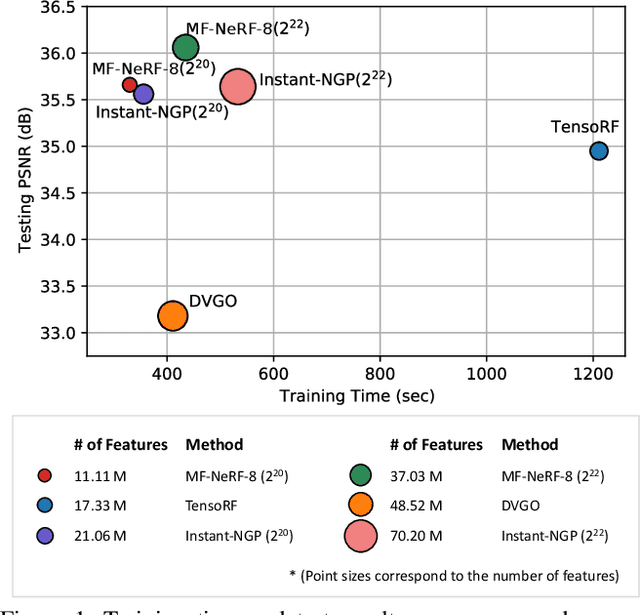
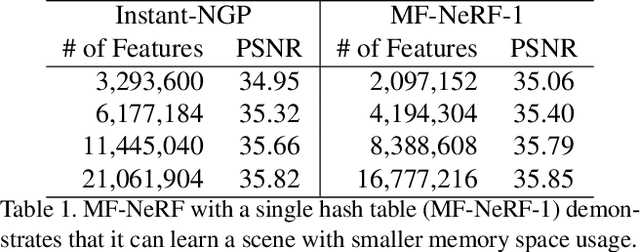
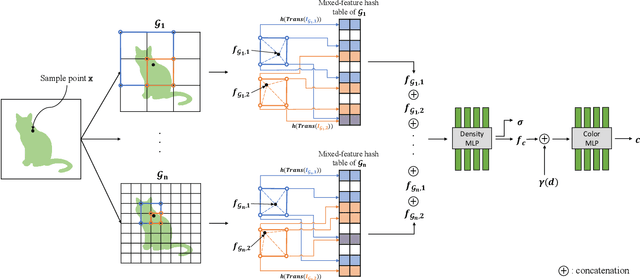

Neural radiance field (NeRF) has shown remarkable performance in generating photo-realistic novel views. Since the emergence of NeRF, many studies have been conducted, among which managing features with explicit structures such as grids has achieved exceptionally fast training by reducing the complexity of multilayer perceptron (MLP) networks. However, storing features in dense grids requires significantly large memory space, which leads to memory bottleneck in computer systems and thus large training time. To address this issue, in this work, we propose MF-NeRF, a memory-efficient NeRF framework that employs a mixed-feature hash table to improve memory efficiency and reduce training time while maintaining reconstruction quality. We first design a mixed-feature hash table to adaptively mix part of multi-level feature grids into one and map it to a single hash table. Following that, in order to obtain the correct index of a grid point, we further design an index transformation method that transforms indices of an arbitrary level grid to those of a canonical grid. Extensive experiments benchmarking with state-of-the-art Instant-NGP, TensoRF, and DVGO, indicate our MF-NeRF could achieve the fastest training time on the same GPU hardware with similar or even higher reconstruction quality. Source code is available at https://github.com/nfyfamr/MF-NeRF.
NPR: Nocturnal Place Recognition in Streets
Apr 17, 2023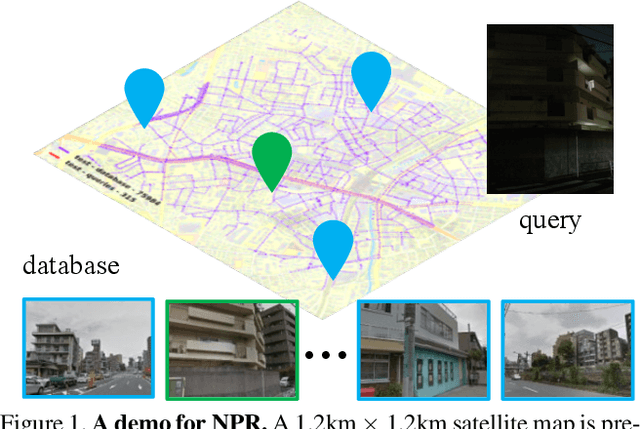
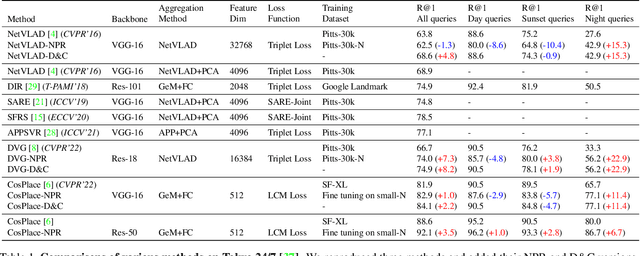


Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023
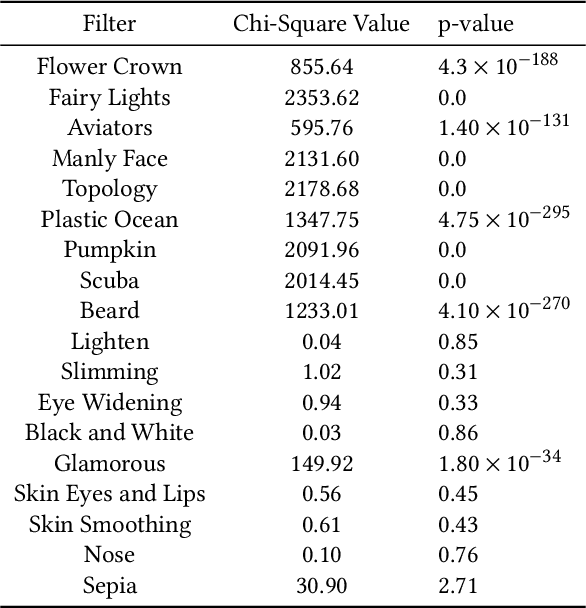

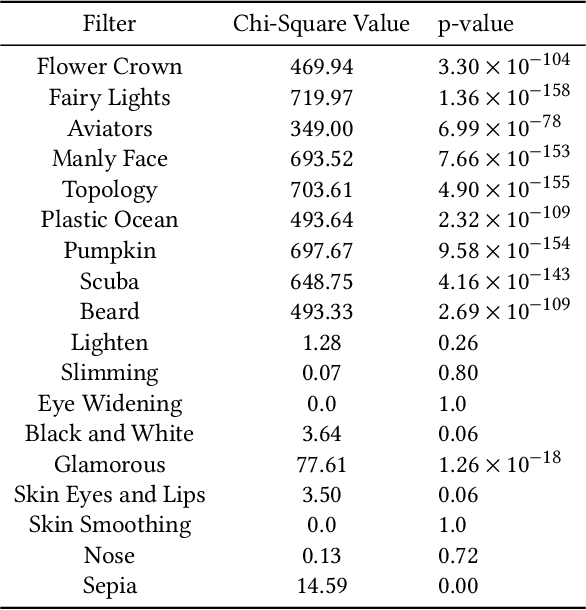
Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.
Inferring Fluid Dynamics via Inverse Rendering
Apr 10, 2023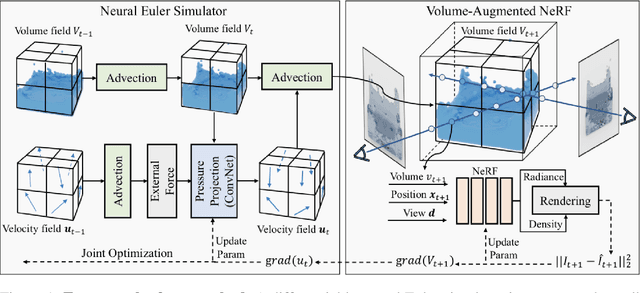


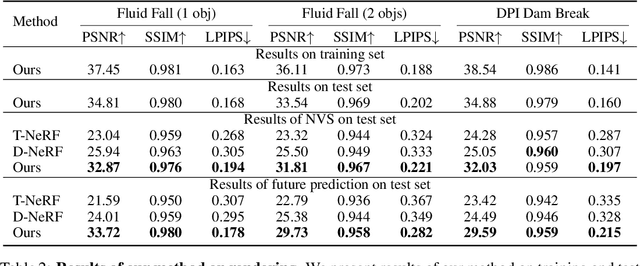
Humans have a strong intuitive understanding of physical processes such as fluid falling by just a glimpse of such a scene picture, i.e., quickly derived from our immersive visual experiences in memory. This work achieves such a photo-to-fluid-dynamics reconstruction functionality learned from unannotated videos, without any supervision of ground-truth fluid dynamics. In a nutshell, a differentiable Euler simulator modeled with a ConvNet-based pressure projection solver, is integrated with a volumetric renderer, supporting end-to-end/coherent differentiable dynamic simulation and rendering. By endowing each sampled point with a fluid volume value, we derive a NeRF-like differentiable renderer dedicated from fluid data; and thanks to this volume-augmented representation, fluid dynamics could be inversely inferred from the error signal between the rendered result and ground-truth video frame (i.e., inverse rendering). Experiments on our generated Fluid Fall datasets and DPI Dam Break dataset are conducted to demonstrate both effectiveness and generalization ability of our method.
Deep Photo Cropper and Enhancer
Aug 03, 2020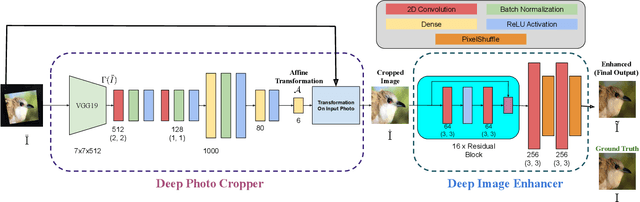


This paper introduces a new type of image enhancement problem. Compared to traditional image enhancement methods, which mostly deal with pixel-wise modifications of a given photo, our proposed task is to crop an image which is embedded within a photo and enhance the quality of the cropped image. We split our proposed approach into two deep networks: deep photo cropper and deep image enhancer. In the photo cropper network, we employ a spatial transformer to extract the embedded image. In the photo enhancer, we employ super-resolution to increase the number of pixels in the embedded image and reduce the effect of stretching and distortion of pixels. We use cosine distance loss between image features and ground truth for the cropper and the mean square loss for the enhancer. Furthermore, we propose a new dataset to train and test the proposed method. Finally, we analyze the proposed method with respect to qualitative and quantitative evaluations.
ViP-NeRF: Visibility Prior for Sparse Input Neural Radiance Fields
Apr 28, 2023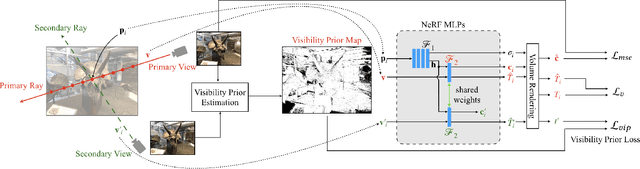
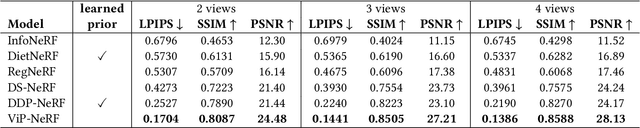
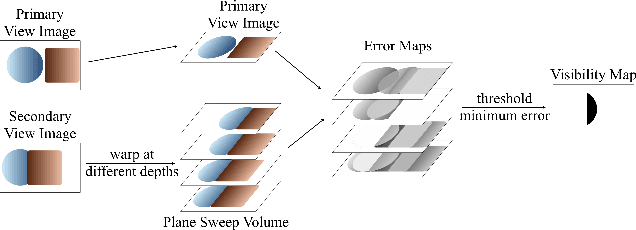
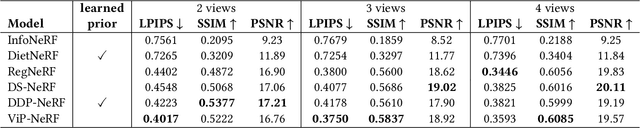
Neural radiance fields (NeRF) have achieved impressive performances in view synthesis by encoding neural representations of a scene. However, NeRFs require hundreds of images per scene to synthesize photo-realistic novel views. Training them on sparse input views leads to overfitting and incorrect scene depth estimation resulting in artifacts in the rendered novel views. Sparse input NeRFs were recently regularized by providing dense depth estimated from pre-trained networks as supervision, to achieve improved performance over sparse depth constraints. However, we find that such depth priors may be inaccurate due to generalization issues. Instead, we hypothesize that the visibility of pixels in different input views can be more reliably estimated to provide dense supervision. In this regard, we compute a visibility prior through the use of plane sweep volumes, which does not require any pre-training. By regularizing the NeRF training with the visibility prior, we successfully train the NeRF with few input views. We reformulate the NeRF to also directly output the visibility of a 3D point from a given viewpoint to reduce the training time with the visibility constraint. On multiple datasets, our model outperforms the competing sparse input NeRF models including those that use learned priors. The source code for our model can be found on our project page: https://nagabhushansn95.github.io/publications/2023/ViP-NeRF.html.
Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation
Mar 02, 2023
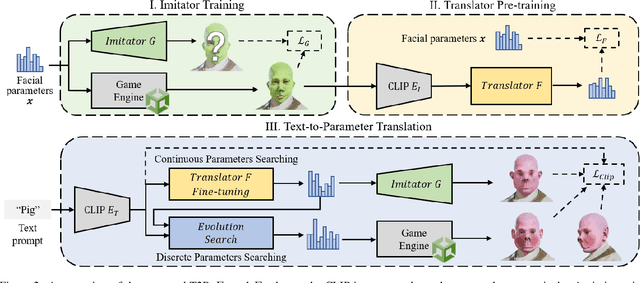

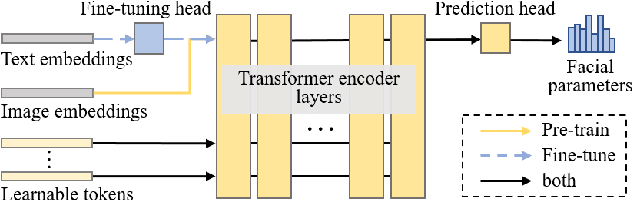
Recent popular Role-Playing Games (RPGs) saw the great success of character auto-creation systems. The bone-driven face model controlled by continuous parameters (like the position of bones) and discrete parameters (like the hairstyles) makes it possible for users to personalize and customize in-game characters. Previous in-game character auto-creation systems are mostly image-driven, where facial parameters are optimized so that the rendered character looks similar to the reference face photo. This paper proposes a novel text-to-parameter translation method (T2P) to achieve zero-shot text-driven game character auto-creation. With our method, users can create a vivid in-game character with arbitrary text description without using any reference photo or editing hundreds of parameters manually. In our method, taking the power of large-scale pre-trained multi-modal CLIP and neural rendering, T2P searches both continuous facial parameters and discrete facial parameters in a unified framework. Due to the discontinuous parameter representation, previous methods have difficulty in effectively learning discrete facial parameters. T2P, to our best knowledge, is the first method that can handle the optimization of both discrete and continuous parameters. Experimental results show that T2P can generate high-quality and vivid game characters with given text prompts. T2P outperforms other SOTA text-to-3D generation methods on both objective evaluations and subjective evaluations.
Audio-Driven Talking Face Generation with Diverse yet Realistic Facial Animations
Apr 18, 2023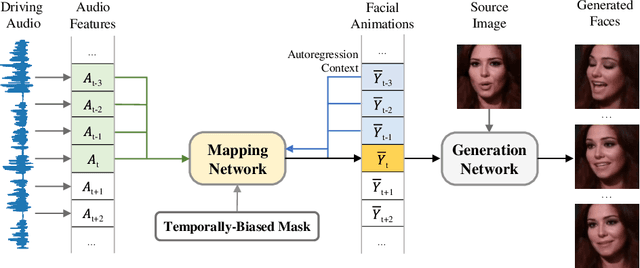
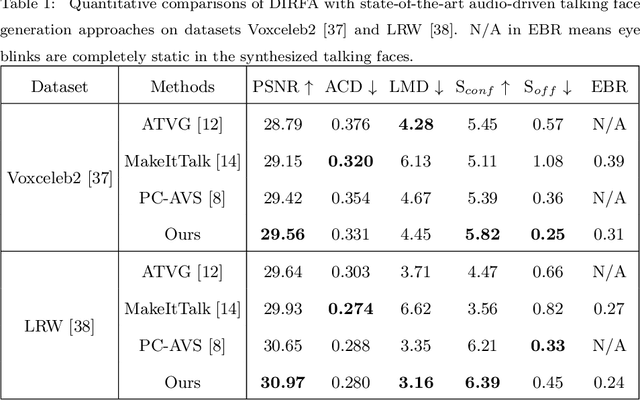

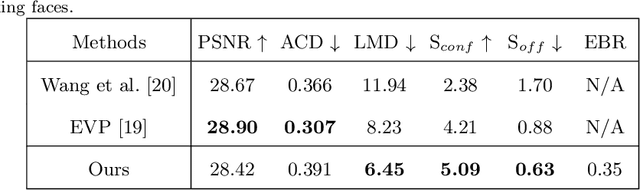
Audio-driven talking face generation, which aims to synthesize talking faces with realistic facial animations (including accurate lip movements, vivid facial expression details and natural head poses) corresponding to the audio, has achieved rapid progress in recent years. However, most existing work focuses on generating lip movements only without handling the closely correlated facial expressions, which degrades the realism of the generated faces greatly. This paper presents DIRFA, a novel method that can generate talking faces with diverse yet realistic facial animations from the same driving audio. To accommodate fair variation of plausible facial animations for the same audio, we design a transformer-based probabilistic mapping network that can model the variational facial animation distribution conditioned upon the input audio and autoregressively convert the audio signals into a facial animation sequence. In addition, we introduce a temporally-biased mask into the mapping network, which allows to model the temporal dependency of facial animations and produce temporally smooth facial animation sequence. With the generated facial animation sequence and a source image, photo-realistic talking faces can be synthesized with a generic generation network. Extensive experiments show that DIRFA can generate talking faces with realistic facial animations effectively.