 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Open Domain Adaption Framework (AODA): Sketch-to-Photo Synthesis
Aug 19, 2021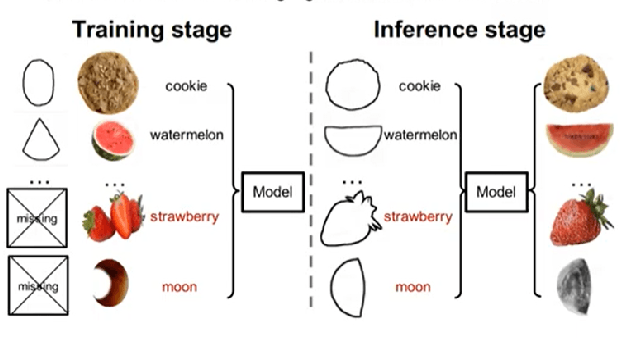

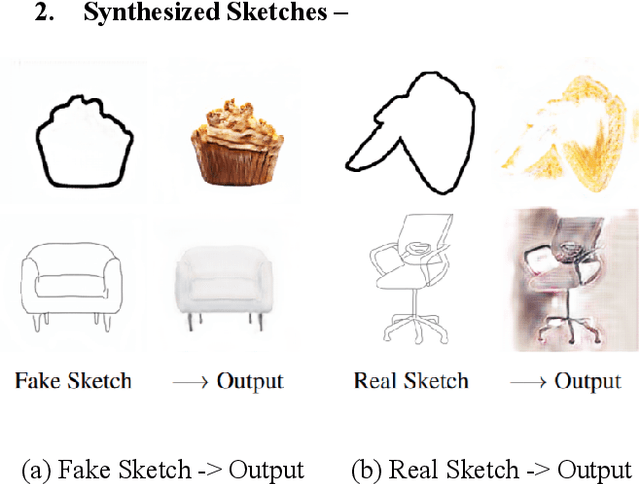
This paper aims to demonstrate the efficiency of the Adversarial Open Domain Adaption framework for sketch-to-photo synthesis. The unsupervised open domain adaption for generating realistic photos from a hand-drawn sketch is challenging as there is no such sketch of that class for training data. The absence of learning supervision and the huge domain gap between both the freehand drawing and picture domains make it hard. We present an approach that learns both sketch-to-photo and photo-to-sketch generation to synthesise the missing freehand drawings from pictures. Due to the domain gap between synthetic sketches and genuine ones, the generator trained on false drawings may produce unsatisfactory results when dealing with drawings of lacking classes. To address this problem, we offer a simple but effective open-domain sampling and optimization method that tricks the generator into considering false drawings as genuine. Our approach generalises the learnt sketch-to-photo and photo-to-sketch mappings from in-domain input to open-domain categories. On the Scribble and SketchyCOCO datasets, we compared our technique to the most current competing methods. For many types of open-domain drawings, our model outperforms impressive results in synthesising accurate colour, substance, and retaining the structural layout.
White-Box Cartoonization Using An Extended GAN Framework
Jul 09, 2021In the present study, we propose to implement a new framework for estimating generative models via an adversarial process to extend an existing GAN framework and develop a white-box controllable image cartoonization, which can generate high-quality cartooned images/videos from real-world photos and videos. The learning purposes of our system are based on three distinct representations: surface representation, structure representation, and texture representation. The surface representation refers to the smooth surface of the images. The structure representation relates to the sparse colour blocks and compresses generic content. The texture representation shows the texture, curves, and features in cartoon images. Generative Adversarial Network (GAN) framework decomposes the images into different representations and learns from them to generate cartoon images. This decomposition makes the framework more controllable and flexible which allows users to make changes based on the required output. This approach overcomes any previous system in terms of maintaining clarity, colours, textures, shapes of images yet showing the characteristics of cartoon images.