 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Guidance and Evaluation: Semantic-Aware Image Inpainting for Mixed Scenes
Mar 17, 2020
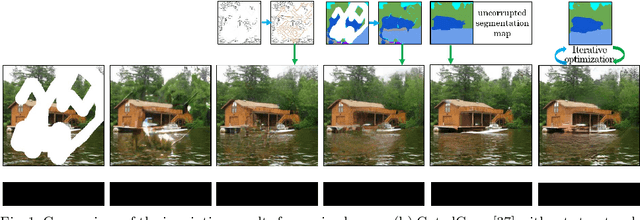
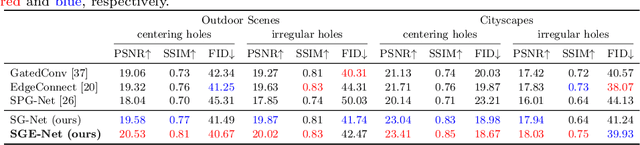
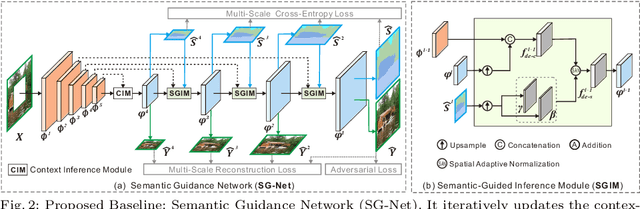

Completing a corrupted image with correct structures and reasonable textures for a mixed scene remains an elusive challenge. Since the missing hole in a mixed scene of a corrupted image often contains various semantic information, conventional two-stage approaches utilizing structural information often lead to the problem of unreliable structural prediction and ambiguous image texture generation. In this paper, we propose a Semantic Guidance and Evaluation Network (SGE-Net) to iteratively update the structural priors and the inpainted image in an interplay framework of semantics extraction and image inpainting. It utilizes semantic segmentation map as guidance in each scale of inpainting, under which location-dependent inferences are re-evaluated, and, accordingly, poorly-inferred regions are refined in subsequent scales. Extensive experiments on real-world images of mixed scenes demonstrated the superiority of our proposed method over state-of-the-art approaches, in terms of clear boundaries and photo-realistic textures.
Robust Re-identification of Manta Rays from Natural Markings by Learning Pose Invariant Embeddings
Feb 28, 2019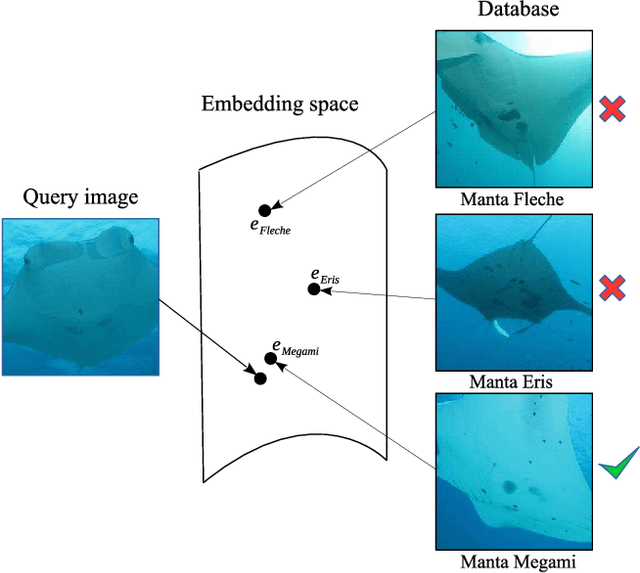
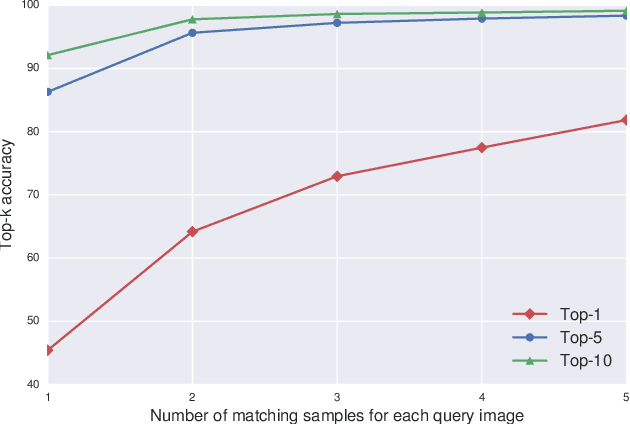


Visual identification of individual animals that bear unique natural body markings is an important task in wildlife conservation. The photo databases of animal markings grow larger and each new observation has to be matched against thousands of images. Existing photo-identification solutions have constraints on image quality and appearance of the pattern of interest in the image. These constraints limit the use of photos from citizen scientists. We present a novel system for visual re-identification based on unique natural markings that is robust to occlusions, viewpoint and illumination changes. We adapt methods developed for face re-identification and implement a deep convolutional neural network (CNN) to learn embeddings for images of natural markings. The distance between the learned embedding points provides a dissimilarity measure between the corresponding input images. The network is optimized using the triplet loss function and the online semi-hard triplet mining strategy. The proposed re-identification method is generic and not species specific. We evaluate the proposed system on image databases of manta ray belly patterns and humpback whale flukes. To be of practical value and adopted by marine biologists, a re-identification system needs to have a top-10 accuracy of at least 95%. The proposed system achieves this performance standard.
Neural Imaging Pipelines - the Scourge or Hope of Forensics?
Feb 27, 2019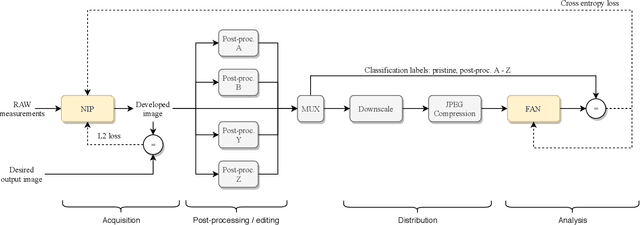
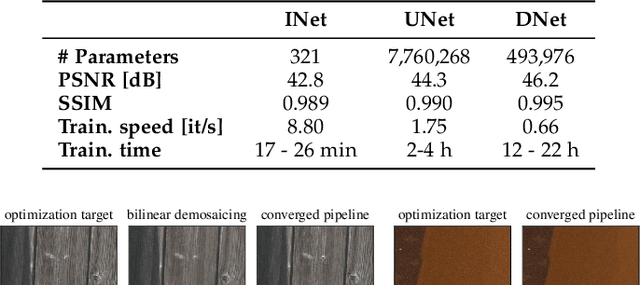
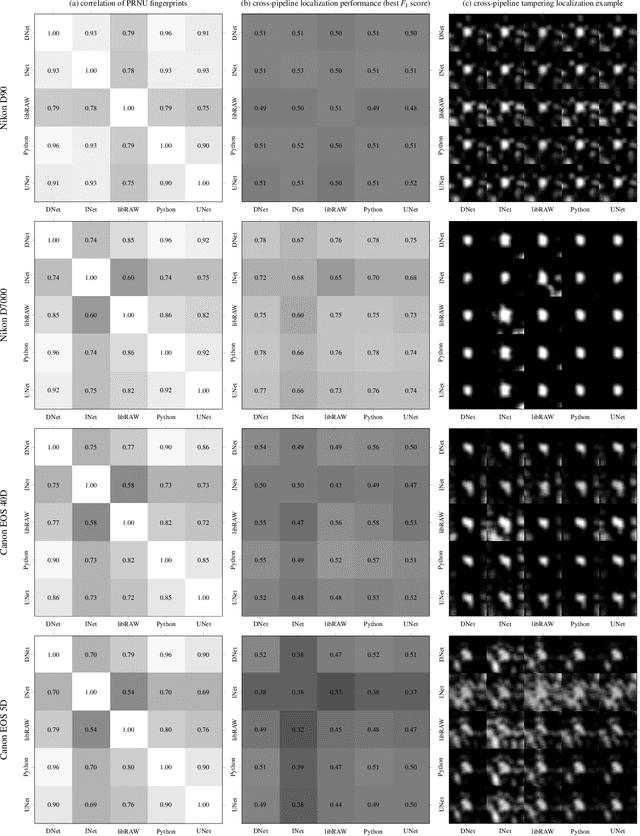
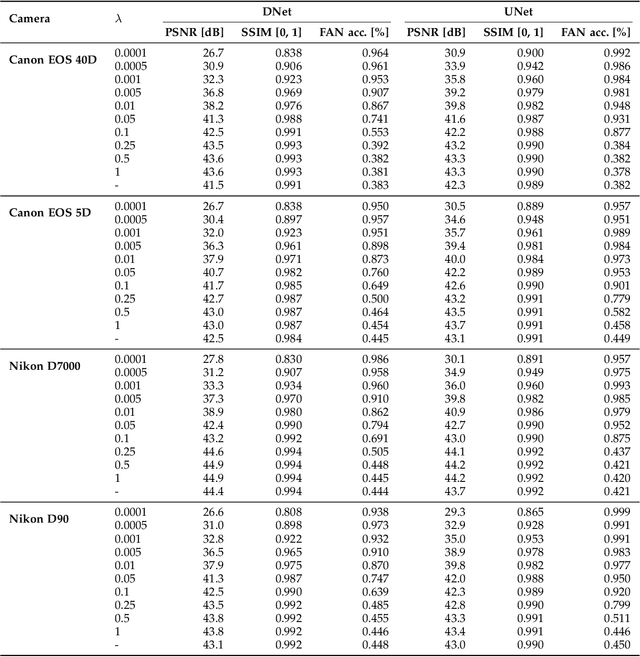
Forensic analysis of digital photographs relies on intrinsic statistical traces introduced at the time of their acquisition or subsequent editing. Such traces are often removed by post-processing (e.g., down-sampling and re-compression applied upon distribution in the Web) which inhibits reliable provenance analysis. Increasing adoption of computational methods within digital cameras further complicates the process and renders explicit mathematical modeling infeasible. While this trend challenges forensic analysis even in near-acquisition conditions, it also creates new opportunities. This paper explores end-to-end optimization of the entire image acquisition and distribution workflow to facilitate reliable forensic analysis at the end of the distribution channel, where state-of-the-art forensic techniques fail. We demonstrate that a neural network can be trained to replace the entire photo development pipeline, and jointly optimized for high-fidelity photo rendering and reliable provenance analysis. Such optimized neural imaging pipeline allowed us to increase image manipulation detection accuracy from approx. 45% to over 90%. The network learns to introduce carefully crafted artifacts, akin to digital watermarks, which facilitate subsequent manipulation detection. Analysis of performance trade-offs indicates that most of the gains can be obtained with only minor distortion. The findings encourage further research towards building more reliable imaging pipelines with explicit provenance-guaranteeing properties.
Cross-domain Correspondence Learning for Exemplar-based Image Translation
Apr 12, 2020
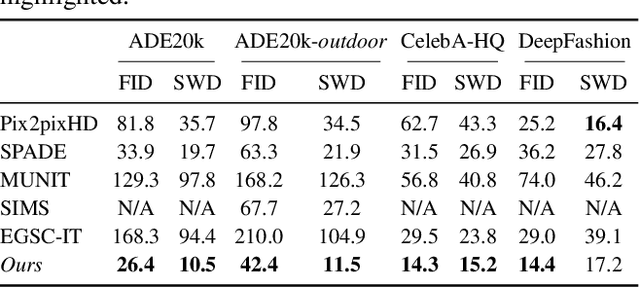
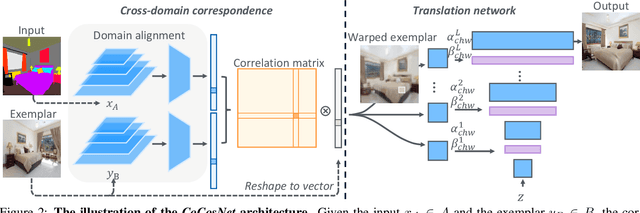
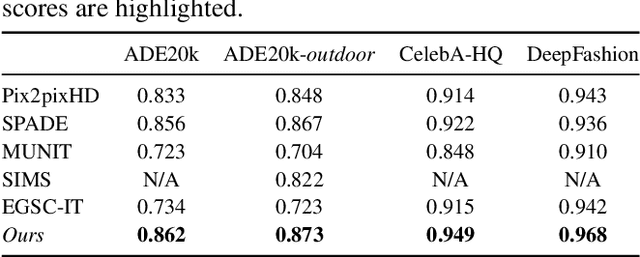
We present a general framework for exemplar-based image translation, which synthesizes a photo-realistic image from the input in a distinct domain (e.g., semantic segmentation mask, or edge map, or pose keypoints), given an exemplar image. The output has the style (e.g., color, texture) in consistency with the semantically corresponding objects in the exemplar. We propose to jointly learn the crossdomain correspondence and the image translation, where both tasks facilitate each other and thus can be learned with weak supervision. The images from distinct domains are first aligned to an intermediate domain where dense correspondence is established. Then, the network synthesizes images based on the appearance of semantically corresponding patches in the exemplar. We demonstrate the effectiveness of our approach in several image translation tasks. Our method is superior to state-of-the-art methods in terms of image quality significantly, with the image style faithful to the exemplar with semantic consistency. Moreover, we show the utility of our method for several applications
* Accepted as a CVPR 2020 oral paper
Microvascular Dynamics from 4D Microscopy Using Temporal Segmentation
Jan 14, 2020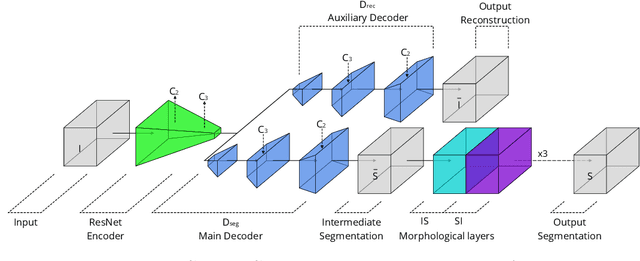



Recently developed methods for rapid continuous volumetric two-photon microscopy facilitate the observation of neuronal activity in hundreds of individual neurons and changes in blood flow in adjacent blood vessels across a large volume of living brain at unprecedented spatio-temporal resolution. However, the high imaging rate necessitates fully automated image analysis, whereas tissue turbidity and photo-toxicity limitations lead to extremely sparse and noisy imagery. In this work, we extend a recently proposed deep learning volumetric blood vessel segmentation network, such that it supports temporal analysis. With this technology, we are able to track changes in cerebral blood volume over time and identify spontaneous arterial dilations that propagate towards the pial surface. This new capability is a promising step towards characterizing the hemodynamic response function upon which functional magnetic resonance imaging (fMRI) is based.
Learning to plan with uncertain topological maps
Jul 10, 2020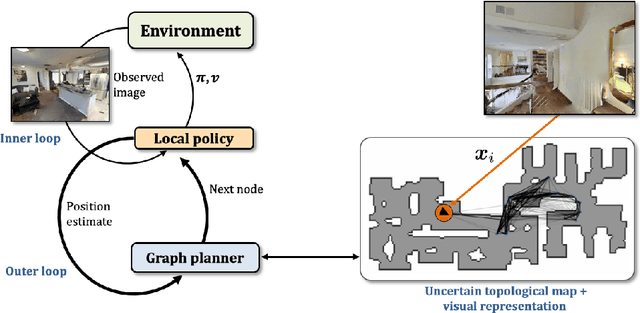

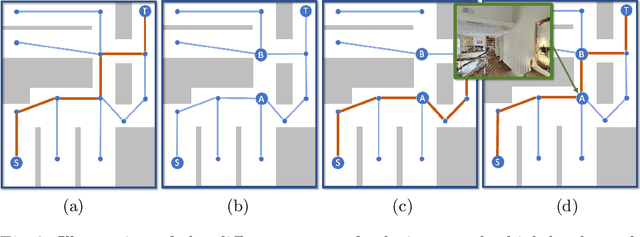

We train an agent to navigate in 3D environments using a hierarchical strategy including a high-level graph based planner and a local policy. Our main contribution is a data driven learning based approach for planning under uncertainty in topological maps, requiring an estimate of shortest paths in valued graphs with a probabilistic structure. Whereas classical symbolic algorithms achieve optimal results on noise-less topologies, or optimal results in a probabilistic sense on graphs with probabilistic structure, we aim to show that machine learning can overcome missing information in the graph by taking into account rich high-dimensional node features, for instance visual information available at each location of the map. Compared to purely learned neural white box algorithms, we structure our neural model with an inductive bias for dynamic programming based shortest path algorithms, and we show that a particular parameterization of our neural model corresponds to the Bellman-Ford algorithm. By performing an empirical analysis of our method in simulated photo-realistic 3D environments, we demonstrate that the inclusion of visual features in the learned neural planner outperforms classical symbolic solutions for graph based planning.
Topic Adaptation and Prototype Encoding for Few-Shot Visual Storytelling
Aug 11, 2020

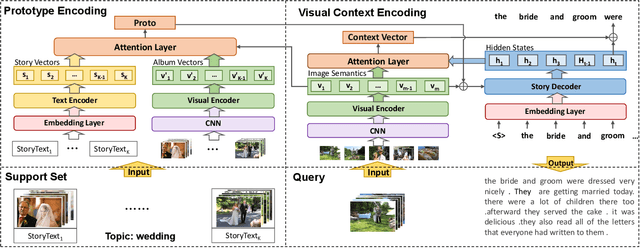
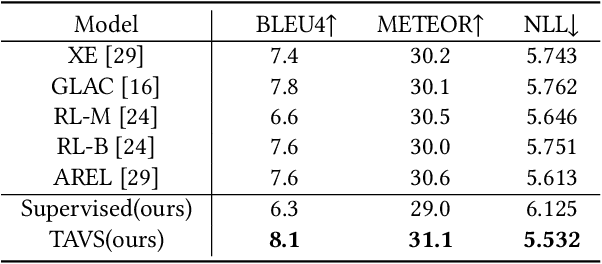
Visual Storytelling~(VIST) is a task to tell a narrative story about a certain topic according to the given photo stream. The existing studies focus on designing complex models, which rely on a huge amount of human-annotated data. However, the annotation of VIST is extremely costly and many topics cannot be covered in the training dataset due to the long-tail topic distribution. In this paper, we focus on enhancing the generalization ability of the VIST model by considering the few-shot setting. Inspired by the way humans tell a story, we propose a topic adaptive storyteller to model the ability of inter-topic generalization. In practice, we apply the gradient-based meta-learning algorithm on multi-modal seq2seq models to endow the model the ability to adapt quickly from topic to topic. Besides, We further propose a prototype encoding structure to model the ability of intra-topic derivation. Specifically, we encode and restore the few training story text to serve as a reference to guide the generation at inference time. Experimental results show that topic adaptation and prototype encoding structure mutually bring benefit to the few-shot model on BLEU and METEOR metric. The further case study shows that the stories generated after few-shot adaptation are more relative and expressive.
SRFlow: Learning the Super-Resolution Space with Normalizing Flow
Jun 25, 2020

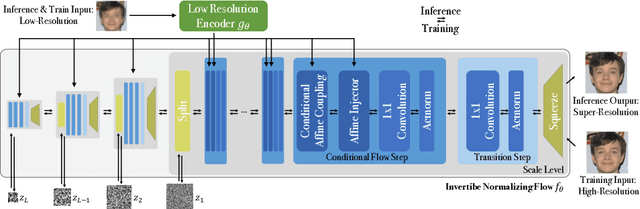
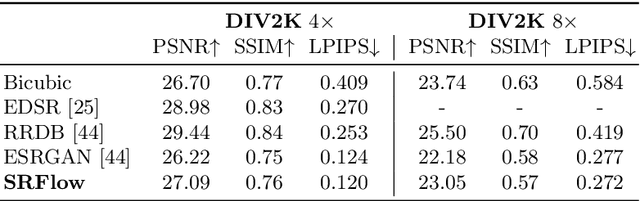
Super-resolution is an ill-posed problem, since it allows for multiple predictions for a given low-resolution image. This fundamental fact is largely ignored by state-of-the-art deep learning based approaches. These methods instead train a deterministic mapping using combinations of reconstruction and adversarial losses. In this work, we therefore propose SRFlow: a normalizing flow based super-resolution method capable of learning the conditional distribution of the output given the low-resolution input. Our model is trained in a principled manner using a single loss, namely the negative log-likelihood. SRFlow therefore directly accounts for the ill-posed nature of the problem, and learns to predict diverse photo-realistic high-resolution images. Moreover, we utilize the strong image posterior learned by SRFlow to design flexible image manipulation techniques, capable of enhancing super-resolved images by, e.g., transferring content from other images. We perform extensive experiments on faces, as well as on super-resolution in general. SRFlow outperforms state-of-the-art GAN-based approaches in terms of both PSNR and perceptual quality metrics, while allowing for diversity through the exploration of the space of super-resolved solutions.
Large Scale Landmark Recognition via Deep Metric Learning
Aug 29, 2019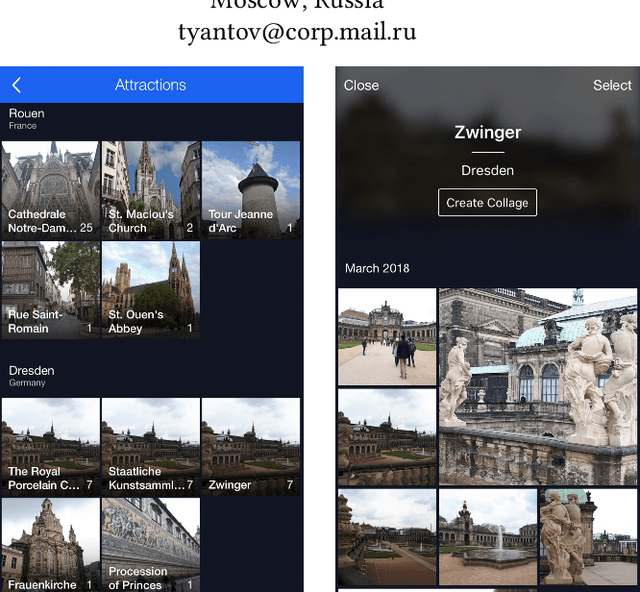
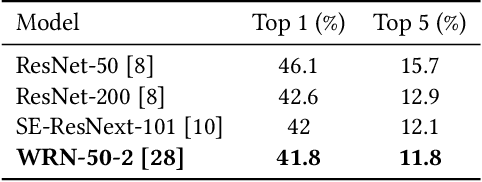
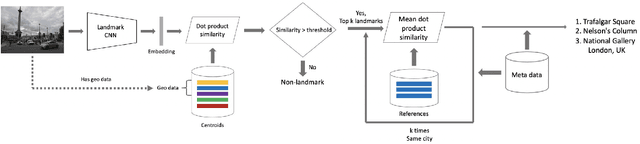
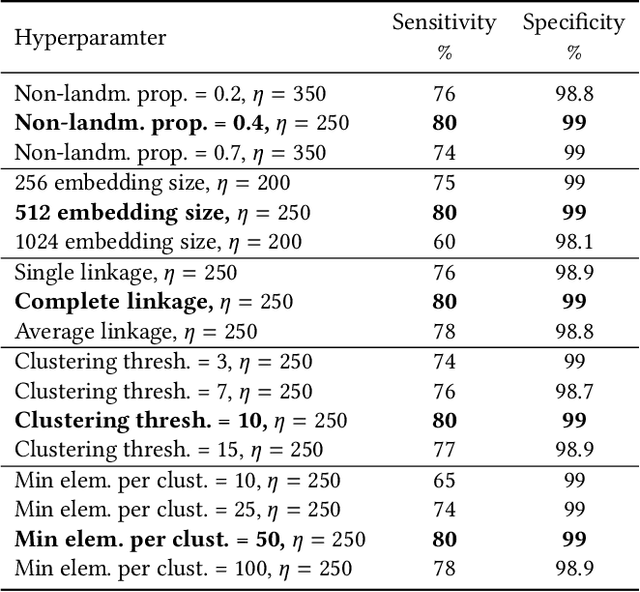
This paper presents a novel approach for landmark recognition in images that we've successfully deployed at Mail ru. This method enables us to recognize famous places, buildings, monuments, and other landmarks in user photos. The main challenge lies in the fact that it's very complicated to give a precise definition of what is and what is not a landmark. Some buildings, statues and natural objects are landmarks; others are not. There's also no database with a fairly large number of landmarks to train a recognition model. A key feature of using landmark recognition in a production environment is that the number of photos containing landmarks is extremely small. This is why the model should have a very low false positive rate as well as high recognition accuracy. We propose a metric learning-based approach that successfully deals with existing challenges and efficiently handles a large number of landmarks. Our method uses a deep neural network and requires a single pass inference that makes it fast to use in production. We also describe an algorithm for cleaning landmarks database which is essential for training a metric learning model. We provide an in-depth description of basic components of our method like neural network architecture, the learning strategy, and the features of our metric learning approach. We show the results of proposed solutions in tests that emulate the distribution of photos with and without landmarks from a user collection. We compare our method with others during these tests. The described system has been deployed as a part of a photo recognition solution at Cloud Mail ru, which is the photo sharing and storage service at Mail ru Group.