 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Adaptation and Prototype Encoding for Few-Shot Visual Storytelling
Paper and Code
Aug 11, 2020

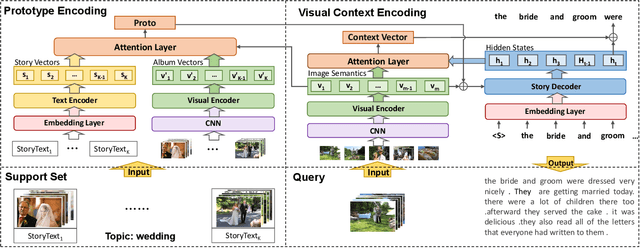
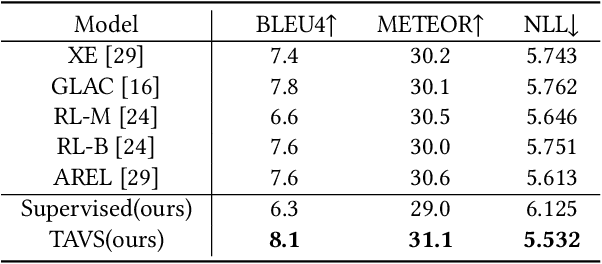
Visual Storytelling~(VIST) is a task to tell a narrative story about a certain topic according to the given photo stream. The existing studies focus on designing complex models, which rely on a huge amount of human-annotated data. However, the annotation of VIST is extremely costly and many topics cannot be covered in the training dataset due to the long-tail topic distribution. In this paper, we focus on enhancing the generalization ability of the VIST model by considering the few-shot setting. Inspired by the way humans tell a story, we propose a topic adaptive storyteller to model the ability of inter-topic generalization. In practice, we apply the gradient-based meta-learning algorithm on multi-modal seq2seq models to endow the model the ability to adapt quickly from topic to topic. Besides, We further propose a prototype encoding structure to model the ability of intra-topic derivation. Specifically, we encode and restore the few training story text to serve as a reference to guide the generation at inference time. Experimental results show that topic adaptation and prototype encoding structure mutually bring benefit to the few-shot model on BLEU and METEOR metric. The further case study shows that the stories generated after few-shot adaptation are more relative and expressive.