 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
AI-Based Affective Music Generation Systems: A Review of Methods, and Challenges
Jan 10, 2023
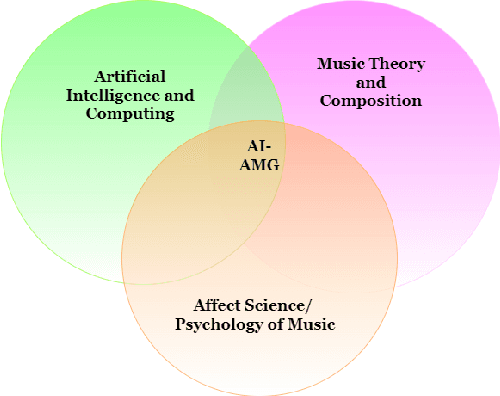
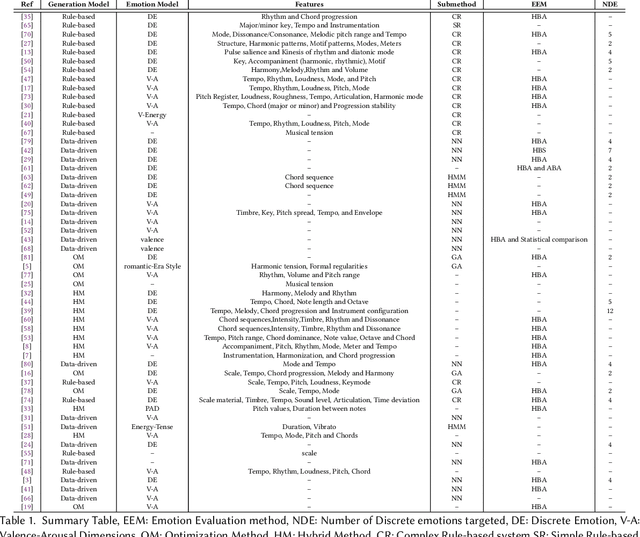
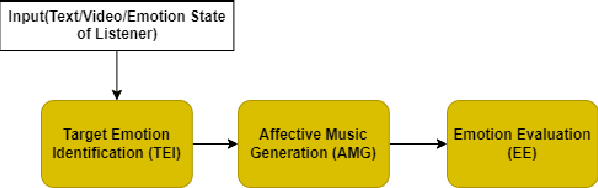

Music is a powerful medium for altering the emotional state of the listener. In recent years, with significant advancement in computing capabilities, artificial intelligence-based (AI-based) approaches have become popular for creating affective music generation (AMG) systems that are empowered with the ability to generate affective music. Entertainment, healthcare, and sensor-integrated interactive system design are a few of the areas in which AI-based affective music generation (AI-AMG) systems may have a significant impact. Given the surge of interest in this topic, this article aims to provide a comprehensive review of AI-AMG systems. The main building blocks of an AI-AMG system are discussed, and existing systems are formally categorized based on the core algorithm used for music generation. In addition, this article discusses the main musical features employed to compose affective music, along with the respective AI-based approaches used for tailoring them. Lastly, the main challenges and open questions in this field, as well as their potential solutions, are presented to guide future research. We hope that this review will be useful for readers seeking to understand the state-of-the-art in AI-AMG systems, and gain an overview of the methods used for developing them, thereby helping them explore this field in the future.
Multi-Modality in Music: Predicting Emotion in Music from High-Level Audio Features and Lyrics
Feb 26, 2023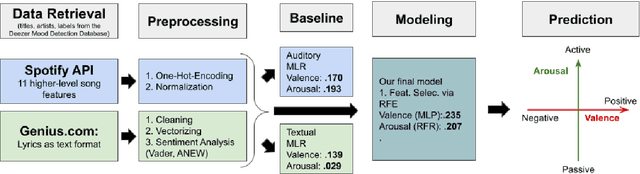
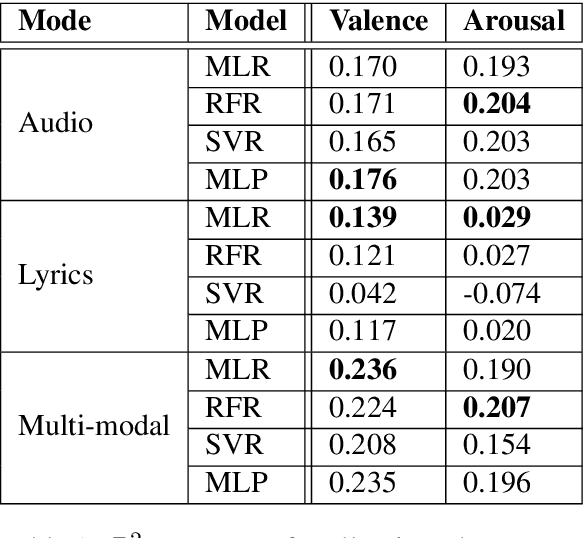
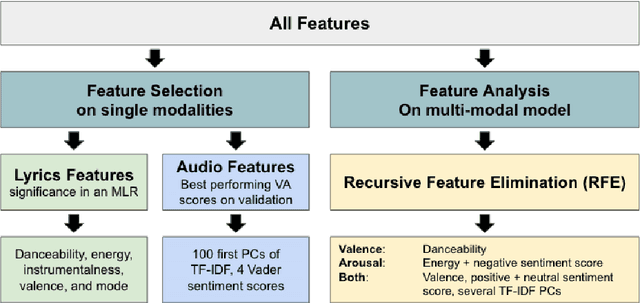
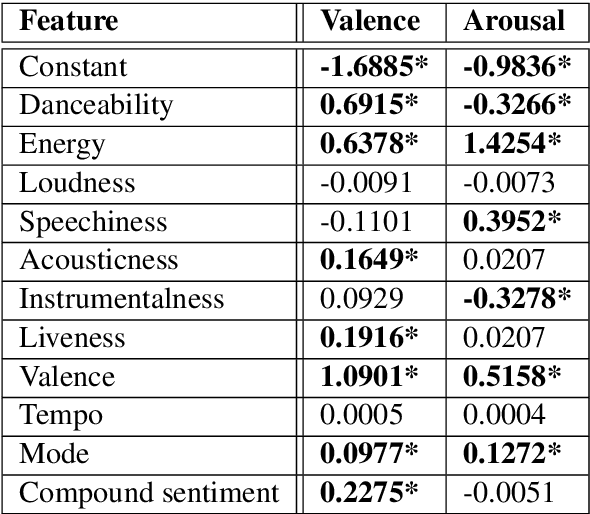
This paper aims to test whether a multi-modal approach for music emotion recognition (MER) performs better than a uni-modal one on high-level song features and lyrics. We use 11 song features retrieved from the Spotify API, combined lyrics features including sentiment, TF-IDF, and Anew to predict valence and arousal (Russell, 1980) scores on the Deezer Mood Detection Dataset (DMDD) (Delbouys et al., 2018) with 4 different regression models. We find that out of the 11 high-level song features, mainly 5 contribute to the performance, multi-modal features do better than audio alone when predicting valence. We made our code publically available.
GTR-CTRL: Instrument and Genre Conditioning for Guitar-Focused Music Generation with Transformers
Feb 10, 2023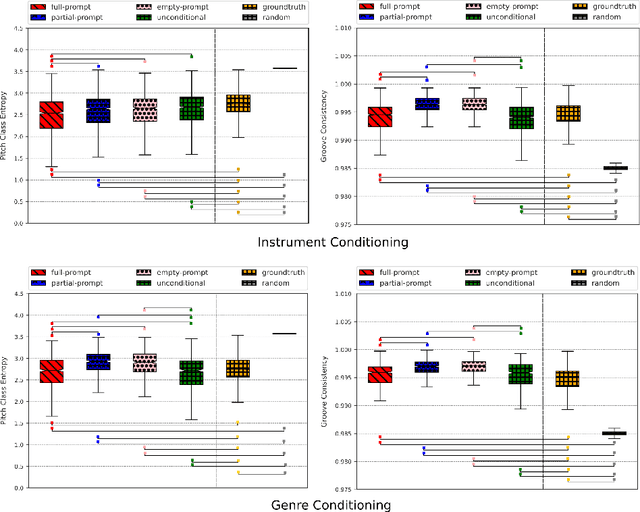

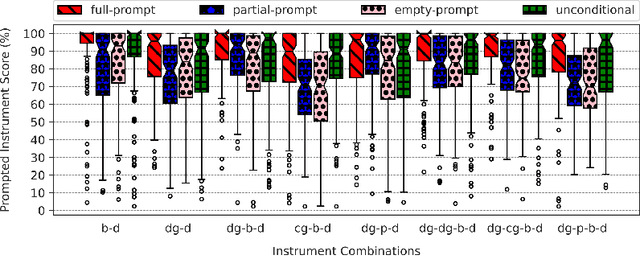
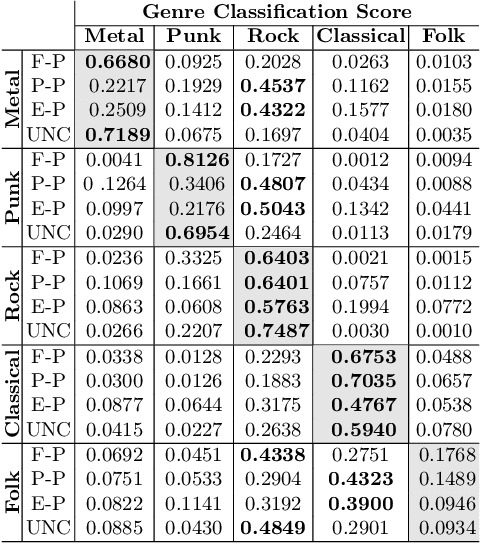
Recently, symbolic music generation with deep learning techniques has witnessed steady improvements. Most works on this topic focus on MIDI representations, but less attention has been paid to symbolic music generation using guitar tablatures (tabs) which can be used to encode multiple instruments. Tabs include information on expressive techniques and fingerings for fretted string instruments in addition to rhythm and pitch. In this work, we use the DadaGP dataset for guitar tab music generation, a corpus of over 26k songs in GuitarPro and token formats. We introduce methods to condition a Transformer-XL deep learning model to generate guitar tabs (GTR-CTRL) based on desired instrumentation (inst-CTRL) and genre (genre-CTRL). Special control tokens are appended at the beginning of each song in the training corpus. We assess the performance of the model with and without conditioning. We propose instrument presence metrics to assess the inst-CTRL model's response to a given instrumentation prompt. We trained a BERT model for downstream genre classification and used it to assess the results obtained with the genre-CTRL model. Statistical analyses evidence significant differences between the conditioned and unconditioned models. Overall, results indicate that the GTR-CTRL methods provide more flexibility and control for guitar-focused symbolic music generation than an unconditioned model.
* This preprint is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). The Version of Record of this contribution is published in Proceedings of EvoMUSART: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) 2023
Polytopic Analysis of Music
Dec 22, 2022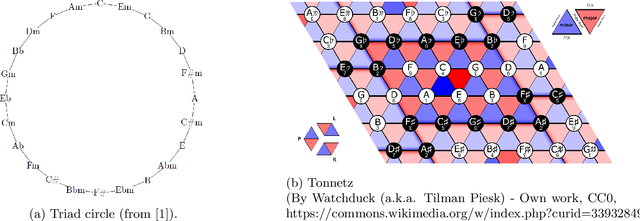
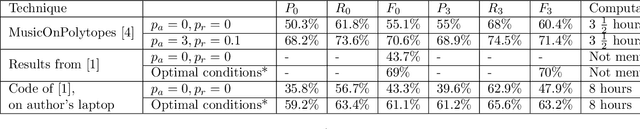
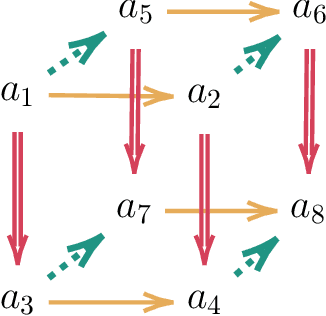
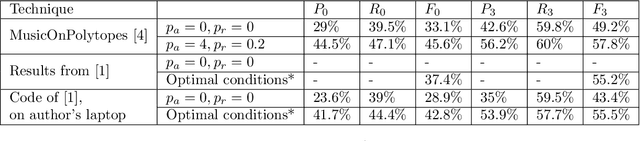
Structural segmentation of music refers to the task of finding a symbolic representation of the organisation of a song, reducing the musical flow to a partition of non-overlapping segments. Under this definition, the musical structure may not be unique, and may even be ambiguous. One way to resolve that ambiguity is to see this task as a compression process, and to consider the musical structure as the optimization of a given compression criteria. In that viewpoint, C. Guichaoua developed a compression-driven model for retrieving the musical structure, based on the "System and Contrast" model, and on polytopes, which are extension of nhypercubes. We present this model, which we call "polytopic analysis of music", along with a new opensource dedicated toolbox called MusicOnPolytopes (in Python). This model is also extended to the use of the Tonnetz as a relation system. Structural segmentation experiments are conducted on the RWC Pop dataset. Results show improvements compared to the previous ones, presented by C. Guichaoua.
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
Apr 25, 2023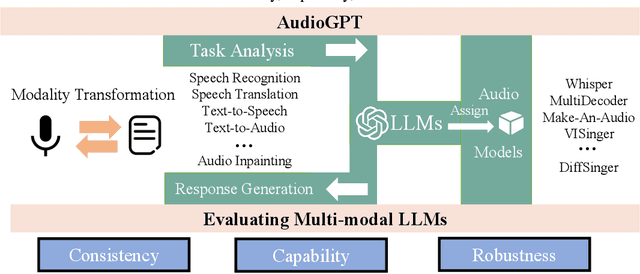

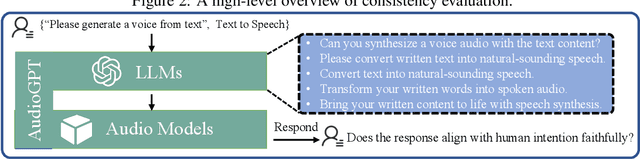

Large language models (LLMs) have exhibited remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Despite the recent success, current LLMs are not capable of processing complex audio information or conducting spoken conversations (like Siri or Alexa). In this work, we propose a multi-modal AI system named AudioGPT, which complements LLMs (i.e., ChatGPT) with 1) foundation models to process complex audio information and solve numerous understanding and generation tasks; and 2) the input/output interface (ASR, TTS) to support spoken dialogue. With an increasing demand to evaluate multi-modal LLMs of human intention understanding and cooperation with foundation models, we outline the principles and processes and test AudioGPT in terms of consistency, capability, and robustness. Experimental results demonstrate the capabilities of AudioGPT in solving AI tasks with speech, music, sound, and talking head understanding and generation in multi-round dialogues, which empower humans to create rich and diverse audio content with unprecedented ease. Our system is publicly available at \url{https://github.com/AIGC-Audio/AudioGPT}.
A Human Subject Study of Named Entity Recognition (NER) in Conversational Music Recommendation Queries
Mar 13, 2023
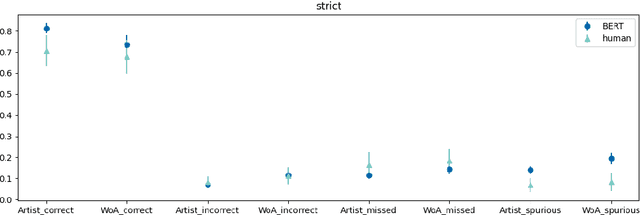
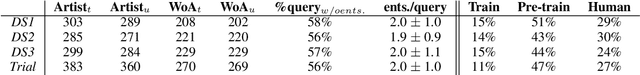
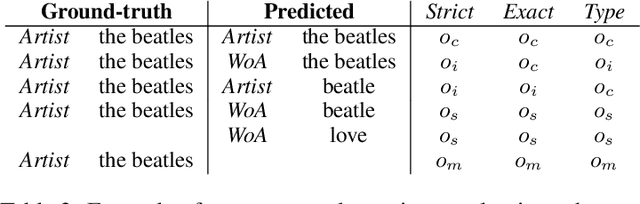
We conducted a human subject study of named entity recognition on a noisy corpus of conversational music recommendation queries, with many irregular and novel named entities. We evaluated the human NER linguistic behaviour in these challenging conditions and compared it with the most common NER systems nowadays, fine-tuned transformers. Our goal was to learn about the task to guide the design of better evaluation methods and NER algorithms. The results showed that NER in our context was quite hard for both human and algorithms under a strict evaluation schema; humans had higher precision, while the model higher recall because of entity exposure especially during pre-training; and entity types had different error patterns (e.g. frequent typing errors for artists). The released corpus goes beyond predefined frames of interaction and can support future work in conversational music recommendation.
Validity in Music Information Research Experiments
Jan 04, 2023
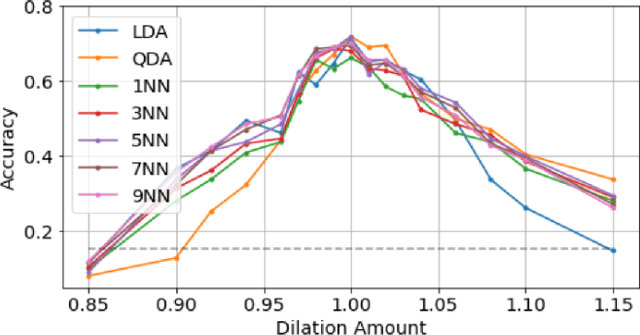
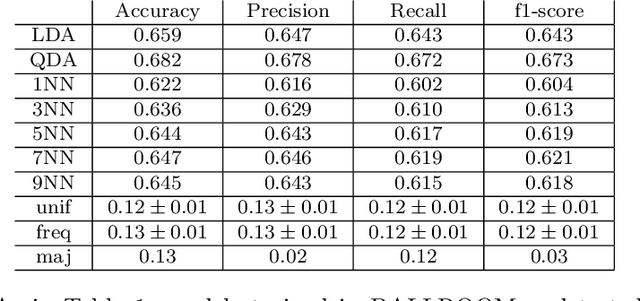
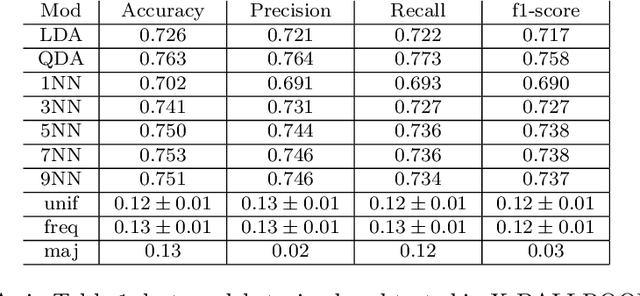
Validity is the truth of an inference made from evidence, such as data collected in an experiment, and is central to working scientifically. Given the maturity of the domain of music information research (MIR), validity in our opinion should be discussed and considered much more than it has been so far. Considering validity in one's work can improve its scientific and engineering value. Puzzling MIR phenomena like adversarial attacks and performance glass ceilings become less mysterious through the lens of validity. In this article, we review the subject of validity in general, considering the four major types of validity from a key reference: Shadish et al. 2002. We ground our discussion of these types with a prototypical MIR experiment: music classification using machine learning. Through this MIR experimentalists can be guided to make valid inferences from data collected from their experiments.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023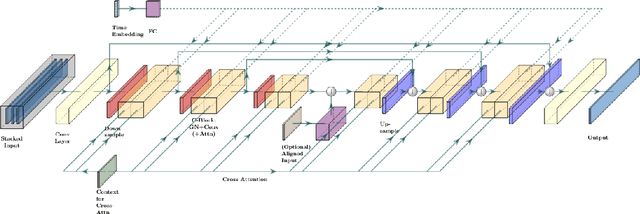

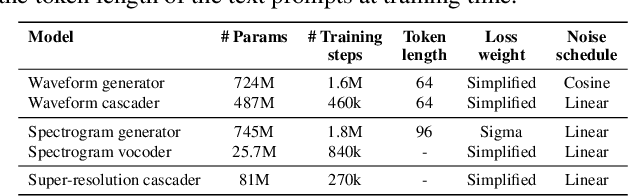
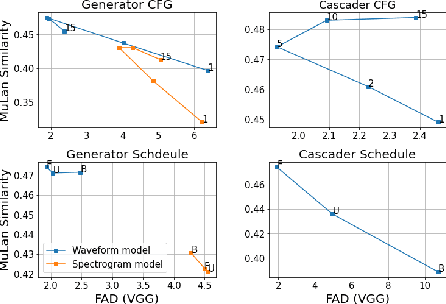
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
Roman Numeral Analysis with Graph Neural Networks: Onset-wise Predictions from Note-wise Features
Jul 12, 2023
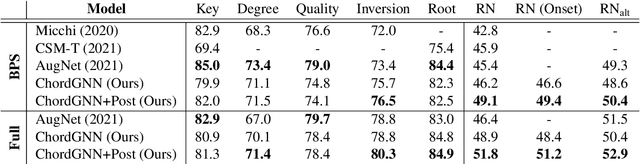

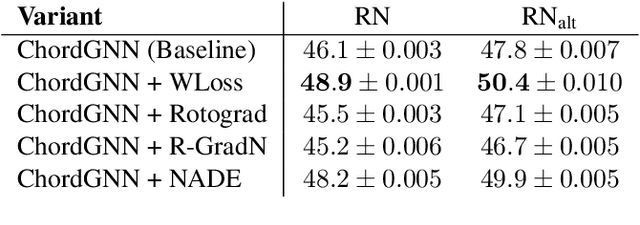
Roman Numeral analysis is the important task of identifying chords and their functional context in pieces of tonal music. This paper presents a new approach to automatic Roman Numeral analysis in symbolic music. While existing techniques rely on an intermediate lossy representation of the score, we propose a new method based on Graph Neural Networks (GNNs) that enable the direct description and processing of each individual note in the score. The proposed architecture can leverage notewise features and interdependencies between notes but yield onset-wise representation by virtue of our novel edge contraction algorithm. Our results demonstrate that ChordGNN outperforms existing state-of-the-art models, achieving higher accuracy in Roman Numeral analysis on the reference datasets. In addition, we investigate variants of our model using proposed techniques such as NADE, and post-processing of the chord predictions. The full source code for this work is available at https://github.com/manoskary/chordgnn
Large Music Recommendation Studies for Small Teams
Jan 31, 2023Running live music recommendation studies without direct industry partnerships can be a prohibitively daunting task, especially for small teams. In order to help future researchers interested in such evaluations, we present a number of struggles we faced in the process of generating our own such evaluation system alongside potential solutions. These problems span the topics of users, data, computation, and application architecture.