 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Reliability of LLMs: Combining CoT, RAG, Self-Consistency, and Self-Verification
May 13, 2025



Hallucination, where large language models (LLMs) generate confident but incorrect or irrelevant information, remains a key limitation in their application to complex, open-ended tasks. Chain-of-thought (CoT) prompting has emerged as a promising method for improving multistep reasoning by guiding models through intermediate steps. However, CoT alone does not fully address the hallucination problem. In this work, we investigate how combining CoT with retrieval-augmented generation (RAG), as well as applying self-consistency and self-verification strategies, can reduce hallucinations and improve factual accuracy. By incorporating external knowledge sources during reasoning and enabling models to verify or revise their own outputs, we aim to generate more accurate and coherent responses. We present a comparative evaluation of baseline LLMs against CoT, CoT+RAG, self-consistency, and self-verification techniques. Our results highlight the effectiveness of each method and identify the most robust approach for minimizing hallucinations while preserving fluency and reasoning depth.
Multimodal Fusion of Glucose Monitoring and Food Imagery for Caloric Content Prediction
May 13, 2025Effective dietary monitoring is critical for managing Type 2 diabetes, yet accurately estimating caloric intake remains a major challenge. While continuous glucose monitors (CGMs) offer valuable physiological data, they often fall short in capturing the full nutritional profile of meals due to inter-individual and meal-specific variability. In this work, we introduce a multimodal deep learning framework that jointly leverages CGM time-series data, Demographic/Microbiome, and pre-meal food images to enhance caloric estimation. Our model utilizes attention based encoding and a convolutional feature extraction for meal imagery, multi-layer perceptrons for CGM and Microbiome data followed by a late fusion strategy for joint reasoning. We evaluate our approach on a curated dataset of over 40 participants, incorporating synchronized CGM, Demographic and Microbiome data and meal photographs with standardized caloric labels. Our model achieves a Root Mean Squared Relative Error (RMSRE) of 0.2544, outperforming the baselines models by over 50%. These findings demonstrate the potential of multimodal sensing to improve automated dietary assessment tools for chronic disease management.
ShredGP: Guitarist Style-Conditioned Tablature Generation
Jul 11, 2023GuitarPro format tablatures are a type of digital music notation that encapsulates information about guitar playing techniques and fingerings. We introduce ShredGP, a GuitarPro tablature generative Transformer-based model conditioned to imitate the style of four distinct iconic electric guitarists. In order to assess the idiosyncrasies of each guitar player, we adopt a computational musicology methodology by analysing features computed from the tokens yielded by the DadaGP encoding scheme. Statistical analyses of the features evidence significant differences between the four guitarists. We trained two variants of the ShredGP model, one using a multi-instrument corpus, the other using solo guitar data. We present a BERT-based model for guitar player classification and use it to evaluate the generated examples. Overall, results from the classifier show that ShredGP is able to generate content congruent with the style of the targeted guitar player. Finally, we reflect on prospective applications for ShredGP for human-AI music interaction.
From Words to Music: A Study of Subword Tokenization Techniques in Symbolic Music Generation
Apr 25, 2023



Subword tokenization has been widely successful in text-based natural language processing (NLP) tasks with Transformer-based models. As Transformer models become increasingly popular in symbolic music-related studies, it is imperative to investigate the efficacy of subword tokenization in the symbolic music domain. In this paper, we explore subword tokenization techniques, such as byte-pair encoding (BPE), in symbolic music generation and its impact on the overall structure of generated songs. Our experiments are based on three types of MIDI datasets: single track-melody only, multi-track with a single instrument, and multi-track and multi-instrument. We apply subword tokenization on post-musical tokenization schemes and find that it enables the generation of longer songs at the same time and improves the overall structure of the generated music in terms of objective metrics like structure indicator (SI), Pitch Class Entropy, etc. We also compare two subword tokenization methods, BPE and Unigram, and observe that both methods lead to consistent improvements. Our study suggests that subword tokenization is a promising technique for symbolic music generation and may have broader implications for music composition, particularly in cases involving complex data such as multi-track songs.
GTR-CTRL: Instrument and Genre Conditioning for Guitar-Focused Music Generation with Transformers
Feb 10, 2023Recently, symbolic music generation with deep learning techniques has witnessed steady improvements. Most works on this topic focus on MIDI representations, but less attention has been paid to symbolic music generation using guitar tablatures (tabs) which can be used to encode multiple instruments. Tabs include information on expressive techniques and fingerings for fretted string instruments in addition to rhythm and pitch. In this work, we use the DadaGP dataset for guitar tab music generation, a corpus of over 26k songs in GuitarPro and token formats. We introduce methods to condition a Transformer-XL deep learning model to generate guitar tabs (GTR-CTRL) based on desired instrumentation (inst-CTRL) and genre (genre-CTRL). Special control tokens are appended at the beginning of each song in the training corpus. We assess the performance of the model with and without conditioning. We propose instrument presence metrics to assess the inst-CTRL model's response to a given instrumentation prompt. We trained a BERT model for downstream genre classification and used it to assess the results obtained with the genre-CTRL model. Statistical analyses evidence significant differences between the conditioned and unconditioned models. Overall, results indicate that the GTR-CTRL methods provide more flexibility and control for guitar-focused symbolic music generation than an unconditioned model.
* This preprint is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). The Version of Record of this contribution is published in Proceedings of EvoMUSART: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) 2023
CounterGeDi: A controllable approach to generate polite, detoxified and emotional counterspeech
May 09, 2022
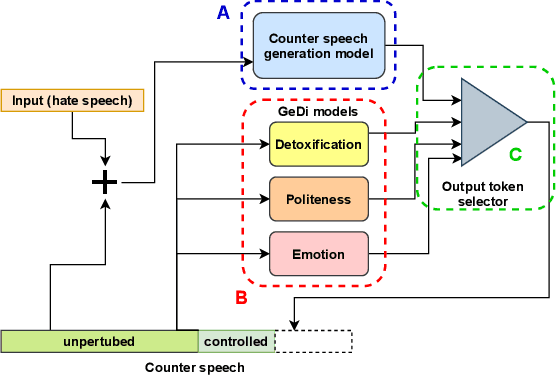


Recently, many studies have tried to create generation models to assist counter speakers by providing counterspeech suggestions for combating the explosive proliferation of online hate. However, since these suggestions are from a vanilla generation model, they might not include the appropriate properties required to counter a particular hate speech instance. In this paper, we propose CounterGeDi - an ensemble of generative discriminators (GeDi) to guide the generation of a DialoGPT model toward more polite, detoxified, and emotionally laden counterspeech. We generate counterspeech using three datasets and observe significant improvement across different attribute scores. The politeness and detoxification scores increased by around 15% and 6% respectively, while the emotion in the counterspeech increased by at least 10% across all the datasets. We also experiment with triple-attribute control and observe significant improvement over single attribute results when combining complementing attributes, e.g., politeness, joyfulness and detoxification. In all these experiments, the relevancy of the generated text does not deteriorate due to the application of these controls
Doing More by Doing Less: How Structured Partial Backpropagation Improves Deep Learning Clusters
Nov 20, 2021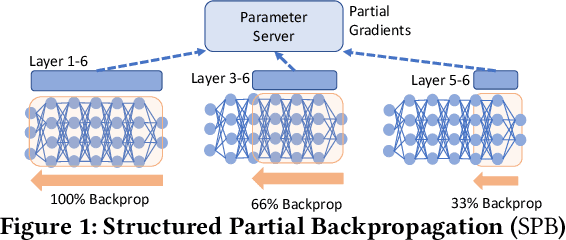
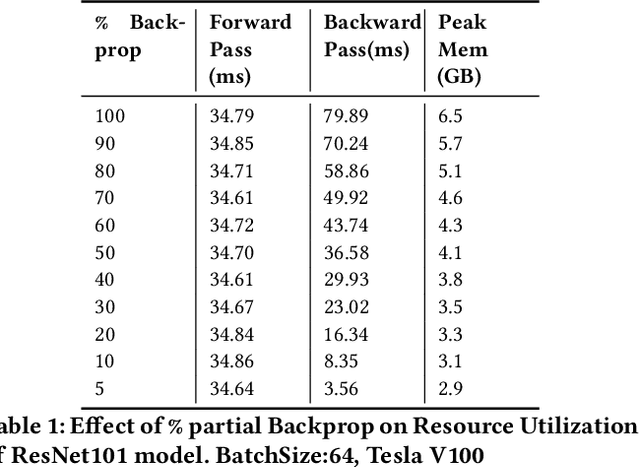
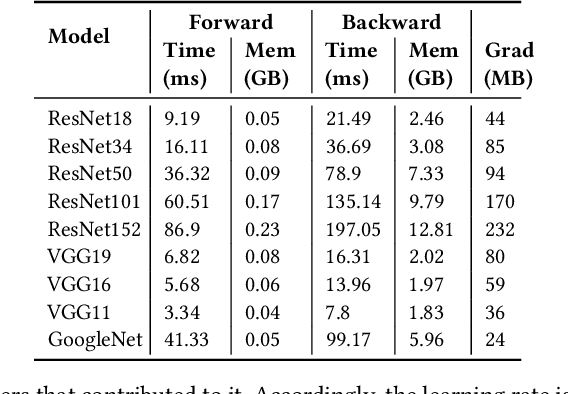
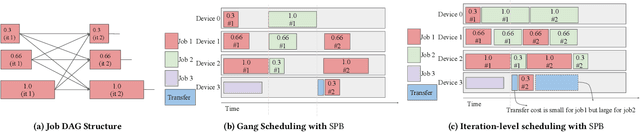
Many organizations employ compute clusters equipped with accelerators such as GPUs and TPUs for training deep learning models in a distributed fashion. Training is resource-intensive, consuming significant compute, memory, and network resources. Many prior works explore how to reduce training resource footprint without impacting quality, but their focus on a subset of the bottlenecks (typically only the network) limits their ability to improve overall cluster utilization. In this work, we exploit the unique characteristics of deep learning workloads to propose Structured Partial Backpropagation(SPB), a technique that systematically controls the amount of backpropagation at individual workers in distributed training. This simultaneously reduces network bandwidth, compute utilization, and memory footprint while preserving model quality. To efficiently leverage the benefits of SPB at cluster level, we introduce JigSaw, a SPB aware scheduler, which does scheduling at the iteration level for Deep Learning Training(DLT) jobs. We find that JigSaw can improve large scale cluster efficiency by as high as 28\%.
DadaGP: A Dataset of Tokenized GuitarPro Songs for Sequence Models
Jul 30, 2021

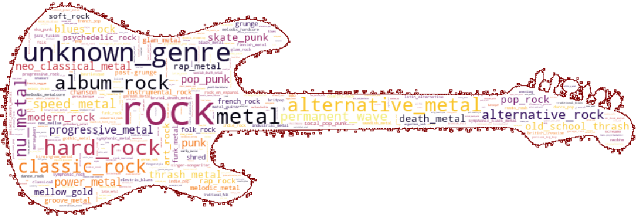
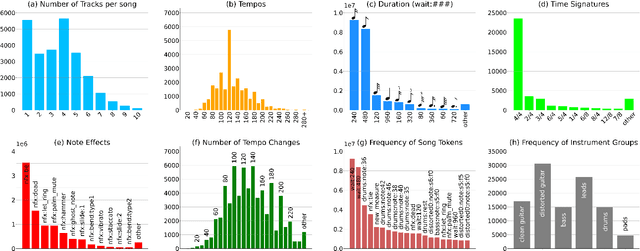
Originating in the Renaissance and burgeoning in the digital era, tablatures are a commonly used music notation system which provides explicit representations of instrument fingerings rather than pitches. GuitarPro has established itself as a widely used tablature format and software enabling musicians to edit and share songs for musical practice, learning, and composition. In this work, we present DadaGP, a new symbolic music dataset comprising 26,181 song scores in the GuitarPro format covering 739 musical genres, along with an accompanying tokenized format well-suited for generative sequence models such as the Transformer. The tokenized format is inspired by event-based MIDI encodings, often used in symbolic music generation models. The dataset is released with an encoder/decoder which converts GuitarPro files to tokens and back. We present results of a use case in which DadaGP is used to train a Transformer-based model to generate new songs in GuitarPro format. We discuss other relevant use cases for the dataset (guitar-bass transcription, music style transfer and artist/genre classification) as well as ethical implications. DadaGP opens up the possibility to train GuitarPro score generators, fine-tune models on custom data, create new styles of music, AI-powered songwriting apps, and human-AI improvisation.
Quantum Artificial Intelligence for the Science of Climate Change
Jul 28, 2021
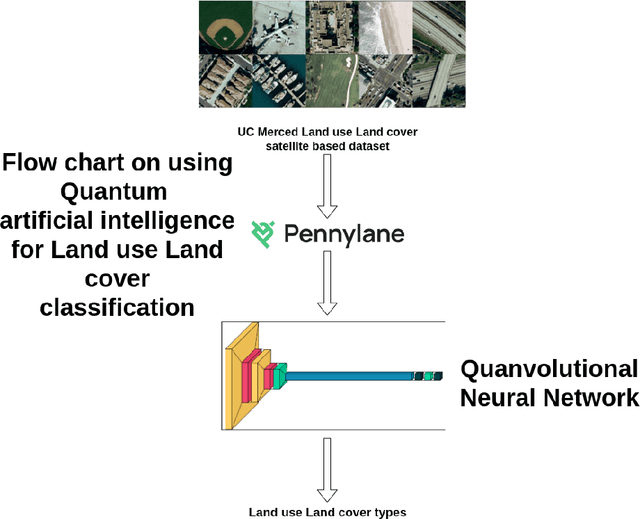
Climate change has become one of the biggest global problems increasingly compromising the Earth's habitability. Recent developments such as the extraordinary heat waves in California & Canada, and the devastating floods in Germany point to the role of climate change in the ever-increasing frequency of extreme weather. Numerical modelling of the weather and climate have seen tremendous improvements in the last five decades, yet stringent limitations remain to be overcome. Spatially and temporally localized forecasting is the need of the hour for effective adaptation measures towards minimizing the loss of life and property. Artificial Intelligence-based methods are demonstrating promising results in improving predictions, but are still limited by the availability of requisite hardware and software required to process the vast deluge of data at a scale of the planet Earth. Quantum computing is an emerging paradigm that has found potential applicability in several fields. In this opinion piece, we argue that new developments in Artificial Intelligence algorithms designed for quantum computers - also known as Quantum Artificial Intelligence (QAI) - may provide the key breakthroughs necessary to furthering the science of climate change. The resultant improvements in weather and climate forecasts are expected to cascade to numerous societal benefits.
Team Phoenix at WASSA 2021: Emotion Analysis on News Stories with Pre-Trained Language Models
Mar 10, 2021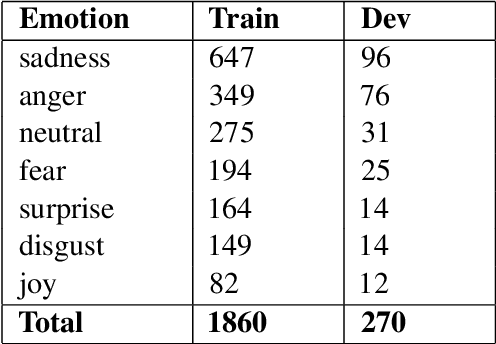
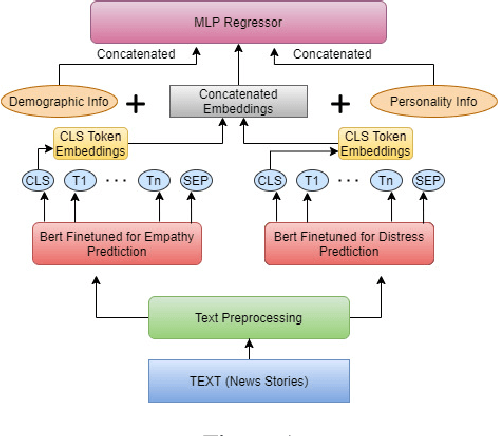
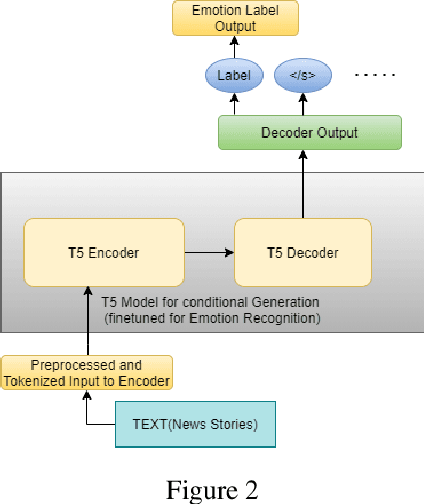
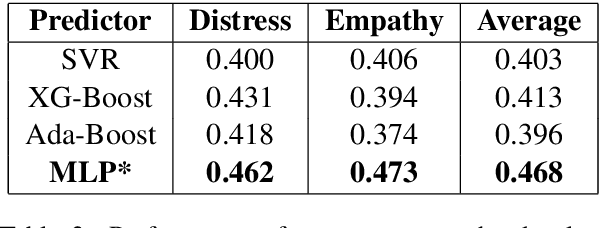
Emotion is fundamental to humanity. The ability to perceive, understand and respond to social interactions in a human-like manner is one of the most desired capabilities in artificial agents, particularly in social-media bots. Over the past few years, computational understanding and detection of emotional aspects in language have been vital in advancing human-computer interaction. The WASSA Shared Task 2021 released a dataset of news-stories across two tracks, Track-1 for Empathy and Distress Prediction and Track-2 for Multi-Dimension Emotion prediction at the essay-level. We describe our system entry for the WASSA 2021 Shared Task (for both Track-1 and Track-2), where we leveraged the information from Pre-trained language models for Track-specific Tasks. Our proposed models achieved an Average Pearson Score of 0.417 and a Macro-F1 Score of 0.502 in Track 1 and Track 2, respectively. In the Shared Task leaderboard, we secured 4th rank in Track 1 and 2nd rank in Track 2.