 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Bounded Residual Gradient Networks (BReG-Net) for Facial Affect Computing
Mar 05, 2019
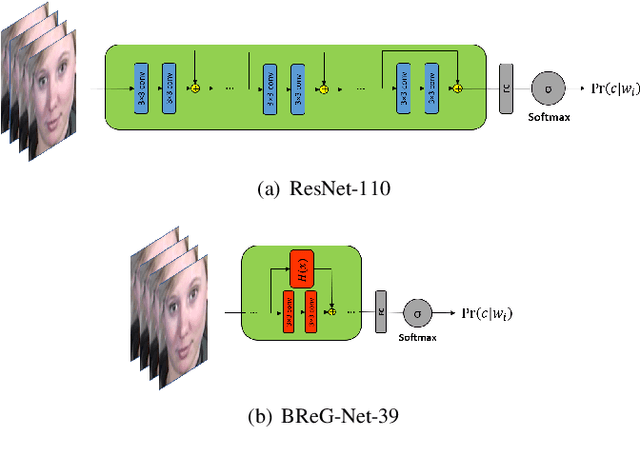
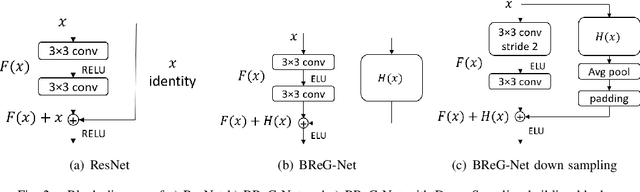
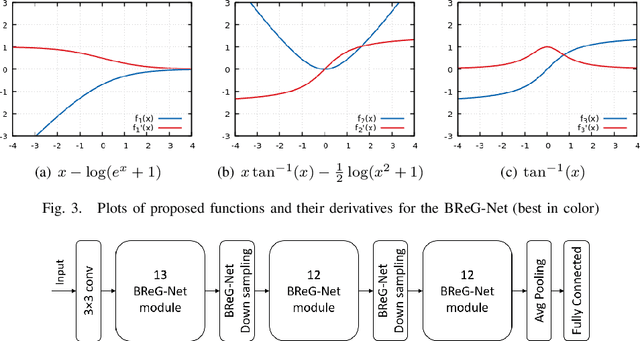
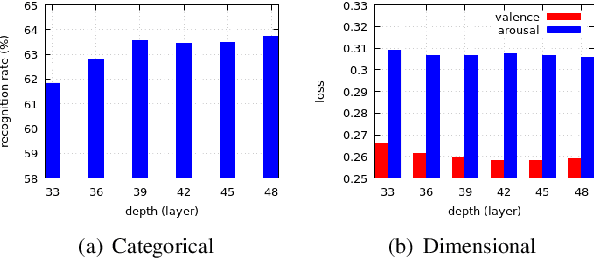
Residual-based neural networks have shown remarkable results in various visual recognition tasks including Facial Expression Recognition (FER). Despite the tremendous efforts have been made to improve the performance of FER systems using DNNs, existing methods are not generalizable enough for practical applications. This paper introduces Bounded Residual Gradient Networks (BReG-Net) for facial expression recognition, in which the shortcut connection between the input and the output of the ResNet module is replaced with a differentiable function with a bounded gradient. This configuration prevents the network from facing the vanishing or exploding gradient problem. We show that utilizing such non-linear units will result in shallower networks with better performance. Further, by using a weighted loss function which gives a higher priority to less represented categories, we can achieve an overall better recognition rate. The results of our experiments show that BReG-Nets outperform state-of-the-art methods on three publicly available facial databases in the wild, on both the categorical and dimensional models of affect.
Learning to Generate Facial Depth Maps
May 30, 2018
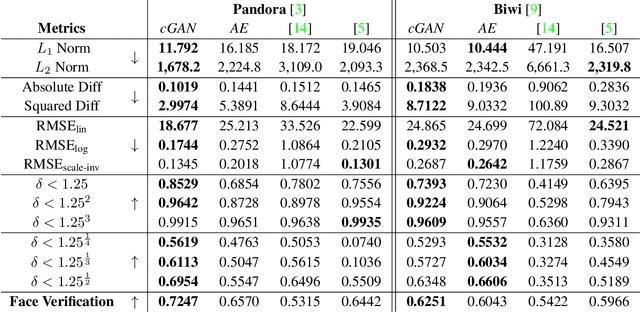
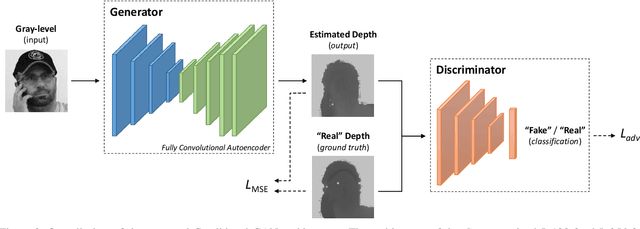

In this paper, an adversarial architecture for facial depth map estimation from monocular intensity images is presented. By following an image-to-image approach, we combine the advantages of supervised learning and adversarial training, proposing a conditional Generative Adversarial Network that effectively learns to translate intensity face images into the corresponding depth maps. Two public datasets, namely Biwi database and Pandora dataset, are exploited to demonstrate that the proposed model generates high-quality synthetic depth images, both in terms of visual appearance and informative content. Furthermore, we show that the model is capable of predicting distinctive facial details by testing the generated depth maps through a deep model trained on authentic depth maps for the face verification task.
Multi-Region Ensemble Convolutional Neural Network for Facial Expression Recognition
Jul 12, 2018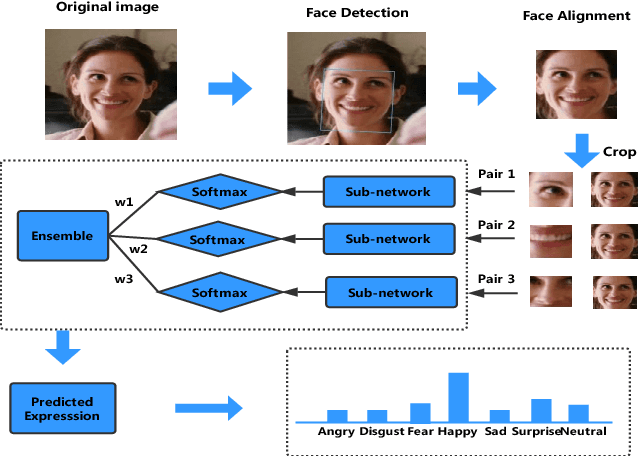
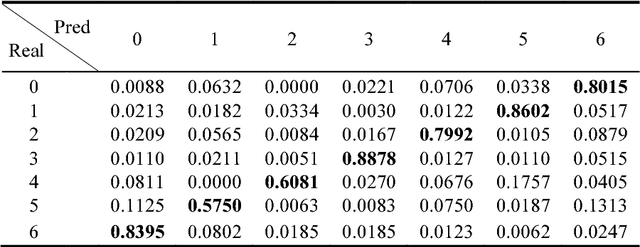

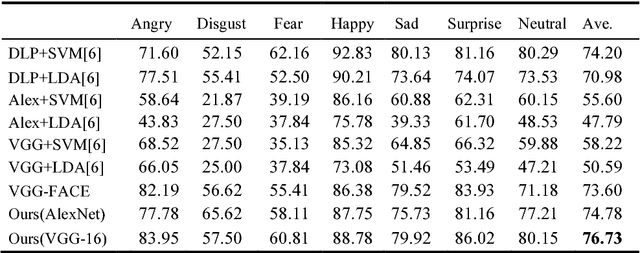
Facial expressions play an important role in conveying the emotional states of human beings. Recently, deep learning approaches have been applied to image recognition field due to the discriminative power of Convolutional Neural Network (CNN). In this paper, we first propose a novel Multi-Region Ensemble CNN (MRE-CNN) framework for facial expression recognition, which aims to enhance the learning power of CNN models by capturing both the global and the local features from multiple human face sub-regions. Second, the weighted prediction scores from each sub-network are aggregated to produce the final prediction of high accuracy. Third, we investigate the effects of different sub-regions of the whole face on facial expression recognition. Our proposed method is evaluated based on two well-known publicly available facial expression databases: AFEW 7.0 and RAF-DB, and has been shown to achieve the state-of-the-art recognition accuracy.
Feature Super-Resolution Based Facial Expression Recognition for Multi-scale Low-Resolution Faces
Apr 05, 2020
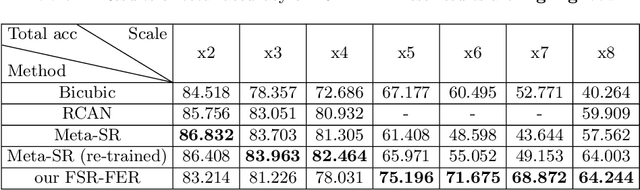
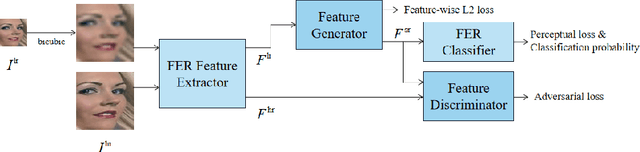
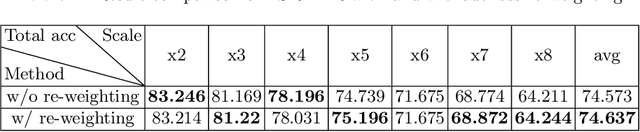
Facial Expressions Recognition(FER) on low-resolution images is necessary for applications like group expression recognition in crowd scenarios(station, classroom etc.). Classifying a small size facial image into the right expression category is still a challenging task. The main cause of this problem is the loss of discriminative feature due to reduced resolution. Super-resolution method is often used to enhance low-resolution images, but the performance on FER task is limited when on images of very low resolution. In this work, inspired by feature super-resolution methods for object detection, we proposed a novel generative adversary network-based feature level super-resolution method for robust facial expression recognition(FSR-FER). In particular, a pre-trained FER model was employed as feature extractor, and a generator network G and a discriminator network D are trained with features extracted from images of low resolution and original high resolution. Generator network G tries to transform features of low-resolution images to more discriminative ones by making them closer to the ones of corresponding high-resolution images. For better classification performance, we also proposed an effective classification-aware loss re-weighting strategy based on the classification probability calculated by a fixed FER model to make our model focus more on samples that are easily misclassified. Experiment results on Real-World Affective Faces (RAF) Database demonstrate that our method achieves satisfying results on various down-sample factors with a single model and has better performance on low-resolution images compared with methods using image super-resolution and expression recognition separately.
Efficient Facial Feature Learning with Wide Ensemble-based Convolutional Neural Networks
Jan 17, 2020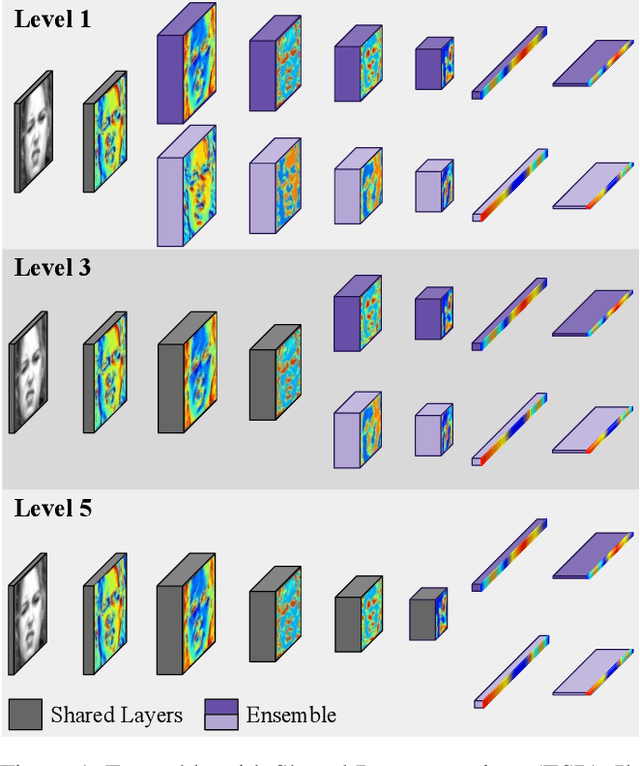
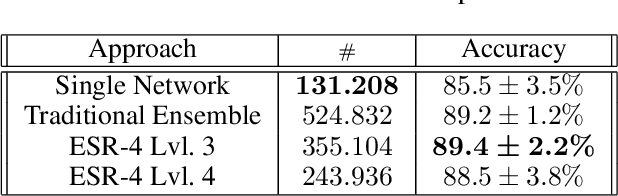
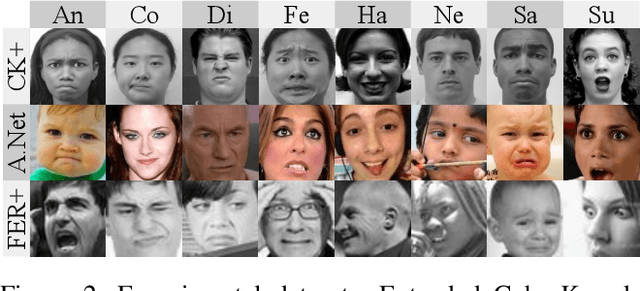
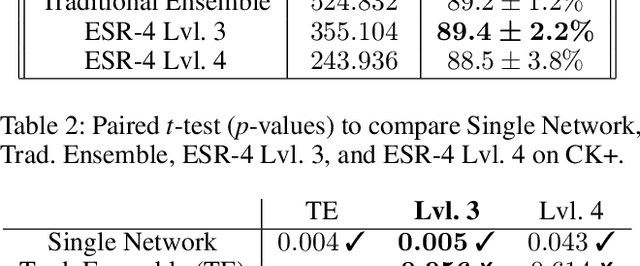
Ensemble methods, traditionally built with independently trained de-correlated models, have proven to be efficient methods for reducing the remaining residual generalization error, which results in robust and accurate methods for real-world applications. In the context of deep learning, however, training an ensemble of deep networks is costly and generates high redundancy which is inefficient. In this paper, we present experiments on Ensembles with Shared Representations (ESRs) based on convolutional networks to demonstrate, quantitatively and qualitatively, their data processing efficiency and scalability to large-scale datasets of facial expressions. We show that redundancy and computational load can be dramatically reduced by varying the branching level of the ESR without loss of diversity and generalization power, which are both important for ensemble performance. Experiments on large-scale datasets suggest that ESRs reduce the remaining residual generalization error on the AffectNet and FER+ datasets, reach human-level performance, and outperform state-of-the-art methods on facial expression recognition in the wild using emotion and affect concepts.
Efficient conditioned face animation using frontally-viewed embedding
Mar 16, 2022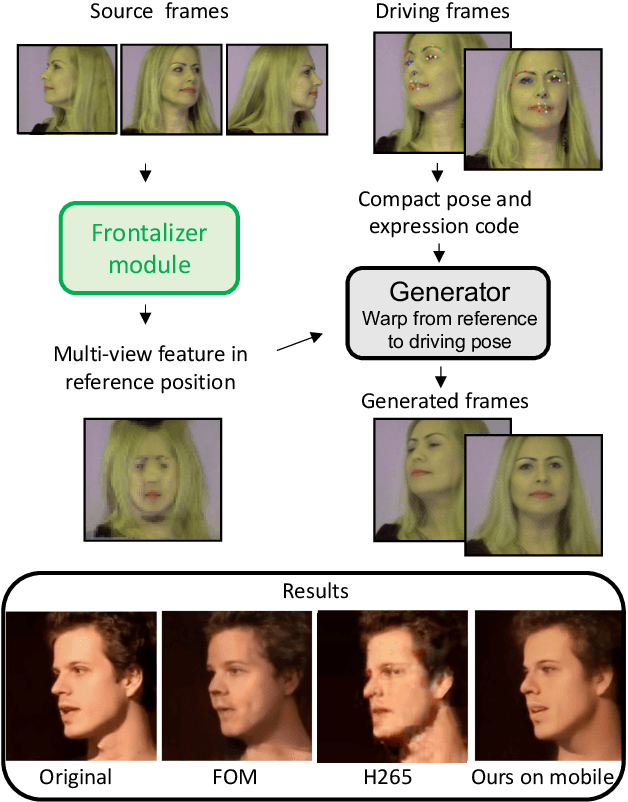


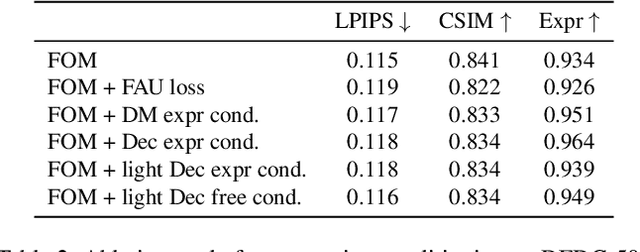
As the quality of few shot facial animation from landmarks increases, new applications become possible, such as ultra low bandwidth video chat compression with a high degree of realism. However, there are some important challenges to tackle in order to improve the experience in real world conditions. In particular, the current approaches fail to represent profile views without distortions, while running in a low compute regime. We focus on this key problem by introducing a multi-frames embedding dubbed Frontalizer to improve profile views rendering. In addition to this core improvement, we explore the learning of a latent code conditioning generations along with landmarks to better convey facial expressions. Our dense models achieves 22% of improvement in perceptual quality and 73% reduction of landmark error over the first order model baseline on a subset of DFDC videos containing head movements. Declined with mobile architectures, our models outperform the previous state-of-the-art (improving perceptual quality by more than 16% and reducing landmark error by more than 47% on two datasets) while running on real time on iPhone 8 with very low bandwidth requirements.
A Face Recognition Signature Combining Patch-based Features with Soft Facial Attributes
Mar 25, 2018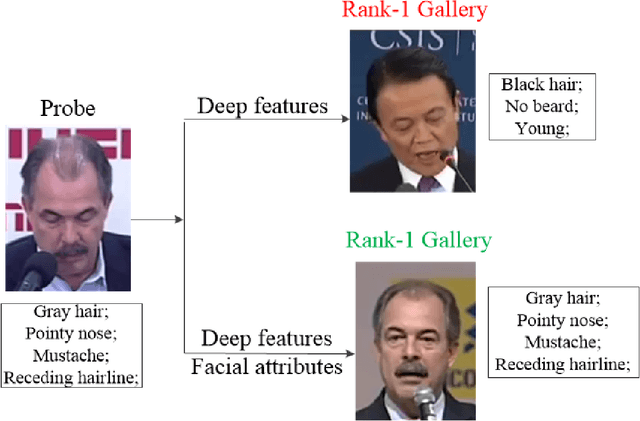

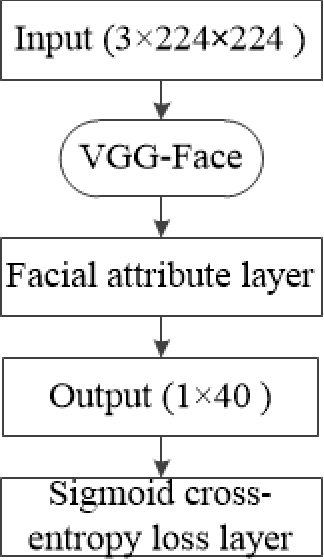
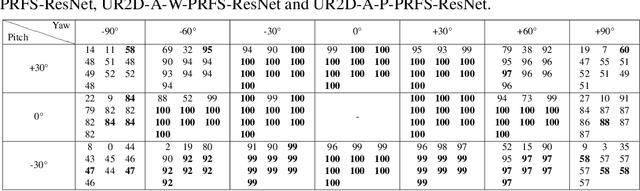
This paper focuses on improving face recognition performance with a new signature combining implicit facial features with explicit soft facial attributes. This signature has two components: the existing patch-based features and the soft facial attributes. A deep convolutional neural network adapted from state-of-the-art networks is used to learn the soft facial attributes. Then, a signature matcher is introduced that merges the contributions of both patch-based features and the facial attributes. In this matcher, the matching scores computed from patch-based features and the facial attributes are combined to obtain a final matching score. The matcher is also extended so that different weights are assigned to different facial attributes. The proposed signature and matcher have been evaluated with the UR2D system on the UHDB31 and IJB-A datasets. The experimental results indicate that the proposed signature achieve better performance than using only patch-based features. The Rank-1 accuracy is improved significantly by 4% and 0.37% on the two datasets when compared with the UR2D system.
THIN: THrowable Information Networks and Application for Facial Expression Recognition In The Wild
Oct 15, 2020

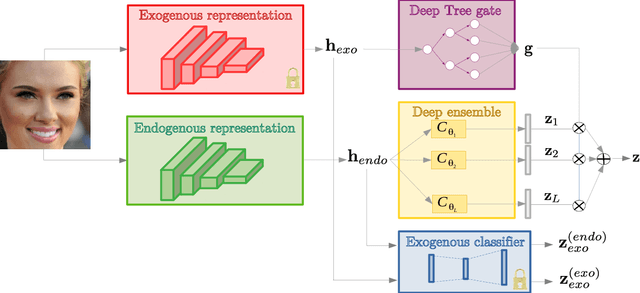
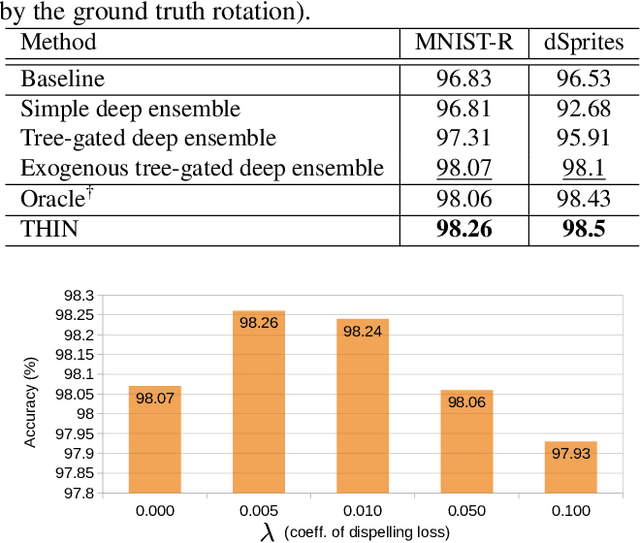
For a number of tasks solved using deep learning techniques, an exogenous variable can be identified such that (a) it heavily influences the appearance of the different classes, and (b) an ideal classifier should be invariant to this variable. An example of such exogenous variable is identity if facial expression recognition (FER) is considered. In this paper, we propose a dual exogenous/endogenous representation. The former captures the exogenous variable whereas the second one models the task at hand (e.g. facial expression). We design a prediction layer that uses a deep ensemble conditioned by the exogenous representation. It employs a differential tree gate that learns an adaptive weak predictor weighting, therefore modeling a partition of the exogenous representation space, upon which the weak predictors specialize. This layer explicitly models the dependency between the exogenous variable and the predicted task (a). We also propose an exogenous dispelling loss to remove the exogenous information from the endogenous representation, enforcing (b). Thus, the exogenous information is used two times in a throwable fashion, first as a conditioning variable for the target task, and second to create invariance within the endogenous representation. We call this method THIN, standing for THrowable Information Networks. We experimentally validate THIN in several contexts where an exogenous information can be identified, such as digit recognition under large rotations and shape recognition at multiple scales. We also apply it to FER with identity as the exogenous variable. In particular, we demonstrate that THIN significantly outperforms state-of-the-art approaches on several challenging datasets.
Equalization and Brightness Mapping Modes of Color-to-Gray Projection Operators
Aug 21, 2022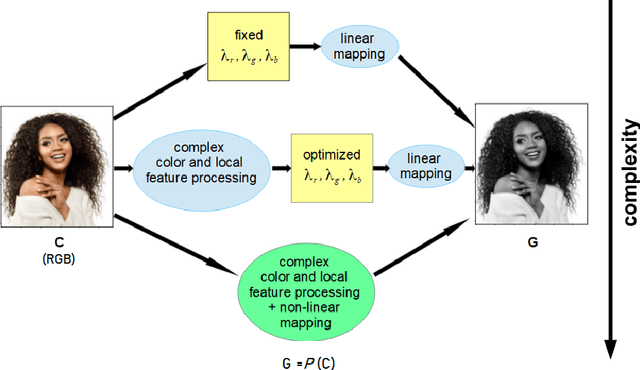

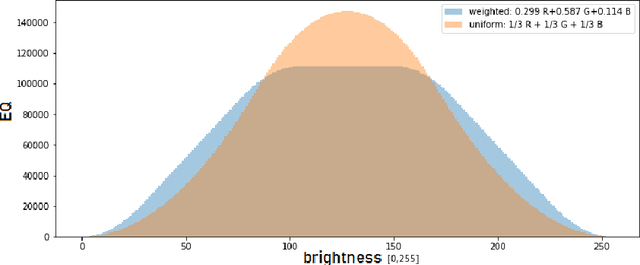
In this article, the conversion of color RGB images to grayscale is covered by characterizing the mathematical operators used to project 3 color channels to a single one. Based on the fact that most operators assign each of the $256^3$ colors a single gray level, ranging from 0 to 255, they are clustering algorithms that distribute the color population into 256 clusters of increasing brightness. To visualize the way operators work the sizes of the clusters and the average brightness of each cluster are plotted. The equalization mode (EQ) introduced in this work focuses on cluster sizes, while the brightness mapping (BM) mode describes the CIE L* luminance distribution per cluster. Three classes of EQ modes and two classes of BM modes were found in linear operators, defining a 6-class taxonomy. The theoretical/methodological framework introduced was applied in a case study considering the equal-weights uniform operator, the NTSC standard operator, and an operator chosen as ideal to lighten the faces of black people to improve facial recognition in current biased classifiers. It was found that most current metrics used to assess the quality of color-to-gray conversions better assess one of the two BM mode classes, but the ideal operator chosen by a human team belongs to the other class. Therefore, this cautions against using these general metrics for specific purpose color-to-gray conversions. It should be noted that eventual applications of this framework to non-linear operators can give rise to new classes of EQ and BM modes. The main contribution of this article is to provide a tool to better understand color to gray converters in general, even those based on machine learning, within the current trend of better explainability of models.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022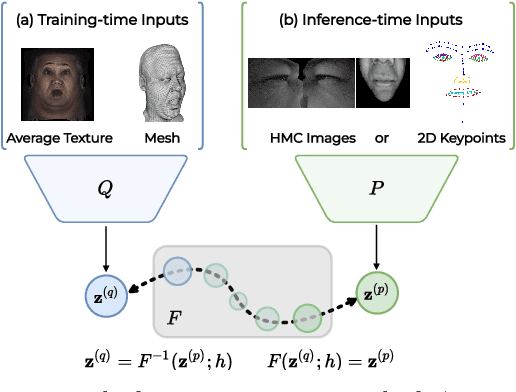
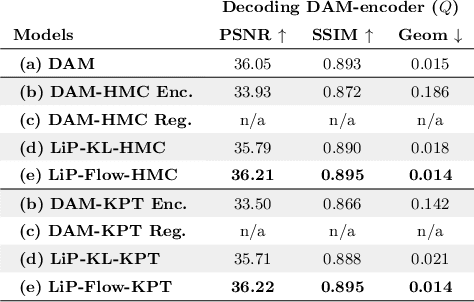

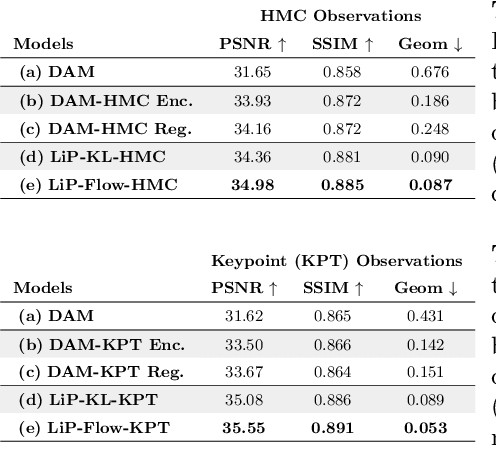
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.