 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning a Generalizable 3D Scene Representation from 2D Observations
Feb 11, 2026We introduce a Generalizable Neural Radiance Field approach for predicting 3D workspace occupancy from egocentric robot observations. Unlike prior methods operating in camera-centric coordinates, our model constructs occupancy representations in a global workspace frame, making it directly applicable to robotic manipulation. The model integrates flexible source views and generalizes to unseen object arrangements without scene-specific finetuning. We demonstrate the approach on a humanoid robot and evaluate predicted geometry against 3D sensor ground truth. Trained on 40 real scenes, our model achieves 26mm reconstruction error, including occluded regions, validating its ability to infer complete 3D occupancy beyond traditional stereo vision methods.
Causal State Distillation for Explainable Reinforcement Learning
Dec 30, 2023



Reinforcement learning (RL) is a powerful technique for training intelligent agents, but understanding why these agents make specific decisions can be quite challenging. This lack of transparency in RL models has been a long-standing problem, making it difficult for users to grasp the reasons behind an agent's behaviour. Various approaches have been explored to address this problem, with one promising avenue being reward decomposition (RD). RD is appealing as it sidesteps some of the concerns associated with other methods that attempt to rationalize an agent's behaviour in a post-hoc manner. RD works by exposing various facets of the rewards that contribute to the agent's objectives during training. However, RD alone has limitations as it primarily offers insights based on sub-rewards and does not delve into the intricate cause-and-effect relationships that occur within an RL agent's neural model. In this paper, we present an extension of RD that goes beyond sub-rewards to provide more informative explanations. Our approach is centred on a causal learning framework that leverages information-theoretic measures for explanation objectives that encourage three crucial properties of causal factors: \emph{causal sufficiency}, \emph{sparseness}, and \emph{orthogonality}. These properties help us distill the cause-and-effect relationships between the agent's states and actions or rewards, allowing for a deeper understanding of its decision-making processes. Our framework is designed to generate local explanations and can be applied to a wide range of RL tasks with multiple reward channels. Through a series of experiments, we demonstrate that our approach offers more meaningful and insightful explanations for the agent's action selections.
A Closer Look at Reward Decomposition for High-Level Robotic Explanations
Apr 25, 2023



Explaining the behavior of intelligent agents such as robots to humans is challenging due to their incomprehensible proprioceptive states, variational intermediate goals, and resultant unpredictability. Moreover, one-step explanations for reinforcement learning agents can be ambiguous as they fail to account for the agent's future behavior at each transition, adding to the complexity of explaining robot actions. By leveraging abstracted actions that map to task-specific primitives, we avoid explanations on the movement level. Our proposed framework combines reward decomposition (RD) with abstracted action spaces into an explainable learning framework, allowing for non-ambiguous and high-level explanations based on object properties in the task. We demonstrate the effectiveness of our framework through quantitative and qualitative analysis of two robot scenarios, showcasing visual and textual explanations, from output artifacts of RD explanation, that are easy for humans to comprehend. Additionally, we demonstrate the versatility of integrating these artifacts with large language models for reasoning and interactive querying.
Neural Field Conditioning Strategies for 2D Semantic Segmentation
Apr 12, 2023



Neural fields are neural networks which map coordinates to a desired signal. When a neural field should jointly model multiple signals, and not memorize only one, it needs to be conditioned on a latent code which describes the signal at hand. Despite being an important aspect, there has been little research on conditioning strategies for neural fields. In this work, we explore the use of neural fields as decoders for 2D semantic segmentation. For this task, we compare three conditioning methods, simple concatenation of the latent code, Feature Wise Linear Modulation (FiLM), and Cross-Attention, in conjunction with latent codes which either describe the full image or only a local region of the image. Our results show a considerable difference in performance between the examined conditioning strategies. Furthermore, we show that conditioning via Cross-Attention achieves the best results and is competitive with a CNN-based decoder for semantic segmentation.
A Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021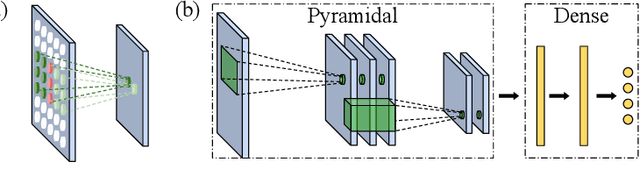

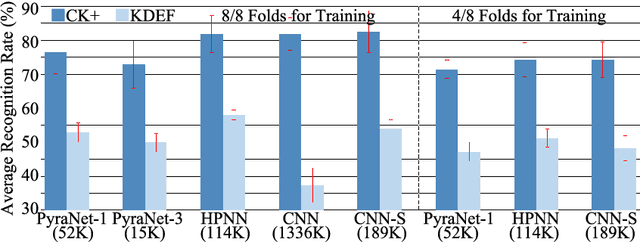

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
Disambiguating Affective Stimulus Associations for Robot Perception and Dialogue
Mar 05, 2021

Effectively recognising and applying emotions to interactions is a highly desirable trait for social robots. Implicitly understanding how subjects experience different kinds of actions and objects in the world is crucial for natural HRI interactions, with the possibility to perform positive actions and avoid negative actions. In this paper, we utilize the NICO robot's appearance and capabilities to give the NICO the ability to model a coherent affective association between a perceived auditory stimulus and a temporally asynchronous emotion expression. This is done by combining evaluations of emotional valence from vision and language. NICO uses this information to make decisions about when to extend conversations in order to accrue more affective information if the representation of the association is not coherent. Our primary contribution is providing a NICO robot with the ability to learn the affective associations between a perceived auditory stimulus and an emotional expression. NICO is able to do this for both individual subjects and specific stimuli, with the aid of an emotion-driven dialogue system that rectifies emotional expression incoherences. The robot is then able to use this information to determine a subject's enjoyment of perceived auditory stimuli in a real HRI scenario.
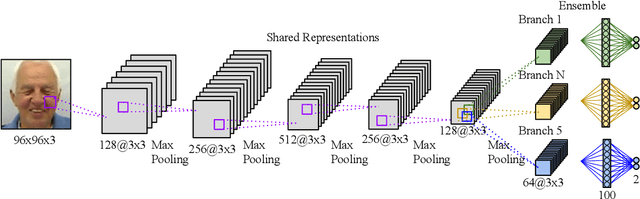
An Ensemble with Shared Representations Based on Convolutional Networks for Continually Learning Facial Expressions
Mar 05, 2021
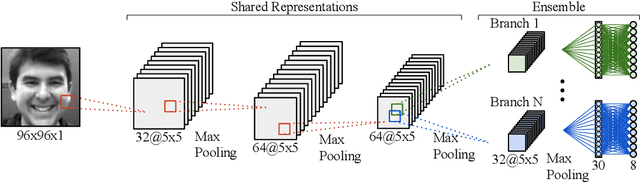

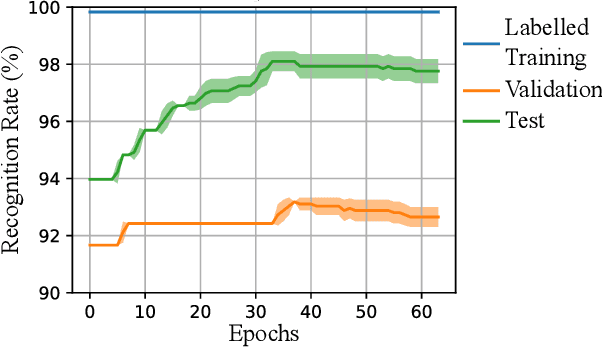
Social robots able to continually learn facial expressions could progressively improve their emotion recognition capability towards people interacting with them. Semi-supervised learning through ensemble predictions is an efficient strategy to leverage the high exposure of unlabelled facial expressions during human-robot interactions. Traditional ensemble-based systems, however, are composed of several independent classifiers leading to a high degree of redundancy, and unnecessary allocation of computational resources. In this paper, we proposed an ensemble based on convolutional networks where the early layers are strong low-level feature extractors, and their representations shared with an ensemble of convolutional branches. This results in a significant drop in redundancy of low-level features processing. Training in a semi-supervised setting, we show that our approach is able to continually learn facial expressions through ensemble predictions using unlabelled samples from different data distributions.
Efficient Facial Feature Learning with Wide Ensemble-based Convolutional Neural Networks
Jan 17, 2020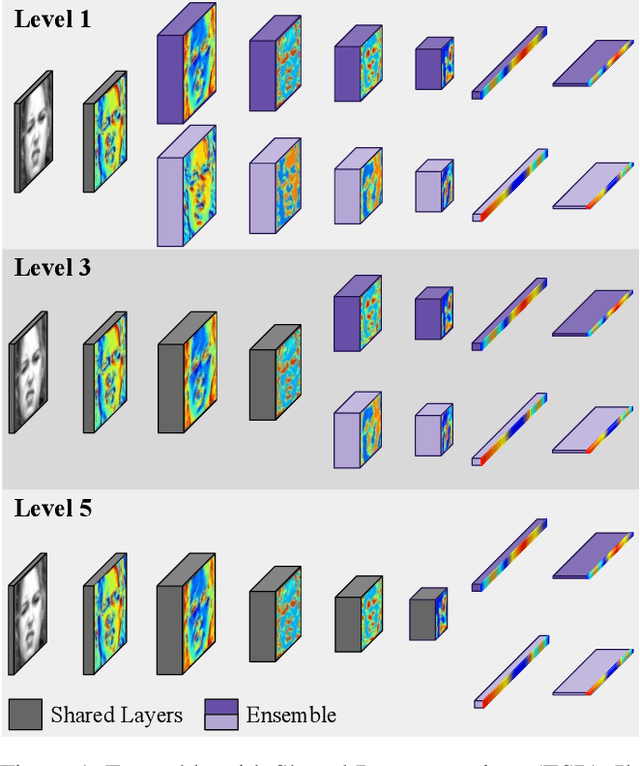
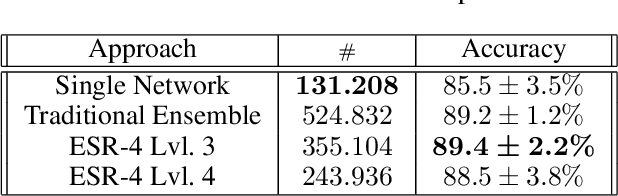
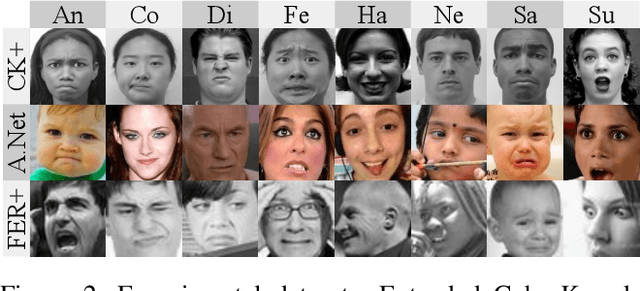
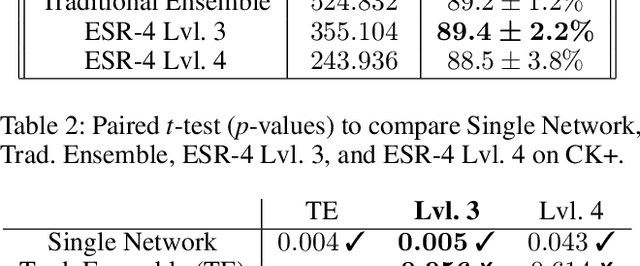
Ensemble methods, traditionally built with independently trained de-correlated models, have proven to be efficient methods for reducing the remaining residual generalization error, which results in robust and accurate methods for real-world applications. In the context of deep learning, however, training an ensemble of deep networks is costly and generates high redundancy which is inefficient. In this paper, we present experiments on Ensembles with Shared Representations (ESRs) based on convolutional networks to demonstrate, quantitatively and qualitatively, their data processing efficiency and scalability to large-scale datasets of facial expressions. We show that redundancy and computational load can be dramatically reduced by varying the branching level of the ESR without loss of diversity and generalization power, which are both important for ensemble performance. Experiments on large-scale datasets suggest that ESRs reduce the remaining residual generalization error on the AffectNet and FER+ datasets, reach human-level performance, and outperform state-of-the-art methods on facial expression recognition in the wild using emotion and affect concepts.
Enriching Existing Conversational Emotion Datasets with Dialogue Acts using Neural Annotators
Dec 05, 2019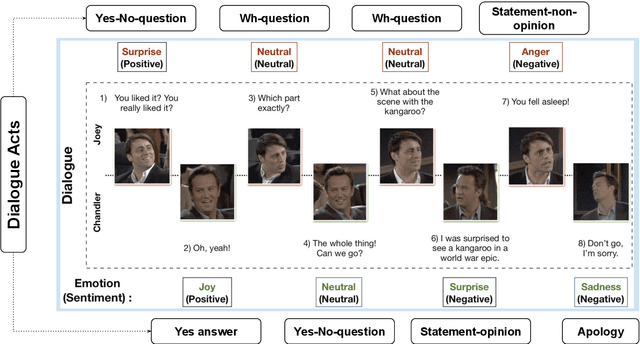

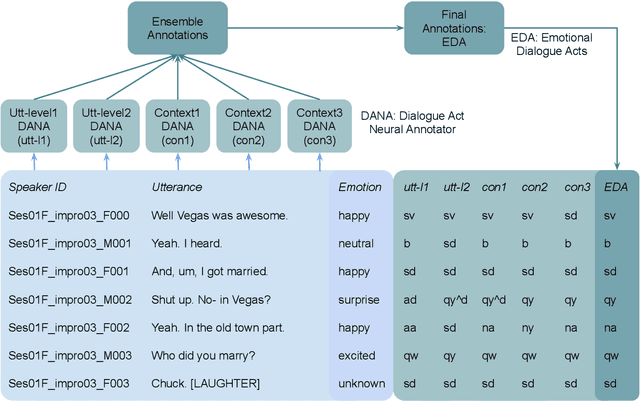
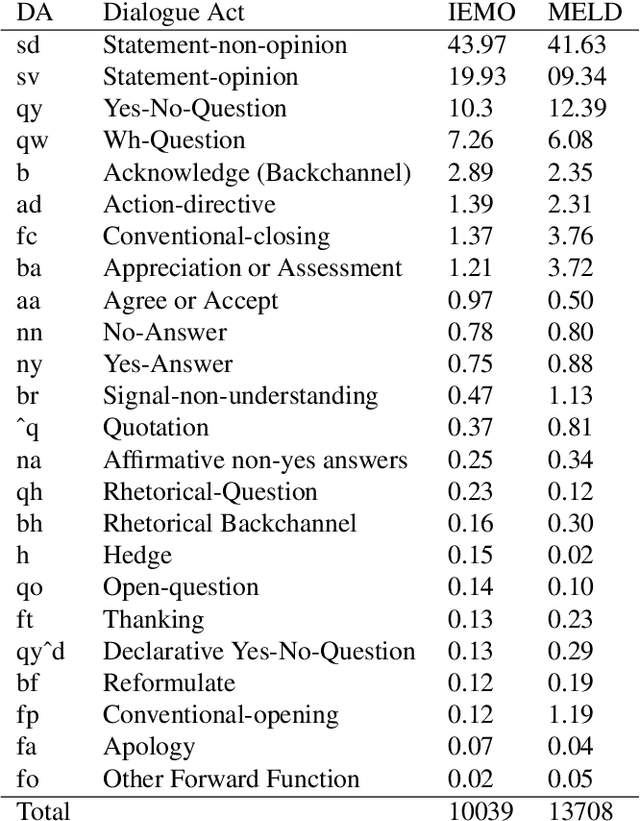
The recognition of emotion and dialogue acts enrich conversational analysis and help to build natural dialogue systems. Emotion makes us understand feelings and dialogue acts reflect the intentions and performative functions in the utterances. However, most of the textual and multi-modal conversational emotion datasets contain only emotion labels but not dialogue acts. To address this problem, we propose to use a pool of various recurrent neural models trained on a dialogue act corpus, with or without context. These neural models annotate the emotion corpus with dialogue act labels and an ensemble annotator extracts the final dialogue act label. We annotated two popular multi-modal emotion datasets: IEMOCAP and MELD. We analysed the co-occurrence of emotion and dialogue act labels and discovered specific relations. For example, Accept/Agree dialogue acts often occur with the Joy emotion, Apology with Sadness, and Thanking with Joy. We make the Emotional Dialogue Act (EDA) corpus publicly available to the research community for further study and analysis.
Hierarchical Control for Bipedal Locomotion using Central Pattern Generators and Neural Networks
Sep 02, 2019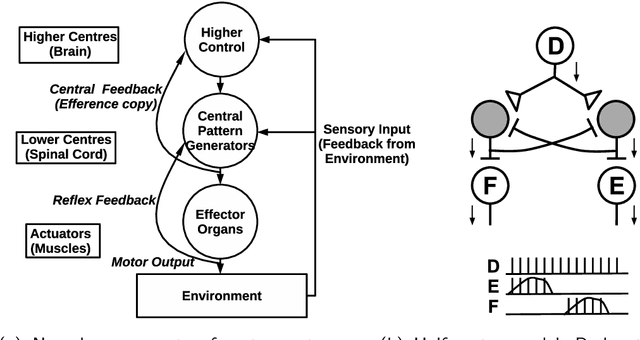
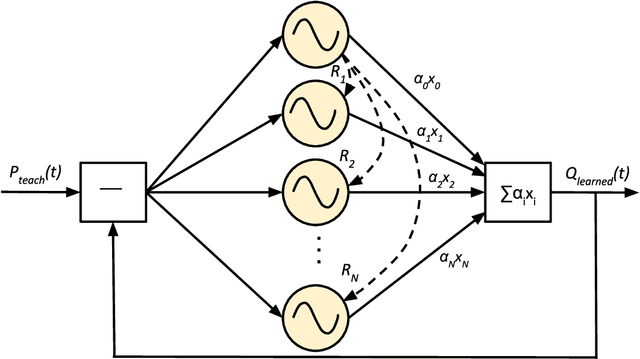
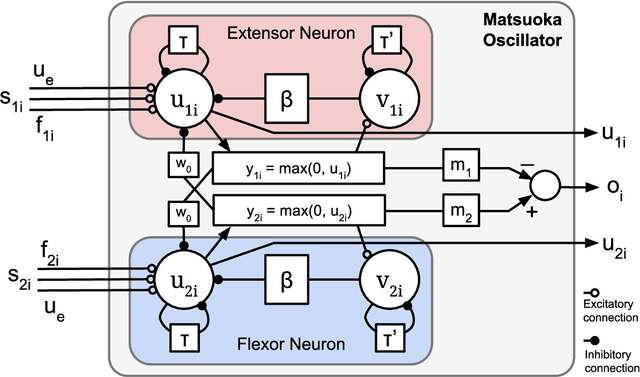
The complexity of bipedal locomotion may be attributed to the difficulty in synchronizing joint movements while at the same time achieving high-level objectives such as walking in a particular direction. Artificial central pattern generators (CPGs) can produce synchronized joint movements and have been used in the past for bipedal locomotion. However, most existing CPG-based approaches do not address the problem of high-level control explicitly. We propose a novel hierarchical control mechanism for bipedal locomotion where an optimized CPG network is used for joint control and a neural network acts as a high-level controller for modulating the CPG network. By separating motion generation from motion modulation, the high-level controller does not need to control individual joints directly but instead can develop to achieve a higher goal using a low-dimensional control signal. The feasibility of the hierarchical controller is demonstrated through simulation experiments using the Neuro-Inspired Companion (NICO) robot. Experimental results demonstrate the controller's ability to function even without the availability of an exact robot model.