 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Needs Labels? Adapting Vision Foundation Models With the Metadata You Already Have
Jun 03, 2026We propose a label-free approach to adapt powerful but generic vision foundation models to specialized scientific domains. Standard supervised fine-tuning is often ill-suited to these settings: labels are scarce, and task-specific training can collapse the model's generality and hurt robustness. We instead leverage metadata to adapt representations to new domains in a self-supervised manner. Our method, FINO, combines a standard self-supervised objective with flexible metadata guidance that handles both highly granular discrete metadata and continuous metadata. It encourages the representation to preserve informative factors while suppressing spurious ones. Across subcellular fluorescence microscopy, Earth observation, wildlife monitoring, and medical imaging, FINO consistently outperforms standard unsupervised domain adaptation and fully supervised adaptation. It also exceeds highly-specialized domain-specific state of the art, while using no task labels for backbone adaptation and only lightweight probes for supervision.
Disentangling the Factors of Convergence between Brains and Computer Vision Models
Aug 25, 2025Many AI models trained on natural images develop representations that resemble those of the human brain. However, the factors that drive this brain-model similarity remain poorly understood. To disentangle how the model, training and data independently lead a neural network to develop brain-like representations, we trained a family of self-supervised vision transformers (DINOv3) that systematically varied these different factors. We compare their representations of images to those of the human brain recorded with both fMRI and MEG, providing high resolution in spatial and temporal analyses. We assess the brain-model similarity with three complementary metrics focusing on overall representational similarity, topographical organization, and temporal dynamics. We show that all three factors - model size, training amount, and image type - independently and interactively impact each of these brain similarity metrics. In particular, the largest DINOv3 models trained with the most human-centric images reach the highest brain-similarity. This emergence of brain-like representations in AI models follows a specific chronology during training: models first align with the early representations of the sensory cortices, and only align with the late and prefrontal representations of the brain with considerably more training. Finally, this developmental trajectory is indexed by both structural and functional properties of the human cortex: the representations that are acquired last by the models specifically align with the cortical areas with the largest developmental expansion, thickness, least myelination, and slowest timescales. Overall, these findings disentangle the interplay between architecture and experience in shaping how artificial neural networks come to see the world as humans do, thus offering a promising framework to understand how the human brain comes to represent its visual world.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
May 24, 2024Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort. This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training. We posit that such datasets should be large, diverse and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of $k$-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data.
Better (pseudo-)labels for semi-supervised instance segmentation
Mar 18, 2024



Despite the availability of large datasets for tasks like image classification and image-text alignment, labeled data for more complex recognition tasks, such as detection and segmentation, is less abundant. In particular, for instance segmentation annotations are time-consuming to produce, and the distribution of instances is often highly skewed across classes. While semi-supervised teacher-student distillation methods show promise in leveraging vast amounts of unlabeled data, they suffer from miscalibration, resulting in overconfidence in frequently represented classes and underconfidence in rarer ones. Additionally, these methods encounter difficulties in efficiently learning from a limited set of examples. We introduce a dual-strategy to enhance the teacher model's training process, substantially improving the performance on few-shot learning. Secondly, we propose a calibration correction mechanism that that enables the student model to correct the teacher's calibration errors. Using our approach, we observed marked improvements over a state-of-the-art supervised baseline performance on the LVIS dataset, with an increase of 2.8% in average precision (AP) and 10.3% gain in AP for rare classes.
Unlocking Pre-trained Image Backbones for Semantic Image Synthesis
Jan 08, 2024



Semantic image synthesis, i.e., generating images from user-provided semantic label maps, is an important conditional image generation task as it allows to control both the content as well as the spatial layout of generated images. Although diffusion models have pushed the state of the art in generative image modeling, the iterative nature of their inference process makes them computationally demanding. Other approaches such as GANs are more efficient as they only need a single feed-forward pass for generation, but the image quality tends to suffer on large and diverse datasets. In this work, we propose a new class of GAN discriminators for semantic image synthesis that generates highly realistic images by exploiting feature backbone networks pre-trained for tasks such as image classification. We also introduce a new generator architecture with better context modeling and using cross-attention to inject noise into latent variables, leading to more diverse generated images. Our model, which we dub DP-SIMS, achieves state-of-the-art results in terms of image quality and consistency with the input label maps on ADE-20K, COCO-Stuff, and Cityscapes, surpassing recent diffusion models while requiring two orders of magnitude less compute for inference.
Guided Distillation for Semi-Supervised Instance Segmentation
Aug 03, 2023



Although instance segmentation methods have improved considerably, the dominant paradigm is to rely on fully-annotated training images, which are tedious to obtain. To alleviate this reliance, and boost results, semi-supervised approaches leverage unlabeled data as an additional training signal that limits overfitting to the labeled samples. In this context, we present novel design choices to significantly improve teacher-student distillation models. In particular, we (i) improve the distillation approach by introducing a novel "guided burn-in" stage, and (ii) evaluate different instance segmentation architectures, as well as backbone networks and pre-training strategies. Contrary to previous work which uses only supervised data for the burn-in period of the student model, we also use guidance of the teacher model to exploit unlabeled data in the burn-in period. Our improved distillation approach leads to substantial improvements over previous state-of-the-art results. For example, on the Cityscapes dataset we improve mask-AP from 23.7 to 33.9 when using labels for 10\% of images, and on the COCO dataset we improve mask-AP from 18.3 to 34.1 when using labels for only 1\% of the training data.
Sub-meter resolution canopy height maps using self-supervised learning and a vision transformer trained on Aerial and GEDI Lidar
Apr 17, 2023



Vegetation structure mapping is critical for understanding the global carbon cycle and monitoring nature-based approaches to climate adaptation and mitigation. Repeat measurements of these data allow for the observation of deforestation or degradation of existing forests, natural forest regeneration, and the implementation of sustainable agricultural practices like agroforestry. Assessments of tree canopy height and crown projected area at a high spatial resolution are also important for monitoring carbon fluxes and assessing tree-based land uses, since forest structures can be highly spatially heterogeneous, especially in agroforestry systems. Very high resolution satellite imagery (less than one meter (1m) ground sample distance) makes it possible to extract information at the tree level while allowing monitoring at a very large scale. This paper presents the first high-resolution canopy height map concurrently produced for multiple sub-national jurisdictions. Specifically, we produce canopy height maps for the states of California and S\~{a}o Paolo, at sub-meter resolution, a significant improvement over the ten meter (10m) resolution of previous Sentinel / GEDI based worldwide maps of canopy height. The maps are generated by applying a vision transformer to features extracted from a self-supervised model in Maxar imagery from 2017 to 2020, and are trained against aerial lidar and GEDI observations. We evaluate the proposed maps with set-aside validation lidar data as well as by comparing with other remotely sensed maps and field-collected data, and find our model produces an average Mean Absolute Error (MAE) within set-aside validation areas of 3.0 meters.
Unifying conditional and unconditional semantic image synthesis with OCO-GAN
Nov 25, 2022Generative image models have been extensively studied in recent years. In the unconditional setting, they model the marginal distribution from unlabelled images. To allow for more control, image synthesis can be conditioned on semantic segmentation maps that instruct the generator the position of objects in the image. While these two tasks are intimately related, they are generally studied in isolation. We propose OCO-GAN, for Optionally COnditioned GAN, which addresses both tasks in a unified manner, with a shared image synthesis network that can be conditioned either on semantic maps or directly on latents. Trained adversarially in an end-to-end approach with a shared discriminator, we are able to leverage the synergy between both tasks. We experiment with Cityscapes, COCO-Stuff, ADE20K datasets in a limited data, semi-supervised and full data regime and obtain excellent performance, improving over existing hybrid models that can generate both with and without conditioning in all settings. Moreover, our results are competitive or better than state-of-the art specialised unconditional and conditional models.
Efficient conditioned face animation using frontally-viewed embedding
Mar 16, 2022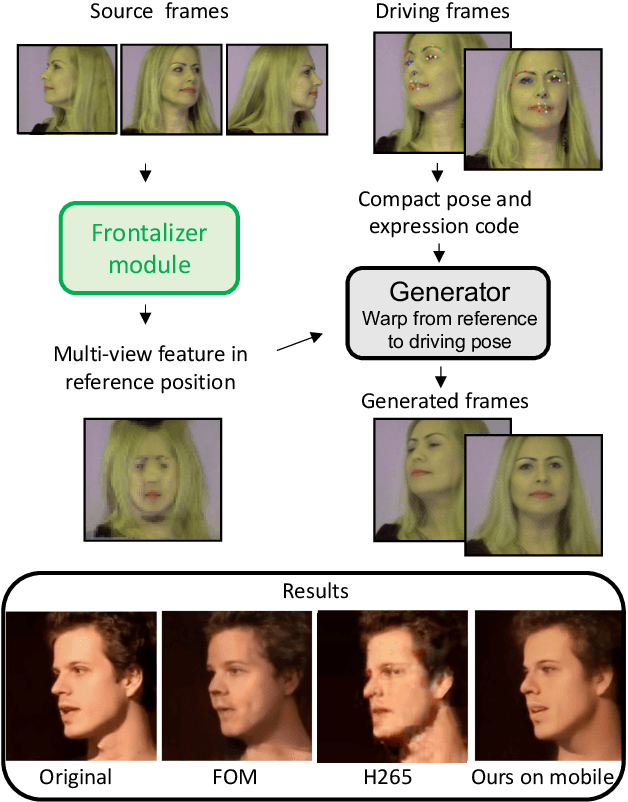


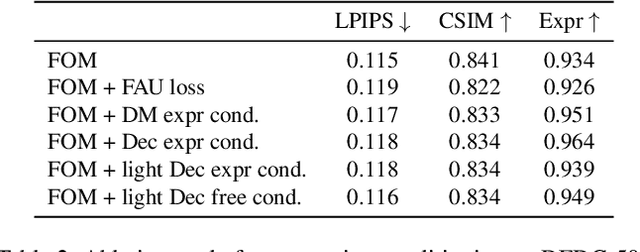
As the quality of few shot facial animation from landmarks increases, new applications become possible, such as ultra low bandwidth video chat compression with a high degree of realism. However, there are some important challenges to tackle in order to improve the experience in real world conditions. In particular, the current approaches fail to represent profile views without distortions, while running in a low compute regime. We focus on this key problem by introducing a multi-frames embedding dubbed Frontalizer to improve profile views rendering. In addition to this core improvement, we explore the learning of a latent code conditioning generations along with landmarks to better convey facial expressions. Our dense models achieves 22% of improvement in perceptual quality and 73% reduction of landmark error over the first order model baseline on a subset of DFDC videos containing head movements. Declined with mobile architectures, our models outperform the previous state-of-the-art (improving perceptual quality by more than 16% and reducing landmark error by more than 47% on two datasets) while running on real time on iPhone 8 with very low bandwidth requirements.