 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parametric Bi-Directional Curvature-Based Framework for Image Artifact Classification and Quantification
Aug 12, 2025This work presents a novel framework for No-Reference Image Quality Assessment (NR-IQA) founded on the analysis of directional image curvature. Within this framework, we define a measure of Anisotropic Texture Richness (ATR), which is computed at the pixel level using two tunable thresholds -- one permissive and one restrictive -- that quantify orthogonal texture suppression. When its parameters are optimized for a specific artifact, the resulting ATR score serves as a high-performance quality metric, achieving Spearman correlations with human perception of approximately -0.93 for Gaussian blur and -0.95 for white noise on the LIVE dataset. The primary contribution is a two-stage system that leverages the differential response of ATR to various distortions. First, the system utilizes the signature from two specialist ATR configurations to classify the primary artifact type (blur vs. noise) with over 97% accuracy. Second, following classification, it employs a dedicated regression model mapping the relevant ATR score to a quality rating to quantify the degradation. On a combined dataset, the complete system predicts human scores with a coefficient of determination (R2) of 0.892 and a Root Mean Square Error (RMSE) of 5.17 DMOS points. This error corresponds to just 7.4% of the dataset's total quality range, demonstrating high predictive accuracy. This establishes our framework as a robust, dual-purpose tool for the classification and subsequent quantification of image degradation.
Equalization and Brightness Mapping Modes of Color-to-Gray Projection Operators
Aug 21, 2022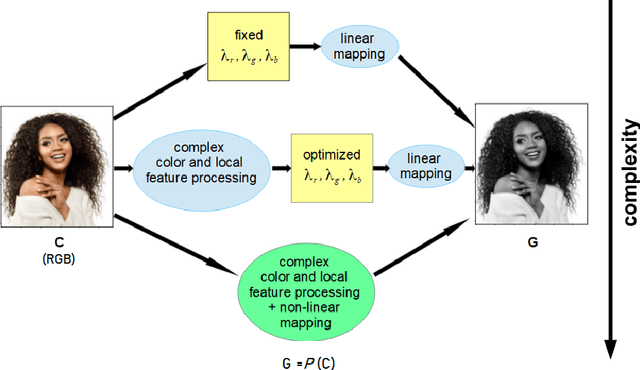

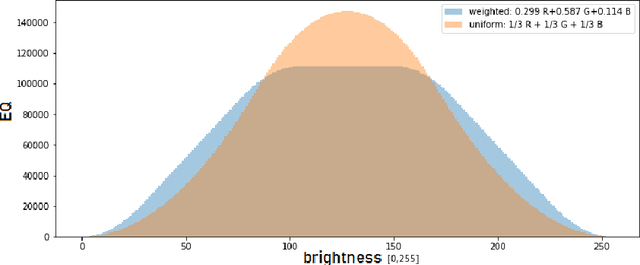
In this article, the conversion of color RGB images to grayscale is covered by characterizing the mathematical operators used to project 3 color channels to a single one. Based on the fact that most operators assign each of the $256^3$ colors a single gray level, ranging from 0 to 255, they are clustering algorithms that distribute the color population into 256 clusters of increasing brightness. To visualize the way operators work the sizes of the clusters and the average brightness of each cluster are plotted. The equalization mode (EQ) introduced in this work focuses on cluster sizes, while the brightness mapping (BM) mode describes the CIE L* luminance distribution per cluster. Three classes of EQ modes and two classes of BM modes were found in linear operators, defining a 6-class taxonomy. The theoretical/methodological framework introduced was applied in a case study considering the equal-weights uniform operator, the NTSC standard operator, and an operator chosen as ideal to lighten the faces of black people to improve facial recognition in current biased classifiers. It was found that most current metrics used to assess the quality of color-to-gray conversions better assess one of the two BM mode classes, but the ideal operator chosen by a human team belongs to the other class. Therefore, this cautions against using these general metrics for specific purpose color-to-gray conversions. It should be noted that eventual applications of this framework to non-linear operators can give rise to new classes of EQ and BM modes. The main contribution of this article is to provide a tool to better understand color to gray converters in general, even those based on machine learning, within the current trend of better explainability of models.
A High Accuracy Image Hashing and Random Forest Classifier for Crack Detection in Concrete Surface Images
Jun 10, 2021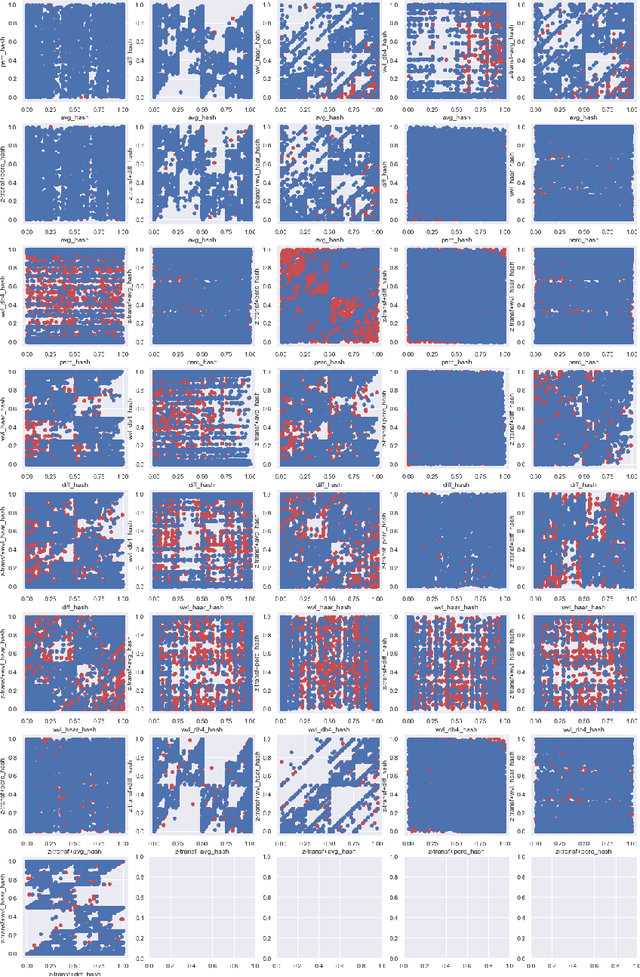
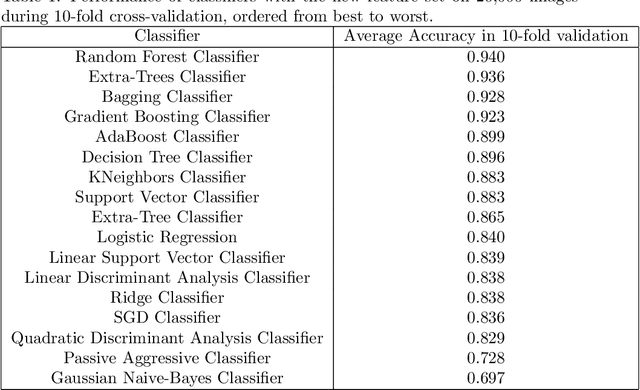
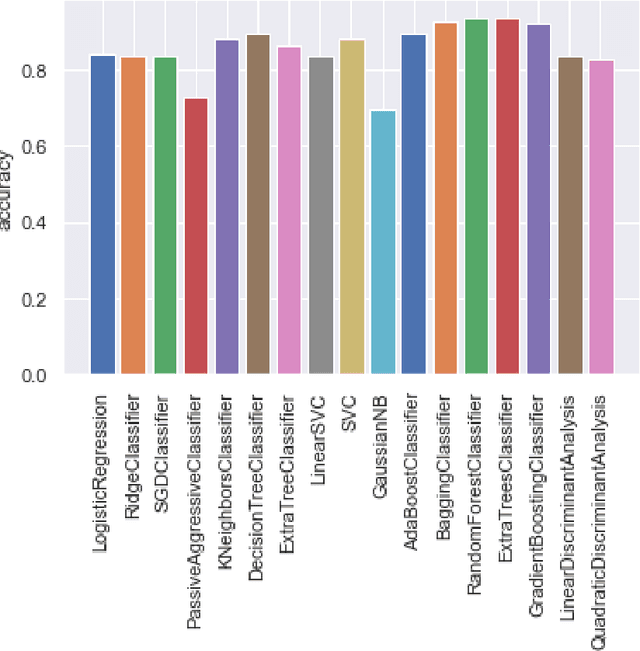
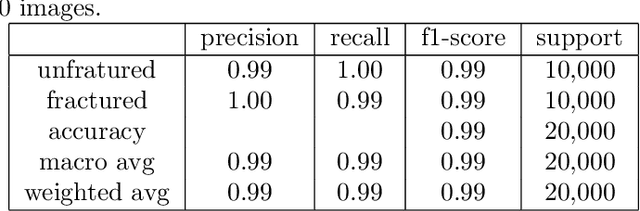
Automatic detection of cracks in concrete surfaces based on image processing is a clear trend in modern civil engineering applications. Most infrastructure is made of concrete and cracks reveal degradation of the structural integrity of the facilities, which can lead to extreme structural failures. There are many approaches to overcome the difficulties in image-based crack detection, ranging from the pre-processing of the input image to the proper adjustment of efficient classifiers, passing through the essential feature selection step. This paper is related to the process of constructing features from images to allow a classifier to find the boundaries between images with and without cracks. The most common approaches to feature extraction are the convolutional techniques to extract relevant positional information from images and the filters for edge detection or background removal. Here we apply hashing techniques for the first time used for features extraction in this problem. The study of the classification capacity of hashes is carried out by comparing 5 different hash algorithms, 2 of which are based on wavelets. The effect of applying the z-transform on the images before calculating the hashes was also studied, which totals the study of 10 new features for this problem. A comparative study of 17 different algorithms from the scikit-learn library was carried out. The results show that 9 of the 10 features are relevant to the problem, as well as that the accuracy of the classifiers varied between 0.697 for the Naive-Bayes Gaussian classifier and 0.99 for the Random Forest (RF) classifier. The feature extraction algorithm developed in this work and the RF classifier algorithm is suitable for embedded applications, for example in inspection drones, as long as they are highly accurate and computationally light, both in terms of memory and processing time.