 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeD: Context-Aware Diffusion for Accurate 3D Gaze Estimation
Jan 19, 2026We introduce GazeD, a new 3D gaze estimation method that jointly provides 3D gaze and human pose from a single RGB image. Leveraging the ability of diffusion models to deal with uncertainty, it generates multiple plausible 3D gaze and pose hypotheses based on the 2D context information extracted from the input image. Specifically, we condition the denoising process on the 2D pose, the surroundings of the subject, and the context of the scene. With GazeD we also introduce a novel way of representing the 3D gaze by positioning it as an additional body joint at a fixed distance from the eyes. The rationale is that the gaze is usually closely related to the pose, and thus it can benefit from being jointly denoised during the diffusion process. Evaluations across three benchmark datasets demonstrate that GazeD achieves state-of-the-art performance in 3D gaze estimation, even surpassing methods that rely on temporal information. Project details will be available at https://aimagelab.ing.unimore.it/go/gazed.
BRUM: Robust 3D Vehicle Reconstruction from 360 Sparse Images
Jul 16, 2025Accurate 3D reconstruction of vehicles is vital for applications such as vehicle inspection, predictive maintenance, and urban planning. Existing methods like Neural Radiance Fields and Gaussian Splatting have shown impressive results but remain limited by their reliance on dense input views, which hinders real-world applicability. This paper addresses the challenge of reconstructing vehicles from sparse-view inputs, leveraging depth maps and a robust pose estimation architecture to synthesize novel views and augment training data. Specifically, we enhance Gaussian Splatting by integrating a selective photometric loss, applied only to high-confidence pixels, and replacing standard Structure-from-Motion pipelines with the DUSt3R architecture to improve camera pose estimation. Furthermore, we present a novel dataset featuring both synthetic and real-world public transportation vehicles, enabling extensive evaluation of our approach. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, showcasing the method's ability to achieve high-quality reconstructions even under constrained input conditions.
TakuNet: an Energy-Efficient CNN for Real-Time Inference on Embedded UAV systems in Emergency Response Scenarios
Jan 10, 2025Designing efficient neural networks for embedded devices is a critical challenge, particularly in applications requiring real-time performance, such as aerial imaging with drones and UAVs for emergency responses. In this work, we introduce TakuNet, a novel light-weight architecture which employs techniques such as depth-wise convolutions and an early downsampling stem to reduce computational complexity while maintaining high accuracy. It leverages dense connections for fast convergence during training and uses 16-bit floating-point precision for optimization on embedded hardware accelerators. Experimental evaluation on two public datasets shows that TakuNet achieves near-state-of-the-art accuracy in classifying aerial images of emergency situations, despite its minimal parameter count. Real-world tests on embedded devices, namely Jetson Orin Nano and Raspberry Pi, confirm TakuNet's efficiency, achieving more than 650 fps on the 15W Jetson board, making it suitable for real-time AI processing on resource-constrained platforms and advancing the applicability of drones in emergency scenarios. The code and implementation details are publicly released.
Depth-based Privileged Information for Boosting 3D Human Pose Estimation on RGB
Sep 17, 2024



Despite the recent advances in computer vision research, estimating the 3D human pose from single RGB images remains a challenging task, as multiple 3D poses can correspond to the same 2D projection on the image. In this context, depth data could help to disambiguate the 2D information by providing additional constraints about the distance between objects in the scene and the camera. Unfortunately, the acquisition of accurate depth data is limited to indoor spaces and usually is tied to specific depth technologies and devices, thus limiting generalization capabilities. In this paper, we propose a method able to leverage the benefits of depth information without compromising its broader applicability and adaptability in a predominantly RGB-camera-centric landscape. Our approach consists of a heatmap-based 3D pose estimator that, leveraging the paradigm of Privileged Information, is able to hallucinate depth information from the RGB frames given at inference time. More precisely, depth information is used exclusively during training by enforcing our RGB-based hallucination network to learn similar features to a backbone pre-trained only on depth data. This approach proves to be effective even when dealing with limited and small datasets. Experimental results reveal that the paradigm of Privileged Information significantly enhances the model's performance, enabling efficient extraction of depth information by using only RGB images.
KRONC: Keypoint-based Robust Camera Optimization for 3D Car Reconstruction
Sep 09, 2024



The three-dimensional representation of objects or scenes starting from a set of images has been a widely discussed topic for years and has gained additional attention after the diffusion of NeRF-based approaches. However, an underestimated prerequisite is the knowledge of camera poses or, more specifically, the estimation of the extrinsic calibration parameters. Although excellent general-purpose Structure-from-Motion methods are available as a pre-processing step, their computational load is high and they require a lot of frames to guarantee sufficient overlapping among the views. This paper introduces KRONC, a novel approach aimed at inferring view poses by leveraging prior knowledge about the object to reconstruct and its representation through semantic keypoints. With a focus on vehicle scenes, KRONC is able to estimate the position of the views as a solution to a light optimization problem targeting the convergence of keypoints' back-projections to a singular point. To validate the method, a specific dataset of real-world car scenes has been collected. Experiments confirm KRONC's ability to generate excellent estimates of camera poses starting from very coarse initialization. Results are comparable with Structure-from-Motion methods with huge savings in computation. Code and data will be made publicly available.
Robot Pose Nowcasting: Forecast the Future to Improve the Present
Aug 24, 2023



In recent years, the effective and safe collaboration between humans and machines has gained significant importance, particularly in the Industry 4.0 scenario. A critical prerequisite for realizing this collaborative paradigm is precisely understanding the robot's 3D pose within its environment. Therefore, in this paper, we introduce a novel vision-based system leveraging depth data to accurately establish the 3D locations of robotic joints. Specifically, we prove the ability of the proposed system to enhance its current pose estimation accuracy by jointly learning to forecast future poses. Indeed, we introduce the concept of Pose Nowcasting, denoting the capability of a system to exploit the learned knowledge of the future to improve the estimation of the present. The experimental evaluation is conducted on two different datasets, providing state-of-the-art and real-time performance and confirming the validity of the proposed method on both the robotic and human scenarios.
CarPatch: A Synthetic Benchmark for Radiance Field Evaluation on Vehicle Components
Jul 24, 2023



Neural Radiance Fields (NeRFs) have gained widespread recognition as a highly effective technique for representing 3D reconstructions of objects and scenes derived from sets of images. Despite their efficiency, NeRF models can pose challenges in certain scenarios such as vehicle inspection, where the lack of sufficient data or the presence of challenging elements (e.g. reflections) strongly impact the accuracy of the reconstruction. To this aim, we introduce CarPatch, a novel synthetic benchmark of vehicles. In addition to a set of images annotated with their intrinsic and extrinsic camera parameters, the corresponding depth maps and semantic segmentation masks have been generated for each view. Global and part-based metrics have been defined and used to evaluate, compare, and better characterize some state-of-the-art techniques. The dataset is publicly released at https://aimagelab.ing.unimore.it/go/carpatch and can be used as an evaluation guide and as a baseline for future work on this challenging topic.
Semi-Perspective Decoupled Heatmaps for 3D Robot Pose Estimation from Depth Maps
Jul 06, 2022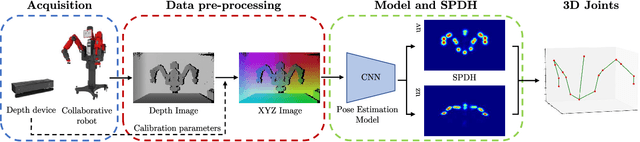
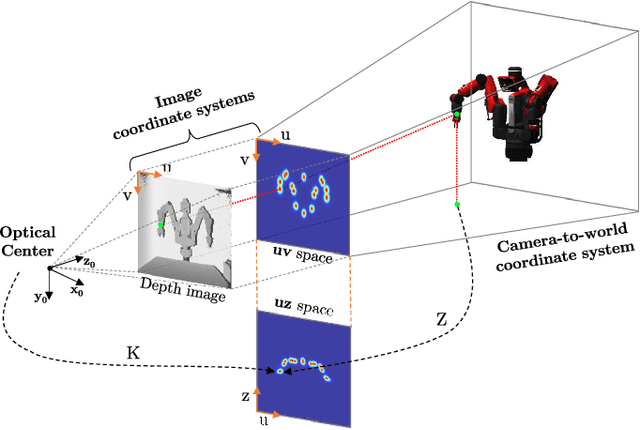
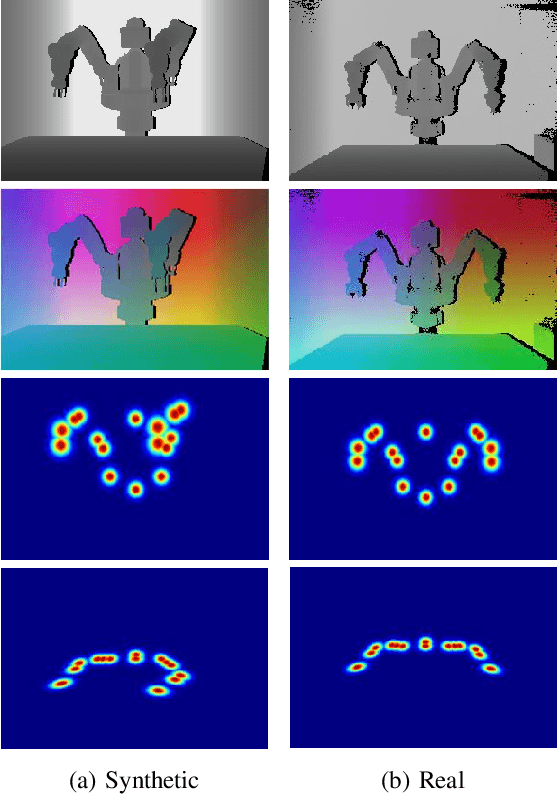

Knowing the exact 3D location of workers and robots in a collaborative environment enables several real applications, such as the detection of unsafe situations or the study of mutual interactions for statistical and social purposes. In this paper, we propose a non-invasive and light-invariant framework based on depth devices and deep neural networks to estimate the 3D pose of robots from an external camera. The method can be applied to any robot without requiring hardware access to the internal states. We introduce a novel representation of the predicted pose, namely Semi-Perspective Decoupled Heatmaps (SPDH), to accurately compute 3D joint locations in world coordinates adapting efficient deep networks designed for the 2D Human Pose Estimation. The proposed approach, which takes as input a depth representation based on XYZ coordinates, can be trained on synthetic depth data and applied to real-world settings without the need for domain adaptation techniques. To this end, we present the SimBa dataset, based on both synthetic and real depth images, and use it for the experimental evaluation. Results show that the proposed approach, made of a specific depth map representation and the SPDH, overcomes the current state of the art.
Multi-Category Mesh Reconstruction From Image Collections
Oct 21, 2021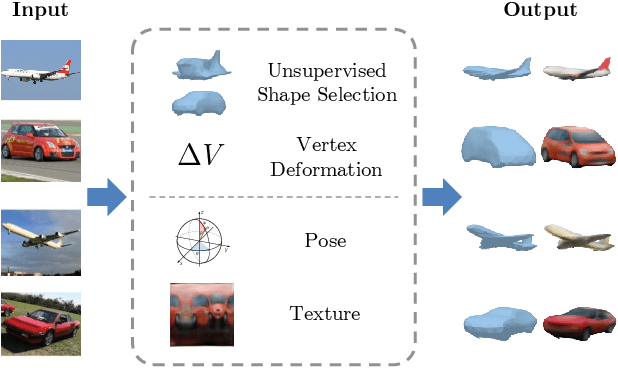
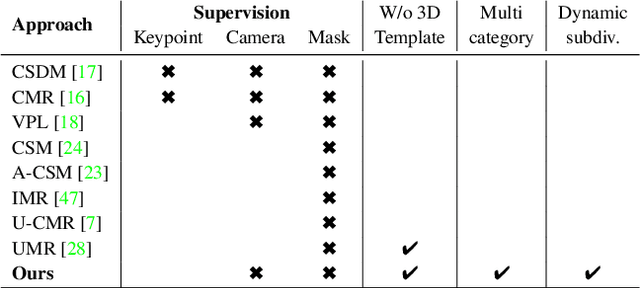
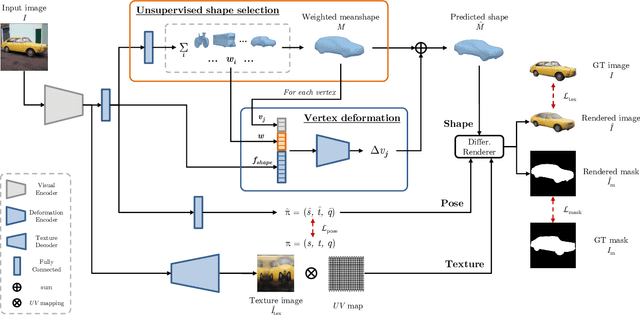
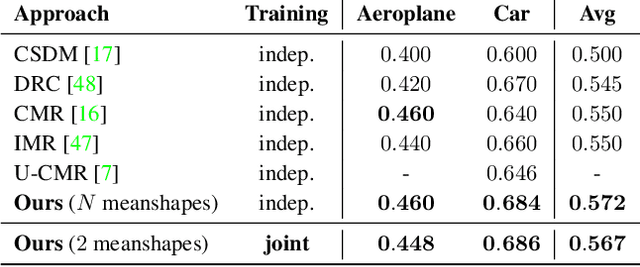
Recently, learning frameworks have shown the capability of inferring the accurate shape, pose, and texture of an object from a single RGB image. However, current methods are trained on image collections of a single category in order to exploit specific priors, and they often make use of category-specific 3D templates. In this paper, we present an alternative approach that infers the textured mesh of objects combining a series of deformable 3D models and a set of instance-specific deformation, pose, and texture. Differently from previous works, our method is trained with images of multiple object categories using only foreground masks and rough camera poses as supervision. Without specific 3D templates, the framework learns category-level models which are deformed to recover the 3D shape of the depicted object. The instance-specific deformations are predicted independently for each vertex of the learned 3D mesh, enabling the dynamic subdivision of the mesh during the training process. Experiments show that the proposed framework can distinguish between different object categories and learn category-specific shape priors in an unsupervised manner. Predicted shapes are smooth and can leverage from multiple steps of subdivision during the training process, obtaining comparable or state-of-the-art results on two public datasets. Models and code are publicly released.
SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild
Jun 21, 2021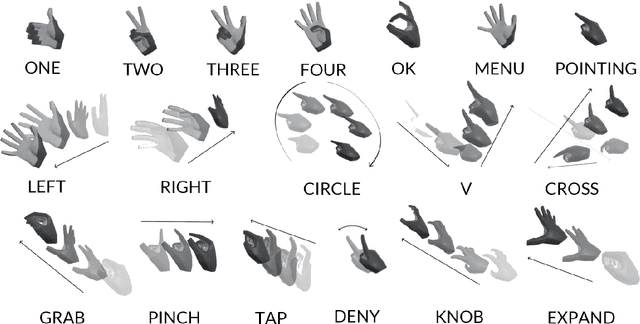
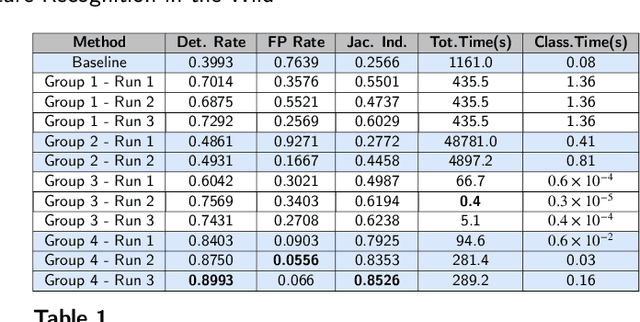
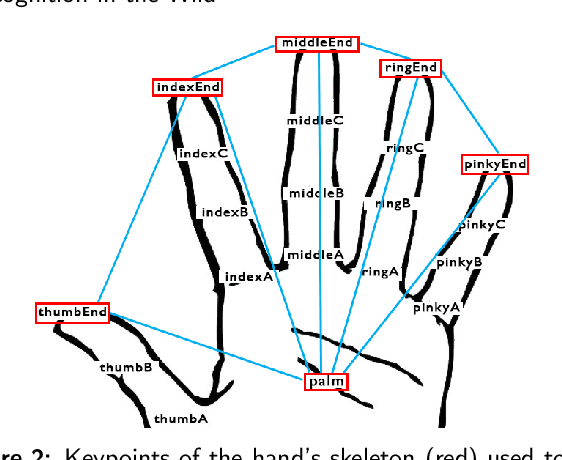
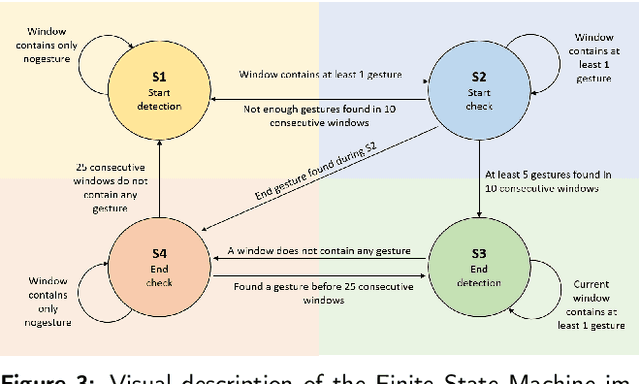
Gesture recognition is a fundamental tool to enable novel interaction paradigms in a variety of application scenarios like Mixed Reality environments, touchless public kiosks, entertainment systems, and more. Recognition of hand gestures can be nowadays performed directly from the stream of hand skeletons estimated by software provided by low-cost trackers (Ultraleap) and MR headsets (Hololens, Oculus Quest) or by video processing software modules (e.g. Google Mediapipe). Despite the recent advancements in gesture and action recognition from skeletons, it is unclear how well the current state-of-the-art techniques can perform in a real-world scenario for the recognition of a wide set of heterogeneous gestures, as many benchmarks do not test online recognition and use limited dictionaries. This motivated the proposal of the SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild. For this contest, we created a novel dataset with heterogeneous gestures featuring different types and duration. These gestures have to be found inside sequences in an online recognition scenario. This paper presents the result of the contest, showing the performances of the techniques proposed by four research groups on the challenging task compared with a simple baseline method.