 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
OpticalDR: A Deep Optical Imaging Model for Privacy-Protective Depression Recognition
Feb 29, 2024
Depression Recognition (DR) poses a considerable challenge, especially in the context of the growing concerns surrounding privacy. Traditional automatic diagnosis of DR technology necessitates the use of facial images, undoubtedly expose the patient identity features and poses privacy risks. In order to mitigate the potential risks associated with the inappropriate disclosure of patient facial images, we design a new imaging system to erase the identity information of captured facial images while retain disease-relevant features. It is irreversible for identity information recovery while preserving essential disease-related characteristics necessary for accurate DR. More specifically, we try to record a de-identified facial image (erasing the identifiable features as much as possible) by a learnable lens, which is optimized in conjunction with the following DR task as well as a range of face analysis related auxiliary tasks in an end-to-end manner. These aforementioned strategies form our final Optical deep Depression Recognition network (OpticalDR). Experiments on CelebA, AVEC 2013, and AVEC 2014 datasets demonstrate that our OpticalDR has achieved state-of-the-art privacy protection performance with an average AUC of 0.51 on popular facial recognition models, and competitive results for DR with MAE/RMSE of 7.53/8.48 on AVEC 2013 and 7.89/8.82 on AVEC 2014, respectively.
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Feb 01, 2024While state-of-the-art facial expression recognition (FER) classifiers achieve a high level of accuracy, they lack interpretability, an important aspect for end-users. To recognize basic facial expressions, experts resort to a codebook associating a set of spatial action units to a facial expression. In this paper, we follow the same expert footsteps, and propose a learning strategy that allows us to explicitly incorporate spatial action units (aus) cues into the classifier's training to build a deep interpretable model. In particular, using this aus codebook, input image expression label, and facial landmarks, a single action units heatmap is built to indicate the most discriminative regions of interest in the image w.r.t the facial expression. We leverage this valuable spatial cue to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with \aus map. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with aus maps, simulating the experts' decision process. This is achieved using only the image class expression as supervision and without any extra manual annotations. Moreover, our method is generic. It can be applied to any CNN- or transformer-based deep classifier without the need for architectural change or adding significant training time. Our extensive evaluation on two public benchmarks RAFDB, and AFFECTNET datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on Class-Activation Mapping methods (CAMs), and we show that our training technique improves the CAM interpretability.
(Beyond) Reasonable Doubt: Challenges that Public Defenders Face in Scrutinizing AI in Court
Mar 13, 2024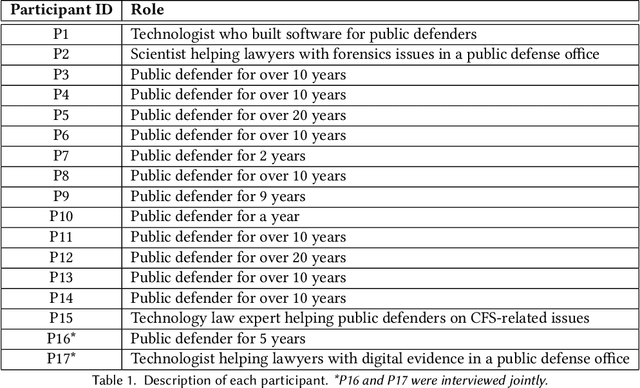
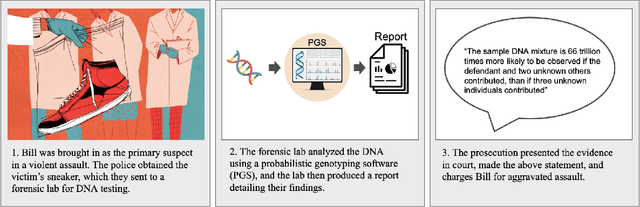
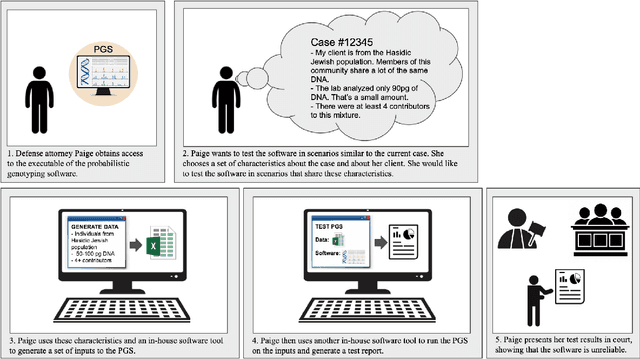

Accountable use of AI systems in high-stakes settings relies on making systems contestable. In this paper we study efforts to contest AI systems in practice by studying how public defenders scrutinize AI in court. We present findings from interviews with 17 people in the U.S. public defense community to understand their perceptions of and experiences scrutinizing computational forensic software (CFS) -- automated decision systems that the government uses to convict and incarcerate, such as facial recognition, gunshot detection, and probabilistic genotyping tools. We find that our participants faced challenges assessing and contesting CFS reliability due to difficulties (a) navigating how CFS is developed and used, (b) overcoming judges and jurors' non-critical perceptions of CFS, and (c) gathering CFS expertise. To conclude, we provide recommendations that center the technical, social, and institutional context to better position interventions such as performance evaluations to support contestability in practice.
FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
Mar 04, 2024
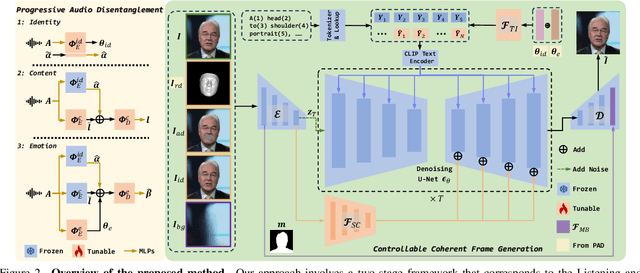
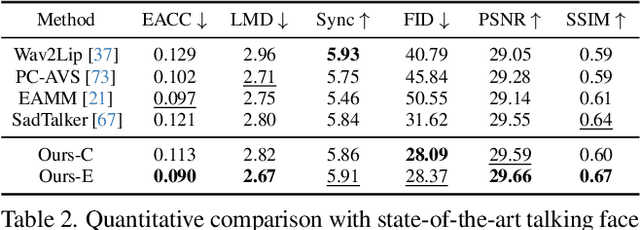
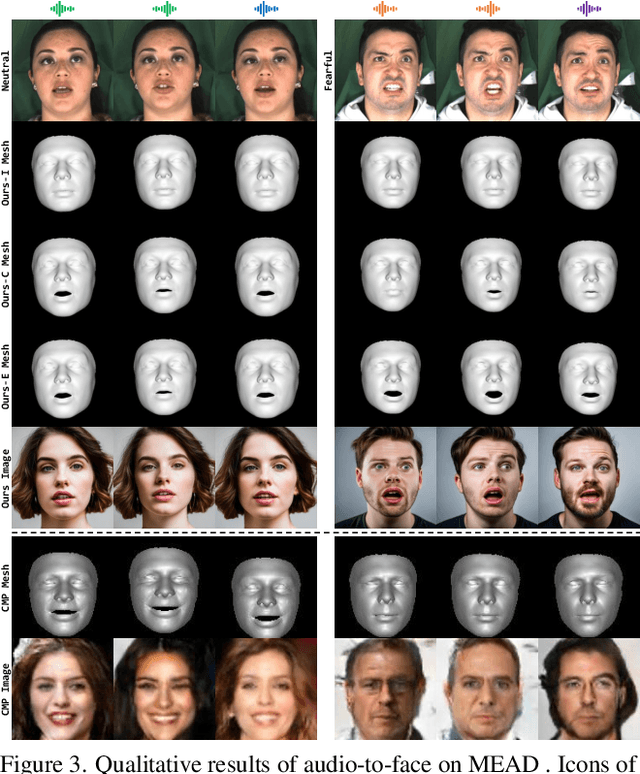
In this paper, we abstract the process of people hearing speech, extracting meaningful cues, and creating various dynamically audio-consistent talking faces, termed Listening and Imagining, into the task of high-fidelity diverse talking faces generation from a single audio. Specifically, it involves two critical challenges: one is to effectively decouple identity, content, and emotion from entangled audio, and the other is to maintain intra-video diversity and inter-video consistency. To tackle the issues, we first dig out the intricate relationships among facial factors and simplify the decoupling process, tailoring a Progressive Audio Disentanglement for accurate facial geometry and semantics learning, where each stage incorporates a customized training module responsible for a specific factor. Secondly, to achieve visually diverse and audio-synchronized animation solely from input audio within a single model, we introduce the Controllable Coherent Frame generation, which involves the flexible integration of three trainable adapters with frozen Latent Diffusion Models (LDMs) to focus on maintaining facial geometry and semantics, as well as texture and temporal coherence between frames. In this way, we inherit high-quality diverse generation from LDMs while significantly improving their controllability at a low training cost. Extensive experiments demonstrate the flexibility and effectiveness of our method in handling this paradigm. The codes will be released at https://github.com/modelscope/facechain.
Data Augmentation and Transfer Learning Approaches Applied to Facial Expressions Recognition
Feb 15, 2024The face expression is the first thing we pay attention to when we want to understand a person's state of mind. Thus, the ability to recognize facial expressions in an automatic way is a very interesting research field. In this paper, because the small size of available training datasets, we propose a novel data augmentation technique that improves the performances in the recognition task. We apply geometrical transformations and build from scratch GAN models able to generate new synthetic images for each emotion type. Thus, on the augmented datasets we fine tune pretrained convolutional neural networks with different architectures. To measure the generalization ability of the models, we apply extra-database protocol approach, namely we train models on the augmented versions of training dataset and test them on two different databases. The combination of these techniques allows to reach average accuracy values of the order of 85\% for the InceptionResNetV2 model.
* The 11th International Conference on Artificial Intelligence, Soft Computing and Applications (AIAA 2021)
Faceptor: A Generalist Model for Face Perception
Mar 14, 2024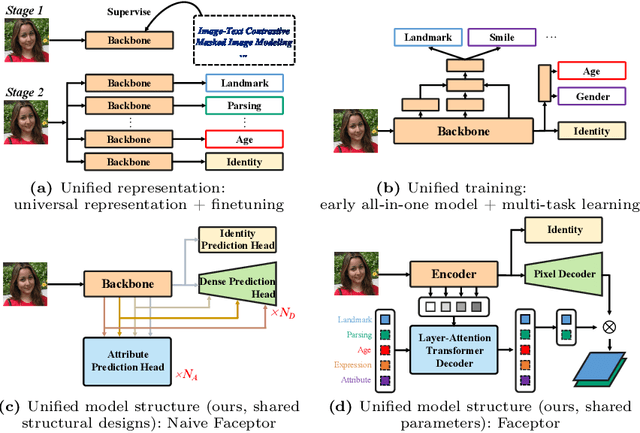

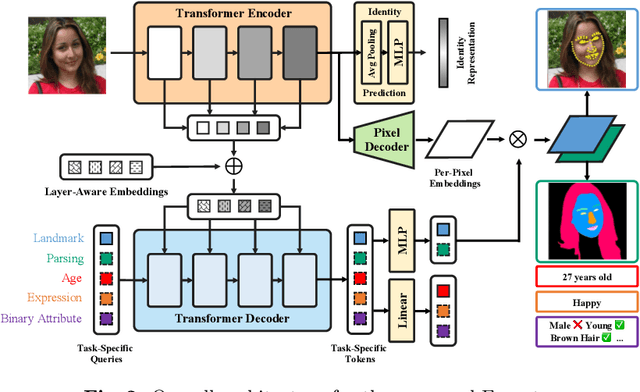
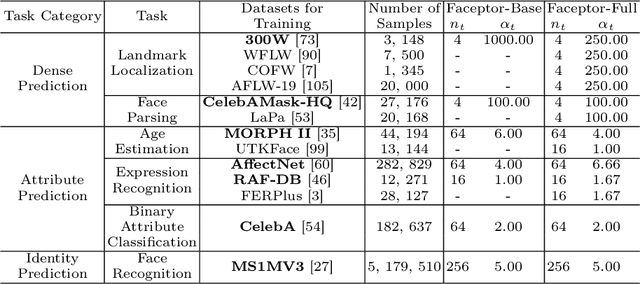
With the comprehensive research conducted on various face analysis tasks, there is a growing interest among researchers to develop a unified approach to face perception. Existing methods mainly discuss unified representation and training, which lack task extensibility and application efficiency. To tackle this issue, we focus on the unified model structure, exploring a face generalist model. As an intuitive design, Naive Faceptor enables tasks with the same output shape and granularity to share the structural design of the standardized output head, achieving improved task extensibility. Furthermore, Faceptor is proposed to adopt a well-designed single-encoder dual-decoder architecture, allowing task-specific queries to represent new-coming semantics. This design enhances the unification of model structure while improving application efficiency in terms of storage overhead. Additionally, we introduce Layer-Attention into Faceptor, enabling the model to adaptively select features from optimal layers to perform the desired tasks. Through joint training on 13 face perception datasets, Faceptor achieves exceptional performance in facial landmark localization, face parsing, age estimation, expression recognition, binary attribute classification, and face recognition, achieving or surpassing specialized methods in most tasks. Our training framework can also be applied to auxiliary supervised learning, significantly improving performance in data-sparse tasks such as age estimation and expression recognition. The code and models will be made publicly available at https://github.com/lxq1000/Faceptor.
A Study on Domain Generalization for Failure Detection through Human Reactions in HRI
Mar 10, 2024
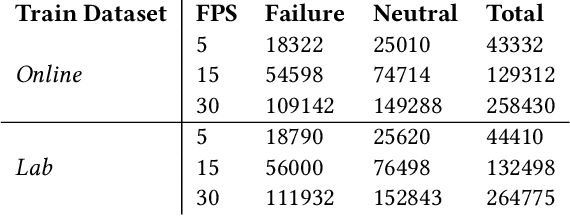

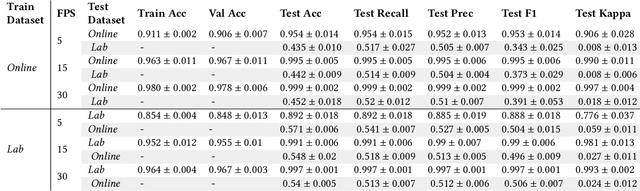
Machine learning models are commonly tested in-distribution (same dataset); performance almost always drops in out-of-distribution settings. For HRI research, the goal is often to develop generalized models. This makes domain generalization - retaining performance in different settings - a critical issue. In this study, we present a concise analysis of domain generalization in failure detection models trained on human facial expressions. Using two distinct datasets of humans reacting to videos where error occurs, one from a controlled lab setting and another collected online, we trained deep learning models on each dataset. When testing these models on the alternate dataset, we observed a significant performance drop. We reflect on the causes for the observed model behavior and leave recommendations. This work emphasizes the need for HRI research focusing on improving model robustness and real-life applicability.
Stable-Makeup: When Real-World Makeup Transfer Meets Diffusion Model
Mar 12, 2024Current makeup transfer methods are limited to simple makeup styles, making them difficult to apply in real-world scenarios. In this paper, we introduce Stable-Makeup, a novel diffusion-based makeup transfer method capable of robustly transferring a wide range of real-world makeup, onto user-provided faces. Stable-Makeup is based on a pre-trained diffusion model and utilizes a Detail-Preserving (D-P) makeup encoder to encode makeup details. It also employs content and structural control modules to preserve the content and structural information of the source image. With the aid of our newly added makeup cross-attention layers in U-Net, we can accurately transfer the detailed makeup to the corresponding position in the source image. After content-structure decoupling training, Stable-Makeup can maintain content and the facial structure of the source image. Moreover, our method has demonstrated strong robustness and generalizability, making it applicable to varioustasks such as cross-domain makeup transfer, makeup-guided text-to-image generation and so on. Extensive experiments have demonstrated that our approach delivers state-of-the-art (SOTA) results among existing makeup transfer methods and exhibits a highly promising with broad potential applications in various related fields.
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Feb 27, 2024In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
Exploiting the Margin: How Capitalism Fuels AI at the Expense of Minoritized Groups
Mar 10, 2024This article investigates the complex nexus of capitalism, racial oppression, and artificial intelligence (AI), revealing how these elements coalesce to deepen social inequities. By tracing the historical exploitation of marginalized communities through capitalist practices, the study demonstrates how AI technologies not only reflect but also amplify societal biases, particularly in exacerbating racial disparities. Through a focused analysis, the paper presents how AI's development and application exploit marginalized groups via mechanisms such as gig economy labor abuses, biased facial recognition technologies, and the disproportionate mental health burdens placed on these communities. These examples underscore the critical role of AI in reinforcing and intensifying existing inequalities. Concluding that unregulated AI significantly threatens to compound current oppressions, the article calls for a concerted effort towards responsible AI development. This entails adopting a holistic approach that rectifies systemic flaws and champions the empowerment of marginalized individuals, ensuring that technological advancement contributes to societal healing rather than perpetuating cycles of exploitation.