 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Joint Multimodal Transformer for Dimensional Emotional Recognition in the Wild
Mar 15, 2024
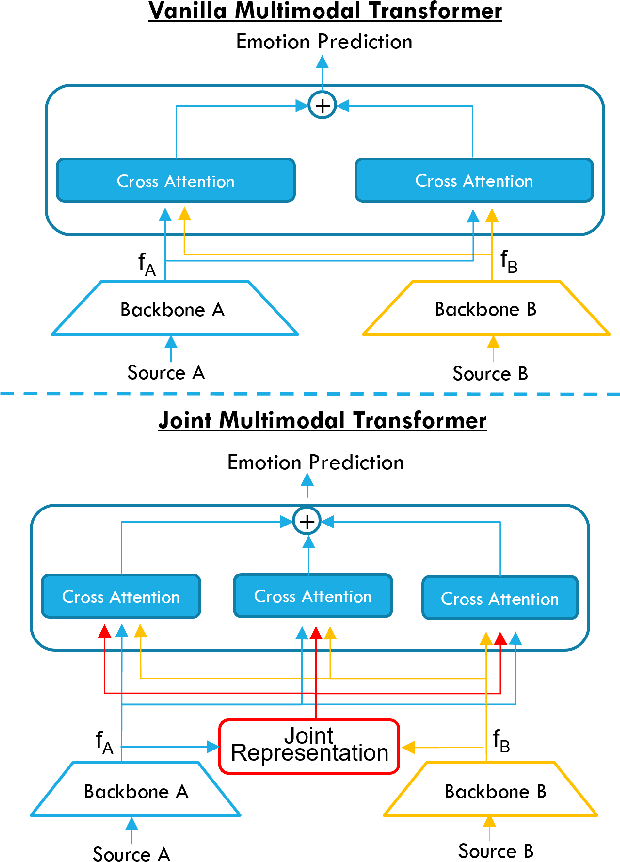
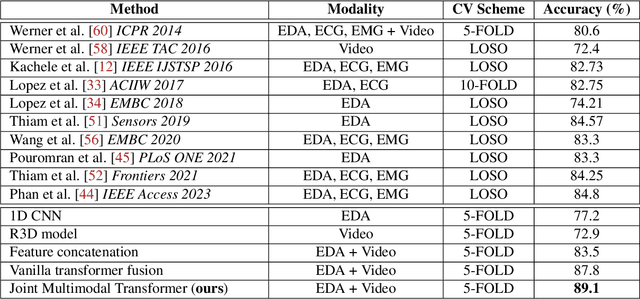
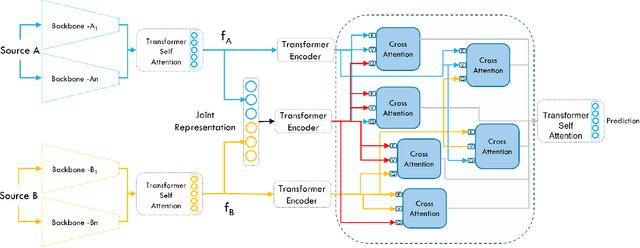
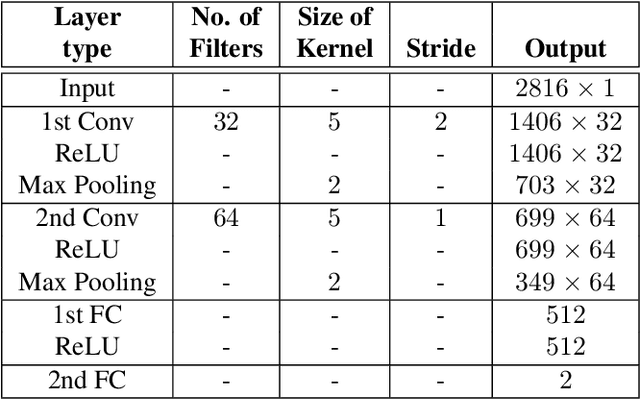
Audiovisual emotion recognition (ER) in videos has immense potential over unimodal performance. It effectively leverages the inter- and intra-modal dependencies between visual and auditory modalities. This work proposes a novel audio-visual emotion recognition system utilizing a joint multimodal transformer architecture with key-based cross-attention. This framework aims to exploit the complementary nature of audio and visual cues (facial expressions and vocal patterns) in videos, leading to superior performance compared to solely relying on a single modality. The proposed model leverages separate backbones for capturing intra-modal temporal dependencies within each modality (audio and visual). Subsequently, a joint multimodal transformer architecture integrates the individual modality embeddings, enabling the model to effectively capture inter-modal (between audio and visual) and intra-modal (within each modality) relationships. Extensive evaluations on the challenging Affwild2 dataset demonstrate that the proposed model significantly outperforms baseline and state-of-the-art methods in ER tasks.
Diffusion Facial Forgery Detection
Jan 29, 2024Detecting diffusion-generated images has recently grown into an emerging research area. Existing diffusion-based datasets predominantly focus on general image generation. However, facial forgeries, which pose a more severe social risk, have remained less explored thus far. To address this gap, this paper introduces DiFF, a comprehensive dataset dedicated to face-focused diffusion-generated images. DiFF comprises over 500,000 images that are synthesized using thirteen distinct generation methods under four conditions. In particular, this dataset leverages 30,000 carefully collected textual and visual prompts, ensuring the synthesis of images with both high fidelity and semantic consistency. We conduct extensive experiments on the DiFF dataset via a human test and several representative forgery detection methods. The results demonstrate that the binary detection accuracy of both human observers and automated detectors often falls below 30%, shedding light on the challenges in detecting diffusion-generated facial forgeries. Furthermore, we propose an edge graph regularization approach to effectively enhance the generalization capability of existing detectors.
E2F-Net: Eyes-to-Face Inpainting via StyleGAN Latent Space
Mar 18, 2024
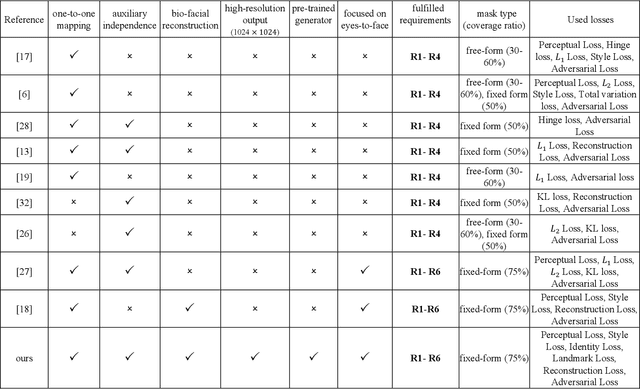

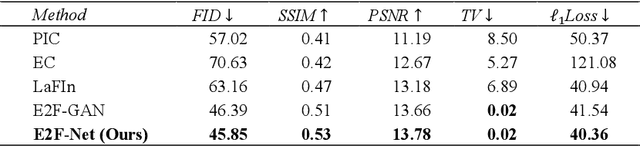
Face inpainting, the technique of restoring missing or damaged regions in facial images, is pivotal for applications like face recognition in occluded scenarios and image analysis with poor-quality captures. This process not only needs to produce realistic visuals but also preserve individual identity characteristics. The aim of this paper is to inpaint a face given periocular region (eyes-to-face) through a proposed new Generative Adversarial Network (GAN)-based model called Eyes-to-Face Network (E2F-Net). The proposed approach extracts identity and non-identity features from the periocular region using two dedicated encoders have been used. The extracted features are then mapped to the latent space of a pre-trained StyleGAN generator to benefit from its state-of-the-art performance and its rich, diverse and expressive latent space without any additional training. We further improve the StyleGAN output to find the optimal code in the latent space using a new optimization for GAN inversion technique. Our E2F-Net requires a minimum training process reducing the computational complexity as a secondary benefit. Through extensive experiments, we show that our method successfully reconstructs the whole face with high quality, surpassing current techniques, despite significantly less training and supervision efforts. We have generated seven eyes-to-face datasets based on well-known public face datasets for training and verifying our proposed methods. The code and datasets are publicly available.
DiffMAC: Diffusion Manifold Hallucination Correction for High Generalization Blind Face Restoration
Mar 15, 2024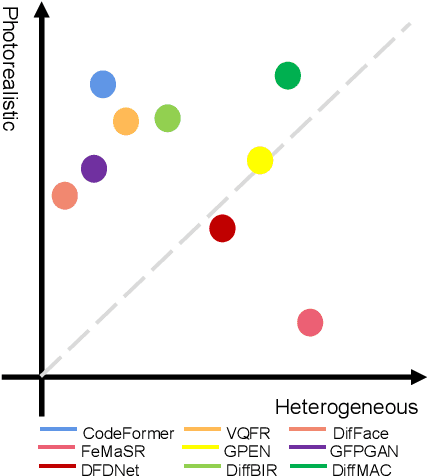
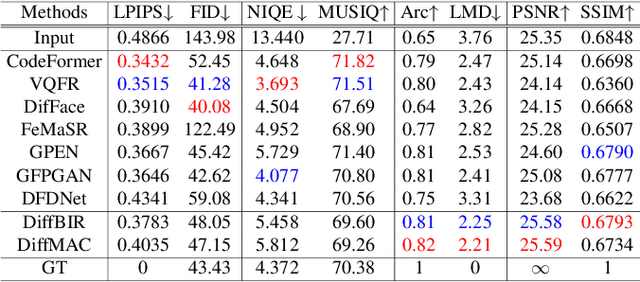
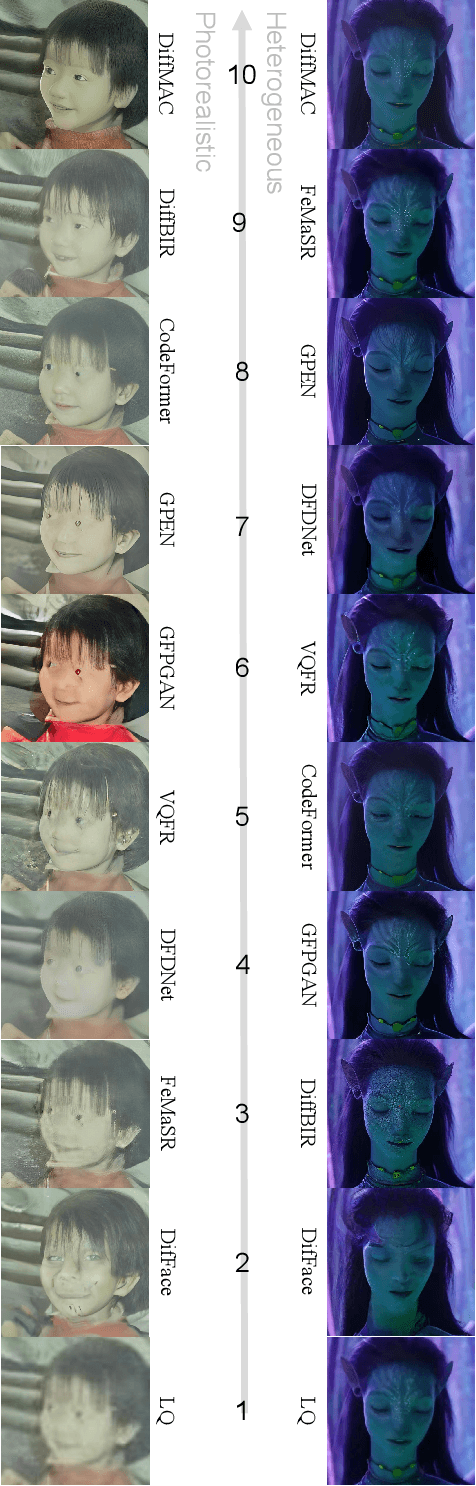
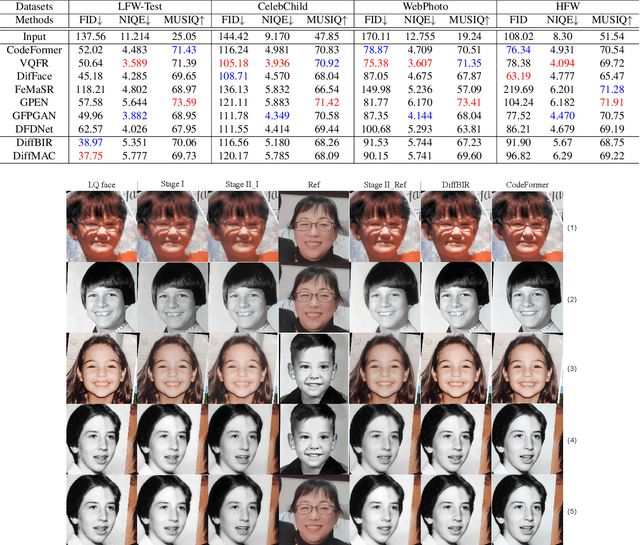
Blind face restoration (BFR) is a highly challenging problem due to the uncertainty of degradation patterns. Current methods have low generalization across photorealistic and heterogeneous domains. In this paper, we propose a Diffusion-Information-Diffusion (DID) framework to tackle diffusion manifold hallucination correction (DiffMAC), which achieves high-generalization face restoration in diverse degraded scenes and heterogeneous domains. Specifically, the first diffusion stage aligns the restored face with spatial feature embedding of the low-quality face based on AdaIN, which synthesizes degradation-removal results but with uncontrollable artifacts for some hard cases. Based on Stage I, Stage II considers information compression using manifold information bottleneck (MIB) and finetunes the first diffusion model to improve facial fidelity. DiffMAC effectively fights against blind degradation patterns and synthesizes high-quality faces with attribute and identity consistencies. Experimental results demonstrate the superiority of DiffMAC over state-of-the-art methods, with a high degree of generalization in real-world and heterogeneous settings. The source code and models will be public.
Creating an African American-Sounding TTS: Guidelines, Technical Challenges,and Surprising Evaluations
Mar 17, 2024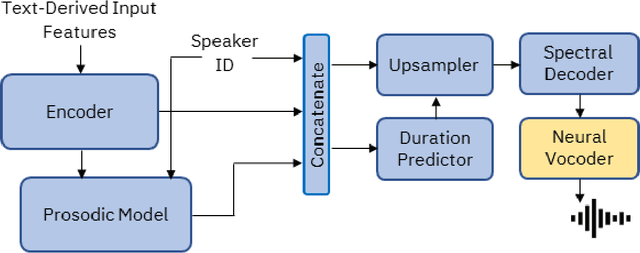

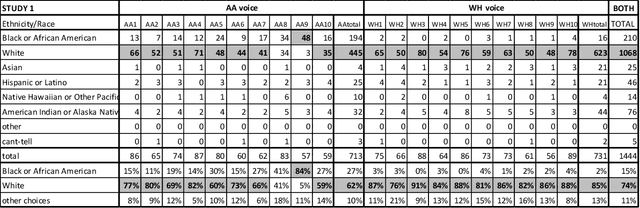
Representations of AI agents in user interfaces and robotics are predominantly White, not only in terms of facial and skin features, but also in the synthetic voices they use. In this paper we explore some unexpected challenges in the representation of race we found in the process of developing an U.S. English Text-to-Speech (TTS) system aimed to sound like an educated, professional, regional accent-free African American woman. The paper starts by presenting the results of focus groups with African American IT professionals where guidelines and challenges for the creation of a representative and appropriate TTS system were discussed and gathered, followed by a discussion about some of the technical difficulties faced by the TTS system developers. We then describe two studies with U.S. English speakers where the participants were not able to attribute the correct race to the African American TTS voice while overwhelmingly correctly recognizing the race of a White TTS system of similar quality. A focus group with African American IT workers not only confirmed the representativeness of the African American voice we built, but also suggested that the surprising recognition results may have been caused by the inability or the latent prejudice from non-African Americans to associate educated, non-vernacular, professionally-sounding voices to African American people.
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Feb 02, 2024While state-of-the-art facial expression recognition (FER) classifiers achieve a high level of accuracy, they lack interpretability, an important aspect for end-users. To recognize basic facial expressions, experts resort to a codebook associating a set of spatial action units to a facial expression. In this paper, we follow the same expert footsteps, and propose a learning strategy that allows us to explicitly incorporate spatial action units (aus) cues into the classifier's training to build a deep interpretable model. In particular, using this aus codebook, input image expression label, and facial landmarks, a single action units heatmap is built to indicate the most discriminative regions of interest in the image w.r.t the facial expression. We leverage this valuable spatial cue to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with \aus map. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with aus maps, simulating the experts' decision process. This is achieved using only the image class expression as supervision and without any extra manual annotations. Moreover, our method is generic. It can be applied to any CNN- or transformer-based deep classifier without the need for architectural change or adding significant training time. Our extensive evaluation on two public benchmarks RAFDB, and AFFECTNET datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on Class-Activation Mapping methods (CAMs), and we show that our training technique improves the CAM interpretability.
3D Face Reconstruction Using A Spectral-Based Graph Convolution Encoder
Mar 08, 2024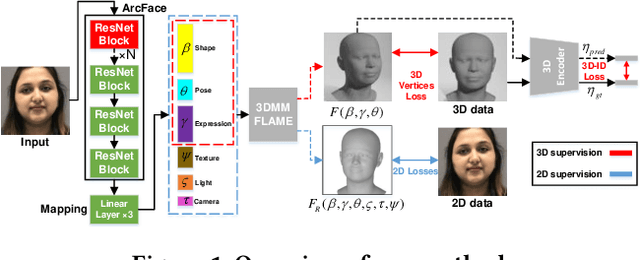
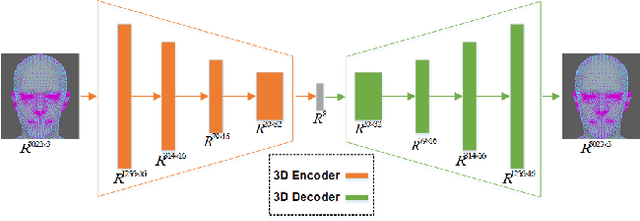
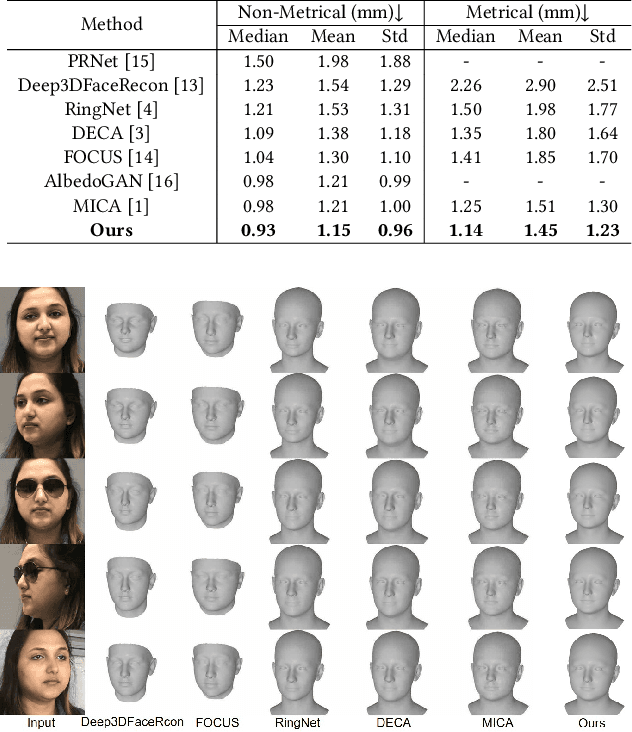
Monocular 3D face reconstruction plays a crucial role in avatar generation, with significant demand in web-related applications such as generating virtual financial advisors in FinTech. Current reconstruction methods predominantly rely on deep learning techniques and employ 2D self-supervision as a means to guide model learning. However, these methods encounter challenges in capturing the comprehensive 3D structural information of the face due to the utilization of 2D images for model training purposes. To overcome this limitation and enhance the reconstruction of 3D structural features, we propose an innovative approach that integrates existing 2D features with 3D features to guide the model learning process. Specifically, we introduce the 3D-ID Loss, which leverages the high-dimensional structure features extracted from a Spectral-Based Graph Convolution Encoder applied to the facial mesh. This approach surpasses the sole reliance on the 3D information provided by the facial mesh vertices coordinates. Our model is trained using 2D-3D data pairs from a combination of datasets and achieves state-of-the-art performance on the NoW benchmark.
Towards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024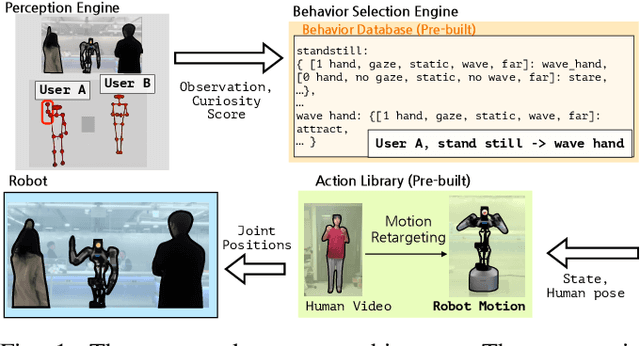
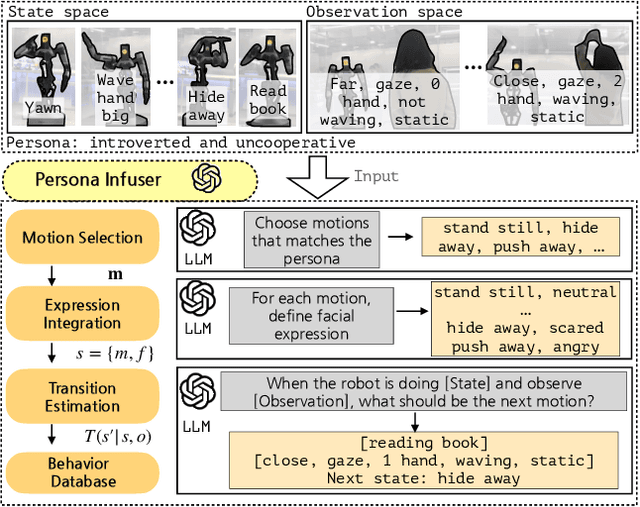
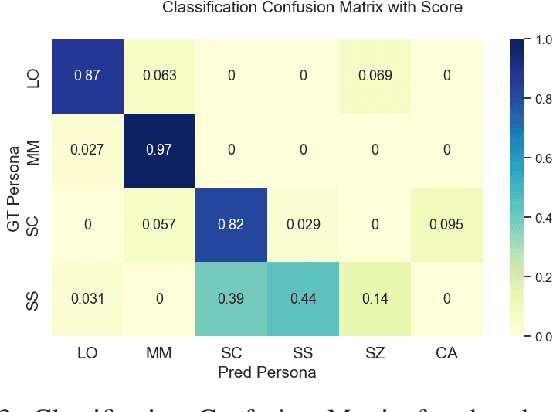

This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.
ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities
Mar 05, 2024

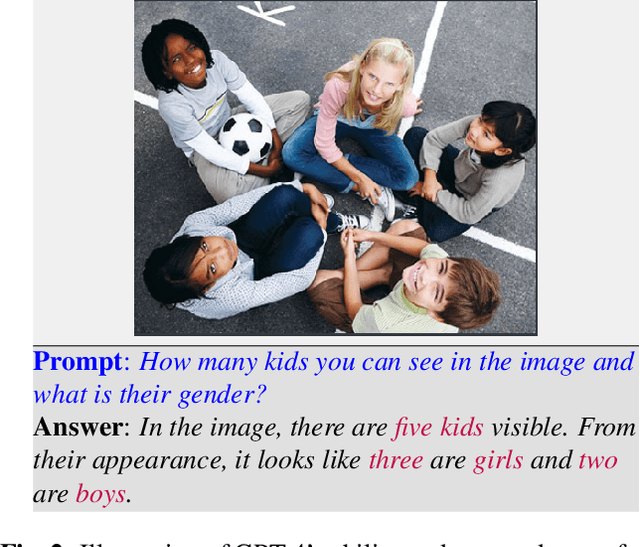

This paper explores the application of large language models (LLMs), like ChatGPT, for biometric tasks. We specifically examine the capabilities of ChatGPT in performing biometric-related tasks, with an emphasis on face recognition, gender detection, and age estimation. Since biometrics are considered as sensitive information, ChatGPT avoids answering direct prompts, and thus we crafted a prompting strategy to bypass its safeguard and evaluate the capabilities for biometrics tasks. Our study reveals that ChatGPT recognizes facial identities and differentiates between two facial images with considerable accuracy. Additionally, experimental results demonstrate remarkable performance in gender detection and reasonable accuracy for the age estimation tasks. Our findings shed light on the promising potentials in the application of LLMs and foundation models for biometrics.
OpticalDR: A Deep Optical Imaging Model for Privacy-Protective Depression Recognition
Feb 29, 2024Depression Recognition (DR) poses a considerable challenge, especially in the context of the growing concerns surrounding privacy. Traditional automatic diagnosis of DR technology necessitates the use of facial images, undoubtedly expose the patient identity features and poses privacy risks. In order to mitigate the potential risks associated with the inappropriate disclosure of patient facial images, we design a new imaging system to erase the identity information of captured facial images while retain disease-relevant features. It is irreversible for identity information recovery while preserving essential disease-related characteristics necessary for accurate DR. More specifically, we try to record a de-identified facial image (erasing the identifiable features as much as possible) by a learnable lens, which is optimized in conjunction with the following DR task as well as a range of face analysis related auxiliary tasks in an end-to-end manner. These aforementioned strategies form our final Optical deep Depression Recognition network (OpticalDR). Experiments on CelebA, AVEC 2013, and AVEC 2014 datasets demonstrate that our OpticalDR has achieved state-of-the-art privacy protection performance with an average AUC of 0.51 on popular facial recognition models, and competitive results for DR with MAE/RMSE of 7.53/8.48 on AVEC 2013 and 7.89/8.82 on AVEC 2014, respectively.