 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGO: Latent-space Exploration for Geometry-aware Optimization of Humanoid Kinematic Design
Apr 09, 2026Designing robot morphologies and kinematics has traditionally relied on human intuition, with little systematic foundation. Motion-design co-optimization offers a promising path toward automation, but two major challenges remain: (i) the vast, unstructured design space and (ii) the difficulty of constructing task-specific loss functions. We propose a new paradigm that minimizes human involvement by (i) learning the design search space from existing mechanical designs, rather than hand-crafting it, and (ii) defining the loss directly from human motion data via motion retargeting and Procrustes analysis. Using screw-theory-based joint axis representation and isometric manifold learning, we construct a compact, geometry-preserving latent space of humanoid upper body designs in which optimization is tractable. We then solve design optimization in this latent space using gradient-free optimization. Our approach establishes a principled framework for data-driven robot design and demonstrates that leveraging existing designs and human motion can effectively guide the automated discovery of novel robot design.
Learning Dexterous Grasping from Sparse Taxonomy Guidance
Apr 05, 2026Dexterous manipulation requires planning a grasp configuration suited to the object and task, which is then executed through coordinated multi-finger control. However, specifying grasp plans with dense pose or contact targets for every object and task is impractical. Meanwhile, end-to-end reinforcement learning from task rewards alone lacks controllability, making it difficult for users to intervene when failures occur. To this end, we present GRIT, a two-stage framework that learns dexterous control from sparse taxonomy guidance. GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Our result shows that certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9%. Moreover, real-world experiments demonstrate controllability, enabling grasp strategies to be adjusted through high-level taxonomy selection based on object geometry and task intent.
Token Bottleneck: One Token to Remember Dynamics
Jul 09, 2025Deriving compact and temporally aware visual representations from dynamic scenes is essential for successful execution of sequential scene understanding tasks such as visual tracking and robotic manipulation. In this paper, we introduce Token Bottleneck (ToBo), a simple yet intuitive self-supervised learning pipeline that squeezes a scene into a bottleneck token and predicts the subsequent scene using minimal patches as hints. The ToBo pipeline facilitates the learning of sequential scene representations by conservatively encoding the reference scene into a compact bottleneck token during the squeeze step. In the expansion step, we guide the model to capture temporal dynamics by predicting the target scene using the bottleneck token along with few target patches as hints. This design encourages the vision backbone to embed temporal dependencies, thereby enabling understanding of dynamic transitions across scenes. Extensive experiments in diverse sequential tasks, including video label propagation and robot manipulation in simulated environments demonstrate the superiority of ToBo over baselines. Moreover, deploying our pre-trained model on physical robots confirms its robustness and effectiveness in real-world environments. We further validate the scalability of ToBo across different model scales.
Versatile Motion Langauge Models for Multi-Turn Interactive Agents
Oct 08, 2024



Recent advancements in large language models (LLMs) have greatly enhanced their ability to generate natural and contextually relevant text, making AI interactions more human-like. However, generating and understanding interactive human-like motion, where two individuals engage in coordinated movements, remains a challenge due to the complexity of modeling these coordinated interactions. Furthermore, a versatile model is required to handle diverse interactive scenarios, such as chat systems that follow user instructions or adapt to their assigned role while adjusting interaction dynamics. To tackle this problem, we introduce VIM, short for the Versatile Interactive Motion language model, which integrates both language and motion modalities to effectively understand, generate, and control interactive motions in multi-turn conversational contexts. To address the scarcity of multi-turn interactive motion data, we introduce a synthetic dataset, INERT-MT2, where we utilize pre-trained models to create diverse instructional datasets with interactive motion. Our approach first trains a motion tokenizer that encodes interactive motions into residual discrete tokens. In the pretraining stage, the model learns to align motion and text representations with these discrete tokens. During the instruction fine-tuning stage, VIM adapts to multi-turn conversations using the INTER-MT2 dataset. We evaluate the versatility of our method across motion-related tasks, motion to text, text to motion, reaction generation, motion editing, and reasoning about motion sequences. The results highlight the versatility and effectiveness of proposed method in handling complex interactive motion synthesis.
Towards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024



This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.
SPOTS: Stable Placement of Objects with Reasoning in Semi-Autonomous Teleoperation Systems
Sep 25, 2023



Pick-and-place is one of the fundamental tasks in robotics research. However, the attention has been mostly focused on the ``pick'' task, leaving the ``place'' task relatively unexplored. In this paper, we address the problem of placing objects in the context of a teleoperation framework. Particularly, we focus on two aspects of the place task: stability robustness and contextual reasonableness of object placements. Our proposed method combines simulation-driven physical stability verification via real-to-sim and the semantic reasoning capability of large language models. In other words, given place context information (e.g., user preferences, object to place, and current scene information), our proposed method outputs a probability distribution over the possible placement candidates, considering the robustness and reasonableness of the place task. Our proposed method is extensively evaluated in two simulation and one real world environments and we show that our method can greatly increase the physical plausibility of the placement as well as contextual soundness while considering user preferences.
CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents
Jun 22, 2023



In this paper, we focus on inferring whether the given user command is clear, ambiguous, or infeasible in the context of interactive robotic agents utilizing large language models (LLMs). To tackle this problem, we first present an uncertainty estimation method for LLMs to classify whether the command is certain (i.e., clear) or not (i.e., ambiguous or infeasible). Once the command is classified as uncertain, we further distinguish it between ambiguous or infeasible commands leveraging LLMs with situational aware context in a zero-shot manner. For ambiguous commands, we disambiguate the command by interacting with users via question generation with LLMs. We believe that proper recognition of the given commands could lead to a decrease in malfunction and undesired actions of the robot, enhancing the reliability of interactive robot agents. We present a dataset for robotic situational awareness, consisting pair of high-level commands, scene descriptions, and labels of command type (i.e., clear, ambiguous, or infeasible). We validate the proposed method on the collected dataset, pick-and-place tabletop simulation. Finally, we demonstrate the proposed approach in real-world human-robot interaction experiments, i.e., handover scenarios.
Towards Text-based Human Search and Approach with an Intelligent Robot Dog
Feb 10, 2023



In this paper, we propose a SOCratic model for Robots Approaching humans based on TExt System (SOCRATES) focusing on the human search and approach based on free-form textual description; the robot first searches for the target user, then the robot proceeds to approach in a human-friendly manner. In particular, textual descriptions are composed of appearance (e.g., wearing white shirts with black hair) and location clues (e.g., is a student who works with robots). We initially present a Human Search Socratic Model that connects large pre-trained models in the language domain to solve the downstream task, which is searching for the target person based on textual descriptions. Then, we propose a hybrid learning-based framework for generating target-cordial robotic motion to approach a person, consisting of a learning-from-demonstration module and a knowledge distillation module. We validate the proposed searching module via simulation using a virtual mobile robot as well as through real-world experiments involving participants and the Boston Dynamics Spot robot. Furthermore, we analyze the properties of the proposed approaching framework with human participants based on the Robotic Social Attributes Scale (RoSAS)
Active Visual Search in the Wild
Sep 20, 2022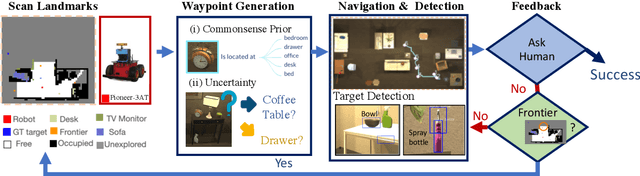
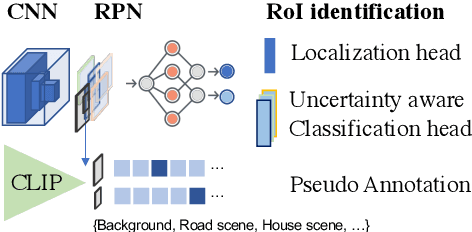

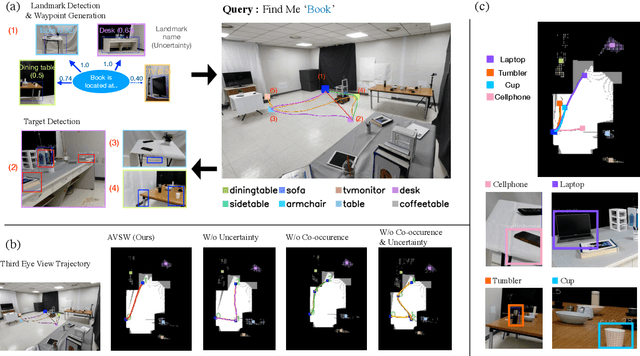
In this paper, we focus on the problem of efficiently locating a target object described with free-form language using a mobile robot equipped with vision sensors (e.g., an RGBD camera). Conventional active visual search predefines a set of objects to search for, rendering these techniques restrictive in practice. To provide added flexibility in active visual searching, we propose a system where a user can enter target commands using free-form language; we call this system Active Visual Search in the Wild (AVSW). AVSW detects and plans to search for a target object inputted by a user through a semantic grid map represented by static landmarks (e.g., desk or bed). For efficient planning of object search patterns, AVSW considers commonsense knowledge-based co-occurrence and predictive uncertainty while deciding which landmarks to visit first. We validate the proposed method with respect to SR (success rate) and SPL (success weighted by path length) in both simulated and real-world environments. The proposed method outperforms previous methods in terms of SPL in simulated scenarios with an average gap of 0.283. We further demonstrate AVSW with a Pioneer-3AT robot in real-world studies.
Elucidating Noisy Data via Uncertainty-Aware Robust Learning
Nov 02, 2021
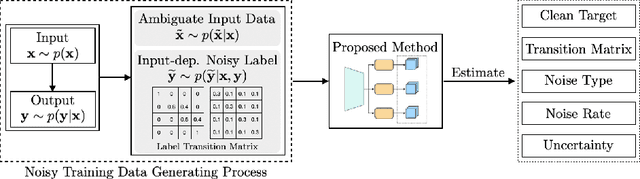
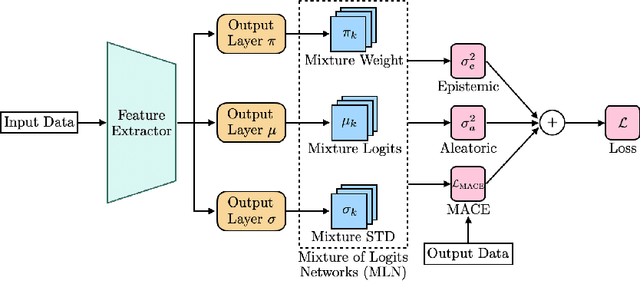
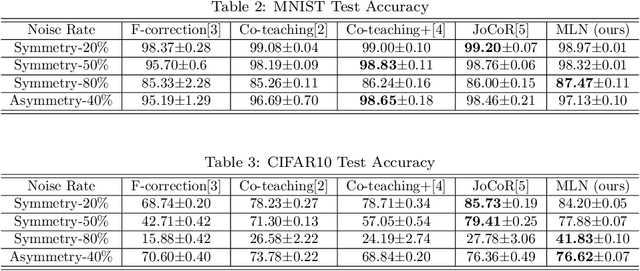
Robust learning methods aim to learn a clean target distribution from noisy and corrupted training data where a specific corruption pattern is often assumed a priori. Our proposed method can not only successfully learn the clean target distribution from a dirty dataset but also can estimate the underlying noise pattern. To this end, we leverage a mixture-of-experts model that can distinguish two different types of predictive uncertainty, aleatoric and epistemic uncertainty. We show that the ability to estimate the uncertainty plays a significant role in elucidating the corruption patterns as these two objectives are tightly intertwined. We also present a novel validation scheme for evaluating the performance of the corruption pattern estimation. Our proposed method is extensively assessed in terms of both robustness and corruption pattern estimation through a number of domains, including computer vision and natural language processing.