 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Mapping Road Lanes Using Laser Remission and Deep Neural Networks
Apr 27, 2018
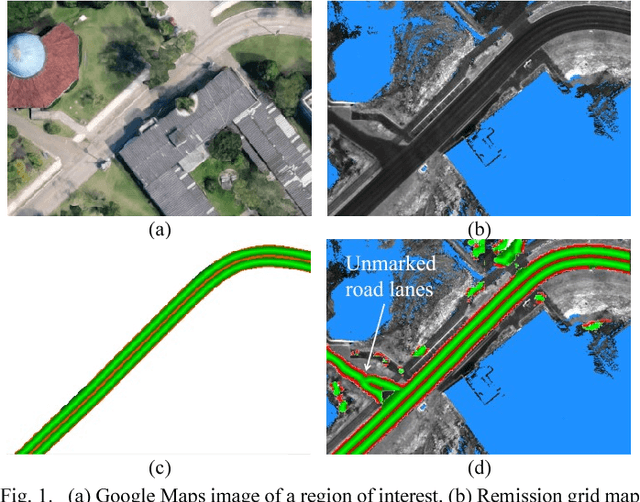

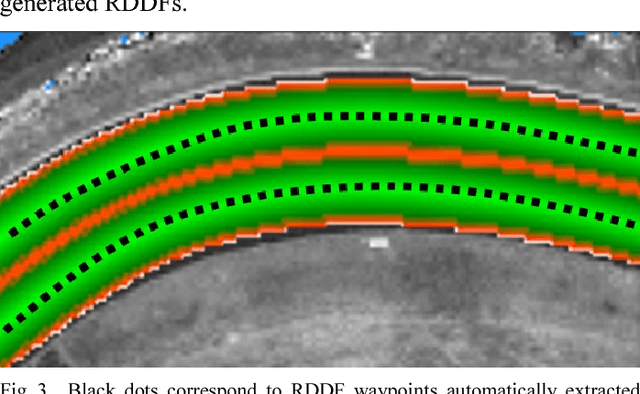

We propose the use of deep neural networks (DNN) for solving the problem of inferring the position and relevant properties of lanes of urban roads with poor or absent horizontal signalization, in order to allow the operation of autonomous cars in such situations. We take a segmentation approach to the problem and use the Efficient Neural Network (ENet) DNN for segmenting LiDAR remission grid maps into road maps. We represent road maps using what we called road grid maps. Road grid maps are square matrixes and each element of these matrixes represents a small square region of real-world space. The value of each element is a code associated with the semantics of the road map. Our road grid maps contain all information about the roads' lanes required for building the Road Definition Data Files (RDDFs) that are necessary for the operation of our autonomous car, IARA (Intelligent Autonomous Robotic Automobile). We have built a dataset of tens of kilometers of manually marked road lanes and used part of it to train ENet to segment road grid maps from remission grid maps. After being trained, ENet achieved an average segmentation accuracy of 83.7%. We have tested the use of inferred road grid maps in the real world using IARA on a stretch of 3.7 km of urban roads and it has shown performance equivalent to that of the previous IARA's subsystem that uses a manually generated RDDF.
Enhanced Attacks on Defensively Distilled Deep Neural Networks
Nov 16, 2017


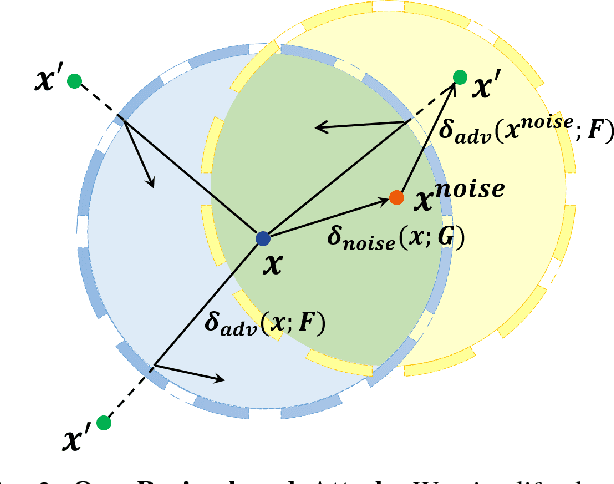
Deep neural networks (DNNs) have achieved tremendous success in many tasks of machine learning, such as the image classification. Unfortunately, researchers have shown that DNNs are easily attacked by adversarial examples, slightly perturbed images which can mislead DNNs to give incorrect classification results. Such attack has seriously hampered the deployment of DNN systems in areas where security or safety requirements are strict, such as autonomous cars, face recognition, malware detection. Defensive distillation is a mechanism aimed at training a robust DNN which significantly reduces the effectiveness of adversarial examples generation. However, the state-of-the-art attack can be successful on distilled networks with 100% probability. But it is a white-box attack which needs to know the inner information of DNN. Whereas, the black-box scenario is more general. In this paper, we first propose the epsilon-neighborhood attack, which can fool the defensively distilled networks with 100% success rate in the white-box setting, and it is fast to generate adversarial examples with good visual quality. On the basis of this attack, we further propose the region-based attack against defensively distilled DNNs in the black-box setting. And we also perform the bypass attack to indirectly break the distillation defense as a complementary method. The experimental results show that our black-box attacks have a considerable success rate on defensively distilled networks.
Classification of Time-Series Data Using Boosted Decision Trees
Oct 01, 2021
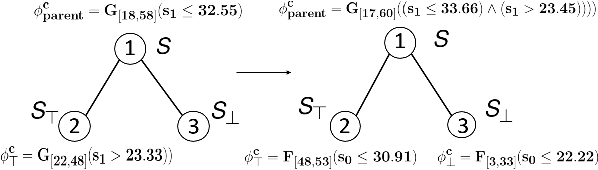
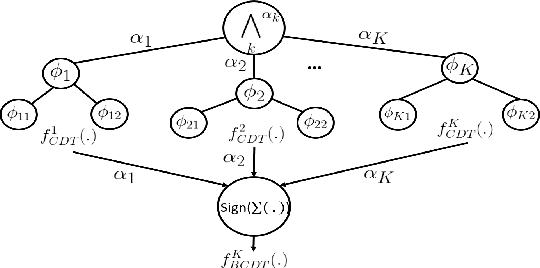
Time-series data classification is central to the analysis and control of autonomous systems, such as robots and self-driving cars. Temporal logic-based learning algorithms have been proposed recently as classifiers of such data. However, current frameworks are either inaccurate for real-world applications, such as autonomous driving, or they generate long and complicated formulae that lack interpretability. To address these limitations, we introduce a novel learning method, called Boosted Concise Decision Trees (BCDTs), to generate binary classifiers that are represented as Signal Temporal Logic (STL) formulae. Our algorithm leverages an ensemble of Concise Decision Trees (CDTs) to improve the classification performance, where each CDT is a decision tree that is empowered by a set of techniques to generate simpler formulae and improve interpretability. The effectiveness and classification performance of our algorithm are evaluated on naval surveillance and urban-driving case studies.
Neural Network Guided Evolutionary Fuzzing for Finding Traffic Violations of Autonomous Vehicles
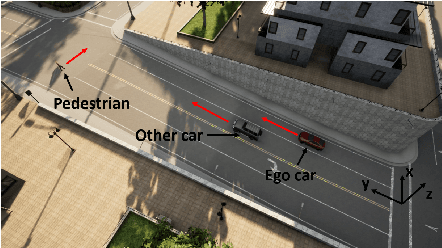
Sep 13, 2021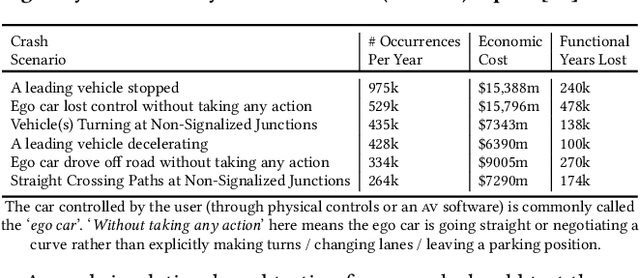
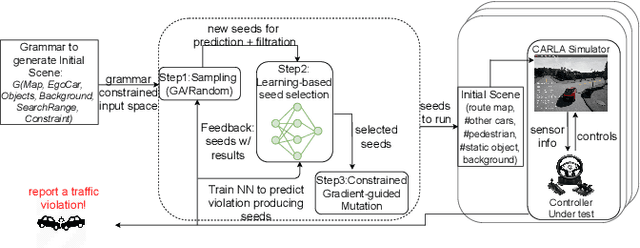
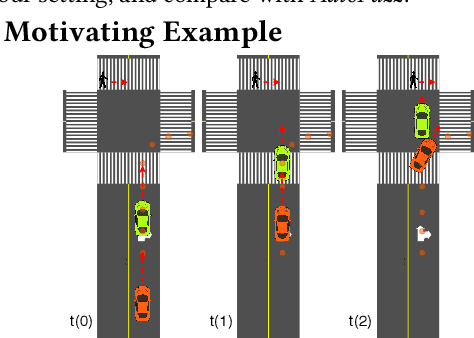

Self-driving cars and trucks, autonomous vehicles (AVs), should not be accepted by regulatory bodies and the public until they have much higher confidence in their safety and reliability -- which can most practically and convincingly be achieved by testing. But existing testing methods are inadequate for checking the end-to-end behaviors of AV controllers against complex, real-world corner cases involving interactions with multiple independent agents such as pedestrians and human-driven vehicles. While test-driving AVs on streets and highways fails to capture many rare events, existing simulation-based testing methods mainly focus on simple scenarios and do not scale well for complex driving situations that require sophisticated awareness of the surroundings. To address these limitations, we propose a new fuzz testing technique, called AutoFuzz, which can leverage widely-used AV simulators' API grammars. to generate semantically and temporally valid complex driving scenarios (sequences of scenes). AutoFuzz is guided by a constrained Neural Network (NN) evolutionary search over the API grammar to generate scenarios seeking to find unique traffic violations. Evaluation of our prototype on one state-of-the-art learning-based controller and two rule-based controllers shows that AutoFuzz efficiently finds hundreds of realistic traffic violations resembling real-world crashes. Further, fine-tuning the learning-based controller with the traffic violations found by AutoFuzz successfully reduced the traffic violations found in the new version of the AV controller software.
Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles
Sep 15, 2016
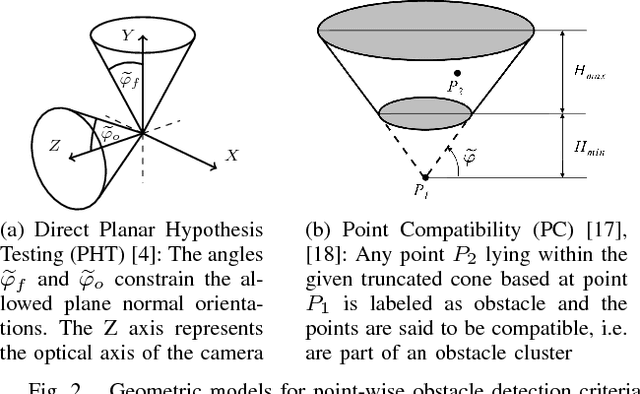

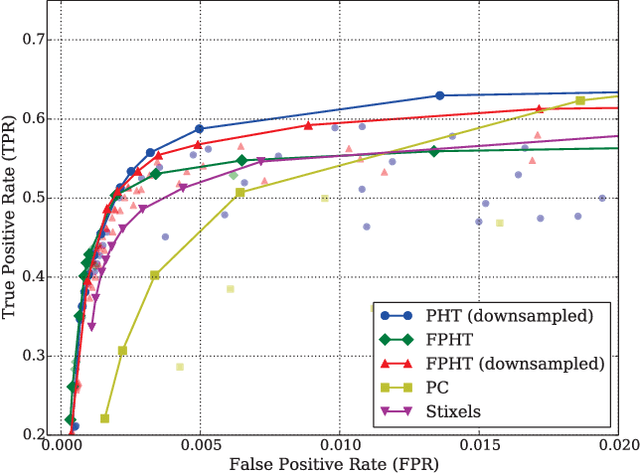
Detecting small obstacles on the road ahead is a critical part of the driving task which has to be mastered by fully autonomous cars. In this paper, we present a method based on stereo vision to reliably detect such obstacles from a moving vehicle. The proposed algorithm performs statistical hypothesis tests in disparity space directly on stereo image data, assessing freespace and obstacle hypotheses on independent local patches. This detection approach does not depend on a global road model and handles both static and moving obstacles. For evaluation, we employ a novel lost-cargo image sequence dataset comprising more than two thousand frames with pixelwise annotations of obstacle and free-space and provide a thorough comparison to several stereo-based baseline methods. The dataset will be made available to the community to foster further research on this important topic. The proposed approach outperforms all considered baselines in our evaluations on both pixel and object level and runs at frame rates of up to 20 Hz on 2 mega-pixel stereo imagery. Small obstacles down to the height of 5 cm can successfully be detected at 20 m distance at low false positive rates.
Localization Uncertainty Estimation for Anchor-Free Object Detection
Jun 28, 2020

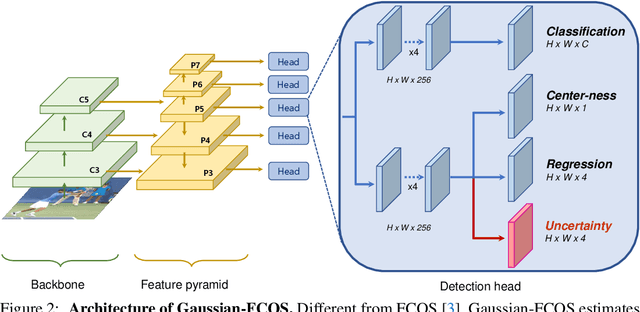
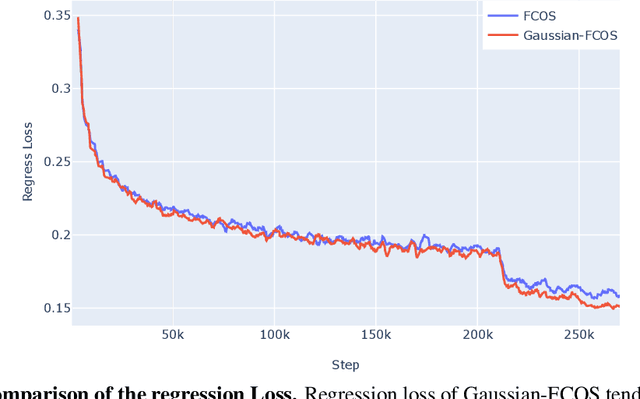
Since many safety-critical systems such as surgical robots and autonomous driving cars are in unstable environments with sensor noise or incomplete data, it is desirable for object detectors to take the confidence of the localization prediction into account. Recent attempts to estimate localization uncertainty for object detection focus only anchor-based method that captures the uncertainty of different characteristics such as location (center point) and scale (width, height). Also, anchor-based methods need to adjust sensitive anchor-box settings. Therefore, we propose a new object detector called Gaussian-FCOS that estimates the localization uncertainty based on an anchor-free detector that captures the uncertainty of similar property with four directions of box offsets (left, right, top, bottom) and avoids the anchor tuning. For this purpose, we design a new loss function, uncertainty loss, to measure how uncertain the estimated object location is by modeling the uncertainty as a Gaussian distribution. Then, the detection score is calibrated through the estimated uncertainty. Experiments on challenging COCO datasets demonstrate that the proposed new loss function not only enables the network to estimate the uncertainty but produces a synergy effect with regression loss. In addition, our Gaussian-FCOS reduces false positives with the estimated localization uncertainty and finds more missing-objects, boosting both Average Precision (AP) and Recall (AR). We hope Gaussian-FCOS serve as a baseline for the reliability-required task.
Gaussian Process-based Stochastic Model Predictive Control for Overtaking in Autonomous Racing
May 25, 2021
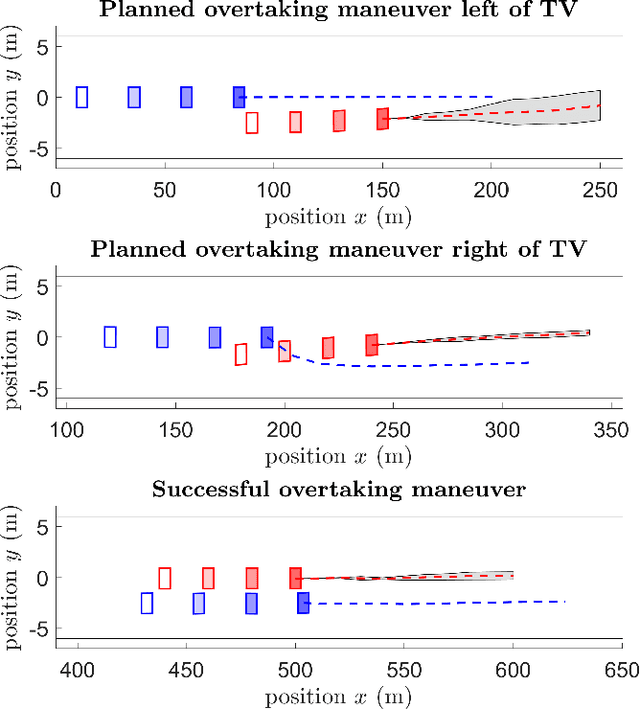
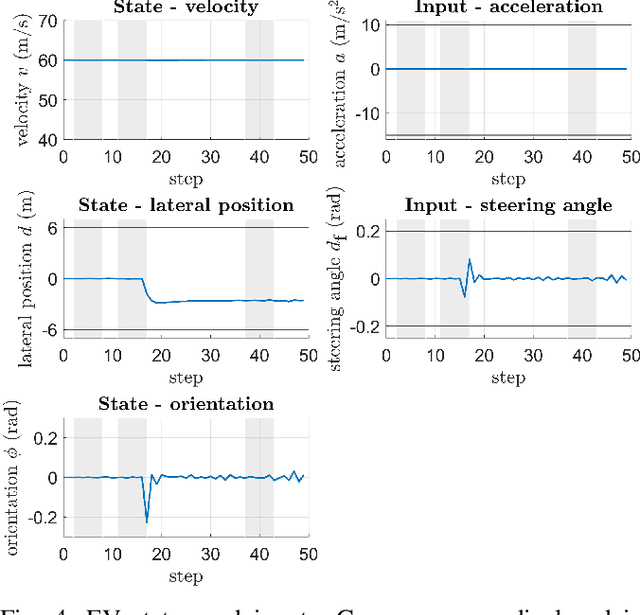
A fundamental aspect of racing is overtaking other race cars. Whereas previous research on autonomous racing has majorly focused on lap-time optimization, here, we propose a method to plan overtaking maneuvers in autonomous racing. A Gaussian process is used to learn the behavior of the leading vehicle. Based on the outputs of the Gaussian process, a stochastic Model Predictive Control algorithm plans optimistic trajectories, such that the controlled autonomous race car is able to overtake the leading vehicle. The proposed method is tested in a simple simulation scenario.
The Autonomous Racing Software Stack of the KIT19d
Oct 06, 2020
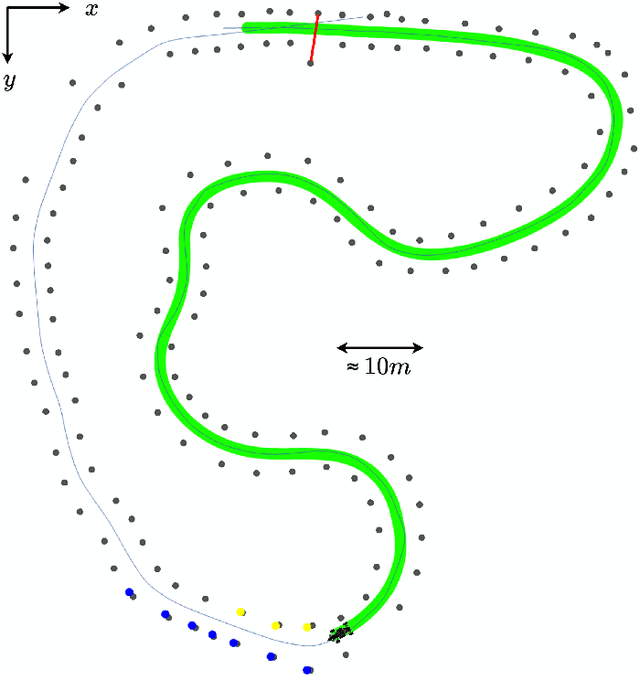
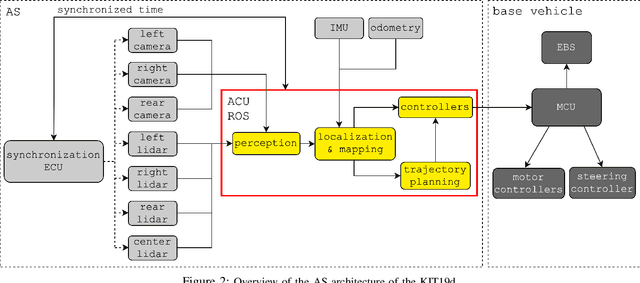
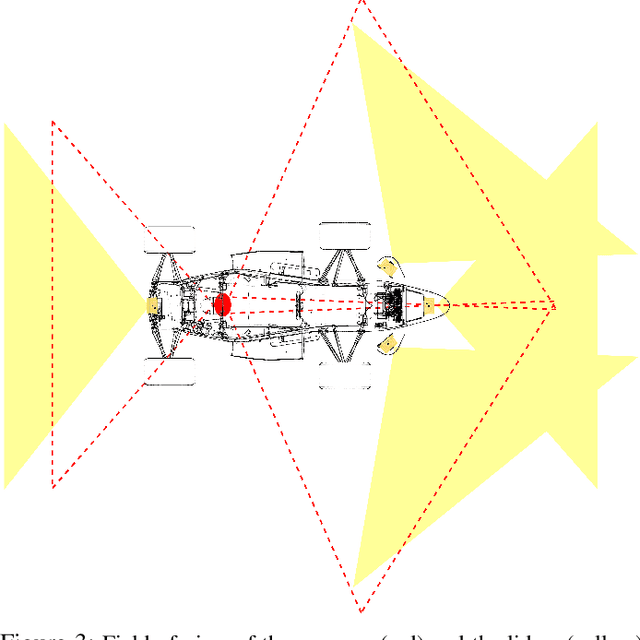
Formula Student Driverless challenges engineering students to develop autonomous single-seater race cars in a quest to bring about more graduates who are well-prepared to solve the real world problems associated with autonomous driving. In this paper, we present the software stack of KA-RaceIng's entry to the 2019 competitions. We cover the essential modules of the system, including perception, localization, mapping, motion planning, and control. Furthermore, development methods are outlined and an overview of the system architecture is given. We conclude by presenting selected runtime measurements, data logs, and competition results to provide an insight into the performance of the final prototype.
Deep Grid Net (DGN): A Deep Learning System for Real-Time Driving Context Understanding
Jan 16, 2019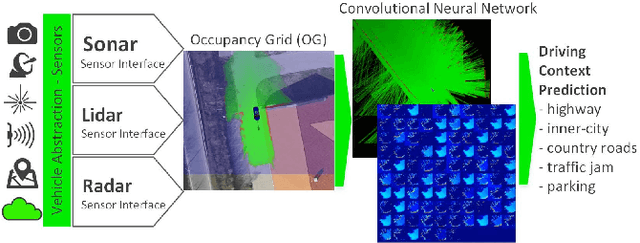

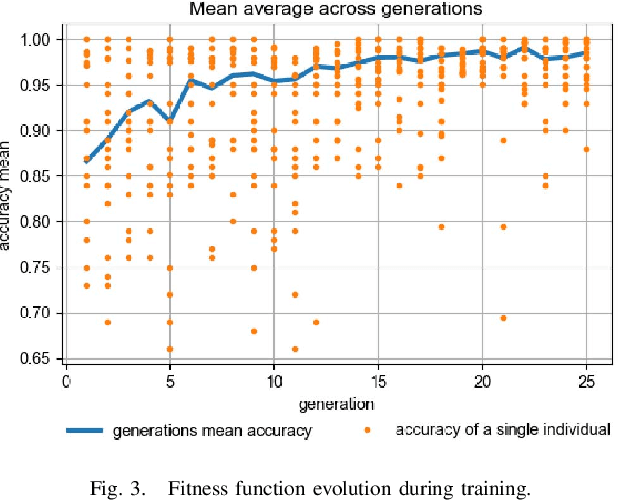
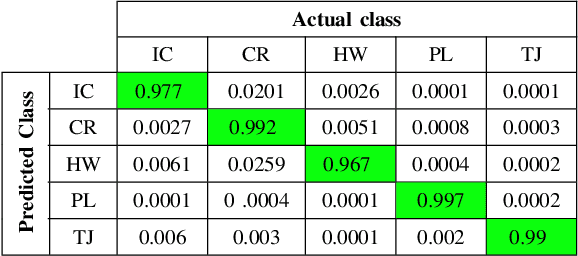
Grid maps obtained from fused sensory information are nowadays among the most popular approaches for motion planning for autonomous driving cars. In this paper, we introduce Deep Grid Net (DGN), a deep learning (DL) system designed for understanding the context in which an autonomous car is driving. DGN incorporates a learned driving environment representation based on Occupancy Grids (OG) obtained from raw Lidar data and constructed on top of the Dempster-Shafer (DS) theory. The predicted driving context is further used for switching between different driving strategies implemented within EB robinos, Elektrobit's Autonomous Driving (AD) software platform. Based on genetic algorithms (GAs), we also propose a neuroevolutionary approach for learning the tuning hyperparameters of DGN. The performance of the proposed deep network has been evaluated against similar competing driving context estimation classifiers.
Lane Attention: Predicting Vehicles' Moving Trajectories by Learning Their Attention over Lanes
Sep 29, 2019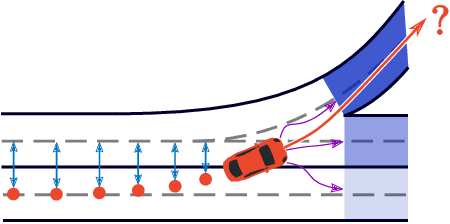
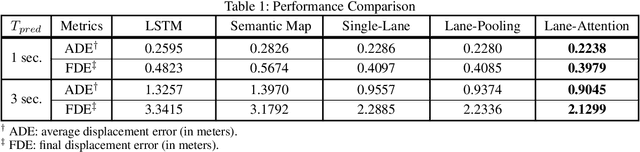
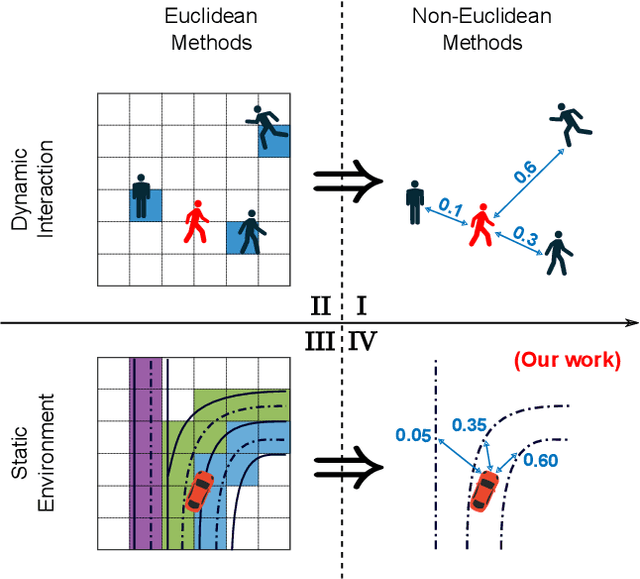
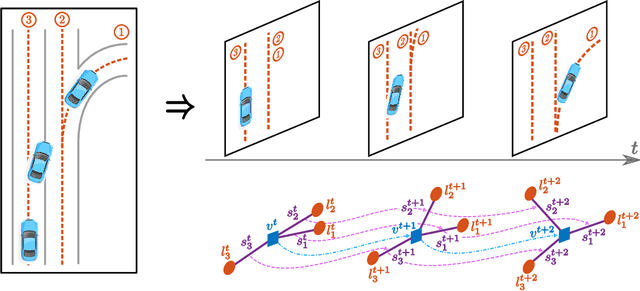
Accurately forecasting the future movements of surrounding vehicles is essential for safe and efficient operations of autonomous driving cars. This task is difficult because a vehicle's moving trajectory is greatly determined by its driver's intention, which is often hard to estimate. By leveraging attention mechanisms along with long short-term memory (LSTM) networks, this work learns the relation between a driver's intention and the vehicle's changing positions relative to road infrastructures, and uses it to guide the prediction. Different from other state-of-the-art solutions, our work treats the on-road lanes as non-Euclidean structures, unfolds the vehicle's moving history to form a spatio-temporal graph, and uses methods from Graph Neural Networks to solve the problem. Not only is our approach a pioneering attempt in using non-Euclidean methods to process static environmental features around a predicted object, our model also outperforms other state-of-the-art models in several metrics. The practicability and interpretability analysis of the model shows great potential for large-scale deployment in various autonomous driving systems in addition to our own.