 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Instructed Causal Routing of Vision Foundation Models for Multi-Task Learning
Jun 14, 2026Vision foundation models (VFMs) have demonstrated strong robustness and transferability across a wide range of visual tasks. However, each model typically encodes strong inductive biases shaped by its pre-training objective and data domain, resulting in fragmented yet complementary visual knowledge. As a result, a single model often struggles to capture the diverse visual representations required across multiple dense prediction tasks. To address this limitation, we propose TIGER (Task-Instruction-Guided Expert Routing), a framework that coordinates multiple heterogeneous VFMs for multi-task dense prediction. Instead of naively aggregating expert features, TIGER leverages natural-language task instructions to guide a routing network that assigns token-level expert weights conditioned on task semantics, enabling adaptive integration of complementary expert features. TIGER further introduces a counterfactual loss that aligns routing decisions with each expert's causal contribution by measuring prediction changes when experts are excluded, encouraging more reliable and interpretable routing. We evaluate TIGER on two multi-task dense prediction benchmarks, NYUD-v2 and Pascal Context, where it consistently outperforms recent multi-task learning baselines while keeping all VFMs frozen. These results demonstrate that combining instruction-guided expert routing with counterfactual causal alignment enables effective coordination of heterogeneous vision foundation models.
Task Prototype-Based Knowledge Retrieval for Multi-Task Learning from Partially Annotated Data
Jan 12, 2026Multi-task learning (MTL) is critical in real-world applications such as autonomous driving and robotics, enabling simultaneous handling of diverse tasks. However, obtaining fully annotated data for all tasks is impractical due to labeling costs. Existing methods for partially labeled MTL typically rely on predictions from unlabeled tasks, making it difficult to establish reliable task associations and potentially leading to negative transfer and suboptimal performance. To address these issues, we propose a prototype-based knowledge retrieval framework that achieves robust MTL instead of relying on predictions from unlabeled tasks. Our framework consists of two key components: (1) a task prototype embedding task-specific characteristics and quantifying task associations, and (2) a knowledge retrieval transformer that adaptively refines feature representations based on these associations. To achieve this, we introduce an association knowledge generating (AKG) loss to ensure the task prototype consistently captures task-specific characteristics. Extensive experiments demonstrate the effectiveness of our framework, highlighting its potential for robust multi-task learning, even when only a subset of tasks is annotated.
MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection
Jul 23, 2024



Monocular 3D object detection is an important challenging task in autonomous driving. Existing methods mainly focus on performing 3D detection in ideal weather conditions, characterized by scenarios with clear and optimal visibility. However, the challenge of autonomous driving requires the ability to handle changes in weather conditions, such as foggy weather, not just clear weather. We introduce MonoWAD, a novel weather-robust monocular 3D object detector with a weather-adaptive diffusion model. It contains two components: (1) the weather codebook to memorize the knowledge of the clear weather and generate a weather-reference feature for any input, and (2) the weather-adaptive diffusion model to enhance the feature representation of the input feature by incorporating a weather-reference feature. This serves an attention role in indicating how much improvement is needed for the input feature according to the weather conditions. To achieve this goal, we introduce a weather-adaptive enhancement loss to enhance the feature representation under both clear and foggy weather conditions. Extensive experiments under various weather conditions demonstrate that MonoWAD achieves weather-robust monocular 3D object detection. The code and dataset are released at https://github.com/VisualAIKHU/MonoWAD.
Customizing Segmentation Foundation Model via Prompt Learning for Instance Segmentation
Mar 14, 2024



Recently, foundation models trained on massive datasets to adapt to a wide range of domains have attracted considerable attention and are actively being explored within the computer vision community. Among these, the Segment Anything Model (SAM) stands out for its remarkable progress in generalizability and flexibility for image segmentation tasks, achieved through prompt-based object mask generation. However, despite its strength, SAM faces two key limitations when applied to customized instance segmentation that segments specific objects or those in unique environments not typically present in the training data: 1) the ambiguity inherent in input prompts and 2) the necessity for extensive additional training to achieve optimal segmentation. To address these challenges, we propose a novel method, customized instance segmentation via prompt learning tailored to SAM. Our method involves a prompt learning module (PLM), which adjusts input prompts into the embedding space to better align with user intentions, thereby enabling more efficient training. Furthermore, we introduce a point matching module (PMM) to enhance the feature representation for finer segmentation by ensuring detailed alignment with ground truth boundaries. Experimental results on various customized instance segmentation scenarios demonstrate the effectiveness of the proposed method.
Prompt Tuning of Deep Neural Networks for Speaker-adaptive Visual Speech Recognition
Feb 16, 2023Visual Speech Recognition (VSR) aims to infer speech into text depending on lip movements alone. As it focuses on visual information to model the speech, its performance is inherently sensitive to personal lip appearances and movements, and this makes the VSR models show degraded performance when they are applied to unseen speakers. In this paper, to remedy the performance degradation of the VSR model on unseen speakers, we propose prompt tuning methods of Deep Neural Networks (DNNs) for speaker-adaptive VSR. Specifically, motivated by recent advances in Natural Language Processing (NLP), we finetune prompts on adaptation data of target speakers instead of modifying the pre-trained model parameters. Different from the previous prompt tuning methods mainly limited to Transformer variant architecture, we explore different types of prompts, the addition, the padding, and the concatenation form prompts that can be applied to the VSR model which is composed of CNN and Transformer in general. With the proposed prompt tuning, we show that the performance of the pre-trained VSR model on unseen speakers can be largely improved by using a small amount of adaptation data (e.g., less than 5 minutes), even if the pre-trained model is already developed with large speaker variations. Moreover, by analyzing the performance and parameters of different types of prompts, we investigate when the prompt tuning is preferred over the finetuning methods. The effectiveness of the proposed method is evaluated on both word- and sentence-level VSR databases, LRW-ID and GRID.
HAZE-Net: High-Frequency Attentive Super-Resolved Gaze Estimation in Low-Resolution Face Images
Sep 21, 2022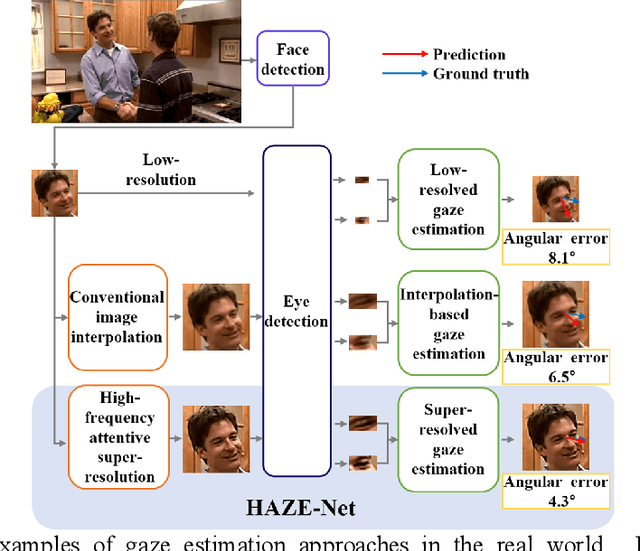

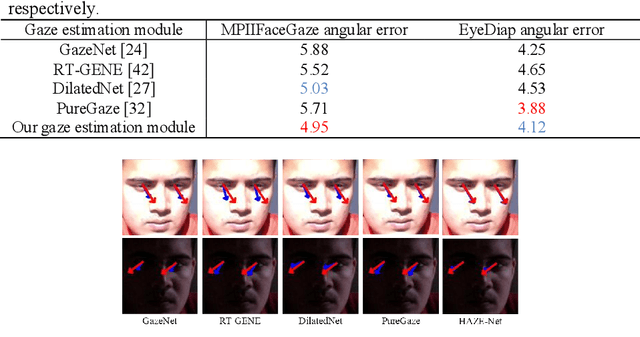
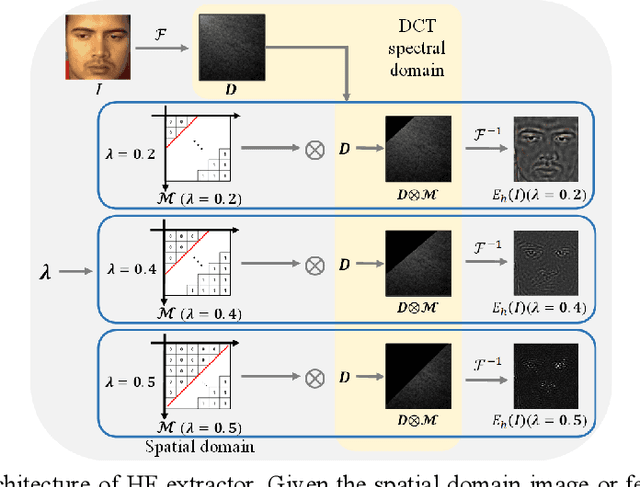
Although gaze estimation methods have been developed with deep learning techniques, there has been no such approach as aim to attain accurate performance in low-resolution face images with a pixel width of 50 pixels or less. To solve a limitation under the challenging low-resolution conditions, we propose a high-frequency attentive super-resolved gaze estimation network, i.e., HAZE-Net. Our network improves the resolution of the input image and enhances the eye features and those boundaries via a proposed super-resolution module based on a high-frequency attention block. In addition, our gaze estimation module utilizes high-frequency components of the eye as well as the global appearance map. We also utilize the structural location information of faces to approximate head pose. The experimental results indicate that the proposed method exhibits robust gaze estimation performance even in low-resolution face images with 28x28 pixels. The source code of this work is available at https://github.com/dbseorms16/HAZE_Net/.
Face Shape-Guided Deep Feature Alignment for Face Recognition Robust to Face Misalignment
Sep 15, 2022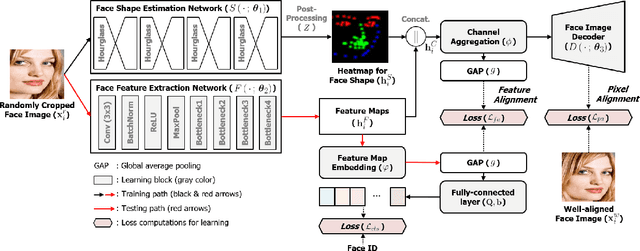
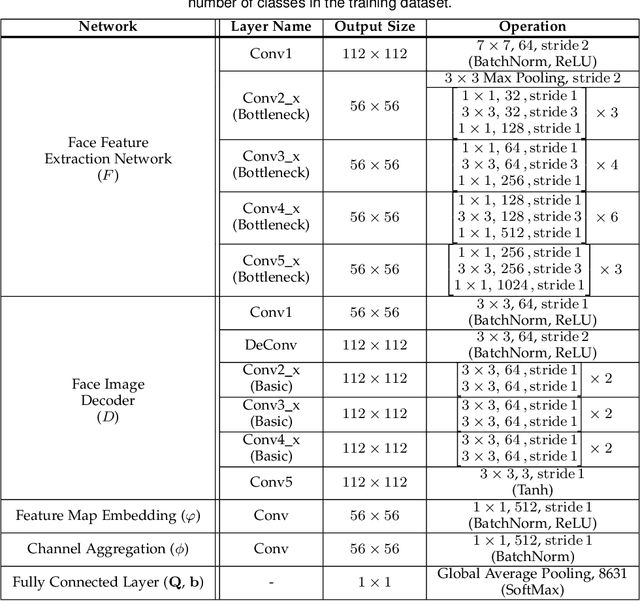
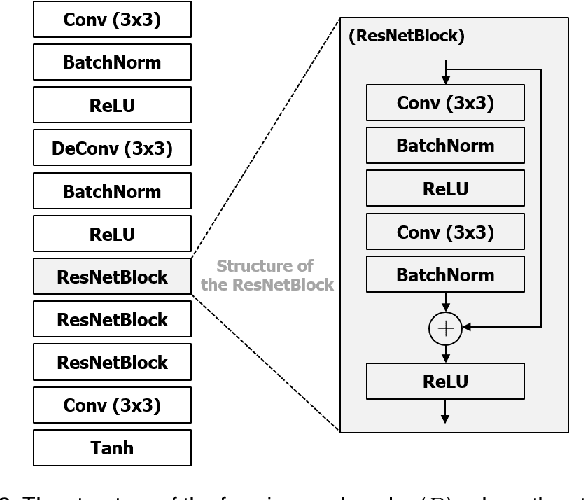
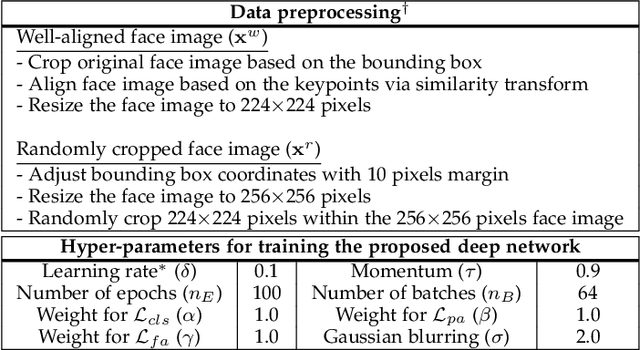
For the past decades, face recognition (FR) has been actively studied in computer vision and pattern recognition society. Recently, due to the advances in deep learning, the FR technology shows high performance for most of the benchmark datasets. However, when the FR algorithm is applied to a real-world scenario, the performance has been known to be still unsatisfactory. This is mainly attributed to the mismatch between training and testing sets. Among such mismatches, face misalignment between training and testing faces is one of the factors that hinder successful FR. To address this limitation, we propose a face shape-guided deep feature alignment framework for FR robust to the face misalignment. Based on a face shape prior (e.g., face keypoints), we train the proposed deep network by introducing alignment processes, i.e., pixel and feature alignments, between well-aligned and misaligned face images. Through the pixel alignment process that decodes the aggregated feature extracted from a face image and face shape prior, we add the auxiliary task to reconstruct the well-aligned face image. Since the aggregated features are linked to the face feature extraction network as a guide via the feature alignment process, we train the robust face feature to the face misalignment. Even if the face shape estimation is required in the training stage, the additional face alignment process, which is usually incorporated in the conventional FR pipeline, is not necessarily needed in the testing phase. Through the comparative experiments, we validate the effectiveness of the proposed method for the face misalignment with the FR datasets.
Entropy-Aware Model Initialization for Effective Exploration in Deep Reinforcement Learning
Aug 24, 2021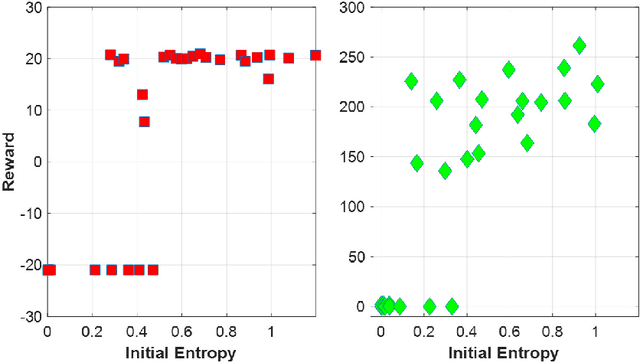
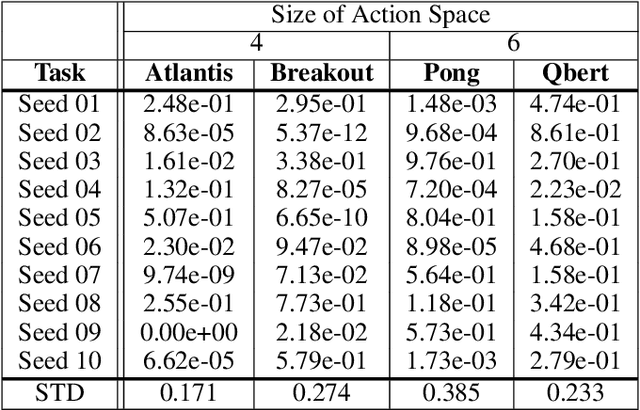
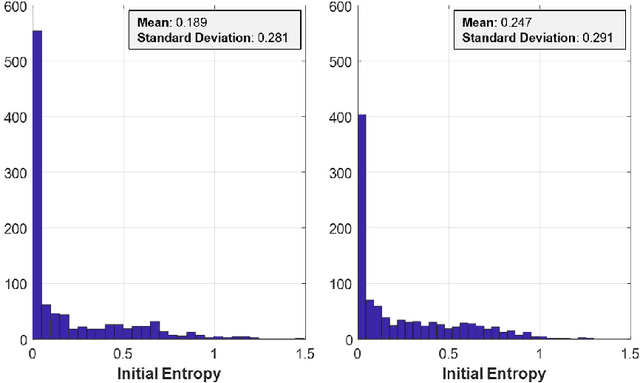
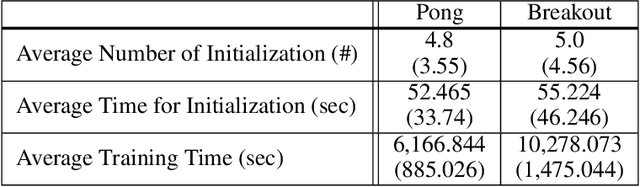
Encouraging exploration is a critical issue in deep reinforcement learning. We investigate the effect of initial entropy that significantly influences the exploration, especially at the earlier stage. Our main observations are as follows: 1) low initial entropy increases the probability of learning failure, and 2) this initial entropy is biased towards a low value that inhibits exploration. Inspired by the investigations, we devise entropy-aware model initialization, a simple yet powerful learning strategy for effective exploration. We show that the devised learning strategy significantly reduces learning failures and enhances performance, stability, and learning speed through experiments.
Video Prediction Recalling Long-term Motion Context via Memory Alignment Learning
Apr 02, 2021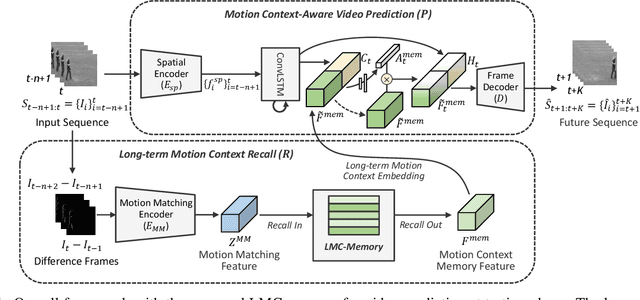
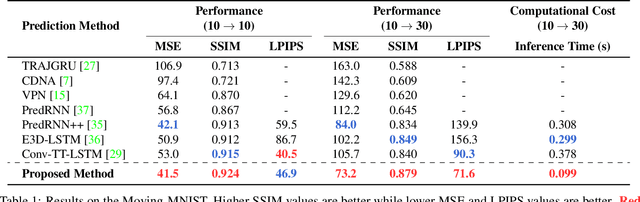
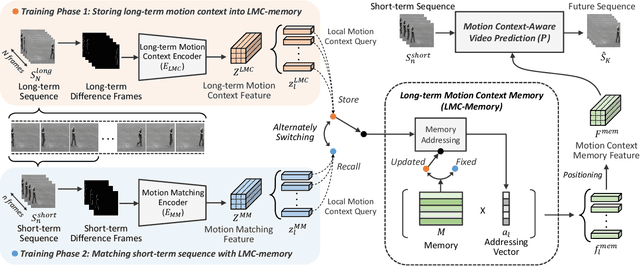
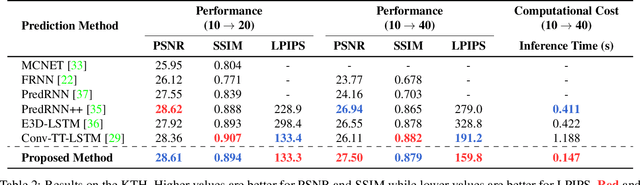
Our work addresses long-term motion context issues for predicting future frames. To predict the future precisely, it is required to capture which long-term motion context (e.g., walking or running) the input motion (e.g., leg movement) belongs to. The bottlenecks arising when dealing with the long-term motion context are: (i) how to predict the long-term motion context naturally matching input sequences with limited dynamics, (ii) how to predict the long-term motion context with high-dimensionality (e.g., complex motion). To address the issues, we propose novel motion context-aware video prediction. To solve the bottleneck (i), we introduce a long-term motion context memory (LMC-Memory) with memory alignment learning. The proposed memory alignment learning enables to store long-term motion contexts into the memory and to match them with sequences including limited dynamics. As a result, the long-term context can be recalled from the limited input sequence. In addition, to resolve the bottleneck (ii), we propose memory query decomposition to store local motion context (i.e., low-dimensional dynamics) and recall the suitable local context for each local part of the input individually. It enables to boost the alignment effects of the memory. Experimental results show that the proposed method outperforms other sophisticated RNN-based methods, especially in long-term condition. Further, we validate the effectiveness of the proposed network designs by conducting ablation studies and memory feature analysis. The source code of this work is available.
Diverse Temporal Aggregation and Depthwise Spatiotemporal Factorization for Efficient Video Classification
Dec 28, 2020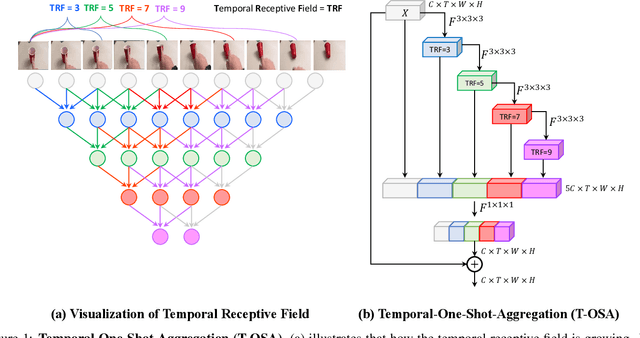

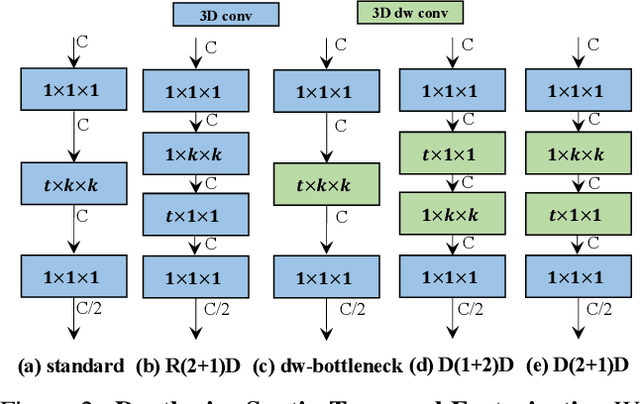

Video classification researches that have recently attracted attention are the fields of temporal modeling and 3D efficient architecture. However, the temporal modeling methods are not efficient or the 3D efficient architecture is less interested in temporal modeling. For bridging the gap between them, we propose an efficient temporal modeling 3D architecture, called VoV3D, that consists of a temporal one-shot aggregation (T-OSA) module and depthwise factorized component, D(2+1)D. The T-OSA is devised to build a feature hierarchy by aggregating temporal features with different temporal receptive fields. Stacking this T-OSA enables the network itself to model short-range as well as long-range temporal relationships across frames without any external modules. Inspired by kernel factorization and channel factorization, we also design a depthwise spatiotemporal factorization module, named, D(2+1)D that decomposes a 3D depthwise convolution into two spatial and temporal depthwise convolutions for making our network more lightweight and efficient. By using the proposed temporal modeling method (T-OSA), and the efficient factorized component (D(2+1)D), we construct two types of VoV3D networks, VoV3D-M and VoV3D-L. Thanks to its efficiency and effectiveness of temporal modeling, VoV3D-L has 6x fewer model parameters and 16x less computation, surpassing a state-of-the-art temporal modeling method on both Something-Something and Kinetics-400. Furthermore, VoV3D shows better temporal modeling ability than a state-of-the-art efficient 3D architecture, X3D having comparable model capacity. We hope that VoV3D can serve as a baseline for efficient video classification.