 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Voices to Validity: Leveraging Large Language Models (LLMs) for Textual Analysis of Policy Stakeholder Interviews
Dec 02, 2023
Obtaining stakeholders' diverse experiences and opinions about current policy in a timely manner is crucial for policymakers to identify strengths and gaps in resource allocation, thereby supporting effective policy design and implementation. However, manually coding even moderately sized interview texts or open-ended survey responses from stakeholders can often be labor-intensive and time-consuming. This study explores the integration of Large Language Models (LLMs)--like GPT-4--with human expertise to enhance text analysis of stakeholder interviews regarding K-12 education policy within one U.S. state. Employing a mixed-methods approach, human experts developed a codebook and coding processes as informed by domain knowledge and unsupervised topic modeling results. They then designed prompts to guide GPT-4 analysis and iteratively evaluate different prompts' performances. This combined human-computer method enabled nuanced thematic and sentiment analysis. Results reveal that while GPT-4 thematic coding aligned with human coding by 77.89% at specific themes, expanding to broader themes increased congruence to 96.02%, surpassing traditional Natural Language Processing (NLP) methods by over 25%. Additionally, GPT-4 is more closely matched to expert sentiment analysis than lexicon-based methods. Findings from quantitative measures and qualitative reviews underscore the complementary roles of human domain expertise and automated analysis as LLMs offer new perspectives and coding consistency. The human-computer interactive approach enhances efficiency, validity, and interpretability of educational policy research.
Meta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Dec 02, 2023Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Dec 02, 2023
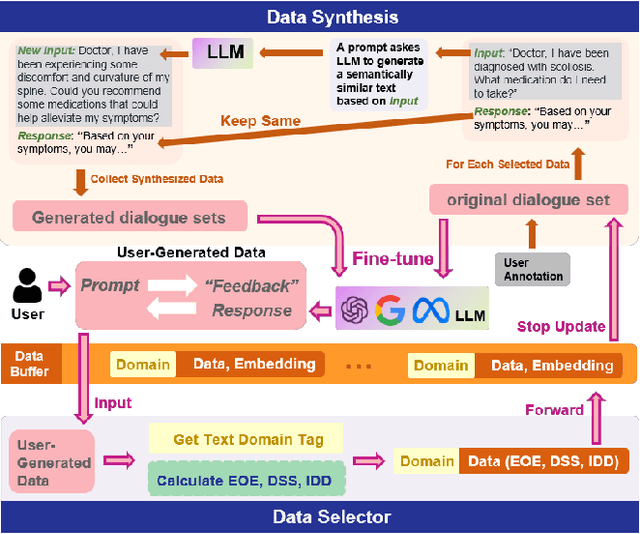
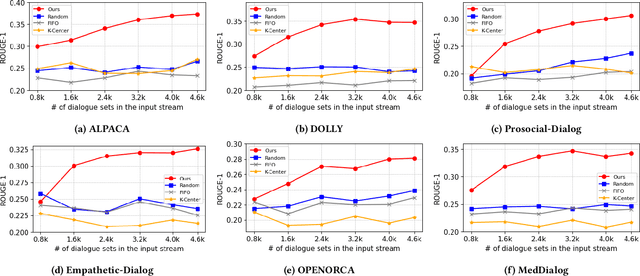
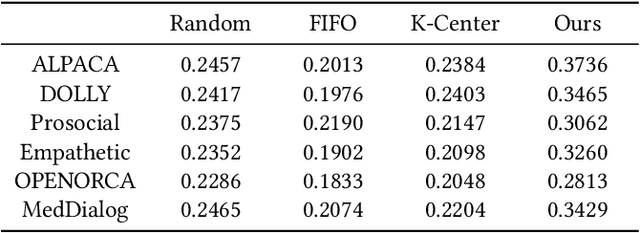
After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.
SEINE: SEgment-based Indexing for NEural information retrieval
Nov 27, 2023Many early neural Information Retrieval (NeurIR) methods are re-rankers that rely on a traditional first-stage retriever due to expensive query time computations. Recently, representation-based retrievers have gained much attention, which learns query representation and document representation separately, making it possible to pre-compute document representations offline and reduce the workload at query time. Both dense and sparse representation-based retrievers have been explored. However, these methods focus on finding the representation that best represents a text (aka metric learning) and the actual retrieval function that is responsible for similarity matching between query and document is kept at a minimum by using dot product. One drawback is that unlike traditional term-level inverted index, the index formed by these embeddings cannot be easily re-used by another retrieval method. Another drawback is that keeping the interaction at minimum hurts retrieval effectiveness. On the contrary, interaction-based retrievers are known for their better retrieval effectiveness. In this paper, we propose a novel SEgment-based Neural Indexing method, SEINE, which provides a general indexing framework that can flexibly support a variety of interaction-based neural retrieval methods. We emphasize on a careful decomposition of common components in existing neural retrieval methods and propose to use segment-level inverted index to store the atomic query-document interaction values. Experiments on LETOR MQ2007 and MQ2008 datasets show that our indexing method can accelerate multiple neural retrieval methods up to 28-times faster without sacrificing much effectiveness.
TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models
Dec 01, 2023Diffusion models have gained prominence in generating data for perception tasks such as image classification and object detection. However, the potential in generating high-quality tracking sequences, a crucial aspect in the field of video perception, has not been fully investigated. To address this gap, we propose TrackDiffusion, a novel architecture designed to generate continuous video sequences from the tracklets. TrackDiffusion represents a significant departure from the traditional layout-to-image (L2I) generation and copy-paste synthesis focusing on static image elements like bounding boxes by empowering image diffusion models to encompass dynamic and continuous tracking trajectories, thereby capturing complex motion nuances and ensuring instance consistency among video frames. For the first time, we demonstrate that the generated video sequences can be utilized for training multi-object tracking (MOT) systems, leading to significant improvement in tracker performance. Experimental results show that our model significantly enhances instance consistency in generated video sequences, leading to improved perceptual metrics. Our approach achieves an improvement of 8.7 in TrackAP and 11.8 in TrackAP$_{50}$ on the YTVIS dataset, underscoring its potential to redefine the standards of video data generation for MOT tasks and beyond.
Gaussian Grouping: Segment and Edit Anything in 3D Scenes
Dec 01, 2023The recent Gaussian Splatting achieves high-quality and real-time novel-view synthesis of the 3D scenes. However, it is solely concentrated on the appearance and geometry modeling, while lacking in fine-grained object-level scene understanding. To address this issue, we propose Gaussian Grouping, which extends Gaussian Splatting to jointly reconstruct and segment anything in open-world 3D scenes. We augment each Gaussian with a compact Identity Encoding, allowing the Gaussians to be grouped according to their object instance or stuff membership in the 3D scene. Instead of resorting to expensive 3D labels, we supervise the Identity Encodings during the differentiable rendering by leveraging the 2D mask predictions by SAM, along with introduced 3D spatial consistency regularization. Comparing to the implicit NeRF representation, we show that the discrete and grouped 3D Gaussians can reconstruct, segment and edit anything in 3D with high visual quality, fine granularity and efficiency. Based on Gaussian Grouping, we further propose a local Gaussian Editing scheme, which shows efficacy in versatile scene editing applications, including 3D object removal, inpainting, colorization and scene recomposition. Our code and models will be at https://github.com/lkeab/gaussian-grouping.
A Recent Survey of Vision Transformers for Medical Image Segmentation
Dec 01, 2023
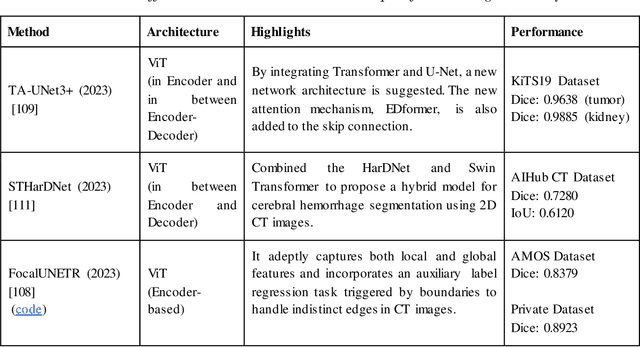

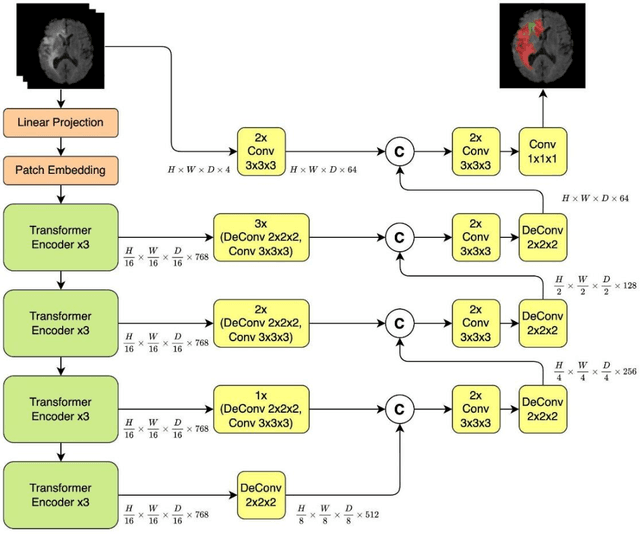
Medical image segmentation plays a crucial role in various healthcare applications, enabling accurate diagnosis, treatment planning, and disease monitoring. In recent years, Vision Transformers (ViTs) have emerged as a promising technique for addressing the challenges in medical image segmentation. In medical images, structures are usually highly interconnected and globally distributed. ViTs utilize their multi-scale attention mechanism to model the long-range relationships in the images. However, they do lack image-related inductive bias and translational invariance, potentially impacting their performance. Recently, researchers have come up with various ViT-based approaches that incorporate CNNs in their architectures, known as Hybrid Vision Transformers (HVTs) to capture local correlation in addition to the global information in the images. This survey paper provides a detailed review of the recent advancements in ViTs and HVTs for medical image segmentation. Along with the categorization of ViT and HVT-based medical image segmentation approaches we also present a detailed overview of their real-time applications in several medical image modalities. This survey may serve as a valuable resource for researchers, healthcare practitioners, and students in understanding the state-of-the-art approaches for ViT-based medical image segmentation.
LiDAR-based curb detection for ground truth annotation in automated driving validation
Dec 01, 2023Curb detection is essential for environmental awareness in Automated Driving (AD), as it typically limits drivable and non-drivable areas. Annotated data are necessary for developing and validating an AD function. However, the number of public datasets with annotated point cloud curbs is scarce. This paper presents a method for detecting 3D curbs in a sequence of point clouds captured from a LiDAR sensor, which consists of two main steps. First, our approach detects the curbs at each scan using a segmentation deep neural network. Then, a sequence-level processing step estimates the 3D curbs in the reconstructed point cloud using the odometry of the vehicle. From these 3D points of the curb, we obtain polylines structured following ASAM OpenLABEL standard. These detections can be used as pre-annotations in labelling pipelines to efficiently generate curb-related ground truth data. We validate our approach through an experiment in which different human annotators were required to annotate curbs in a group of LiDAR-based sequences with and without our automatically generated pre-annotations. The results show that the manual annotation time is reduced by 50.99% thanks to our detections, keeping the data quality level.
Generative artificial intelligence enhances individual creativity but reduces the collective diversity of novel content
Dec 01, 2023Creativity is core to being human. Generative artificial intelligence (GenAI) holds promise for humans to be more creative by offering new ideas, or less creative by anchoring on GenAI ideas. We study the causal impact of GenAI ideas on the production of an unstructured creative output in an online experimental study where some writers could obtain ideas for a story from a GenAI platform. We find that access to GenAI ideas causes stories to be evaluated as more creative, better written and more enjoyable, especially among less creative writers. However, objective measures of story similarity within each condition reveal that GenAI-enabled stories are more similar to each other than stories by humans alone. These results point to an increase in individual creativity, but at the same time there is a risk of losing collective novelty: this dynamic resembles a social dilemma where individual writers are better off using GenAI to improve their own writing, but collectively a narrower scope of novel content may be produced with GenAI. Our results have implications for researchers, policy-makers and practitioners interested in bolstering creativity, but point to potential downstream consequences from over-reliance.