 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rotation Equivariant Proximal Operator for Deep Unfolding Methods in Image Restoration
Dec 25, 2023
The deep unfolding approach has attracted significant attention in computer vision tasks, which well connects conventional image processing modeling manners with more recent deep learning techniques. Specifically, by establishing a direct correspondence between algorithm operators at each implementation step and network modules within each layer, one can rationally construct an almost ``white box'' network architecture with high interpretability. In this architecture, only the predefined component of the proximal operator, known as a proximal network, needs manual configuration, enabling the network to automatically extract intrinsic image priors in a data-driven manner. In current deep unfolding methods, such a proximal network is generally designed as a CNN architecture, whose necessity has been proven by a recent theory. That is, CNN structure substantially delivers the translational invariant image prior, which is the most universally possessed structural prior across various types of images. However, standard CNN-based proximal networks have essential limitations in capturing the rotation symmetry prior, another universal structural prior underlying general images. This leaves a large room for further performance improvement in deep unfolding approaches. To address this issue, this study makes efforts to suggest a high-accuracy rotation equivariant proximal network that effectively embeds rotation symmetry priors into the deep unfolding framework. Especially, we deduce, for the first time, the theoretical equivariant error for such a designed proximal network with arbitrary layers under arbitrary rotation degrees. This analysis should be the most refined theoretical conclusion for such error evaluation to date and is also indispensable for supporting the rationale behind such networks with intrinsic interpretability requirements.
OCTOPUS: Open-vocabulary Content Tracking and Object Placement Using Semantic Understanding in Mixed Reality
Dec 20, 2023One key challenge in augmented reality is the placement of virtual content in natural locations. Existing automated techniques are only able to work with a closed-vocabulary, fixed set of objects. In this paper, we introduce a new open-vocabulary method for object placement. Our eight-stage pipeline leverages recent advances in segmentation models, vision-language models, and LLMs to place any virtual object in any AR camera frame or scene. In a preliminary user study, we show that our method performs at least as well as human experts 57% of the time.
Low-power event-based face detection with asynchronous neuromorphic hardware
Dec 21, 2023The rise of mobility, IoT and wearables has shifted processing to the edge of the sensors, driven by the need to reduce latency, communication costs and overall energy consumption. While deep learning models have achieved remarkable results in various domains, their deployment at the edge for real-time applications remains computationally expensive. Neuromorphic computing emerges as a promising paradigm shift, characterized by co-localized memory and computing as well as event-driven asynchronous sensing and processing. In this work, we demonstrate the possibility of solving the ubiquitous computer vision task of object detection at the edge with low-power requirements, using the event-based N-Caltech101 dataset. We present the first instance of an on-chip spiking neural network for event-based face detection deployed on the SynSense Speck neuromorphic chip, which comprises both an event-based sensor and a spike-based asynchronous processor implementing Integrate-and-Fire neurons. We show how to reduce precision discrepancies between off-chip clock-driven simulation used for training and on-chip event-driven inference. This involves using a multi-spike version of the Integrate-and-Fire neuron on simulation, where spikes carry values that are proportional to the extent the membrane potential exceeds the firing threshold. We propose a robust strategy to train spiking neural networks with back-propagation through time using multi-spike activation and firing rate regularization and demonstrate how to decode output spikes into bounding boxes. We show that the power consumption of the chip is directly proportional to the number of synaptic operations in the spiking neural network, and we explore the trade-off between power consumption and detection precision with different firing rate regularization, achieving an on-chip face detection mAP[0.5] of ~0.6 while consuming only ~20 mW.
Free-Editor: Zero-shot Text-driven 3D Scene Editing
Dec 21, 2023Text-to-Image (T2I) diffusion models have gained popularity recently due to their multipurpose and easy-to-use nature, e.g. image and video generation as well as editing. However, training a diffusion model specifically for 3D scene editing is not straightforward due to the lack of large-scale datasets. To date, editing 3D scenes requires either re-training the model to adapt to various 3D edited scenes or design-specific methods for each special editing type. Furthermore, state-of-the-art (SOTA) methods require multiple synchronized edited images from the same scene to facilitate the scene editing. Due to the current limitations of T2I models, it is very challenging to apply consistent editing effects to multiple images, i.e. multi-view inconsistency in editing. This in turn compromises the desired 3D scene editing performance if these images are used. In our work, we propose a novel training-free 3D scene editing technique, Free-Editor, which allows users to edit 3D scenes without further re-training the model during test time. Our proposed method successfully avoids the multi-view style inconsistency issue in SOTA methods with the help of a "single-view editing" scheme. Specifically, we show that editing a particular 3D scene can be performed by only modifying a single view. To this end, we introduce an Edit Transformer that enforces intra-view consistency and inter-view style transfer by utilizing self- and cross-attention, respectively. Since it is no longer required to re-train the model and edit every view in a scene, the editing time, as well as memory resources, are reduced significantly, e.g., the runtime being $\sim \textbf{20} \times$ faster than SOTA. We have conducted extensive experiments on a wide range of benchmark datasets and achieve diverse editing capabilities with our proposed technique.
High-resolution myelin-water fraction and quantitative relaxation mapping using 3D ViSTa-MR fingerprinting
Dec 21, 2023Purpose: This study aims to develop a high-resolution whole-brain multi-parametric quantitative MRI approach for simultaneous mapping of myelin-water fraction (MWF), T1, T2, and proton-density (PD), all within a clinically feasible scan time. Methods: We developed 3D ViSTa-MRF, which combined Visualization of Short Transverse relaxation time component (ViSTa) technique with MR Fingerprinting (MRF), to achieve high-fidelity whole-brain MWF and T1/T2/PD mapping on a clinical 3T scanner. To achieve fast acquisition and memory-efficient reconstruction, the ViSTa-MRF sequence leverages an optimized 3D tiny-golden-angle-shuffling spiral-projection acquisition and joint spatial-temporal subspace reconstruction with optimized preconditioning algorithm. With the proposed ViSTa-MRF approach, high-fidelity direct MWF mapping was achieved without a need for multi-compartment fitting that could introduce bias and/or noise from additional assumptions or priors. Results: The in-vivo results demonstrate the effectiveness of the proposed acquisition and reconstruction framework to provide fast multi-parametric mapping with high SNR and good quality. The in-vivo results of 1mm- and 0.66mm-iso datasets indicate that the MWF values measured by the proposed method are consistent with standard ViSTa results that are 30x slower with lower SNR. Furthermore, we applied the proposed method to enable 5-minute whole-brain 1mm-iso assessment of MWF and T1/T2/PD mappings for infant brain development and for post-mortem brain samples. Conclusions: In this work, we have developed a 3D ViSTa-MRF technique that enables the acquisition of whole-brain MWF, quantitative T1, T2, and PD maps at 1mm and 0.66mm isotropic resolution in 5 and 15 minutes, respectively. This advancement allows for quantitative investigations of myelination changes in the brain.
AsyncMLD: Asynchronous Multi-LLM Framework for Dialogue Recommendation System
Dec 21, 2023We have reached a practical and realistic phase in human-support dialogue agents by developing a large language model (LLM). However, when requiring expert knowledge or anticipating the utterance content using the massive size of the dialogue database, we still need help with the utterance content's effectiveness and the efficiency of its output speed, even if using LLM. Therefore, we propose a framework that uses LLM asynchronously in the part of the system that returns an appropriate response and in the part that understands the user's intention and searches the database. In particular, noting that it takes time for the robot to speak, threading related to database searches is performed while the robot is speaking.
A Summarized History-based Dialogue System for Amnesia-Free Prompt Updates
Dec 21, 2023In today's society, information overload presents challenges in providing optimal recommendations. Consequently, the importance of dialogue systems that can discern and provide the necessary information through dialogue is increasingly recognized. However, some concerns existing dialogue systems rely on pre-trained models and need help to cope with real-time or insufficient information. To address these concerns, models that allow the addition of missing information to dialogue robots are being proposed. Yet, maintaining the integrity of previous conversation history while integrating new data remains a formidable challenge. This paper presents a novel system for dialogue robots designed to remember user-specific characteristics by retaining past conversation history even as new information is added.
Dynamic Local Attention with Hierarchical Patching for Irregular Clinical Time Series
Nov 13, 2023Irregular multivariate time series data is prevalent in the clinical and healthcare domains. It is characterized by time-wise and feature-wise irregularities, making it challenging for machine learning methods to work with. To solve this, we introduce a new model architecture composed of two modules: (1) DLA, a Dynamic Local Attention mechanism that uses learnable queries and feature-specific local windows when computing the self-attention operation. This results in aggregating irregular time steps raw input within each window to a harmonized regular latent space representation while taking into account the different features' sampling rates. (2) A hierarchical MLP mixer that processes the output of DLA through multi-scale patching to leverage information at various scales for the downstream tasks. Our approach outperforms state-of-the-art methods on three real-world datasets, including the latest clinical MIMIC IV dataset.
Blood Glucose Level Prediction: A Graph-based Explainable Method with Federated Learning
Dec 19, 2023In the UK, approximately 400,000 people with type 1 diabetes (T1D) rely on insulin delivery due to insufficient pancreatic insulin production. Managing blood glucose (BG) levels is crucial, with continuous glucose monitoring (CGM) playing a key role. CGM, tracking BG every 5 minutes, enables effective blood glucose level prediction (BGLP) by considering factors like carbohydrate intake and insulin delivery. Recent research has focused on developing sequential models for BGLP using historical BG data, incorporating additional attributes such as carbohydrate intake, insulin delivery, and time. These methods have shown notable success in BGLP, with some providing temporal explanations. However, they often lack clear correlations between attributes and their impact on BGLP. Additionally, some methods raise privacy concerns by aggregating participant data to learn population patterns. Addressing these limitations, we introduced a graph attentive memory (GAM) model, combining a graph attention network (GAT) with a gated recurrent unit (GRU). GAT applies graph attention to model attribute correlations, offering transparent, dynamic attribute relationships. Attention weights dynamically gauge attribute significance over time. To ensure privacy, we employed federated learning (FL), facilitating secure population pattern analysis. Our method was validated using the OhioT1DM'18 and OhioT1DM'20 datasets from 12 participants, focusing on 6 key attributes. We demonstrated our model's stability and effectiveness through hyperparameter impact analysis.
Time Series Synthesis Using the Matrix Profile for Anonymization
Nov 05, 2023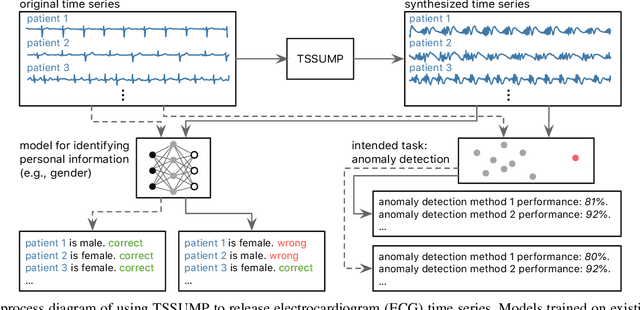
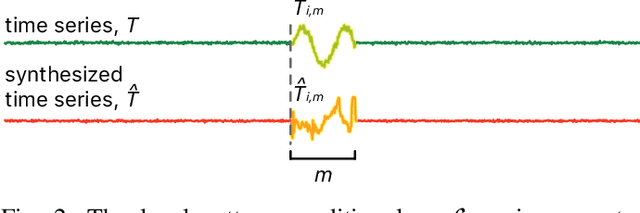
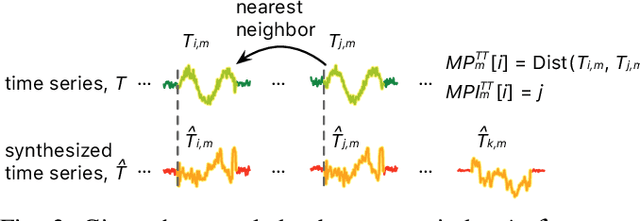
Publishing and sharing data is crucial for the data mining community, allowing collaboration and driving open innovation. However, many researchers cannot release their data due to privacy regulations or fear of leaking confidential business information. To alleviate such issues, we propose the Time Series Synthesis Using the Matrix Profile (TSSUMP) method, where synthesized time series can be released in lieu of the original data. The TSSUMP method synthesizes time series by preserving similarity join information (i.e., Matrix Profile) while reducing the correlation between the synthesized and the original time series. As a result, neither the values for the individual time steps nor the local patterns (or shapes) from the original data can be recovered, yet the resulting data can be used for downstream tasks that data analysts are interested in. We concentrate on similarity joins because they are one of the most widely applied time series data mining routines across different data mining tasks. We test our method on a case study of ECG and gender masking prediction. In this case study, the gender information is not only removed from the synthesized time series, but the synthesized time series also preserves enough information from the original time series. As a result, unmodified data mining tools can obtain near-identical performance on the synthesized time series as on the original time series.