 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSF-4D: A Progressive Sampling Framework for View Consistent 4D Editing
Mar 14, 2025Instruction-guided generative models, especially those using text-to-image (T2I) and text-to-video (T2V) diffusion frameworks, have advanced the field of content editing in recent years. To extend these capabilities to 4D scene, we introduce a progressive sampling framework for 4D editing (PSF-4D) that ensures temporal and multi-view consistency by intuitively controlling the noise initialization during forward diffusion. For temporal coherence, we design a correlated Gaussian noise structure that links frames over time, allowing each frame to depend meaningfully on prior frames. Additionally, to ensure spatial consistency across views, we implement a cross-view noise model, which uses shared and independent noise components to balance commonalities and distinct details among different views. To further enhance spatial coherence, PSF-4D incorporates view-consistent iterative refinement, embedding view-aware information into the denoising process to ensure aligned edits across frames and views. Our approach enables high-quality 4D editing without relying on external models, addressing key challenges in previous methods. Through extensive evaluation on multiple benchmarks and multiple editing aspects (e.g., style transfer, multi-attribute editing, object removal, local editing, etc.), we show the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art 4D editing methods in diverse benchmarks.
Fisher Information guided Purification against Backdoor Attacks
Sep 01, 2024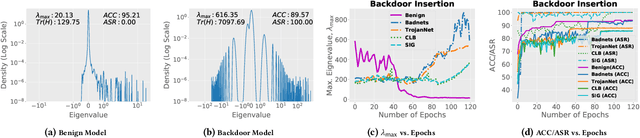

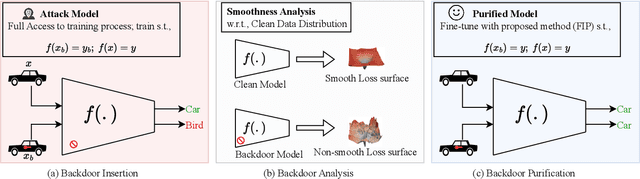

Studies on backdoor attacks in recent years suggest that an adversary can compromise the integrity of a deep neural network (DNN) by manipulating a small set of training samples. Our analysis shows that such manipulation can make the backdoor model converge to a bad local minima, i.e., sharper minima as compared to a benign model. Intuitively, the backdoor can be purified by re-optimizing the model to smoother minima. However, a na\"ive adoption of any optimization targeting smoother minima can lead to sub-optimal purification techniques hampering the clean test accuracy. Hence, to effectively obtain such re-optimization, inspired by our novel perspective establishing the connection between backdoor removal and loss smoothness, we propose Fisher Information guided Purification (FIP), a novel backdoor purification framework. Proposed FIP consists of a couple of novel regularizers that aid the model in suppressing the backdoor effects and retaining the acquired knowledge of clean data distribution throughout the backdoor removal procedure through exploiting the knowledge of Fisher Information Matrix (FIM). In addition, we introduce an efficient variant of FIP, dubbed as Fast FIP, which reduces the number of tunable parameters significantly and obtains an impressive runtime gain of almost $5\times$. Extensive experiments show that the proposed method achieves state-of-the-art (SOTA) performance on a wide range of backdoor defense benchmarks: 5 different tasks -- Image Recognition, Object Detection, Video Action Recognition, 3D point Cloud, Language Generation; 11 different datasets including ImageNet, PASCAL VOC, UCF101; diverse model architectures spanning both CNN and vision transformer; 14 different backdoor attacks, e.g., Dynamic, WaNet, LIRA, ISSBA, etc.
Augmented Neural Fine-Tuning for Efficient Backdoor Purification
Jul 14, 2024



Recent studies have revealed the vulnerability of deep neural networks (DNNs) to various backdoor attacks, where the behavior of DNNs can be compromised by utilizing certain types of triggers or poisoning mechanisms. State-of-the-art (SOTA) defenses employ too-sophisticated mechanisms that require either a computationally expensive adversarial search module for reverse-engineering the trigger distribution or an over-sensitive hyper-parameter selection module. Moreover, they offer sub-par performance in challenging scenarios, e.g., limited validation data and strong attacks. In this paper, we propose Neural mask Fine-Tuning (NFT) with an aim to optimally re-organize the neuron activities in a way that the effect of the backdoor is removed. Utilizing a simple data augmentation like MixUp, NFT relaxes the trigger synthesis process and eliminates the requirement of the adversarial search module. Our study further reveals that direct weight fine-tuning under limited validation data results in poor post-purification clean test accuracy, primarily due to overfitting issue. To overcome this, we propose to fine-tune neural masks instead of model weights. In addition, a mask regularizer has been devised to further mitigate the model drift during the purification process. The distinct characteristics of NFT render it highly efficient in both runtime and sample usage, as it can remove the backdoor even when a single sample is available from each class. We validate the effectiveness of NFT through extensive experiments covering the tasks of image classification, object detection, video action recognition, 3D point cloud, and natural language processing. We evaluate our method against 14 different attacks (LIRA, WaNet, etc.) on 11 benchmark data sets such as ImageNet, UCF101, Pascal VOC, ModelNet, OpenSubtitles2012, etc.
Free-Editor: Zero-shot Text-driven 3D Scene Editing
Dec 21, 2023



Text-to-Image (T2I) diffusion models have gained popularity recently due to their multipurpose and easy-to-use nature, e.g. image and video generation as well as editing. However, training a diffusion model specifically for 3D scene editing is not straightforward due to the lack of large-scale datasets. To date, editing 3D scenes requires either re-training the model to adapt to various 3D edited scenes or design-specific methods for each special editing type. Furthermore, state-of-the-art (SOTA) methods require multiple synchronized edited images from the same scene to facilitate the scene editing. Due to the current limitations of T2I models, it is very challenging to apply consistent editing effects to multiple images, i.e. multi-view inconsistency in editing. This in turn compromises the desired 3D scene editing performance if these images are used. In our work, we propose a novel training-free 3D scene editing technique, Free-Editor, which allows users to edit 3D scenes without further re-training the model during test time. Our proposed method successfully avoids the multi-view style inconsistency issue in SOTA methods with the help of a "single-view editing" scheme. Specifically, we show that editing a particular 3D scene can be performed by only modifying a single view. To this end, we introduce an Edit Transformer that enforces intra-view consistency and inter-view style transfer by utilizing self- and cross-attention, respectively. Since it is no longer required to re-train the model and edit every view in a scene, the editing time, as well as memory resources, are reduced significantly, e.g., the runtime being $\sim \textbf{20} \times$ faster than SOTA. We have conducted extensive experiments on a wide range of benchmark datasets and achieve diverse editing capabilities with our proposed technique.
LatentEditor: Text Driven Local Editing of 3D Scenes
Dec 18, 2023While neural fields have made significant strides in view synthesis and scene reconstruction, editing them poses a formidable challenge due to their implicit encoding of geometry and texture information from multi-view inputs. In this paper, we introduce \textsc{LatentEditor}, an innovative framework designed to empower users with the ability to perform precise and locally controlled editing of neural fields using text prompts. Leveraging denoising diffusion models, we successfully embed real-world scenes into the latent space, resulting in a faster and more adaptable NeRF backbone for editing compared to traditional methods. To enhance editing precision, we introduce a delta score to calculate the 2D mask in the latent space that serves as a guide for local modifications while preserving irrelevant regions. Our novel pixel-level scoring approach harnesses the power of InstructPix2Pix (IP2P) to discern the disparity between IP2P conditional and unconditional noise predictions in the latent space. The edited latents conditioned on the 2D masks are then iteratively updated in the training set to achieve 3D local editing. Our approach achieves faster editing speeds and superior output quality compared to existing 3D editing models, bridging the gap between textual instructions and high-quality 3D scene editing in latent space. We show the superiority of our approach on four benchmark 3D datasets, LLFF, IN2N, NeRFStudio and NeRF-Art.
Efficient Backdoor Removal Through Natural Gradient Fine-tuning
Jun 30, 2023


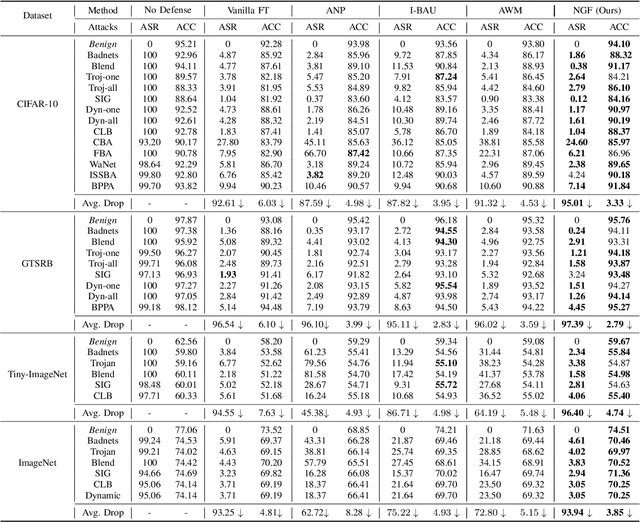
The success of a deep neural network (DNN) heavily relies on the details of the training scheme; e.g., training data, architectures, hyper-parameters, etc. Recent backdoor attacks suggest that an adversary can take advantage of such training details and compromise the integrity of a DNN. Our studies show that a backdoor model is usually optimized to a bad local minima, i.e. sharper minima as compared to a benign model. Intuitively, a backdoor model can be purified by reoptimizing the model to a smoother minima through fine-tuning with a few clean validation data. However, fine-tuning all DNN parameters often requires huge computational costs and often results in sub-par clean test performance. To address this concern, we propose a novel backdoor purification technique, Natural Gradient Fine-tuning (NGF), which focuses on removing the backdoor by fine-tuning only one layer. Specifically, NGF utilizes a loss surface geometry-aware optimizer that can successfully overcome the challenge of reaching a smooth minima under a one-layer optimization scenario. To enhance the generalization performance of our proposed method, we introduce a clean data distribution-aware regularizer based on the knowledge of loss surface curvature matrix, i.e., Fisher Information Matrix. Extensive experiments show that the proposed method achieves state-of-the-art performance on a wide range of backdoor defense benchmarks: four different datasets- CIFAR10, GTSRB, Tiny-ImageNet, and ImageNet; 13 recent backdoor attacks, e.g. Blend, Dynamic, WaNet, ISSBA, etc.
SAVE: Spectral-Shift-Aware Adaptation of Image Diffusion Models for Text-guided Video Editing
May 30, 2023



Text-to-Image (T2I) diffusion models have achieved remarkable success in synthesizing high-quality images conditioned on text prompts. Recent methods have tried to replicate the success by either training text-to-video (T2V) models on a very large number of text-video pairs or adapting T2I models on text-video pairs independently. Although the latter is computationally less expensive, it still takes a significant amount of time for per-video adaption. To address this issue, we propose SAVE, a novel spectral-shift-aware adaptation framework, in which we fine-tune the spectral shift of the parameter space instead of the parameters themselves. Specifically, we take the spectral decomposition of the pre-trained T2I weights and only control the change in the corresponding singular values, i.e. spectral shift, while freezing the corresponding singular vectors. To avoid drastic drift from the original T2I weights, we introduce a spectral shift regularizer that confines the spectral shift to be more restricted for large singular values and more relaxed for small singular values. Since we are only dealing with spectral shifts, the proposed method reduces the adaptation time significantly (approx. 10 times) and has fewer resource constrains for training. Such attributes posit SAVE to be more suitable for real-world applications, e.g. editing undesirable content during video streaming. We validate the effectiveness of SAVE with an extensive experimental evaluation under different settings, e.g. style transfer, object replacement, privacy preservation, etc.
C-SFDA: A Curriculum Learning Aided Self-Training Framework for Efficient Source Free Domain Adaptation
Mar 30, 2023



Unsupervised domain adaptation (UDA) approaches focus on adapting models trained on a labeled source domain to an unlabeled target domain. UDA methods have a strong assumption that the source data is accessible during adaptation, which may not be feasible in many real-world scenarios due to privacy concerns and resource constraints of devices. In this regard, source-free domain adaptation (SFDA) excels as access to source data is no longer required during adaptation. Recent state-of-the-art (SOTA) methods on SFDA mostly focus on pseudo-label refinement based self-training which generally suffers from two issues: i) inevitable occurrence of noisy pseudo-labels that could lead to early training time memorization, ii) refinement process requires maintaining a memory bank which creates a significant burden in resource constraint scenarios. To address these concerns, we propose C-SFDA, a curriculum learning aided self-training framework for SFDA that adapts efficiently and reliably to changes across domains based on selective pseudo-labeling. Specifically, we employ a curriculum learning scheme to promote learning from a restricted amount of pseudo labels selected based on their reliabilities. This simple yet effective step successfully prevents label noise propagation during different stages of adaptation and eliminates the need for costly memory-bank based label refinement. Our extensive experimental evaluations on both image recognition and semantic segmentation tasks confirm the effectiveness of our method. C-SFDA is readily applicable to online test-time domain adaptation and also outperforms previous SOTA methods in this task.
CNLL: A Semi-supervised Approach For Continual Noisy Label Learning
Apr 21, 2022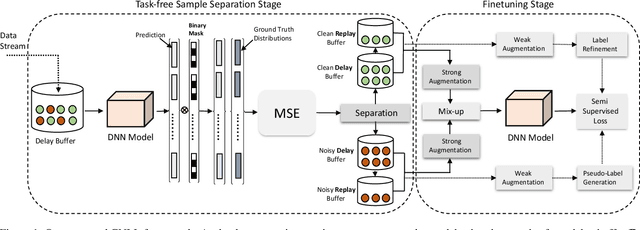
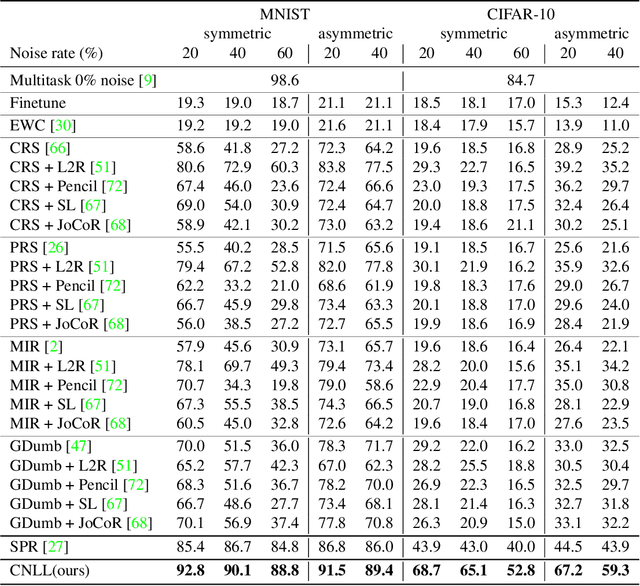
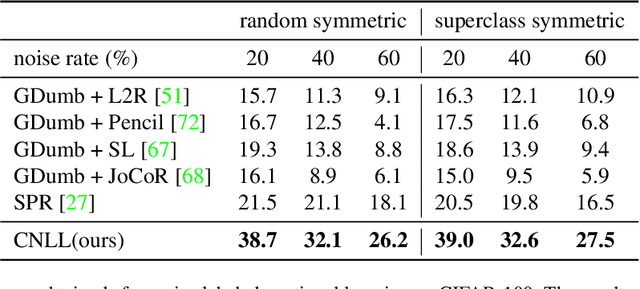
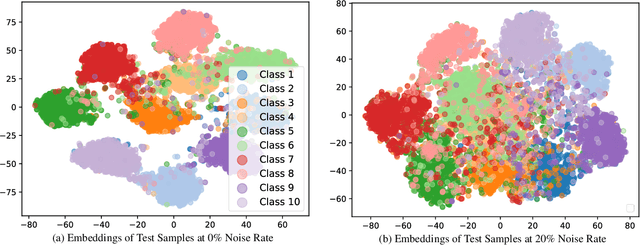
The task of continual learning requires careful design of algorithms that can tackle catastrophic forgetting. However, the noisy label, which is inevitable in a real-world scenario, seems to exacerbate the situation. While very few studies have addressed the issue of continual learning under noisy labels, long training time and complicated training schemes limit their applications in most cases. In contrast, we propose a simple purification technique to effectively cleanse the online data stream that is both cost-effective and more accurate. After purification, we perform fine-tuning in a semi-supervised fashion that ensures the participation of all available samples. Training in this fashion helps us learn a better representation that results in state-of-the-art (SOTA) performance. Through extensive experimentation on 3 benchmark datasets, MNIST, CIFAR10 and CIFAR100, we show the effectiveness of our proposed approach. We achieve a 24.8% performance gain for CIFAR10 with 20% noise over previous SOTA methods. Our code is publicly available.
RODD: A Self-Supervised Approach for Robust Out-of-Distribution Detection
Apr 13, 2022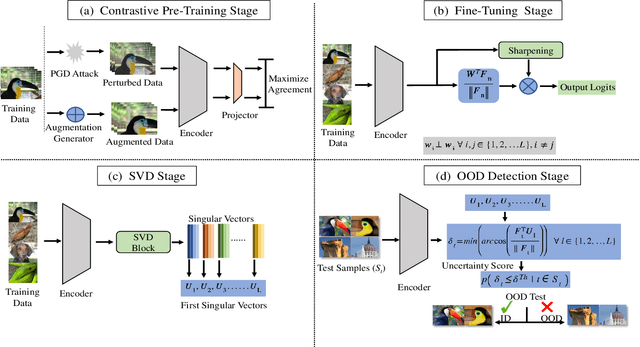
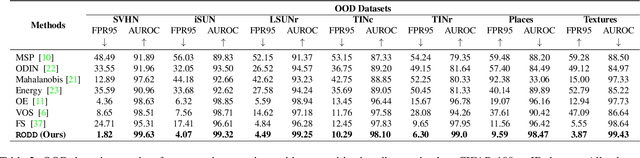
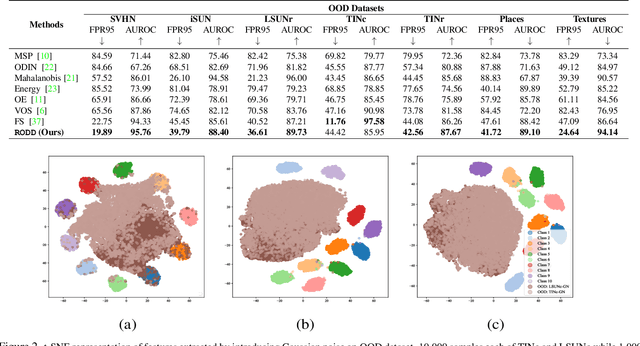
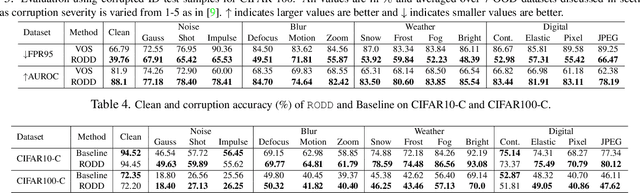
Recent studies have addressed the concern of detecting and rejecting the out-of-distribution (OOD) samples as a major challenge in the safe deployment of deep learning (DL) models. It is desired that the DL model should only be confident about the in-distribution (ID) data which reinforces the driving principle of the OOD detection. In this paper, we propose a simple yet effective generalized OOD detection method independent of out-of-distribution datasets. Our approach relies on self-supervised feature learning of the training samples, where the embeddings lie on a compact low-dimensional space. Motivated by the recent studies that show self-supervised adversarial contrastive learning helps robustify the model, we empirically show that a pre-trained model with self-supervised contrastive learning yields a better model for uni-dimensional feature learning in the latent space. The method proposed in this work referred to as RODD outperforms SOTA detection performance on an extensive suite of benchmark datasets on OOD detection tasks. On the CIFAR-100 benchmarks, RODD achieves a 26.97 $\%$ lower false-positive rate (FPR@95) compared to SOTA methods.