 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
POMP: Pomcp-based Online Motion Planning for active visual search in indoor environments
Sep 17, 2020
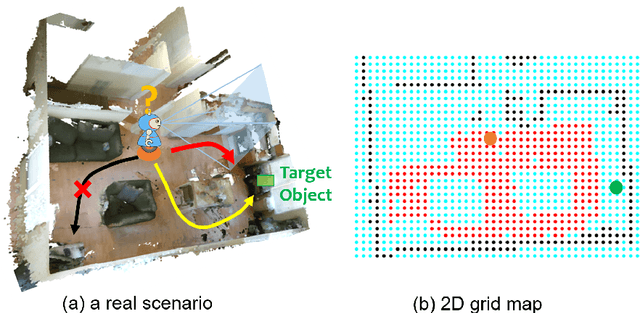
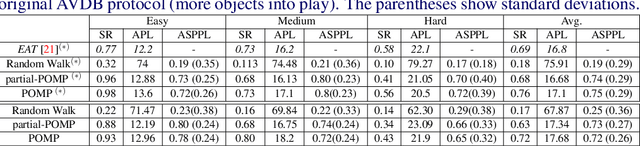
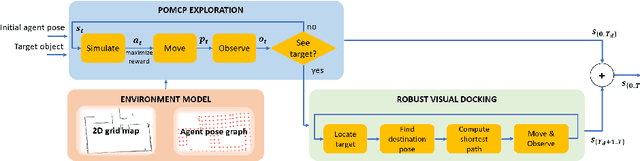

In this paper we focus on the problem of learning an optimal policy for Active Visual Search (AVS) of objects in known indoor environments with an online setup. Our POMP method uses as input the current pose of an agent (e.g. a robot) and a RGB-D frame. The task is to plan the next move that brings the agent closer to the target object. We model this problem as a Partially Observable Markov Decision Process solved by a Monte-Carlo planning approach. This allows us to make decisions on the next moves by iterating over the known scenario at hand, exploring the environment and searching for the object at the same time. Differently from the current state of the art in Reinforcement Learning, POMP does not require extensive and expensive (in time and computation) labelled data so being very agile in solving AVS in small and medium real scenarios. We only require the information of the floormap of the environment, an information usually available or that can be easily extracted from an a priori single exploration run. We validate our method on the publicly available AVD benchmark, achieving an average success rate of 0.76 with an average path length of 17.1, performing close to the state of the art but without any training needed. Additionally, we show experimentally the robustness of our method when the quality of the object detection goes from ideal to faulty.
Fusion Recurrent Neural Network
Jun 07, 2020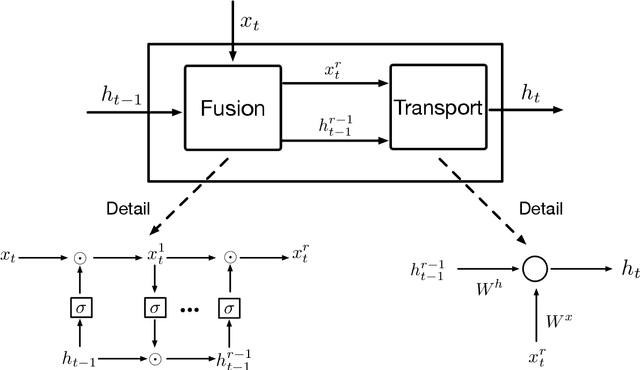


Considering deep sequence learning for practical application, two representative RNNs - LSTM and GRU may come to mind first. Nevertheless, is there no chance for other RNNs? Will there be a better RNN in the future? In this work, we propose a novel, succinct and promising RNN - Fusion Recurrent Neural Network (Fusion RNN). Fusion RNN is composed of Fusion module and Transport module every time step. Fusion module realizes the multi-round fusion of the input and hidden state vector. Transport module which mainly refers to simple recurrent network calculate the hidden state and prepare to pass it to the next time step. Furthermore, in order to evaluate Fusion RNN's sequence feature extraction capability, we choose a representative data mining task for sequence data, estimated time of arrival (ETA) and present a novel model based on Fusion RNN. We contrast our method and other variants of RNN for ETA under massive vehicle travel data from DiDi Chuxing. The results demonstrate that for ETA, Fusion RNN is comparable to state-of-the-art LSTM and GRU which are more complicated than Fusion RNN.
Fast and accurate learned multiresolution dynamical downscaling for precipitation
Jan 18, 2021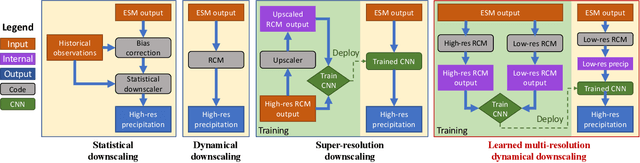
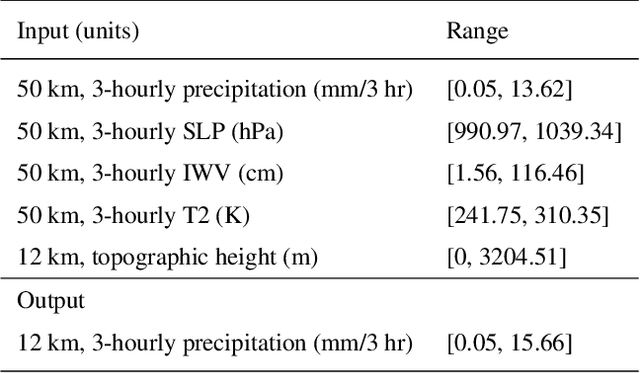
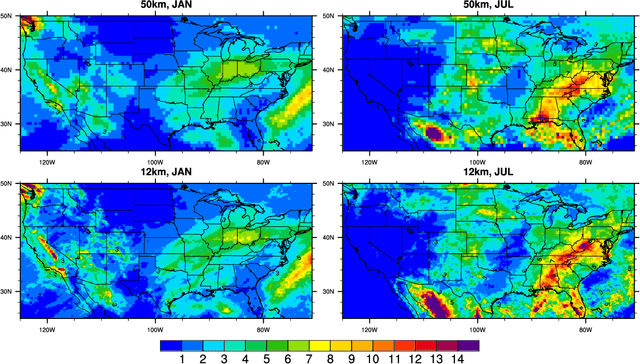
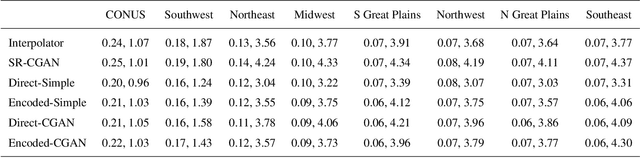
This study develops a neural network-based approach for emulating high-resolution modeled precipitation data with comparable statistical properties but at greatly reduced computational cost. The key idea is to use combination of low- and high- resolution simulations to train a neural network to map from the former to the latter. Specifically, we define two types of CNNs, one that stacks variables directly and one that encodes each variable before stacking, and we train each CNN type both with a conventional loss function, such as mean square error (MSE), and with a conditional generative adversarial network (CGAN), for a total of four CNN variants. We compare the four new CNN-derived high-resolution precipitation results with precipitation generated from original high resolution simulations, a bilinear interpolater and the state-of-the-art CNN-based super-resolution (SR) technique. Results show that the SR technique produces results similar to those of the bilinear interpolator with smoother spatial and temporal distributions and smaller data variabilities and extremes than the original high resolution simulations. While the new CNNs trained by MSE generate better results over some regions than the interpolator and SR technique do, their predictions are still not as close as the original high resolution simulations. The CNNs trained by CGAN generate more realistic and physically reasonable results, better capturing not only data variability in time and space but also extremes such as intense and long-lasting storms. The new proposed CNN-based downscaling approach can downscale precipitation from 50~km to 12~km in 14~min for 30~years once the network is trained (training takes 4~hours using 1~GPU), while the conventional dynamical downscaling would take 1~month using 600 CPU cores to generate simulations at the resolution of 12~km over contiguous United States.
Policy Optimization for Markovian Jump Linear Quadratic Control: Gradient-Based Methods and Global Convergence
Nov 24, 2020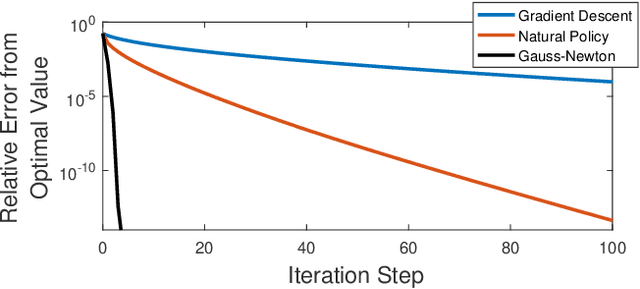
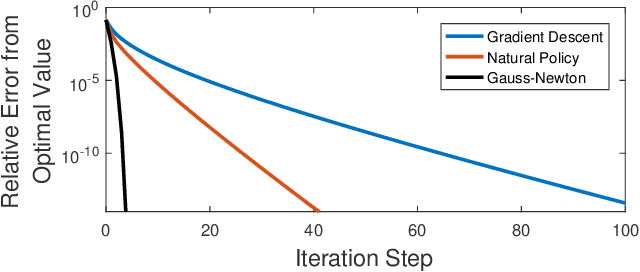
Recently, policy optimization for control purposes has received renewed attention due to the increasing interest in reinforcement learning. In this paper, we investigate the global convergence of gradient-based policy optimization methods for quadratic optimal control of discrete-time Markovian jump linear systems (MJLS). First, we study the optimization landscape of direct policy optimization for MJLS, with static state feedback controllers and quadratic performance costs. Despite the non-convexity of the resultant problem, we are still able to identify several useful properties such as coercivity, gradient dominance, and almost smoothness. Based on these properties, we show global convergence of three types of policy optimization methods: the gradient descent method; the Gauss-Newton method; and the natural policy gradient method. We prove that all three methods converge to the optimal state feedback controller for MJLS at a linear rate if initialized at a controller which is mean-square stabilizing. Some numerical examples are presented to support the theory. This work brings new insights for understanding the performance of policy gradient methods on the Markovian jump linear quadratic control problem.
Warm Starting CMA-ES for Hyperparameter Optimization
Dec 13, 2020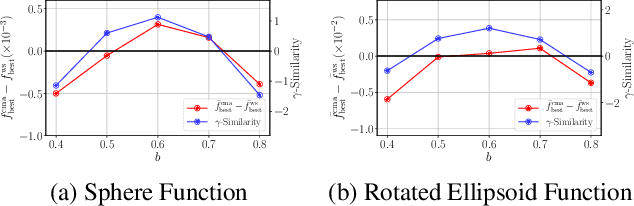

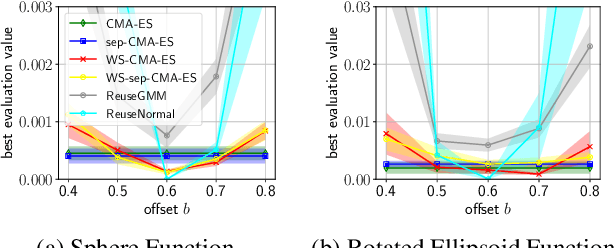
Hyperparameter optimization (HPO), formulated as black-box optimization (BBO), is recognized as essential for automation and high performance of machine learning approaches. The CMA-ES is a promising BBO approach with a high degree of parallelism, and has been applied to HPO tasks, often under parallel implementation, and shown superior performance to other approaches including Bayesian optimization (BO). However, if the budget of hyperparameter evaluations is severely limited, which is often the case for end users who do not deserve parallel computing, the CMA-ES exhausts the budget without improving the performance due to its long adaptation phase, resulting in being outperformed by BO approaches. To address this issue, we propose to transfer prior knowledge on similar HPO tasks through the initialization of the CMA-ES, leading to significantly shortening the adaptation time. The knowledge transfer is designed based on the novel definition of task similarity, with which the correlation of the performance of the proposed approach is confirmed on synthetic problems. The proposed warm starting CMA-ES, called WS-CMA-ES, is applied to different HPO tasks where some prior knowledge is available, showing its superior performance over the original CMA-ES as well as BO approaches with or without using the prior knowledge.
REPAINT: Knowledge Transfer in Deep Actor-Critic Reinforcement Learning
Nov 24, 2020
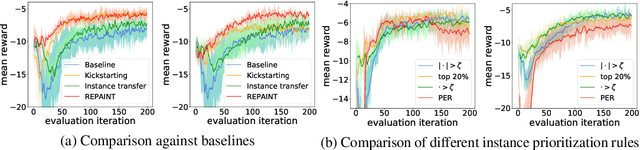
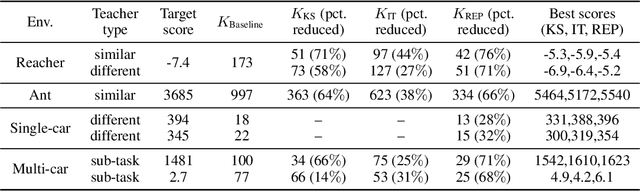
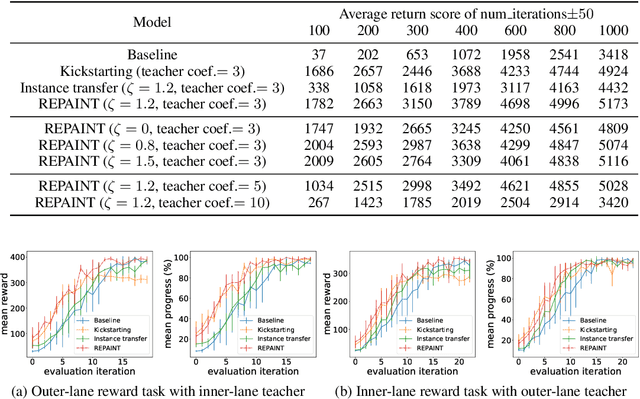
Accelerating the learning processes for complex tasks by leveraging previously learned tasks has been one of the most challenging problems in reinforcement learning, especially when the similarity between source and target tasks is low or unknown. In this work, we propose a REPresentation-And-INstance Transfer algorithm (REPAINT) for deep actor-critic reinforcement learning paradigm. In representation transfer, we adopt a kickstarted training method using a pre-trained teacher policy by introducing an auxiliary cross-entropy loss. In instance transfer, we develop a sampling approach, i.e., advantage-based experience replay, on transitions collected following the teacher policy, where only the samples with high advantage estimates are retained for policy update. We consider both learning an unseen target task by transferring from previously learned teacher tasks and learning a partially unseen task composed of multiple sub-tasks by transferring from a pre-learned teacher sub-task. In several benchmark experiments, REPAINT significantly reduces the total training time and improves the asymptotic performance compared to training with no prior knowledge and other baselines.
Acoustic span embeddings for multilingual query-by-example search
Nov 24, 2020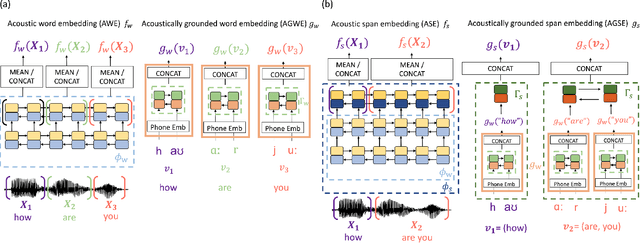
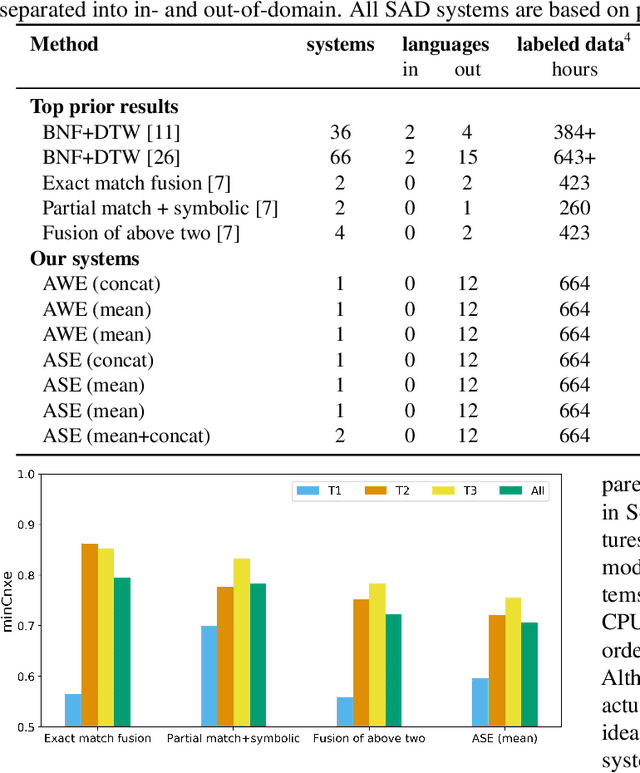
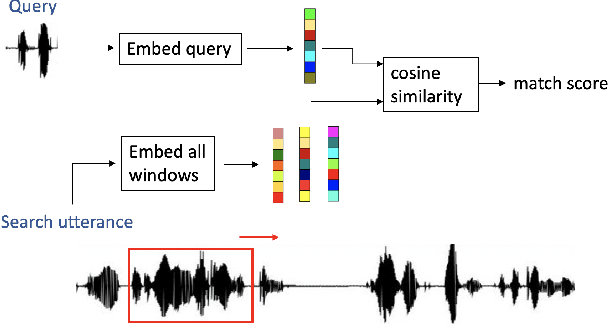
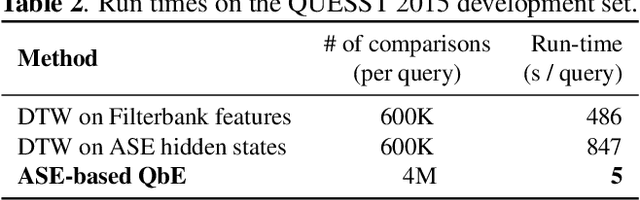
Query-by-example (QbE) speech search is the task of matching spoken queries to utterances within a search collection. In low- or zero-resource settings, QbE search is often addressed with approaches based on dynamic time warping (DTW). Recent work has found that methods based on acoustic word embeddings (AWEs) can improve both performance and search speed. However, prior work on AWE-based QbE has primarily focused on English data and with single-word queries. In this work, we generalize AWE training to spans of words, producing acoustic span embeddings (ASE), and explore the application of ASE to QbE with arbitrary-length queries in multiple unseen languages. We consider the commonly used setting where we have access to labeled data in other languages (in our case, several low-resource languages) distinct from the unseen test languages. We evaluate our approach on the QUESST 2015 QbE tasks, finding that multilingual ASE-based search is much faster than DTW-based search and outperforms the best previously published results on this task.
Safe and Robust Motion Planning for Dynamic Robotics via Control Barrier Functions
Nov 13, 2020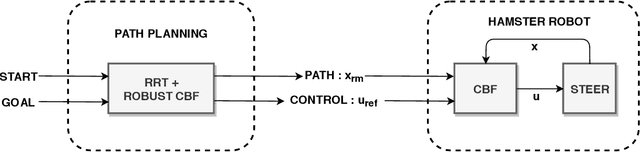
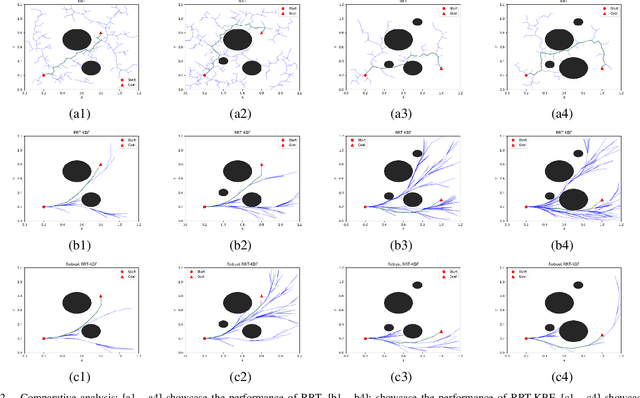

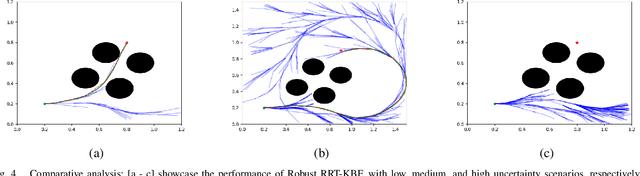
Control Barrier Functions (CBF) are widely used to enforce the safety-critical constraints on nonlinear systems. Recently, these functions are being incorporated into a path planning framework to design a safety-critical path planner. However, these methods fall short of providing a realistic path considering both run-time complexity and safety-critical constraints. This paper proposes a novel motion planning approach using Rapidly exploring Random Trees (RRT) algorithm to enforce the robust CBF and kinodynamic constraints to generate a safety-critical path that is free of any obstacles while taking into account the model uncertainty from robot dynamics as well as perception. Result analysis indicates that the proposed method outperforms various conventional RRT based path planners, guaranteeing a safety-critical path with reduced computational overhead. We present numerical validation of the algorithm on the Hamster V7 robot car, a micro autonomous Unmanned Ground Vehicle, where it performs dynamic navigation on an obstacle-ridden path with various uncertainties in perception noises, and robot dynamics.
Turn-level Dialog Evaluation with Dialog-level Weak Signals for Bot-Human Hybrid Customer Service Systems
Oct 25, 2020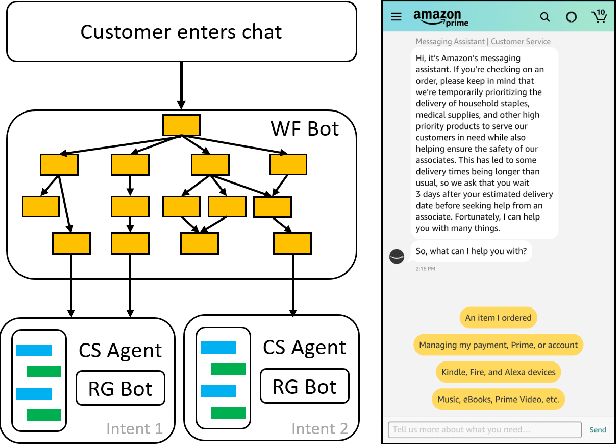
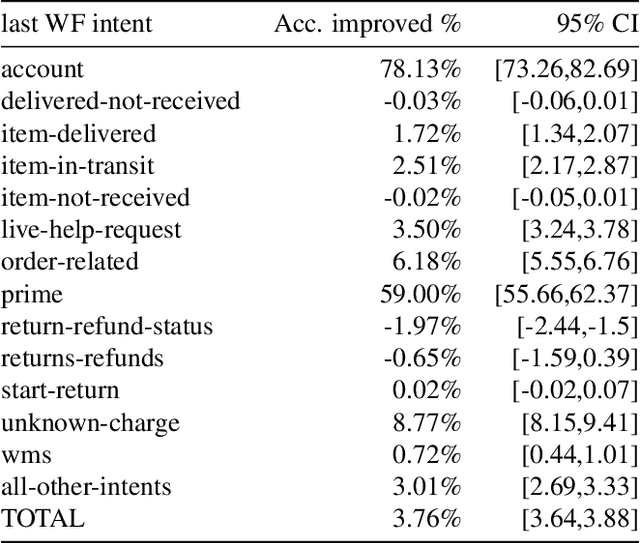
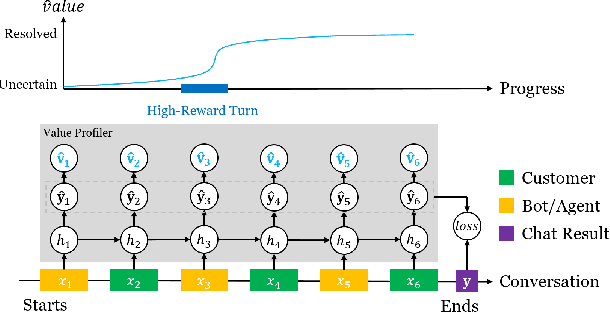
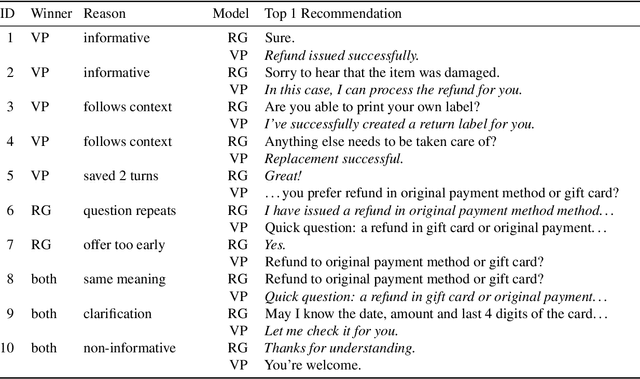
We developed a machine learning approach that quantifies multiple aspects of the success or values in Customer Service contacts, at anytime during the interaction. Specifically, the value/reward function regarding to the turn-level behaviors across human agents, chatbots and other hybrid dialog systems is characterized by the incremental information and confidence gain between sentences, based on the token-level predictions from a multi-task neural network trained with only weak signals in dialog-level attributes/states. The resulting model, named Value Profiler, serves as a goal-oriented dialog manager that enhances conversations by regulating automated decisions with its reward and state predictions. It supports both real-time monitoring and scalable offline customer experience evaluation, for both bot- and human-handled contacts. We show how it improves Amazon customer service quality in several applications.
From BOP to BOSS and Beyond: Time Series Classification with Dictionary Based Classifiers
Sep 18, 2018

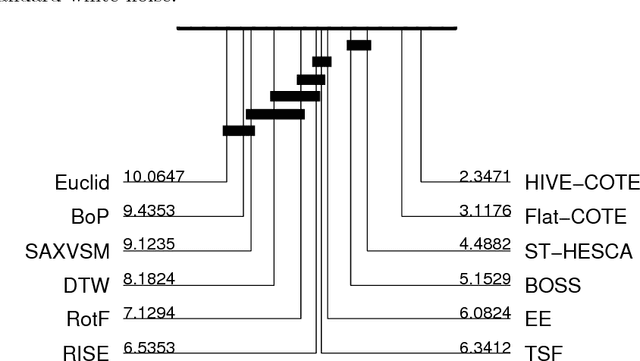
A family of algorithms for time series classification (TSC) involve running a sliding window across each series, discretising the window to form a word, forming a histogram of word counts over the dictionary, then constructing a classifier on the histograms. A recent evaluation of two of this type of algorithm, Bag of Patterns (BOP) and Bag of Symbolic Fourier Approximation Symbols (BOSS) found a significant difference in accuracy between these seemingly similar algorithms. We investigate this phenomenon by deconstructing the classifiers and measuring the relative importance of the four key components between BOP and BOSS. We find that whilst ensembling is a key component for both algorithms, the effect of the other components is mixed and more complex. We conclude that BOSS represents the state of the art for dictionary based TSC. Both BOP and BOSS can be classed as bag of words approaches. These are particularly popular in Computer Vision for tasks such as image classification. Converting approaches from vision requires careful engineering. We adapt three techniques used in Computer Vision for TSC: Scale Invariant Feature Transform; Spatial Pyramids; and Histrogram Intersection. We find that using Spatial Pyramids in conjunction with BOSS (SP) produces a significantly more accurate classifier. SP is significantly more accurate than standard benchmarks and the original BOSS algorithm. It is not significantly worse than the best shapelet based approach, and is only outperformed by HIVE-COTE, an ensemble that includes BOSS as a constituent module.