 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-ANCHOR: Federated Quantum Learning with ZNE-guided Correction
May 28, 2026Quantum Federated Learning (QFL) offers a promising framework to train quantum models across distributed clients while keeping data strictly local. Due to its simplicity and low communication overhead, Federated Averaging (FedAvg) is the standard aggregation choice in QFL literature. However, deploying QFL on practical hardware exposes a severe double-drift phenomenon: the global model is simultaneously derailed by client drift from non-IID data and hardware bias from noisy quantum gradient estimates. In this work, we first analyze the convergence of FedAvg under these realistic conditions, mathematically demonstrating that quantum hardware bias creates a persistent error floor that standard averaging cannot correct. To overcome this limitation, we propose Q-ANCHOR, a quantum-aware federated aggregation architecture that anchors server updates with zero-noise extrapolation while applying stateful client correction to suppress both client drift and hardware-induced bias. Our convergence theory proves that Q-ANCHOR successfully mitigates classical client drift while actively reducing the hardware-bias floor. Experimental results demonstrate that Q-ANCHOR achieves significantly more stable training than conventional FL baselines.
The Geometric Wall: Manifold Structure Predicts Layerwise Sparse Autoencoder Scaling Laws
May 11, 2026Sparse autoencoders (SAEs) operationalise the linear representation hypothesis: they reconstruct model activations as sparse linear combinations of interpretable dictionary atoms, on the implicit assumption that activation space is well approximated by a globally linear structure. Their reconstruction error varies sharply across layers in ways that existing scaling laws, fitted at single layers, do not explain. We argue that this variation is the empirical trace of a geometric mismatch: where the activation manifold is curved and its intrinsic dimension varies across layers, no sparse linear dictionary can match it uniformly, and the SAE's width-sparsity scaling becomes a layer-dependent function of manifold structure rather than a single universal law. We conduct the first cross-layer SAE scaling study, fitting and regressing on 844 residual-stream Gemma Scope SAE checkpoints across 68 layers of Gemma 2 2B and 9B. Stage 1 fits a per-layer scaling-law surface; Stage 2 regresses the fitted parameters and the derived per-layer width exponents on four layerwise geometric summaries. We find that manifold geometry predicts the per-layer width exponent in both models, and that the same regression coefficients learnt on one model predict the other model's per-layer exponents under cross-model transfer, indicating a transferable geometric law. At the showcase layers where richer width grids permit identification of the asymptotic floor, we find that the fitted floor tracks the layerwise geometric ordering: higher curvature and intrinsic dimension correspond to higher floor, consistent with the irreducible second-order residual that any sparse linear approximation of a curved manifold must leave behind. SAEs thus encounter not a finite-resource ceiling but a geometry-dependent wall, set by the manifold they are trying to reconstruct.
Learning-augmented robotic automation for real-world manufacturing
Apr 24, 2026Industrial robots are widely used in manufacturing, yet most manipulation still depends on fixed waypoint scripts that are brittle to environmental changes. Learning-based control offers a more adaptive alternative, but it remains unclear whether such methods, still mostly confined to laboratory demonstrations, can sustain hours of reliable operation, deliver consistent quality, and behave safely around people on a live production line. Here we present Learning-Augmented Robotic Automation, a hybrid system that integrates learned task controllers and a neural 3D safety monitor into conventional industrial workflows. We deployed the system on an electric-motor production line to automate deformable cable insertion and soldering under real manufacturing constraints, a step previously performed manually by human workers. With less than 20 min of real-world data per task, the system operated continuously for 5 h 10 min, producing 108 motors without physical fencing and achieving a 99.4% pass rate on product-level quality-control tests. It maintained near-human takt time while reducing variability in solder-joint quality and cycle time. These results establish a practical pathway for extending industrial automation with learning-based methods.
Q-ShiftDP: A Differentially Private Parameter-Shift Rule for Quantum Machine Learning
Feb 03, 2026Quantum Machine Learning (QML) promises significant computational advantages, but preserving training data privacy remains challenging. Classical approaches like differentially private stochastic gradient descent (DP-SGD) add noise to gradients but fail to exploit the unique properties of quantum gradient estimation. In this work, we introduce the Differentially Private Parameter-Shift Rule (Q-ShiftDP), the first privacy mechanism tailored to QML. By leveraging the inherent boundedness and stochasticity of quantum gradients computed via the parameter-shift rule, Q-ShiftDP enables tighter sensitivity analysis and reduces noise requirements. We combine carefully calibrated Gaussian noise with intrinsic quantum noise to provide formal privacy and utility guarantees, and show that harnessing quantum noise further improves the privacy-utility trade-off. Experiments on benchmark datasets demonstrate that Q-ShiftDP consistently outperforms classical DP methods in QML.
Counterfactual Explanations on Robust Perceptual Geodesics
Jan 26, 2026Latent-space optimization methods for counterfactual explanations - framed as minimal semantic perturbations that change model predictions - inherit the ambiguity of Wachter et al.'s objective: the choice of distance metric dictates whether perturbations are meaningful or adversarial. Existing approaches adopt flat or misaligned geometries, leading to off-manifold artifacts, semantic drift, or adversarial collapse. We introduce Perceptual Counterfactual Geodesics (PCG), a method that constructs counterfactuals by tracing geodesics under a perceptually Riemannian metric induced from robust vision features. This geometry aligns with human perception and penalizes brittle directions, enabling smooth, on-manifold, semantically valid transitions. Experiments on three vision datasets show that PCG outperforms baselines and reveals failure modes hidden under standard metrics.
DiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
May 29, 2025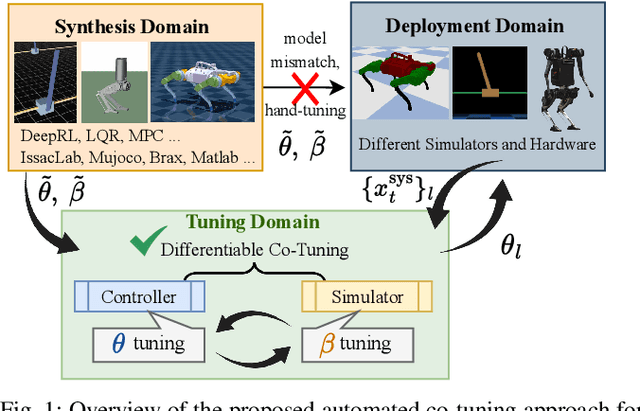
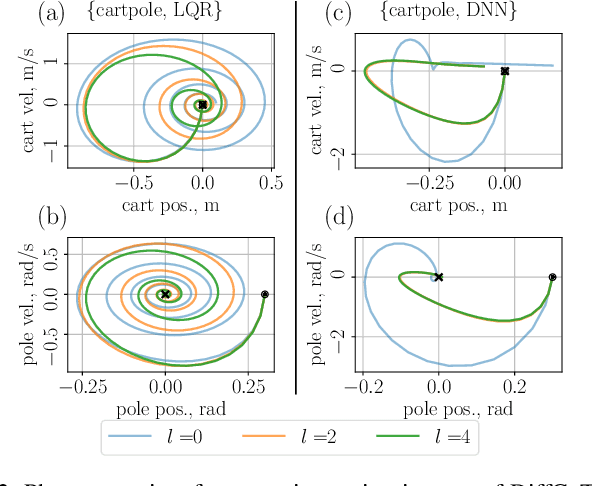
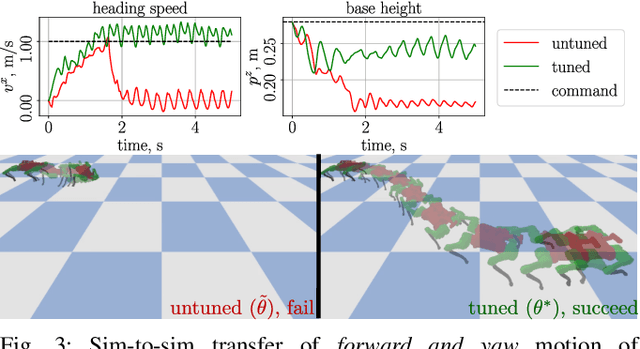
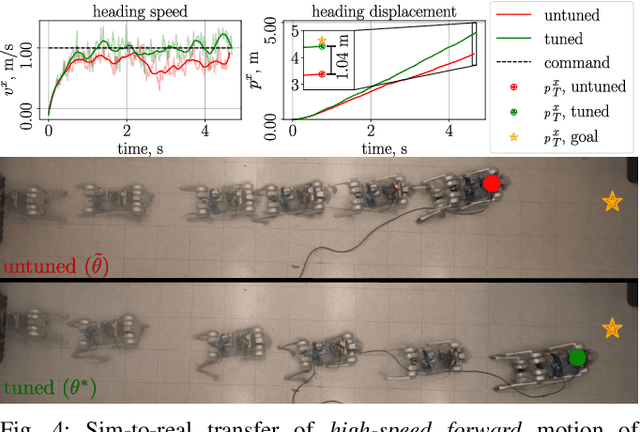
The deployment of robot controllers is hindered by modeling discrepancies due to necessary simplifications for computational tractability or inaccuracies in data-generating simulators. Such discrepancies typically require ad-hoc tuning to meet the desired performance, thereby ensuring successful transfer to a target domain. We propose a framework for automated, gradient-based tuning to enhance performance in the deployment domain by leveraging differentiable simulators. Our method collects rollouts in an iterative manner to co-tune the simulator and controller parameters, enabling systematic transfer within a few trials in the deployment domain. Specifically, we formulate multi-step objectives for tuning and employ alternating optimization to effectively adapt the controller to the deployment domain. The scalability of our framework is demonstrated by co-tuning model-based and learning-based controllers of arbitrary complexity for tasks ranging from low-dimensional cart-pole stabilization to high-dimensional quadruped and biped tracking, showing performance improvements across different deployment domains.
Reduce Computational Cost In Deep Reinforcement Learning Via Randomized Policy Learning
May 25, 2025Recent advancements in reinforcement learning (RL) have leveraged neural networks to achieve state-of-the-art performance across various control tasks. However, these successes often come at the cost of significant computational resources, as training deep neural networks requires substantial time and data. In this paper, we introduce an actor-critic algorithm that utilizes randomized neural networks to drastically reduce computational costs while maintaining strong performance. Despite its simple architecture, our method effectively solves a range of control problems, including the locomotion control of a highly dynamic 12-motor quadruped robot, and achieves results comparable to leading algorithms such as Proximal Policy Optimization (PPO). Notably, our approach does not outperform other algorithms in terms of sample efficnency but rather in terms of wall-clock training time. That is, although our algorithm requires more timesteps to converge to an optimal policy, the actual time required for training turns out to be lower.
One-Layer Transformers are Provably Optimal for In-context Reasoning and Distributional Association Learning in Next-Token Prediction Tasks
May 21, 2025We study the approximation capabilities and on-convergence behaviors of one-layer transformers on the noiseless and noisy in-context reasoning of next-token prediction. Existing theoretical results focus on understanding the in-context reasoning behaviors for either the first gradient step or when the number of samples is infinite. Furthermore, no convergence rates nor generalization abilities were known. Our work addresses these gaps by showing that there exists a class of one-layer transformers that are provably Bayes-optimal with both linear and ReLU attention. When being trained with gradient descent, we show via a finite-sample analysis that the expected loss of these transformers converges at linear rate to the Bayes risk. Moreover, we prove that the trained models generalize to unseen samples as well as exhibit learning behaviors that were empirically observed in previous works. Our theoretical findings are further supported by extensive empirical validations.
Multimodal Integrated Knowledge Transfer to Large Language Models through Preference Optimization with Biomedical Applications
May 09, 2025The scarcity of high-quality multimodal biomedical data limits the ability to effectively fine-tune pretrained Large Language Models (LLMs) for specialized biomedical tasks. To address this challenge, we introduce MINT (Multimodal Integrated kNowledge Transfer), a framework that aligns unimodal large decoder models with domain-specific decision patterns from multimodal biomedical data through preference optimization. While MINT supports different optimization techniques, we primarily implement it with the Odds Ratio Preference Optimization (ORPO) framework as its backbone. This strategy enables the aligned LLMs to perform predictive tasks using text-only or image-only inputs while retaining knowledge learnt from multimodal data. MINT leverages an upstream multimodal machine learning (MML) model trained on high-quality multimodal data to transfer domain-specific insights to downstream text-only or image-only LLMs. We demonstrate its effectiveness through two key applications: (1) Rare genetic disease prediction from texts, where MINT uses a multimodal encoder model, trained on facial photos and clinical notes, to generate a preference dataset for aligning a lightweight Llama 3.2-3B-Instruct. Despite relying on text input only, the MINT-derived model outperforms models trained with SFT, RAG, or DPO, and even outperforms Llama 3.1-405B-Instruct. (2) Tissue type classification using cell nucleus images, where MINT uses a vision-language foundation model as the preference generator, containing knowledge learnt from both text and histopathological images to align downstream image-only models. The resulting MINT-derived model significantly improves the performance of Llama 3.2-Vision-11B-Instruct on tissue type classification. In summary, MINT provides an effective strategy to align unimodal LLMs with high-quality multimodal expertise through preference optimization.
HDC: Hierarchical Distillation for Multi-level Noisy Consistency in Semi-Supervised Fetal Ultrasound Segmentation
Apr 14, 2025Transvaginal ultrasound is a critical imaging modality for evaluating cervical anatomy and detecting physiological changes. However, accurate segmentation of cervical structures remains challenging due to low contrast, shadow artifacts, and fuzzy boundaries. While convolutional neural networks (CNNs) have shown promising results in medical image segmentation, their performance is often limited by the need for large-scale annotated datasets - an impractical requirement in clinical ultrasound imaging. Semi-supervised learning (SSL) offers a compelling solution by leveraging unlabeled data, but existing teacher-student frameworks often suffer from confirmation bias and high computational costs. We propose HDC, a novel semi-supervised segmentation framework that integrates Hierarchical Distillation and Consistency learning within a multi-level noise mean-teacher framework. Unlike conventional approaches that rely solely on pseudo-labeling, we introduce a hierarchical distillation mechanism that guides feature-level learning via two novel objectives: (1) Correlation Guidance Loss to align feature representations between the teacher and main student branch, and (2) Mutual Information Loss to stabilize representations between the main and noisy student branches. Our framework reduces model complexity while improving generalization. Extensive experiments on two fetal ultrasound datasets, FUGC and PSFH, demonstrate that our method achieves competitive performance with significantly lower computational overhead than existing multi-teacher models.