 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CLeaRForecast: Contrastive Learning of High-Purity Representations for Time Series Forecasting
Dec 10, 2023
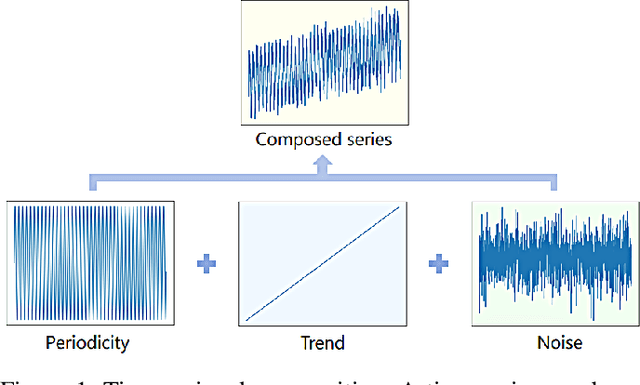
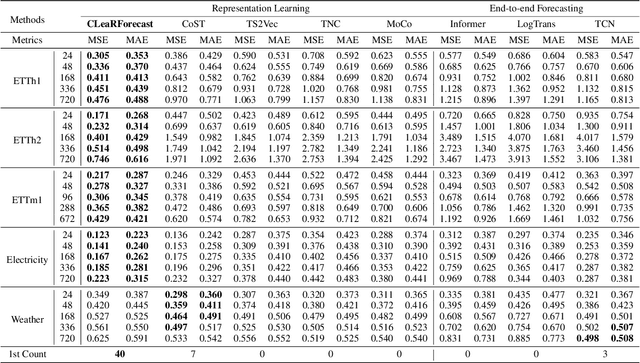
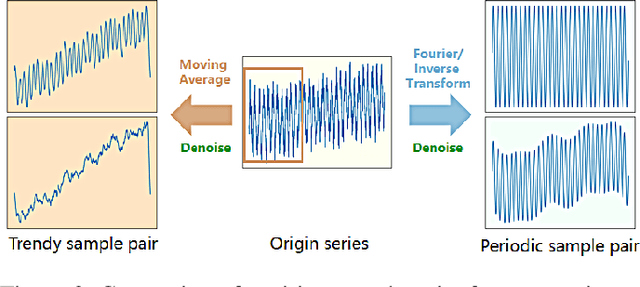
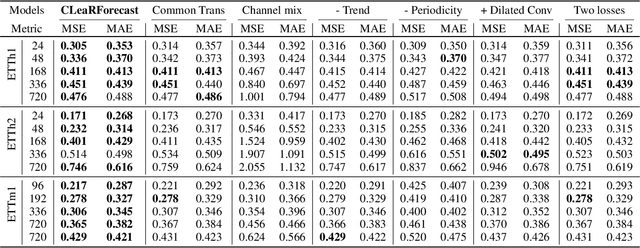
Time series forecasting (TSF) holds significant importance in modern society, spanning numerous domains. Previous representation learning-based TSF algorithms typically embrace a contrastive learning paradigm featuring segregated trend-periodicity representations. Yet, these methodologies disregard the inherent high-impact noise embedded within time series data, resulting in representation inaccuracies and seriously demoting the forecasting performance. To address this issue, we propose CLeaRForecast, a novel contrastive learning framework to learn high-purity time series representations with proposed sample, feature, and architecture purifying methods. More specifically, to avoid more noise adding caused by the transformations of original samples (series), transformations are respectively applied for trendy and periodic parts to provide better positive samples with obviously less noise. Moreover, we introduce a channel independent training manner to mitigate noise originating from unrelated variables in the multivariate series. By employing a streamlined deep-learning backbone and a comprehensive global contrastive loss function, we prevent noise introduction due to redundant or uneven learning of periodicity and trend. Experimental results show the superior performance of CLeaRForecast in various downstream TSF tasks.
Graph Learning-based Fleet Scheduling for Urban Air Mobility under Operational Constraints, Varying Demand & Uncertainties
Jan 09, 2024This paper develops a graph reinforcement learning approach to online planning of the schedule and destinations of electric aircraft that comprise an urban air mobility (UAM) fleet operating across multiple vertiports. This fleet scheduling problem is formulated to consider time-varying demand, constraints related to vertiport capacity, aircraft capacity and airspace safety guidelines, uncertainties related to take-off delay, weather-induced route closures, and unanticipated aircraft downtime. Collectively, such a formulation presents greater complexity, and potentially increased realism, than in existing UAM fleet planning implementations. To address these complexities, a new policy architecture is constructed, primary components of which include: graph capsule conv-nets for encoding vertiport and aircraft-fleet states both abstracted as graphs; transformer layers encoding time series information on demand and passenger fare; and a Multi-head Attention-based decoder that uses the encoded information to compute the probability of selecting each available destination for an aircraft. Trained with Proximal Policy Optimization, this policy architecture shows significantly better performance in terms of daily averaged profits on unseen test scenarios involving 8 vertiports and 40 aircraft, when compared to a random baseline and genetic algorithm-derived optimal solutions, while being nearly 1000 times faster in execution than the latter.
T-PRIME: Transformer-based Protocol Identification for Machine-learning at the Edge
Jan 09, 2024Spectrum sharing allows different protocols of the same standard (e.g., 802.11 family) or different standards (e.g., LTE and DVB) to coexist in overlapping frequency bands. As this paradigm continues to spread, wireless systems must also evolve to identify active transmitters and unauthorized waveforms in real time under intentional distortion of preambles, extremely low signal-to-noise ratios and challenging channel conditions. We overcome limitations of correlation-based preamble matching methods in such conditions through the design of T-PRIME: a Transformer-based machine learning approach. T-PRIME learns the structural design of transmitted frames through its attention mechanism, looking at sequence patterns that go beyond the preamble alone. The paper makes three contributions: First, it compares Transformer models and demonstrates their superiority over traditional methods and state-of-the-art neural networks. Second, it rigorously analyzes T-PRIME's real-time feasibility on DeepWave's AIR-T platform. Third, it utilizes an extensive 66 GB dataset of over-the-air (OTA) WiFi transmissions for training, which is released along with the code for community use. Results reveal nearly perfect (i.e. $>98\%$) classification accuracy under simulated scenarios, showing $100\%$ detection improvement over legacy methods in low SNR ranges, $97\%$ classification accuracy for OTA single-protocol transmissions and up to $75\%$ double-protocol classification accuracy in interference scenarios.
DeepSweep: Parallel and Scalable Spectrum Sensing via Convolutional Neural Networks
Jan 09, 2024Spectrum sensing is an essential component of modern wireless networks as it offers a tool to characterize spectrum usage and better utilize it. Deep Learning (DL) has become one of the most used techniques to perform spectrum sensing as they are capable of delivering high accuracy and reliability. However, current techniques suffer from ad-hoc implementations and high complexity, which makes them unsuited for practical deployment on wireless systems where flexibility and fast inference time are necessary to support real-time spectrum sensing. In this paper, we introduce DeepSweep, a novel DL-based transceiver design that allows scalable, accurate, and fast spectrum sensing while maintaining a high level of customizability to adapt its design to a broad range of application scenarios and use cases. DeepSweep is designed to be seamlessly integrated with well-established transceiver designs and leverages shallow convolutional neural network (CNN) to "sweep" the spectrum and process captured IQ samples fast and reliably without interrupting ongoing demodulation and decoding operations. DeepSweep reduces training and inference times by more than 2 times and 10 times respectively, achieves up to 98 percent accuracy in locating spectrum activity, and produces outputs in less than 1 ms, thus showing that DeepSweep can be used for a broad range of spectrum sensing applications and scenarios.
FourCastNeXt: Improving FourCastNet Training with Limited Compute
Jan 10, 2024Recently, the FourCastNet Neural Earth System Model (NESM) has shown impressive results on predicting various atmospheric variables, trained on the ERA5 reanalysis dataset. While FourCastNet enjoys quasi-linear time and memory complexity in sequence length compared to quadratic complexity in vanilla transformers, training FourCastNet on ERA5 from scratch still requires large amount of compute resources, which is expensive or even inaccessible to most researchers. In this work, we will show improved methods that can train FourCastNet using only 1% of the compute required by the baseline, while maintaining model performance or par or even better than the baseline.
A Data-driven Resilience Framework of Directionality Configuration based on Topological Credentials in Road Networks
Jan 14, 2024Roadway reconfiguration is a crucial aspect of transportation planning, aiming to enhance traffic flow, reduce congestion, and improve overall road network performance with existing infrastructure and resources. This paper presents a novel roadway reconfiguration technique by integrating optimization based Brute Force search approach and decision support framework to rank various roadway configurations for better performance. The proposed framework incorporates a multi-criteria decision analysis (MCDA) approach, combining input from generated scenarios during the optimization process. By utilizing data from optimization, the model identifies total betweenness centrality (TBC), system travel time (STT), and total link traffic flow (TLTF) as the most influential decision variables. The developed framework leverages graph theory to model the transportation network topology and apply network science metrics as well as stochastic user equilibrium traffic assignment to assess the impact of each roadway configuration on the overall network performance. To rank the roadway configurations, the framework employs machine learning algorithms, such as ridge regression, to determine the optimal weights for each criterion (i.e., TBC, STT, TLTF). Moreover, the network-based analysis ensures that the selected configurations not only optimize individual roadway segments but also enhance system-level efficiency, which is particularly helpful as the increasing frequency and intensity of natural disasters and other disruptive events underscore the critical need for resilient transportation networks. By integrating multi-criteria decision analysis, machine learning, and network science metrics, the proposed framework would enable transportation planners to make informed and data-driven decisions, leading to more sustainable, efficient, and resilient roadway configurations.
Generative AI-enabled Quantum Computing Networks and Intelligent Resource Allocation
Jan 13, 2024Quantum computing networks enable scalable collaboration and secure information exchange among multiple classical and quantum computing nodes while executing large-scale generative AI computation tasks and advanced quantum algorithms. Quantum computing networks overcome limitations such as the number of qubits and coherence time of entangled pairs and offer advantages for generative AI infrastructure, including enhanced noise reduction through distributed processing and improved scalability by connecting multiple quantum devices. However, efficient resource allocation in quantum computing networks is a critical challenge due to factors including qubit variability and network complexity. In this article, we propose an intelligent resource allocation framework for quantum computing networks to improve network scalability with minimized resource costs. To achieve scalability in quantum computing networks, we formulate the resource allocation problem as stochastic programming, accounting for the uncertain fidelities of qubits and entangled pairs. Furthermore, we introduce state-of-the-art reinforcement learning (RL) algorithms, from generative learning to quantum machine learning for optimal quantum resource allocation to resolve the proposed stochastic resource allocation problem efficiently. Finally, we optimize the resource allocation in heterogeneous quantum computing networks supporting quantum generative learning applications and propose a multi-agent RL-based algorithm to learn the optimal resource allocation policies without prior knowledge.
E^2-LLM: Efficient and Extreme Length Extension of Large Language Models
Jan 13, 2024Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. Existing long-context extension methods usually need additional training procedures to support corresponding long-context windows, where the long-context training data (e.g., 32k) is needed, and high GPU training costs are assumed. To address the aforementioned issues, we propose an Efficient and Extreme length extension method for Large Language Models, called E 2 -LLM, with only one training procedure and dramatically reduced computation cost, which also removes the need to collect long-context data. Concretely, first, the training data of our E 2 -LLM only requires a short length (e.g., 4k), which reduces the tuning cost greatly. Second, the training procedure on the short training context window is performed only once time, and we can support different evaluation context windows at inference. Third, in E 2 - LLM, based on RoPE position embeddings, we introduce two different augmentation methods on the scale and position index parameters for different samples in training. It aims to make the model more robust to the different relative differences when directly interpolating the arbitrary context length at inference. Comprehensive experimental results on multiple benchmark datasets demonstrate the effectiveness of our E 2 -LLM on challenging long-context tasks.
Artificial intelligence to automate the systematic review of scientific literature
Jan 13, 2024Artificial intelligence (AI) has acquired notorious relevance in modern computing as it effectively solves complex tasks traditionally done by humans. AI provides methods to represent and infer knowledge, efficiently manipulate texts and learn from vast amount of data. These characteristics are applicable in many activities that human find laborious or repetitive, as is the case of the analysis of scientific literature. Manually preparing and writing a systematic literature review (SLR) takes considerable time and effort, since it requires planning a strategy, conducting the literature search and analysis, and reporting the findings. Depending on the area under study, the number of papers retrieved can be of hundreds or thousands, meaning that filtering those relevant ones and extracting the key information becomes a costly and error-prone process. However, some of the involved tasks are repetitive and, therefore, subject to automation by means of AI. In this paper, we present a survey of AI techniques proposed in the last 15 years to help researchers conduct systematic analyses of scientific literature. We describe the tasks currently supported, the types of algorithms applied, and available tools proposed in 34 primary studies. This survey also provides a historical perspective of the evolution of the field and the role that humans can play in an increasingly automated SLR process.
* 25 pages, 3 figures, 1 table, journal paper
Data-driven Nonlinear Model Reduction using Koopman Theory: Integrated Control Form and NMPC Case Study
Jan 09, 2024We use Koopman theory for data-driven model reduction of nonlinear dynamical systems with controls. We propose generic model structures combining delay-coordinate encoding of measurements and full-state decoding to integrate reduced Koopman modeling and state estimation. We present a deep-learning approach to train the proposed models. A case study demonstrates that our approach provides accurate control models and enables real-time capable nonlinear model predictive control of a high-purity cryogenic distillation column.