 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LSTMs and Deep Residual Networks for Carbohydrate and Bolus Recommendations in Type 1 Diabetes Management
Mar 06, 2021
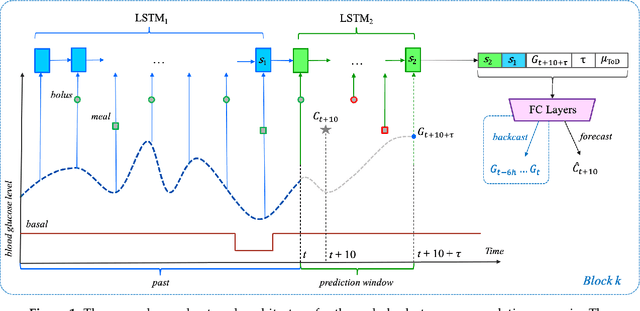
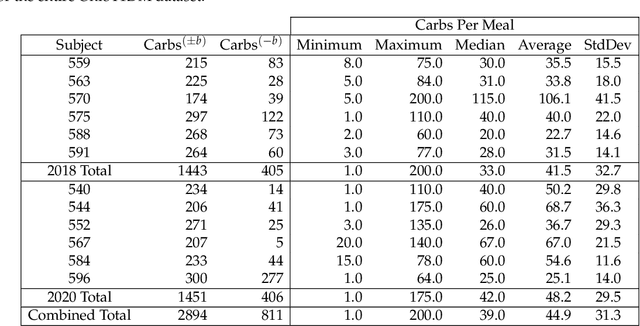
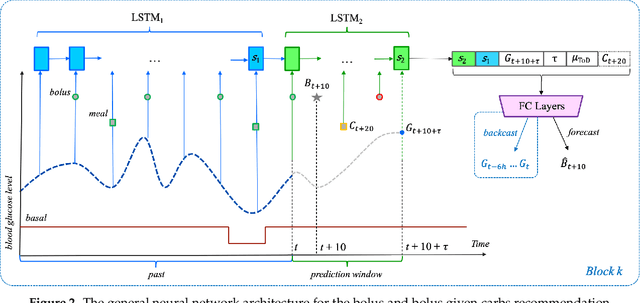
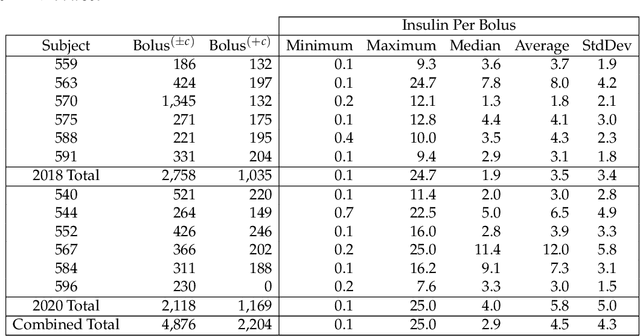
To avoid serious diabetic complications, people with type 1 diabetes must keep their blood glucose levels (BGLs) as close to normal as possible. Insulin dosages and carbohydrate consumption are important considerations in managing BGLs. Since the 1960s, models have been developed to forecast blood glucose levels based on the history of BGLs, insulin dosages, carbohydrate intake, and other physiological and lifestyle factors. Such predictions can be used to alert people of impending unsafe BGLs or to control insulin flow in an artificial pancreas. In past work, we have introduced an LSTM-based approach to blood glucose level prediction aimed at "what if" scenarios, in which people could enter foods they might eat or insulin amounts they might take and then see the effect on future BGLs. In this work, we invert the "what-if" scenario and introduce a similar architecture based on chaining two LSTMs that can be trained to make either insulin or carbohydrate recommendations aimed at reaching a desired BG level in the future. Leveraging a recent state-of-the-art model for time series forecasting, we then derive a novel architecture for the same recommendation task, in which the two LSTM chain is used as a repeating block inside a deep residual architecture. Experimental evaluations using real patient data from the OhioT1DM dataset show that the new integrated architecture compares favorably with the previous LSTM-based approach, substantially outperforming the baselines. The promising results suggest that this novel approach could potentially be of practical use to people with type 1 diabetes for self-management of BGLs.
Automatic image annotation base on Naive Bayes and Decision Tree classifiers using MPEG-7
Jan 27, 2021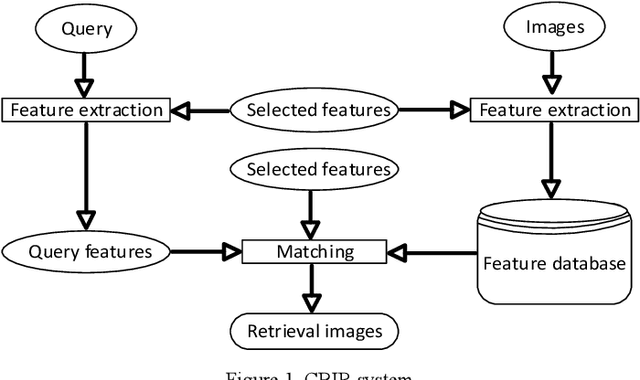


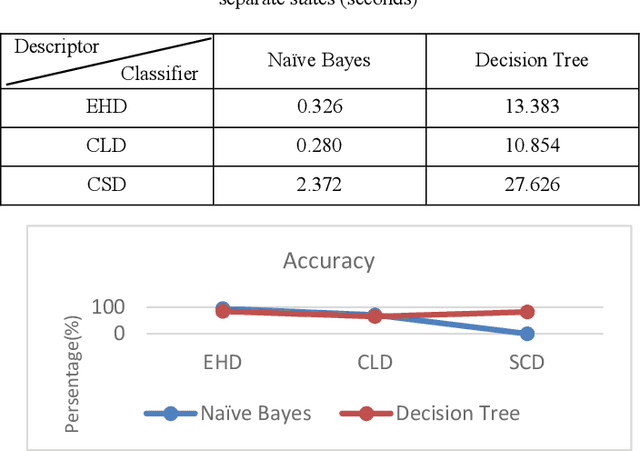
Recently it has become essential to search for and retrieve high-resolution and efficient images easily due to swift development of digital images, many present annotation algorithms facing a big challenge which is the variance for represent the image where high level represent image semantic and low level illustrate the features, this issue is known as semantic gab. This work has been used MPEG-7 standard to extract the features from the images, where the color feature was extracted by using Scalable Color Descriptor (SCD) and Color Layout Descriptor (CLD), whereas the texture feature was extracted by employing Edge Histogram Descriptor (EHD), the CLD produced high dimensionality feature vector therefore it is reduced by Principal Component Analysis (PCA). The features that have extracted by these three descriptors could be passing to the classifiers (Naive Bayes and Decision Tree) for training. Finally, they annotated the query image. In this study TUDarmstadt image bank had been used. The results of tests and comparative performance evaluation indicated better precision and executing time of Naive Bayes classification in comparison with Decision Tree classification.
MultiBodySync: Multi-Body Segmentation and Motion Estimation via 3D Scan Synchronization
Jan 17, 2021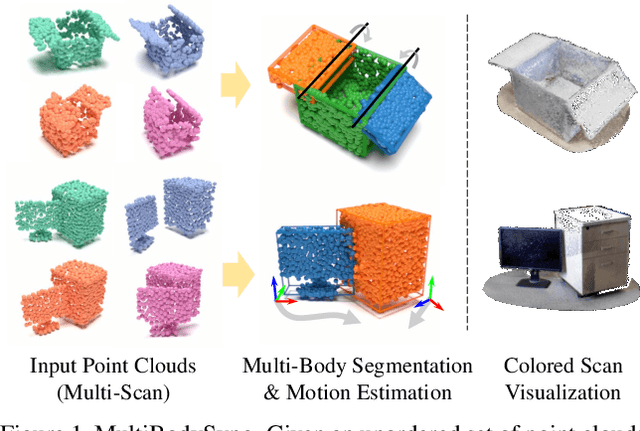
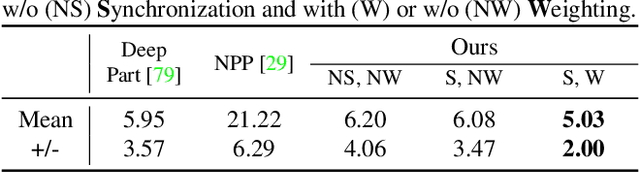
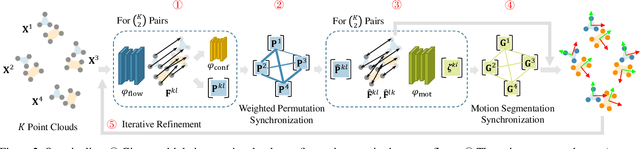
We present MultiBodySync, a novel, end-to-end trainable multi-body motion segmentation and rigid registration framework for multiple input 3D point clouds. The two non-trivial challenges posed by this multi-scan multibody setting that we investigate are: (i) guaranteeing correspondence and segmentation consistency across multiple input point clouds capturing different spatial arrangements of bodies or body parts; and (ii) obtaining robust motion-based rigid body segmentation applicable to novel object categories. We propose an approach to address these issues that incorporates spectral synchronization into an iterative deep declarative network, so as to simultaneously recover consistent correspondences as well as motion segmentation. At the same time, by explicitly disentangling the correspondence and motion segmentation estimation modules, we achieve strong generalizability across different object categories. Our extensive evaluations demonstrate that our method is effective on various datasets ranging from rigid parts in articulated objects to individually moving objects in a 3D scene, be it single-view or full point clouds.
Evolutionary Generative Adversarial Networks with Crossover Based Knowledge Distillation
Jan 27, 2021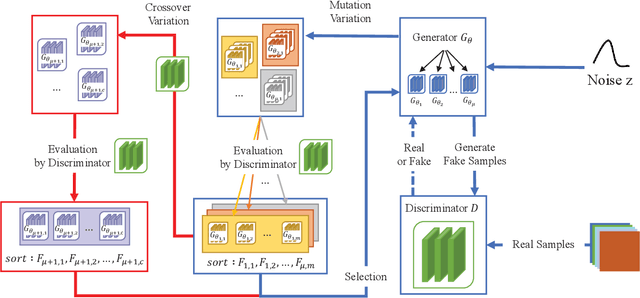
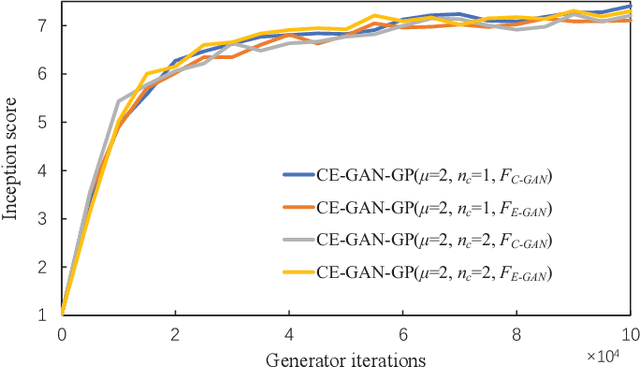
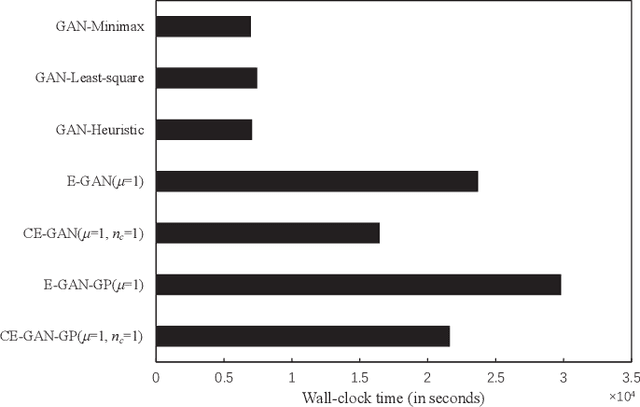
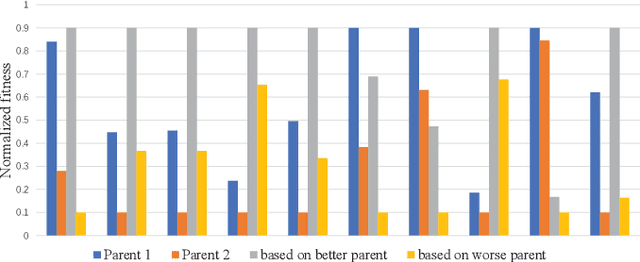
Generative Adversarial Networks (GAN) is an adversarial model, and it has been demonstrated to be effective for various generative tasks. However, GAN and its variants also suffer from many training problems, such as mode collapse and gradient vanish. In this paper, we firstly propose a general crossover operator, which can be widely applied to GANs using evolutionary strategies. Then we design an evolutionary GAN framework C-GAN based on it. And we combine the crossover operator with evolutionary generative adversarial networks (EGAN) to implement the evolutionary generative adversarial networks with crossover (CE-GAN). Under the premise that a variety of loss functions are used as mutation operators to generate mutation individuals, we evaluate the generated samples and allow the mutation individuals to learn experiences from the output in a knowledge distillation manner, imitating the best output outcome, resulting in better offspring. Then, we greedily selected the best offspring as parents for subsequent training using discriminator as evaluator. Experiments on real datasets demonstrate the effectiveness of CE-GAN and show that our method is competitive in terms of generated images quality and time efficiency.
Machine Learning-Based Automated Design Space Exploration for Autonomous Aerial Robots
Feb 05, 2021
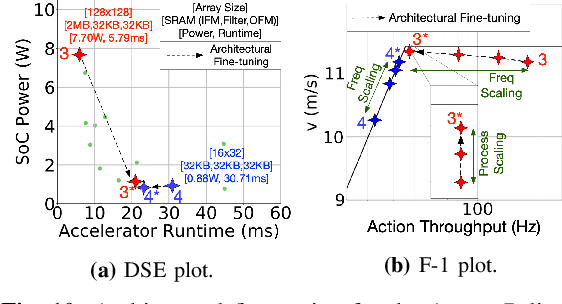
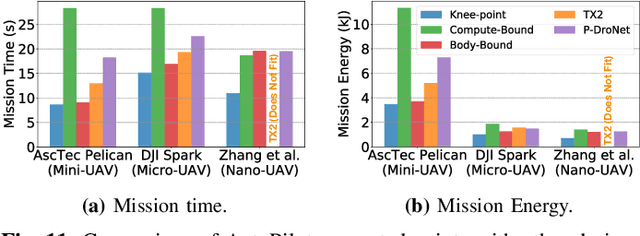

Building domain-specific architectures for autonomous aerial robots is challenging due to a lack of systematic methodology for designing onboard compute. We introduce a novel performance model called the F-1 roofline to help architects understand how to build a balanced computing system for autonomous aerial robots considering both its cyber (sensor rate, compute performance) and physical components (body-dynamics) that affect the performance of the machine. We use F-1 to characterize commonly used learning-based autonomy algorithms with onboard platforms to demonstrate the need for cyber-physical co-design. To navigate the cyber-physical design space automatically, we subsequently introduce AutoPilot. This push-button framework automates the co-design of cyber-physical components for aerial robots from a high-level specification guided by the F-1 model. AutoPilot uses Bayesian optimization to automatically co-design the autonomy algorithm and hardware accelerator while considering various cyber-physical parameters to generate an optimal design under different task level complexities for different robots and sensor framerates. As a result, designs generated by AutoPilot, on average, lower mission time up to 2x over baseline approaches, conserving battery energy.
Learning from Sparse Demonstrations
Aug 05, 2020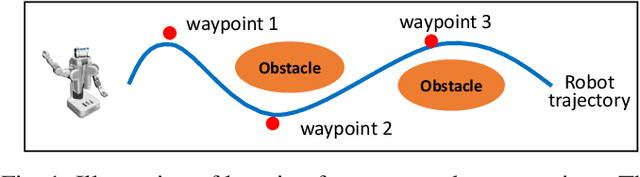
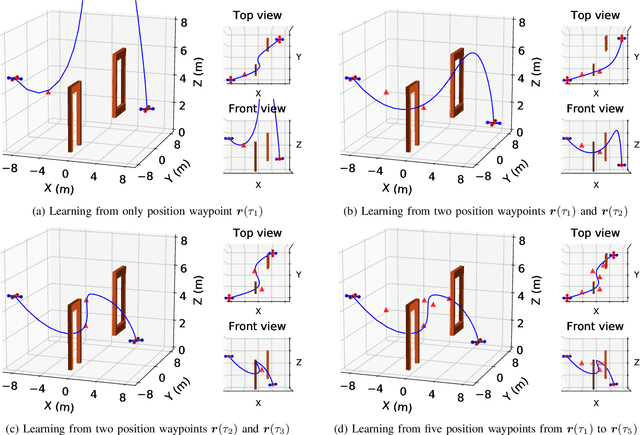
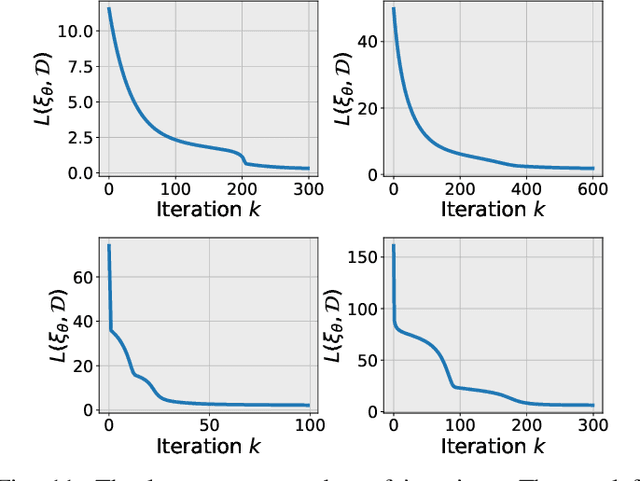
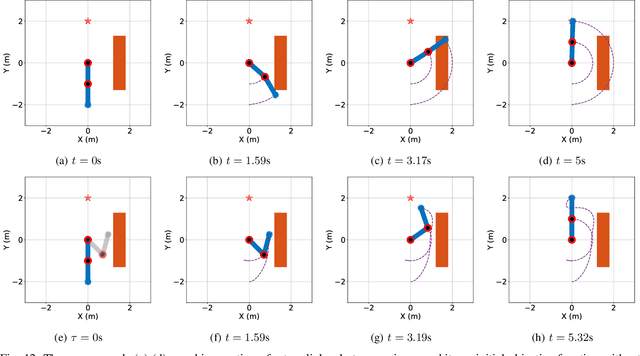
This paper proposes an approach which enables a robot to learn an objective function from sparse demonstrations of an expert. The demonstrations are given by a small number of sparse waypoints; the waypoints are desired outputs of the robot's trajectory at certain time instances, sparsely located within a demonstration time horizon. The duration of the expert's demonstration may be different from the actual duration of the robot's execution. The proposed method enables to jointly learn an objective function and a time-warping function such that the robot's reproduced trajectory has minimal distance to the sparse demonstration waypoints. Unlike existing inverse reinforcement learning techniques, the proposed approach uses the differential Pontryagin's maximum principle, which allows direct minimization of the distance between the robot's trajectory and the sparse demonstration waypoints and enables simultaneous learning of an objective function and a time-warping function. We demonstrate the effectiveness of the proposed approach in various simulated scenarios. We apply the method to learn motion planning/control of a 6-DoF maneuvering unmanned aerial vehicle (UAV) and a robot arm in environments with obstacles. The results show that a robot is able to learn a valid objective function to avoid obstacles with few demonstrated waypoints.
Beam-Guided TasNet: An Iterative Speech Separation Framework with Multi-Channel Output
Feb 20, 2021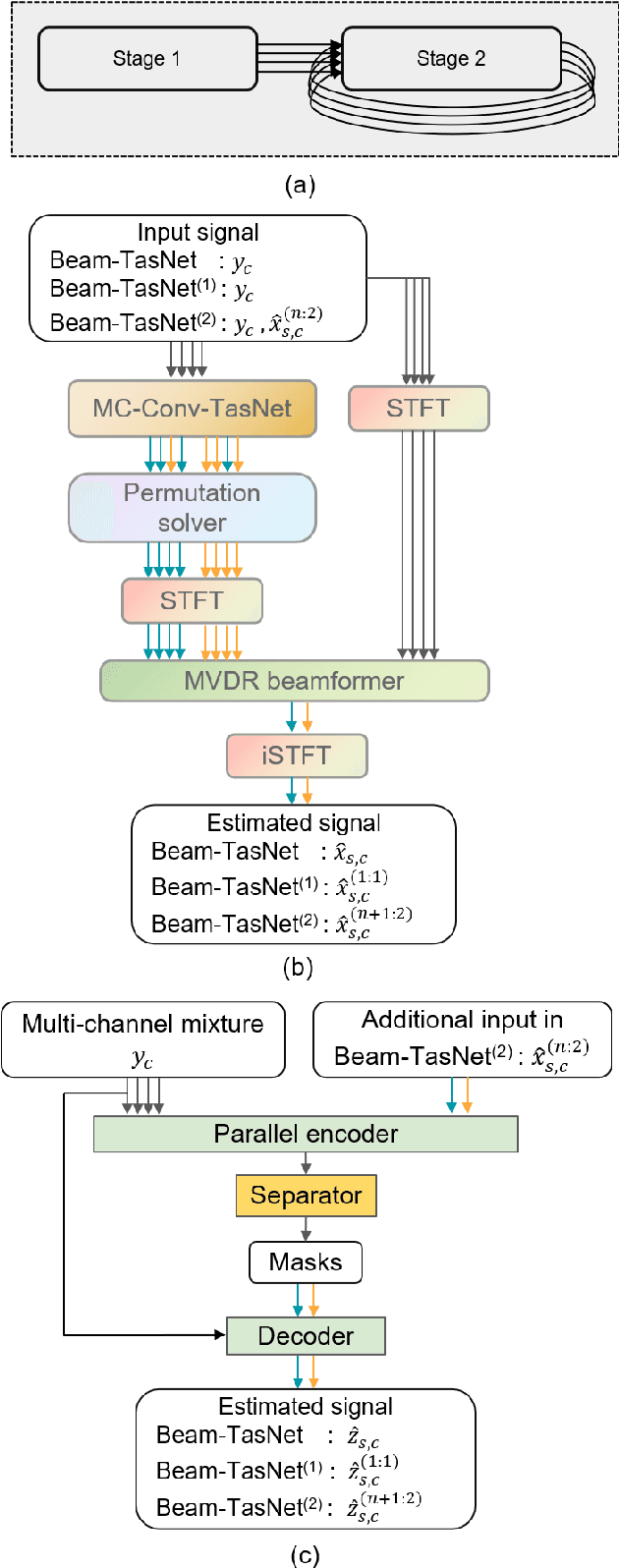
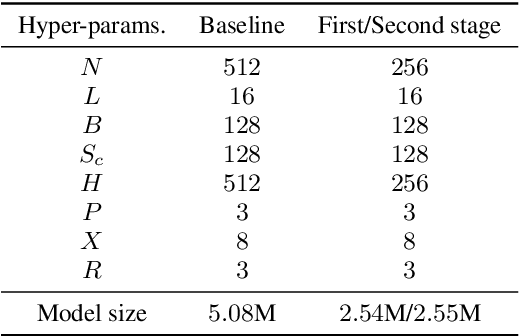
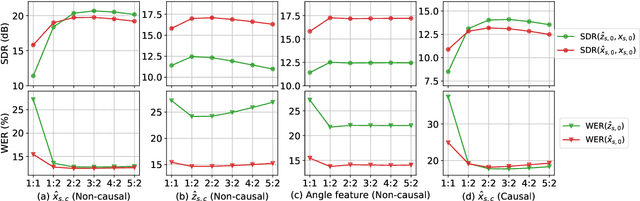
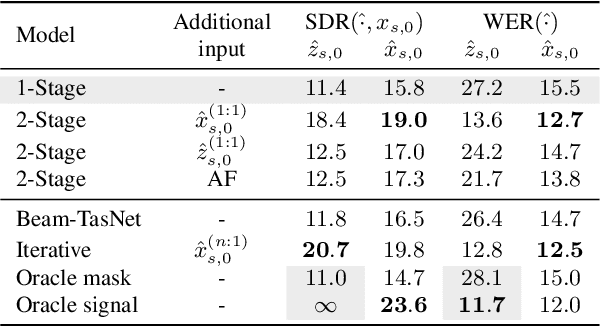
Time-domain audio separation network (TasNet) has achieved remarkable performance in blind source separation (BSS). Classic multi-channel speech processing framework employs signal estimation and beamforming. For example, Beam-TasNet links multi-channel convolutional TasNet (MC-Conv-TasNet) with minimum variance distortionless response (MVDR) beamforming, which leverages the strong modelling ability of data-driven MC-Conv-TasNet and boosts the performance of beamforming with an accurate estimation of speech statistics. Such integration can be viewed as a directed acyclic graph by accepting multi-channel input and generating multi-source output. In this letter, we design a "multi-channel input, multi-channel multi-source output" (MIMMO) speech separation system entitled "Beam-Guided TasNet", where MC-Conv-TasNet and MVDR can interact and promote each other more compactly under a directed cyclic flow. Specifically, the first stage uses Beam-TasNet to generate estimated single-speaker signals, which favours the separation in the second stage. The proposed framework facilitates iterative signal refinement with the guide of beamforming and seeks to reach the upper bound of the MVDR-based methods. Experimental results on the spatialized WSJ0-2MIX demonstrate that the Beam-Guided TasNet has achieved an SDR of 20.7 dB, which exceeded the baseline Beam-TasNet by 4.2 dB under the same model size and narrowed the gap with the oracle signal-based MVDR to 2.9 dB.
Towards Automatic Manipulation of Intra-cardiac Echocardiography Catheter
Sep 12, 2020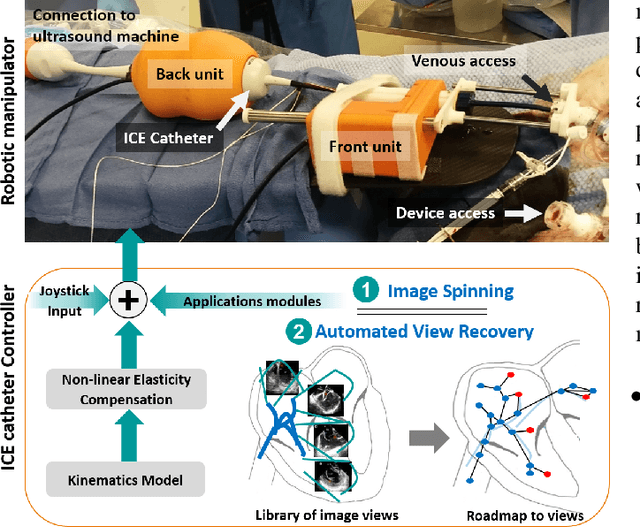
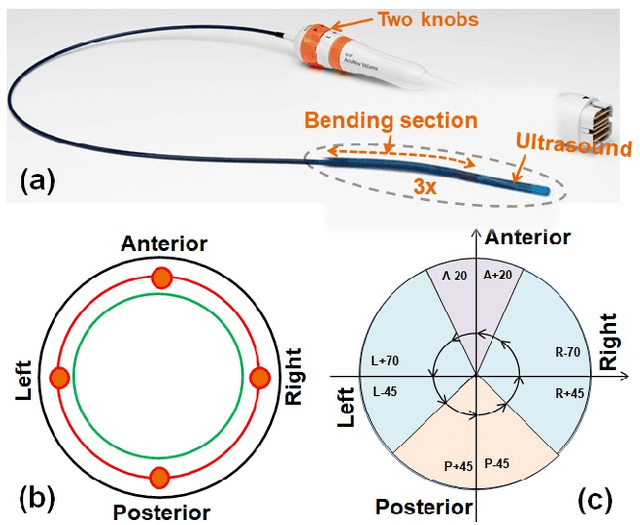
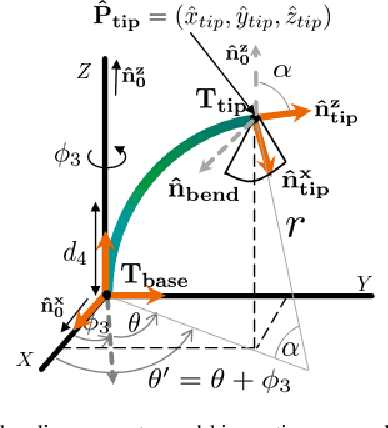
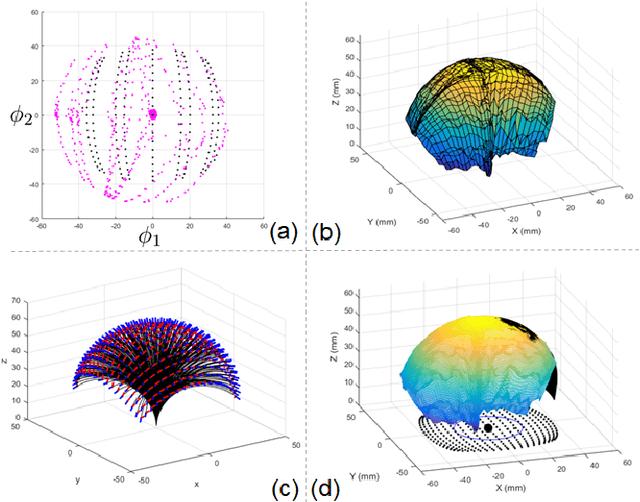
Intra-cardiac Echocardiography (ICE) has been evolving as a real-time imaging modality of choice for guiding electrophiosology and structural heart interventions. ICE provides real-time imaging of anatomy, catheters, and complications such as pericardial effusion or thrombus formation. However, there now exists a high cognitive demand on physicians with the increased reliance on intraprocedural imaging. In response, we present a robotic manipulator for AcuNav ICE catheters to alleviate the physician's burden and support applied methods for more automated. Herein, we introduce two methods towards these goals: (1) a data-driven method to compensate kinematic model errors due to non-linear elasticity in catheter bending, providing more precise robotic control and (2) an automated image recovery process that allows physicians to bookmark images during intervention and automatically return with the push of a button. To validate our error compensation method, we demonstrate a complex rotation of the ultrasound imaging plane evaluated on benchtop. Automated view recovery is validated by repeated imaging of landmarks on benchtop and in vivo experiments with position- and image-based analysis. Results support that a robotic-assist system for more autonomous ICE can provide a safe and efficient tool, potentially reducing the execution time and allowing more complex procedures to become common place.
Terahertz-Band Joint Ultra-Massive MIMO Radar-Communications: Model-Based and Model-Free Hybrid Beamforming
Feb 27, 2021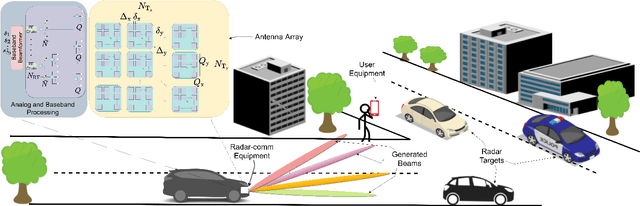
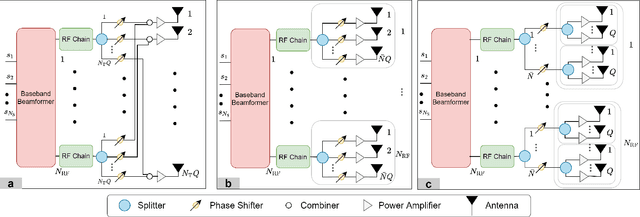
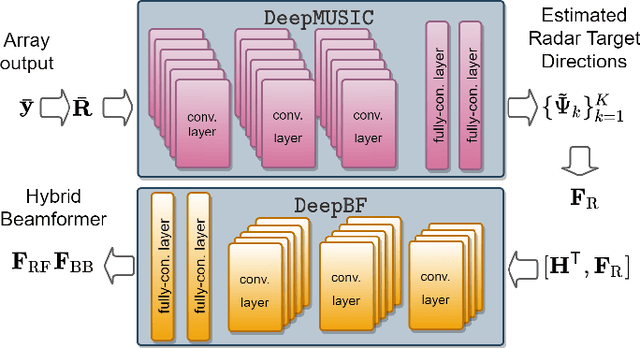
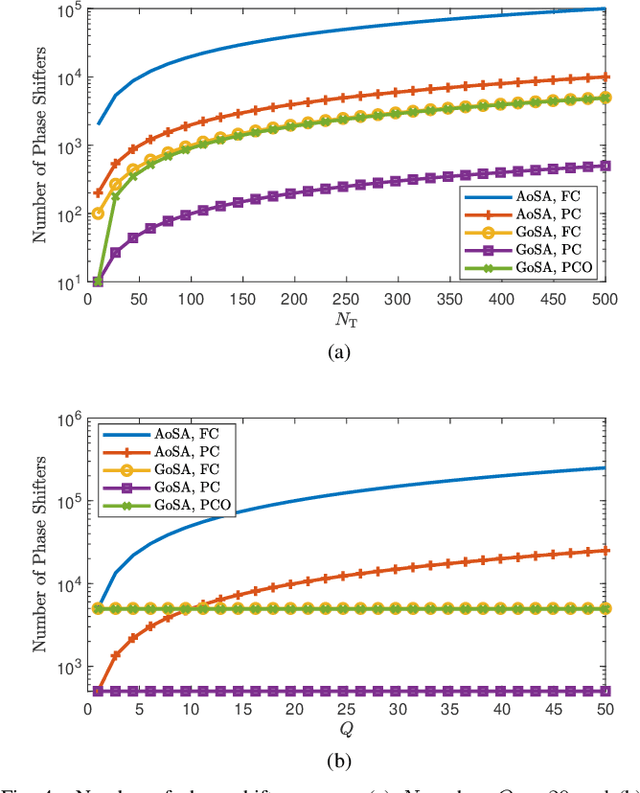
Wireless communications and sensing at terahertz (THz) band are increasingly investigated as promising short-range technologies because of the availability of high operational bandwidth at THz. In order to address the extremely high attenuation at THz, ultra-massive multiple-input multiple-output (UM-MIMO) antenna systems have been proposed for THz communications to compensate propagation losses. However, the cost and power associated with fully digital beamformers of these huge antenna arrays are prohibitive. In this paper, we develop THz hybrid beamformers based on both model-based and model-free techniques for a new group-of-subarrays (GoSA) UM-MIMO structure. Further, driven by the recent developments to save the spectrum, we propose beamformers for a joint UM-MIMO radar-communications system, wherein the base station serves multi-antenna user equipment (RX), and tracks radar targets by generating multiple beams toward both RX and the targets. We formulate the GoSA beamformer design as an optimization problem to provide a trade-off between the unconstrained communications beamformers and the desired radar beamformers. Additionally, our design also exploits second-order channel statistics so that an infrequent channel feedback from the RX is achieved with less channel overhead. To further decrease the UM-MIMO computational complexity and enhance robustness, we also implement deep learning solutions to the proposed model-based hybrid beamformers. Numerical experiments demonstrate that both techniques outperform the conventional approaches in terms of spectral efficiency and radar beampatterns, as well as exhibiting less hardware cost and computation time.
Reconstructing cellular automata rules from observations at nonconsecutive times
Dec 03, 2020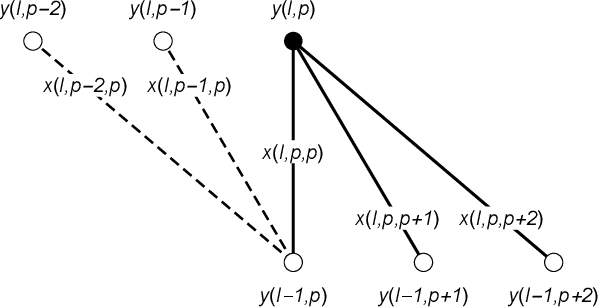

Recent experiments by Springer and Kenyon have shown that a deep neural network can be trained to predict the action of $t$ steps of Conway's Game of Life automaton given millions of examples of this action on random initial states. However, training was never completely successful for $t>1$, and even when successful, a reconstruction of the elementary rule ($t=1$) from $t>1$ data is not within the scope of what the neural network can deliver. We describe an alternative network-like method, based on constraint projections, where this is possible. From a single data item this method perfectly reconstructs not just the automaton rule but also the states in the time steps it did not see. For a unique reconstruction, the size of the initial state need only be large enough that it and the $t-1$ states it evolves into contain all possible automaton input patterns. We demonstrate the method on 1D binary cellular automata that take inputs from $n$ adjacent cells. The unknown rules in our experiments are not restricted to simple rules derived from a few linear functions on the inputs (as in Game of Life), but include all $2^{2^n}$ possible rules on $n$ inputs. Our results extend to $n=6$, for which exhaustive rule-search is not feasible. By relaxing translational symmetry in space and also time, our method is attractive as a platform for the learning of binary data, since the discreteness of the variables does not pose the same challenge it does for gradient-based methods.