 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeam-Guided TasNet: An Iterative Speech Separation Framework with Multi-Channel Output
Paper and Code
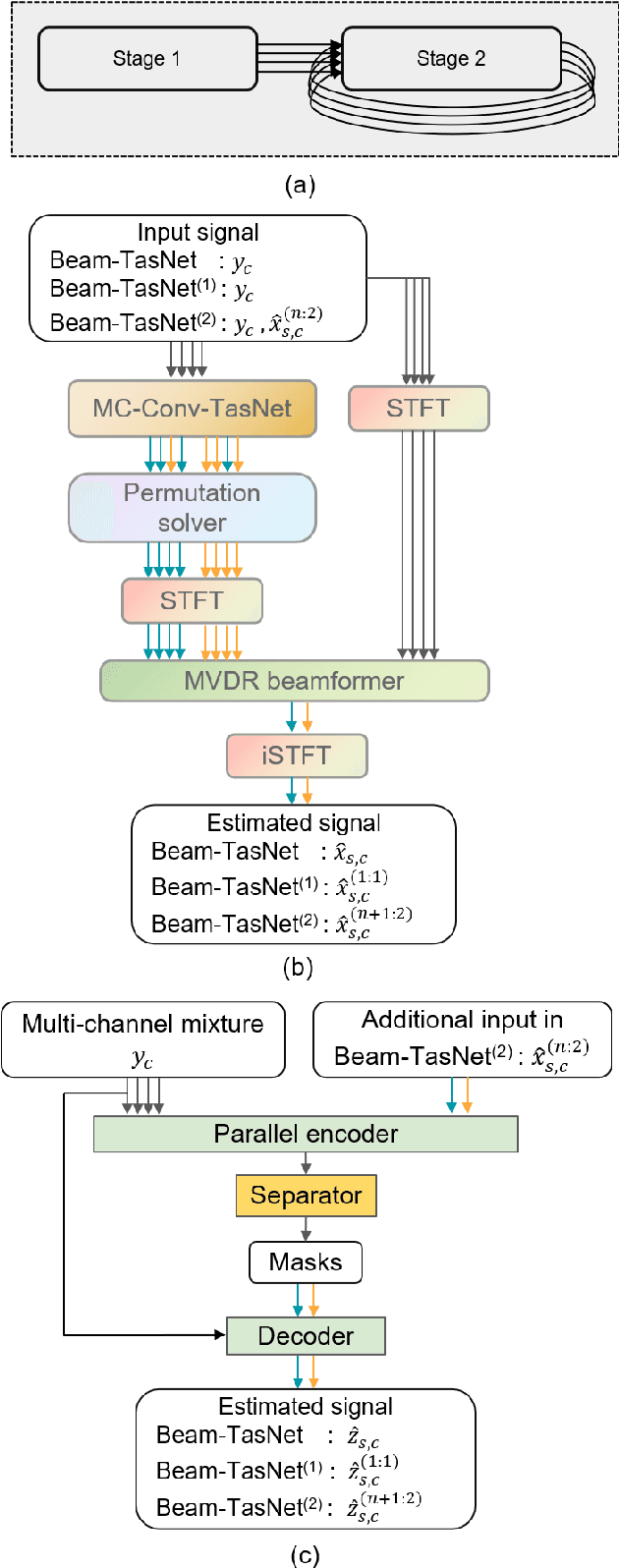
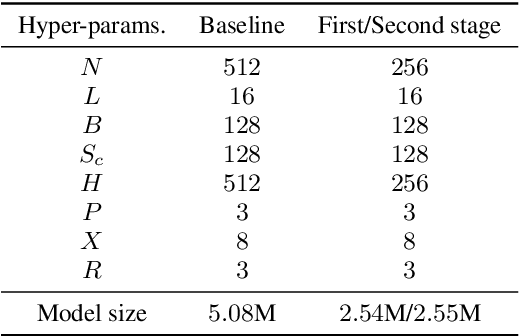
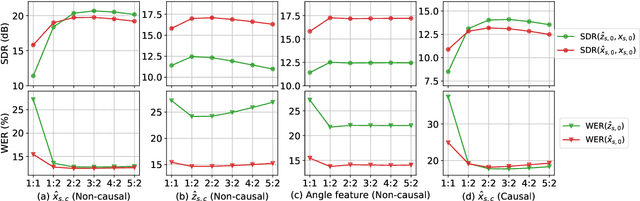
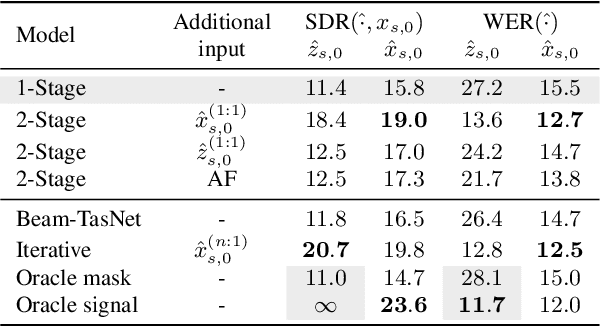
Time-domain audio separation network (TasNet) has achieved remarkable performance in blind source separation (BSS). Classic multi-channel speech processing framework employs signal estimation and beamforming. For example, Beam-TasNet links multi-channel convolutional TasNet (MC-Conv-TasNet) with minimum variance distortionless response (MVDR) beamforming, which leverages the strong modelling ability of data-driven MC-Conv-TasNet and boosts the performance of beamforming with an accurate estimation of speech statistics. Such integration can be viewed as a directed acyclic graph by accepting multi-channel input and generating multi-source output. In this letter, we design a "multi-channel input, multi-channel multi-source output" (MIMMO) speech separation system entitled "Beam-Guided TasNet", where MC-Conv-TasNet and MVDR can interact and promote each other more compactly under a directed cyclic flow. Specifically, the first stage uses Beam-TasNet to generate estimated single-speaker signals, which favours the separation in the second stage. The proposed framework facilitates iterative signal refinement with the guide of beamforming and seeks to reach the upper bound of the MVDR-based methods. Experimental results on the spatialized WSJ0-2MIX demonstrate that the Beam-Guided TasNet has achieved an SDR of 20.7 dB, which exceeded the baseline Beam-TasNet by 4.2 dB under the same model size and narrowed the gap with the oracle signal-based MVDR to 2.9 dB.