 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Solving a Multi-resource Partial-ordering Flexible Variant of the Job-shop Scheduling Problem with Hybrid ASP
Jan 26, 2021
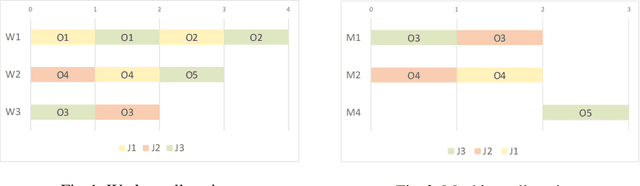
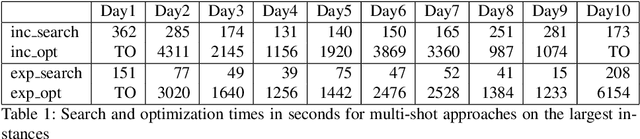
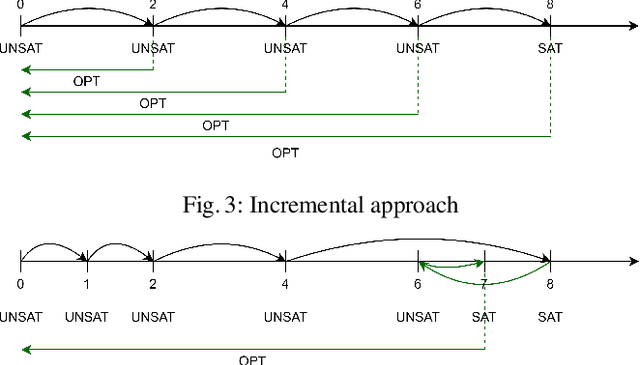
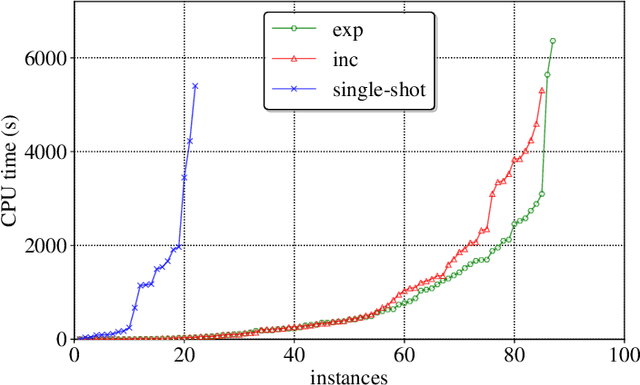
Many complex activities of production cycles, such as quality control or fault analysis, require highly experienced specialists to perform various operations on (semi)finished products using different tools. In practical scenarios, the selection of a next operation is complicated, since each expert has only a local view on the total set of operations to be performed. As a result, decisions made by the specialists are suboptimal and might cause significant costs. In this paper, we consider a Multi-resource Partial-ordering Flexible Job-shop Scheduling (MPF-JSS) problem where partially-ordered sequences of operations must be scheduled on multiple required resources, such as tools and specialists. The resources are flexible and can perform one or more operations depending on their properties. The problem is modeled using Answer Set Programming (ASP) in which the time assignments are efficiently done using Difference Logic. Moreover, we suggest two multi-shot solving strategies aiming at the identification of the time bounds allowing for a solution of the schedule optimization problem. Experiments conducted on a set of instances extracted from a medium-sized semiconductor fault analysis lab indicate that our approach can find schedules for 87 out of 91 considered real-world instances.
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 14, 2020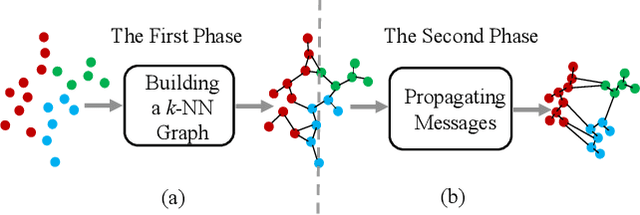

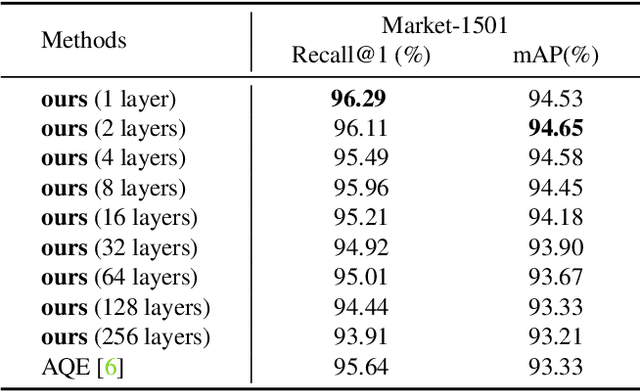
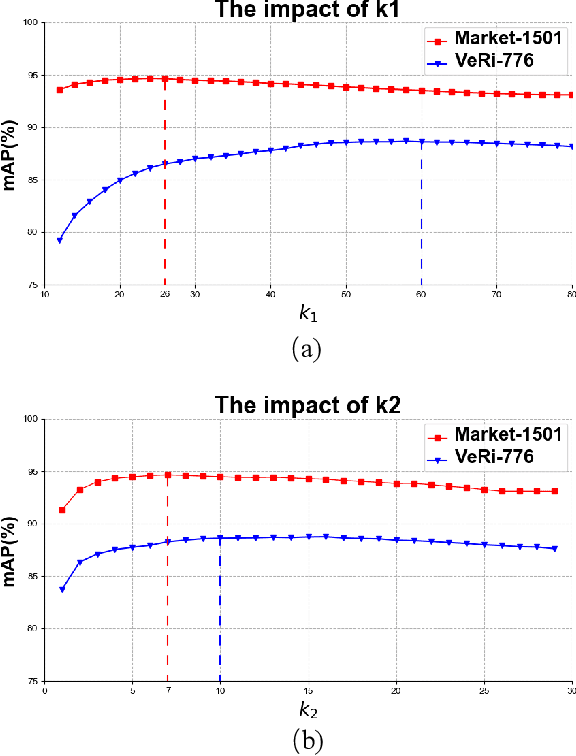
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.
Time-Sensitive Bandit Learning and Satisficing Thompson Sampling
Apr 28, 2017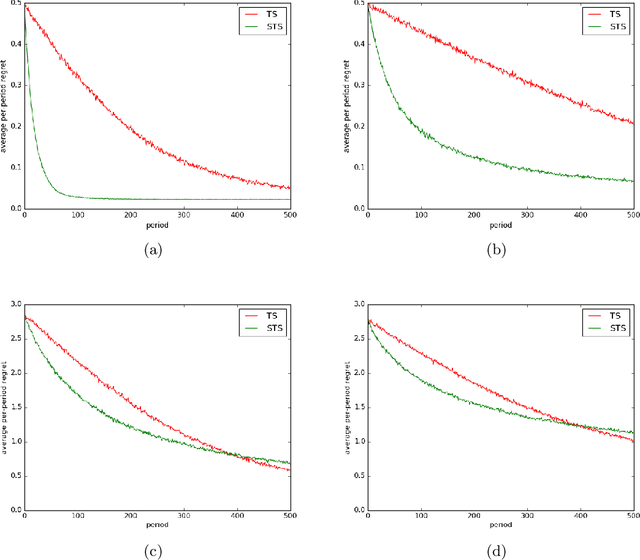
The literature on bandit learning and regret analysis has focused on contexts where the goal is to converge on an optimal action in a manner that limits exploration costs. One shortcoming imposed by this orientation is that it does not treat time preference in a coherent manner. Time preference plays an important role when the optimal action is costly to learn relative to near-optimal actions. This limitation has not only restricted the relevance of theoretical results but has also influenced the design of algorithms. Indeed, popular approaches such as Thompson sampling and UCB can fare poorly in such situations. In this paper, we consider discounted rather than cumulative regret, where a discount factor encodes time preference. We propose satisficing Thompson sampling -- a variation of Thompson sampling -- and establish a strong discounted regret bound for this new algorithm.
Real-time Egocentric Gesture Recognition on Mobile Head Mounted Displays
Dec 13, 2017
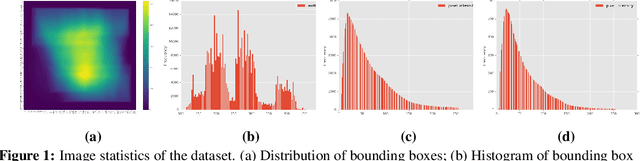
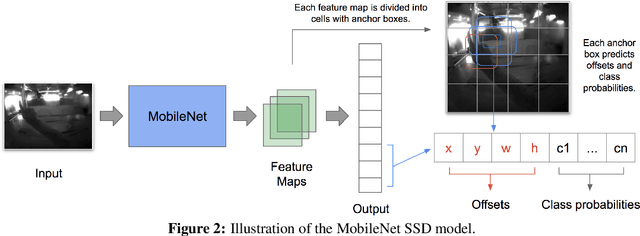
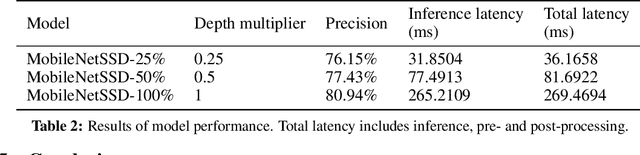
Mobile virtual reality (VR) head mounted displays (HMD) have become popular among consumers in recent years. In this work, we demonstrate real-time egocentric hand gesture detection and localization on mobile HMDs. Our main contributions are: 1) A novel mixed-reality data collection tool to automatic annotate bounding boxes and gesture labels; 2) The largest-to-date egocentric hand gesture and bounding box dataset with more than 400,000 annotated frames; 3) A neural network that runs real time on modern mobile CPUs, and achieves higher than 76% precision on gesture recognition across 8 classes.
Soft and subspace robust multivariate rank tests based on entropy regularized optimal transport
Mar 16, 2021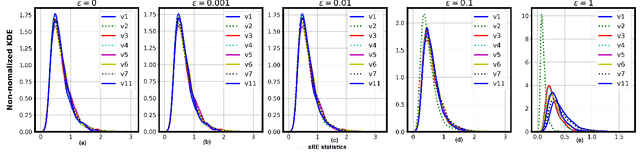
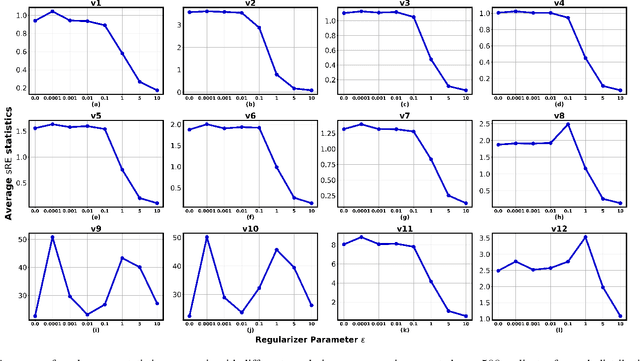
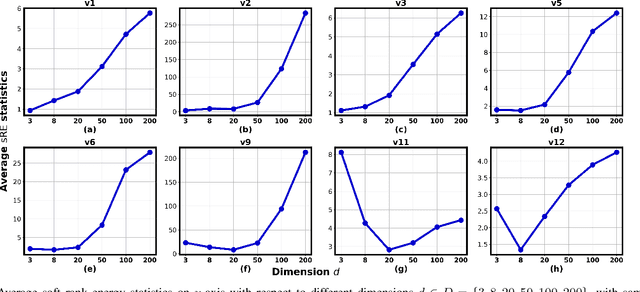
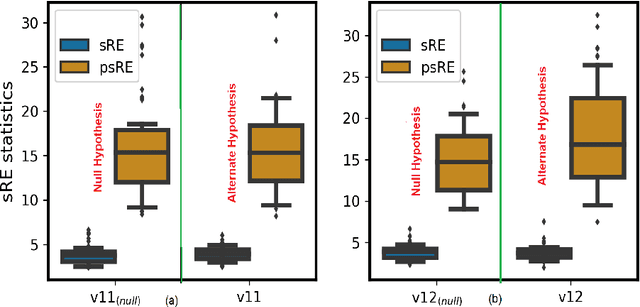
In this paper, we extend the recently proposed multivariate rank energy distance, based on the theory of optimal transport, for statistical testing of distributional similarity, to soft rank energy distance. Being differentiable, this in turn allows us to extend the rank energy to a subspace robust rank energy distance, dubbed Projected soft-Rank Energy distance, which can be computed via optimization over the Stiefel manifold. We show via experiments that using projected soft rank energy one can trade-off the detection power vs the false alarm via projections onto an appropriately selected low dimensional subspace. We also show the utility of the proposed tests on unsupervised change point detection in multivariate time series data. All codes are publicly available at the link provided in the experiment section.
Device-Cloud Collaborative Learning for Recommendation
Apr 14, 2021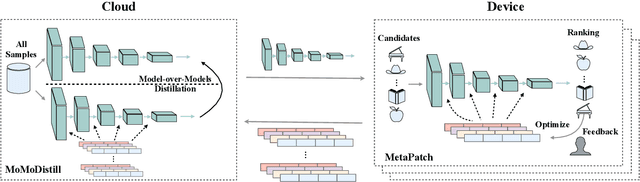
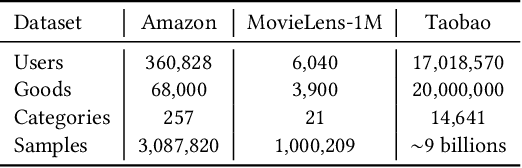
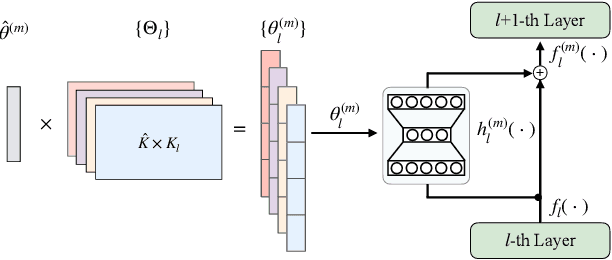
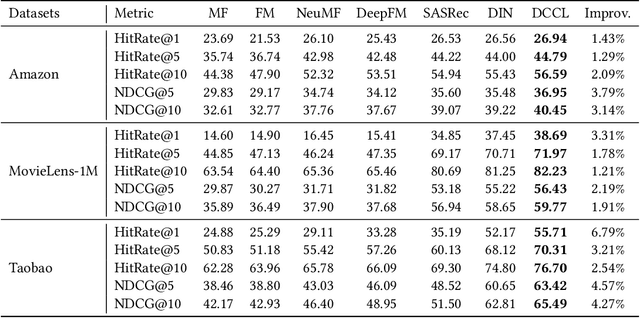
With the rapid development of storage and computing power on mobile devices, it becomes critical and popular to deploy models on devices to save onerous communication latencies and to capture real-time features. While quite a lot of works have explored to facilitate on-device learning and inference, most of them focus on dealing with response delay or privacy protection. Little has been done to model the collaboration between the device and the cloud modeling and benefit both sides jointly. To bridge this gap, we are among the first attempts to study the Device-Cloud Collaborative Learning (DCCL) framework. Specifically, we propose a novel MetaPatch learning approach on the device side to efficiently achieve "thousands of people with thousands of models" given a centralized cloud model. Then, with billions of updated personalized device models, we propose a "model-over-models" distillation algorithm, namely MoMoDistill, to update the centralized cloud model. Our extensive experiments over a range of datasets with different settings demonstrate the effectiveness of such collaboration on both cloud and device sides, especially its superiority in modeling long-tailed users.
Multi-Disease Detection in Retinal Imaging based on Ensembling Heterogeneous Deep Learning Models
Mar 26, 2021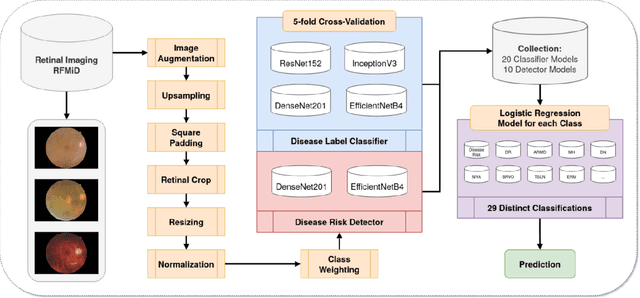
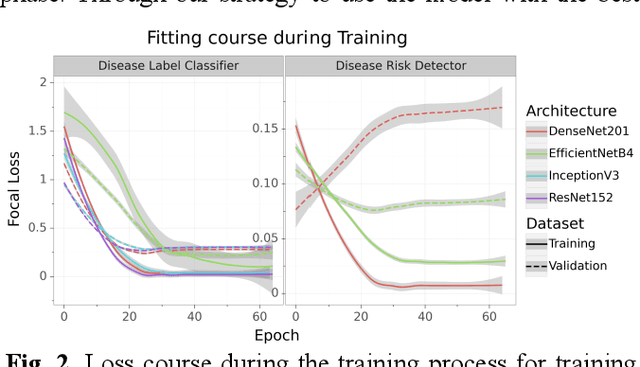
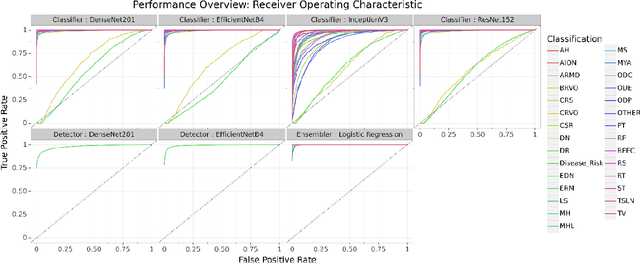
Preventable or undiagnosed visual impairment and blindness affect billion of people worldwide. Automated multi-disease detection models offer great potential to address this problem via clinical decision support in diagnosis. In this work, we proposed an innovative multi-disease detection pipeline for retinal imaging which utilizes ensemble learning to combine the predictive capabilities of several heterogeneous deep convolutional neural network models. Our pipeline includes state-of-the-art strategies like transfer learning, class weighting, real-time image augmentation and Focal loss utilization. Furthermore, we integrated ensemble learning techniques like heterogeneous deep learning models, bagging via 5-fold cross-validation and stacked logistic regression models. Through internal and external evaluation, we were able to validate and demonstrate high accuracy and reliability of our pipeline, as well as the comparability with other state-of-the-art pipelines for retinal disease prediction.
Estimation of Hurst Exponent in Self-similar Traffic Flows
Mar 31, 2021In this paper it presents, develops and discusses the existence of a process with long scope memory structure, representing of the independence between the degree of randomness of the traffic generated by the sources and flow pattern exhibited by the network. The process existence is presented in term of a new algorithmic that is a variant of the maximum likelihood estimator (MLE) of Whittle, for the calculation of the Hurst exponent (H) of self-similar stationary second order time series of the flows of the individual sources and their aggregation. Also, it is discussed the additional problems introduced by the phenomenon of the locality of the Hurst exponent, that appears when the traffic flows consist of diverse elements with different Hurst exponents. The instance is exposed with the intention of being considered as a new and alternative approach for modeling and simulating traffic in existing computer networks.
Peer Offloading with Delayed Feedback in Fog Networks
Nov 24, 2020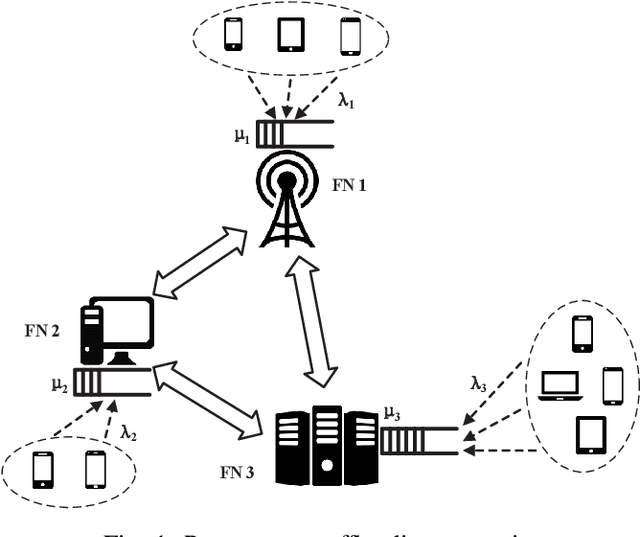
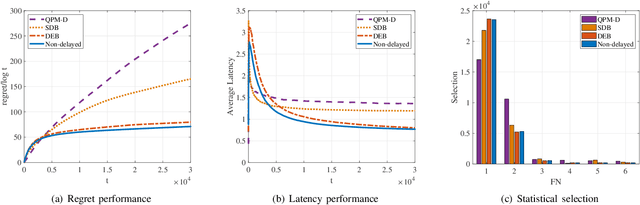
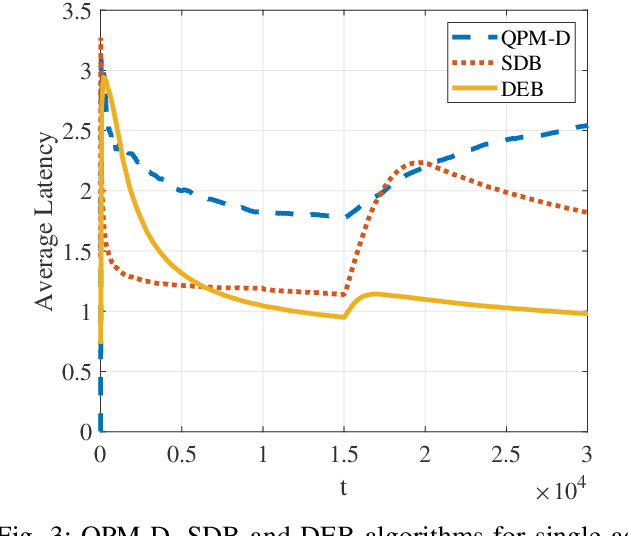
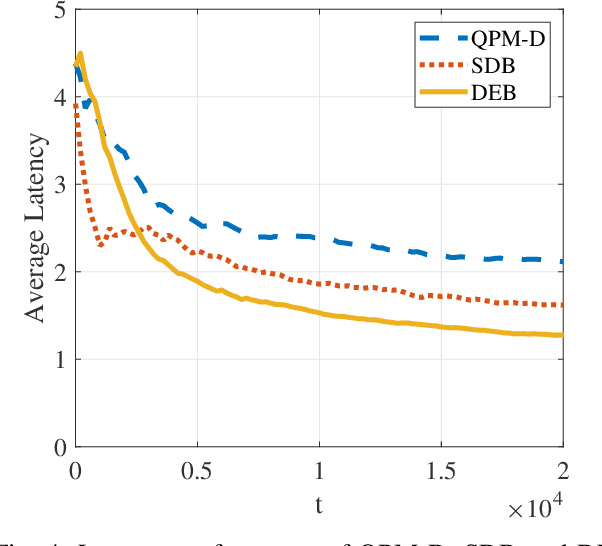
Comparing to cloud computing, fog computing performs computation and services at the edge of networks, thus relieving the computation burden of the data center and reducing the task latency of end devices. Computation latency is a crucial performance metric in fog computing, especially for real-time applications. In this paper, we study a peer computation offloading problem for a fog network with unknown dynamics. In this scenario, each fog node (FN) can offload their computation tasks to neighboring FNs in a time slot manner. The offloading latency, however, could not be fed back to the task dispatcher instantaneously due to the uncertainty of the processing time in peer FNs. Besides, peer competition occurs when different FNs offload tasks to one FN at the same time. To tackle the above difficulties, we model the computation offloading problem as a sequential FN selection problem with delayed information feedback. Using adversarial multi-arm bandit framework, we construct an online learning policy to deal with delayed information feedback. Different contention resolution approaches are considered to resolve peer competition. Performance analysis shows that the regret of the proposed algorithm, or the performance loss with suboptimal FN selections, achieves a sub-linear order, suggesting an optimal FN selection policy. In addition, we prove that the proposed strategy can result in a Nash equilibrium (NE) with all FNs playing the same policy. Simulation results validate the effectiveness of the proposed policy.
Unsupervised 3D Shape Completion through GAN Inversion
Apr 29, 2021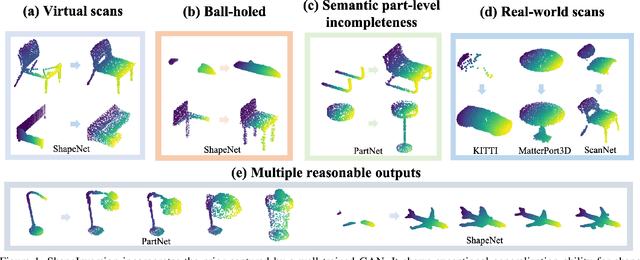
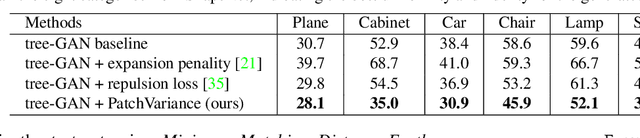
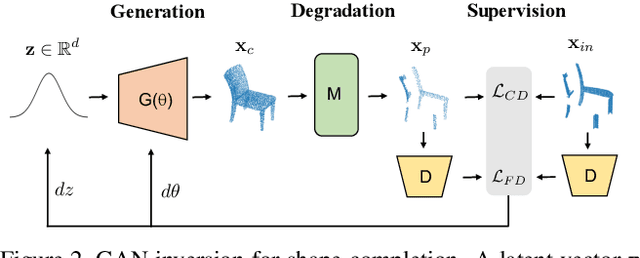

Most 3D shape completion approaches rely heavily on partial-complete shape pairs and learn in a fully supervised manner. Despite their impressive performances on in-domain data, when generalizing to partial shapes in other forms or real-world partial scans, they often obtain unsatisfactory results due to domain gaps. In contrast to previous fully supervised approaches, in this paper we present ShapeInversion, which introduces Generative Adversarial Network (GAN) inversion to shape completion for the first time. ShapeInversion uses a GAN pre-trained on complete shapes by searching for a latent code that gives a complete shape that best reconstructs the given partial input. In this way, ShapeInversion no longer needs paired training data, and is capable of incorporating the rich prior captured in a well-trained generative model. On the ShapeNet benchmark, the proposed ShapeInversion outperforms the SOTA unsupervised method, and is comparable with supervised methods that are learned using paired data. It also demonstrates remarkable generalization ability, giving robust results for real-world scans and partial inputs of various forms and incompleteness levels. Importantly, ShapeInversion naturally enables a series of additional abilities thanks to the involvement of a pre-trained GAN, such as producing multiple valid complete shapes for an ambiguous partial input, as well as shape manipulation and interpolation.