 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve and Optimize by Evolving Code
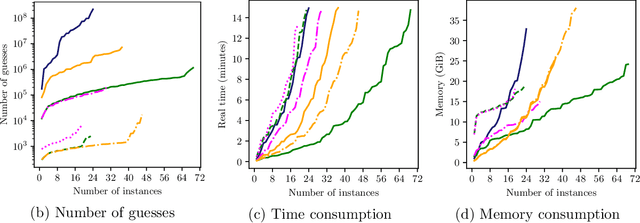
May 29, 2026Combinatorial and optimization problems are fundamental to many industrial AI applications. Solving large-scale real-world instances of such problems typically requires careful problem formalization, specialized solvers, and expert-designed heuristics. Thus, experts need to specify not only what solutions are, but also how they are derived. By introducing the tool CHECKMATE, we show that algorithm generation via code evolution represents a paradigm shift by eliminating the need to formulate the how. CHECKMATE solely relies on the what. Specifically, a formal specification ensures solutions' correctness and enables systematic performance evaluation of the generated programs, while a natural language description guides the evolutionary process. The effectiveness of our method is demonstrated on selected problems from two industrial domains: configuration and scheduling. In all cases, the evolved algorithms consistently outperform state-of-the-art solvers. This underscores the potential of formal methods in guiding code evolution for automatically solving complex real-world problems.
Managing Complex Failure Analysis Workflows with LLM-based Reasoning and Acting Agents
Jun 18, 2025Failure Analysis (FA) is a highly intricate and knowledge-intensive process. The integration of AI components within the computational infrastructure of FA labs has the potential to automate a variety of tasks, including the detection of non-conformities in images, the retrieval of analogous cases from diverse data sources, and the generation of reports from annotated images. However, as the number of deployed AI models increases, the challenge lies in orchestrating these components into cohesive and efficient workflows that seamlessly integrate with the FA process. This paper investigates the design and implementation of a Large Language Model (LLM)-based Planning Agent (LPA) to assist FA engineers in solving their analysis cases. The LPA integrates LLMs with advanced planning capabilities and external tool utilization, enabling autonomous processing of complex queries, retrieval of relevant data from external systems, and generation of human-readable responses. Evaluation results demonstrate the agent's operational effectiveness and reliability in supporting FA tasks.
Scalability of Reinforcement Learning Methods for Dispatching in Semiconductor Frontend Fabs: A Comparison of Open-Source Models with Real Industry Datasets
May 16, 2025Benchmark datasets are crucial for evaluating approaches to scheduling or dispatching in the semiconductor industry during the development and deployment phases. However, commonly used benchmark datasets like the Minifab or SMT2020 lack the complex details and constraints found in real-world scenarios. To mitigate this shortcoming, we compare open-source simulation models with a real industry dataset to evaluate how optimization methods scale with different levels of complexity. Specifically, we focus on Reinforcement Learning methods, performing optimization based on policy-gradient and Evolution Strategies. Our research provides insights into the effectiveness of these optimization methods and their applicability to realistic semiconductor frontend fab simulations. We show that our proposed Evolution Strategies-based method scales much better than a comparable policy-gradient-based approach. Moreover, we identify the selection and combination of relevant bottleneck tools to control by the agent as crucial for an efficient optimization. For the generalization across different loading scenarios and stochastic tool failure patterns, we achieve advantages when utilizing a diverse training dataset. While the overall approach is computationally expensive, it manages to scale well with the number of CPU cores used for training. For the real industry dataset, we achieve an improvement of up to 4% regarding tardiness and up to 1% regarding throughput. For the less complex open-source models Minifab and SMT2020, we observe double-digit percentage improvement in tardiness and single digit percentage improvement in throughput by use of Evolution Strategies.
An End-to-End Reinforcement Learning Approach for Job-Shop Scheduling Problems Based on Constraint Programming
Jun 09, 2023Constraint Programming (CP) is a declarative programming paradigm that allows for modeling and solving combinatorial optimization problems, such as the Job-Shop Scheduling Problem (JSSP). While CP solvers manage to find optimal or near-optimal solutions for small instances, they do not scale well to large ones, i.e., they require long computation times or yield low-quality solutions. Therefore, real-world scheduling applications often resort to fast, handcrafted, priority-based dispatching heuristics to find a good initial solution and then refine it using optimization methods. This paper proposes a novel end-to-end approach to solving scheduling problems by means of CP and Reinforcement Learning (RL). In contrast to previous RL methods, tailored for a given problem by including procedural simulation algorithms, complex feature engineering, or handcrafted reward functions, our neural-network architecture and training algorithm merely require a generic CP encoding of some scheduling problem along with a set of small instances. Our approach leverages existing CP solvers to train an agent learning a Priority Dispatching Rule (PDR) that generalizes well to large instances, even from separate datasets. We evaluate our method on seven JSSP datasets from the literature, showing its ability to find higher-quality solutions for very large instances than obtained by static PDRs and by a CP solver within the same time limit.
Semiconductor Fab Scheduling with Self-Supervised and Reinforcement Learning
Feb 14, 2023Semiconductor manufacturing is a notoriously complex and costly multi-step process involving a long sequence of operations on expensive and quantity-limited equipment. Recent chip shortages and their impacts have highlighted the importance of semiconductors in the global supply chains and how reliant on those our daily lives are. Due to the investment cost, environmental impact, and time scale needed to build new factories, it is difficult to ramp up production when demand spikes. This work introduces a method to successfully learn to schedule a semiconductor manufacturing facility more efficiently using deep reinforcement and self-supervised learning. We propose the first adaptive scheduling approach to handle complex, continuous, stochastic, dynamic, modern semiconductor manufacturing models. Our method outperforms the traditional hierarchical dispatching strategies typically used in semiconductor manufacturing plants, substantially reducing each order's tardiness and time until completion. As a result, our method yields a better allocation of resources in the semiconductor manufacturing process.
Specifying and Exploiting Non-Monotonic Domain-Specific Declarative Heuristics in Answer Set Programming
Sep 19, 2022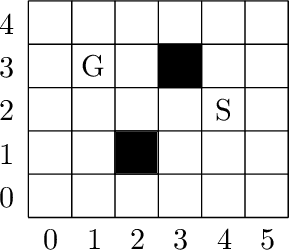
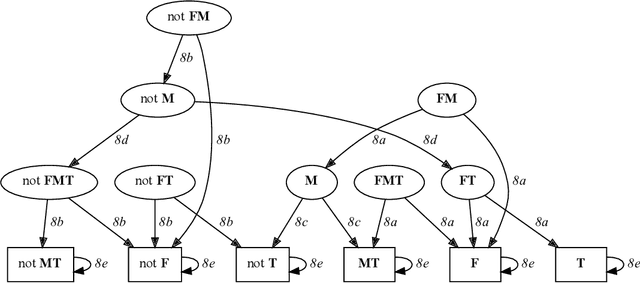
Domain-specific heuristics are an essential technique for solving combinatorial problems efficiently. Current approaches to integrate domain-specific heuristics with Answer Set Programming (ASP) are unsatisfactory when dealing with heuristics that are specified non-monotonically on the basis of partial assignments. Such heuristics frequently occur in practice, for example, when picking an item that has not yet been placed in bin packing. Therefore, we present novel syntax and semantics for declarative specifications of domain-specific heuristics in ASP. Our approach supports heuristic statements that depend on the partial assignment maintained during solving, which has not been possible before. We provide an implementation in ALPHA that makes ALPHA the first lazy-grounding ASP system to support declaratively specified domain-specific heuristics. Two practical example domains are used to demonstrate the benefits of our proposal. Additionally, we use our approach to implement informed} search with A*, which is tackled within ASP for the first time. A* is applied to two further search problems. The experiments confirm that combining lazy-grounding ASP solving and our novel heuristics can be vital for solving industrial-size problems.
Problem Decomposition and Multi-shot ASP Solving for Job-shop Scheduling
May 23, 2022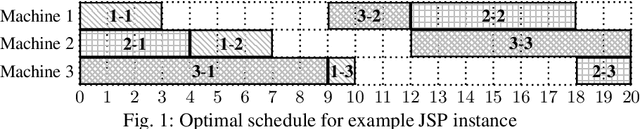
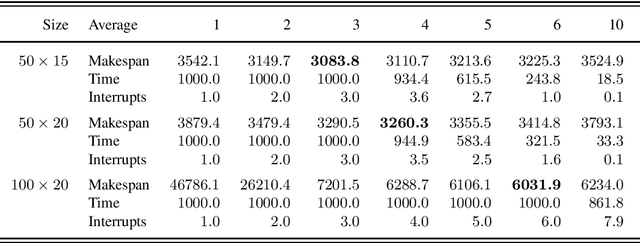

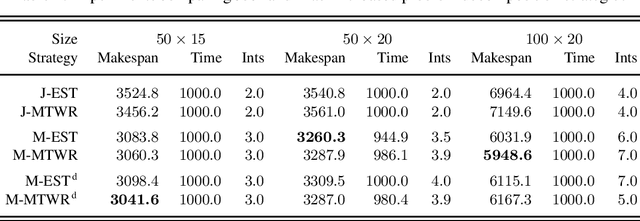
The Job-shop Scheduling Problem (JSP) is a well-known and challenging combinatorial optimization problem in which tasks sharing a machine are to be arranged in a sequence such that encompassing jobs can be completed as early as possible. In this paper, we propose problem decomposition into time windows whose operations can be successively scheduled and optimized by means of multi-shot Answer Set Programming (ASP) solving. Decomposition aims to split highly complex scheduling tasks into better manageable sub-problems with a balanced number of operations so that good quality or even optimal partial solutions can be reliably found in a small fraction of runtime. Problem decomposition must respect the precedence of operations within their jobs and partial schedules optimized by time windows should yield better global solutions than obtainable in similar runtime on the entire instance. We devise and investigate a variety of decomposition strategies in terms of the number and size of time windows as well as heuristics for choosing their operations. Moreover, we incorporate time window overlapping and compression techniques into the iterative scheduling process to counteract window-wise optimization limitations restricted to partial schedules. Our experiments on JSP benchmark sets of several sizes show that successive optimization by multi-shot ASP solving leads to substantially better schedules within the runtime limit than global optimization on the full problem, where the gap increases with the number of operations to schedule. While the obtained solution quality still remains behind a state-of-the-art Constraint Programming system, our multi-shot solving approach comes closer the larger the instance size, demonstrating good scalability by problem decomposition.
Efficient lifting of symmetry breaking constraints for complex combinatorial problems
May 14, 2022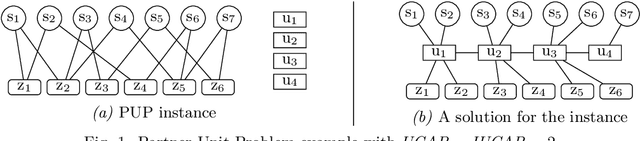
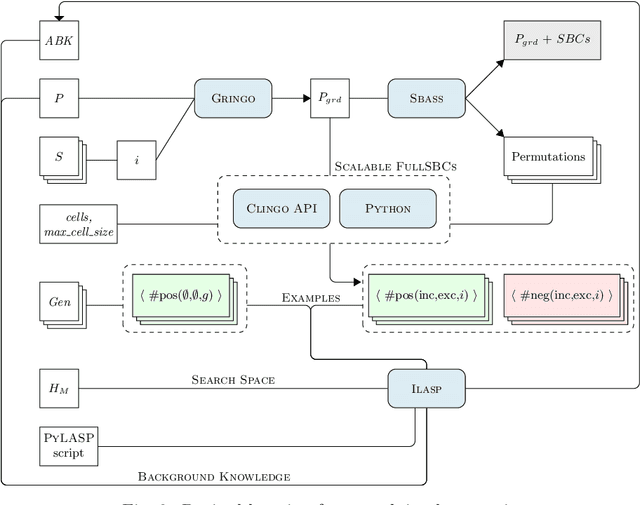
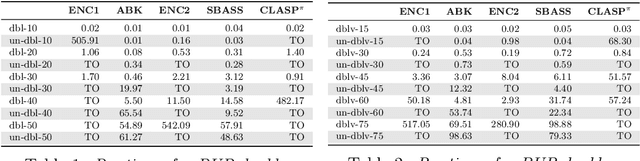
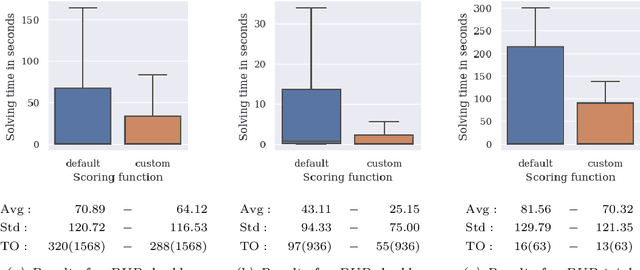
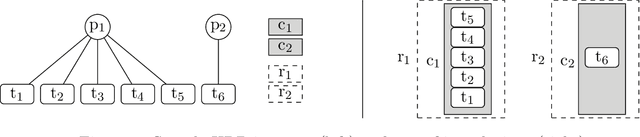
Many industrial applications require finding solutions to challenging combinatorial problems. Efficient elimination of symmetric solution candidates is one of the key enablers for high-performance solving. However, existing model-based approaches for symmetry breaking are limited to problems for which a set of representative and easily-solvable instances is available, which is often not the case in practical applications. This work extends the learning framework and implementation of a model-based approach for Answer Set Programming to overcome these limitations and address challenging problems, such as the Partner Units Problem. In particular, we incorporate a new conflict analysis algorithm in the Inductive Logic Programming system ILASP, redefine the learning task, and suggest a new example generation method to scale up the approach. The experiments conducted for different kinds of Partner Units Problem instances demonstrate the applicability of our approach and the computational benefits due to the first-order constraints learned.
Lifting Symmetry Breaking Constraints with Inductive Logic Programming
Dec 23, 2021Efficient omission of symmetric solution candidates is essential for combinatorial problem-solving. Most of the existing approaches are instance-specific and focus on the automatic computation of Symmetry Breaking Constraints (SBCs) for each given problem instance. However, the application of such approaches to large-scale instances or advanced problem encodings might be problematic since the computed SBCs are propositional and, therefore, can neither be meaningfully interpreted nor transferred to other instances. As a result, a time-consuming recomputation of SBCs must be done before every invocation of a solver. To overcome these limitations, we introduce a new model-oriented approach for Answer Set Programming that lifts the SBCs of small problem instances into a set of interpretable first-order constraints using the Inductive Logic Programming paradigm. Experiments demonstrate the ability of our framework to learn general constraints from instance-specific SBCs for a collection of combinatorial problems. The obtained results indicate that our approach significantly outperforms a state-of-the-art instance-specific method as well as the direct application of a solver.
A Reinforcement Learning Environment For Job-Shop Scheduling
Apr 08, 2021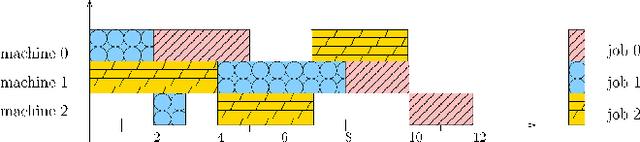
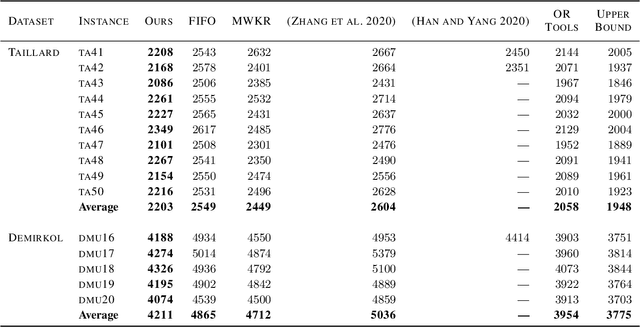
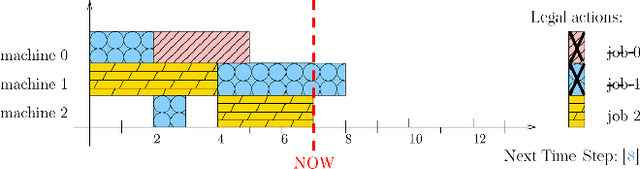
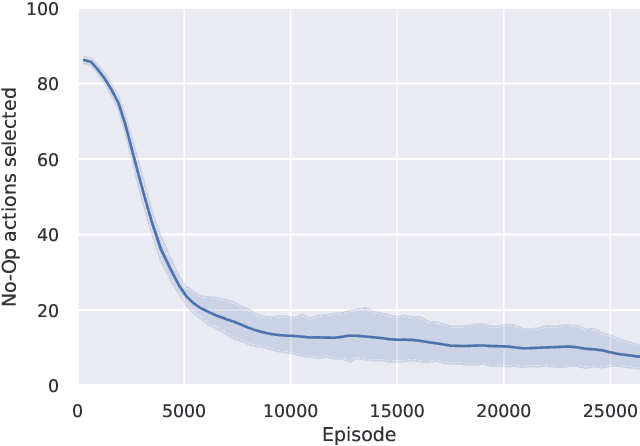
Scheduling is a fundamental task occurring in various automated systems applications, e.g., optimal schedules for machines on a job shop allow for a reduction of production costs and waste. Nevertheless, finding such schedules is often intractable and cannot be achieved by Combinatorial Optimization Problem (COP) methods within a given time limit. Recent advances of Deep Reinforcement Learning (DRL) in learning complex behavior enable new COP application possibilities. This paper presents an efficient DRL environment for Job-Shop Scheduling -- an important problem in the field. Furthermore, we design a meaningful and compact state representation as well as a novel, simple dense reward function, closely related to the sparse make-span minimization criteria used by COP methods. We demonstrate that our approach significantly outperforms existing DRL methods on classic benchmark instances, coming close to state-of-the-art COP approaches.