 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-latency Space-time Supersampling for Real-time Rendering
Dec 18, 2023
With the rise of real-time rendering and the evolution of display devices, there is a growing demand for post-processing methods that offer high-resolution content in a high frame rate. Existing techniques often suffer from quality and latency issues due to the disjointed treatment of frame supersampling and extrapolation. In this paper, we recognize the shared context and mechanisms between frame supersampling and extrapolation, and present a novel framework, Space-time Supersampling (STSS). By integrating them into a unified framework, STSS can improve the overall quality with lower latency. To implement an efficient architecture, we treat the aliasing and warping holes unified as reshading regions and put forth two key components to compensate the regions, namely Random Reshading Masking (RRM) and Efficient Reshading Module (ERM). Extensive experiments demonstrate that our approach achieves superior visual fidelity compared to state-of-the-art (SOTA) methods. Notably, the performance is achieved within only 4ms, saving up to 75\% of time against the conventional two-stage pipeline that necessitates 17ms.
ReAlnet: Achieving More Human Brain-Like Vision via Human Neural Representational Alignment
Jan 30, 2024Despite the remarkable strides made in artificial intelligence, current object recognition models still lag behind in emulating the mechanism of visual information processing in human brains. Recent studies have highlighted the potential of using neural data to mimic brain processing; however, these often reply on invasive neural recordings from non-human subjects, leaving a critical gap in our understanding of human visual perception and the development of more human brain-like vision models. Addressing this gap, we present, for the first time, "Re(presentational)Al(ignment)net", a vision model aligned with human brain activity based on non-invasive EEG recordings, demonstrating a significantly higher similarity to human brain representations. Our innovative image-to-brain multi-layer encoding alignment framework not only optimizes multiple layers of the model, marking a substantial leap in neural alignment, but also enables the model to efficiently learn and mimic human brain's visual representational patterns across object categories and different neural data modalities. Furthermore, we discover that alignment with human brain representations improves the model's adversarial robustness. Our findings suggest that ReAlnet sets a new precedent in the field, bridging the gap between artificial and human vision, and paving the way for more brain-like artificial intelligence systems.
Online Robot Navigation and and Manipulation with Distilled Vision-Language Models
Jan 30, 2024Autonomous robot navigation within the dynamic unknown environment is of crucial significance for mobile robotic applications including robot navigation in last-mile delivery and robot-enabled automated supplies in industrial and hospital delivery applications. Current solutions still suffer from limitations, such as the robot cannot recognize unknown objects in real time and cannot navigate freely in a dynamic, narrow, and complex environment. We propose a complete software framework for autonomous robot perception and navigation within very dense obstacles and dense human crowds. First, we propose a framework that accurately detects and segments open-world object categories in a zero-shot manner, which overcomes the over-segmentation limitation of the current SAM model. Second, we proposed the distillation strategy to distill the knowledge to segment the free space of the walkway for robot navigation without the label. In the meantime, we design the trimming strategy that works collaboratively with distillation to enable lightweight inference to deploy the neural network on edge devices such as NVIDIA-TX2 or Xavier NX during autonomous navigation. Integrated into the robot navigation system, extensive experiments demonstrate that our proposed framework has achieved superior performance in terms of both accuracy and efficiency in robot scene perception and autonomous robot navigation.
Segmentation and Characterization of Macerated Fibers and Vessels Using Deep Learning
Jan 30, 2024Purpose: Wood comprises different cell types, such as fibers and vessels, defining its properties. Studying their shape, size, and arrangement in microscopic images is crucial for understanding wood samples. Typically, this involves macerating (soaking) samples in a solution to separate cells, then spreading them on slides for imaging with a microscope that covers a wide area, capturing thousands of cells. However, these cells often cluster and overlap in images, making the segmentation difficult and time-consuming using standard image-processing methods. Results: In this work, we develop an automatic deep learning segmentation approach that utilizes the one-stage YOLOv8 model for fast and accurate fiber and vessel segmentation and characterization in microscopy images. The model can analyze 32640 x 25920 pixels images and demonstrate effective cell detection and segmentation, achieving a mAP_0.5-0.95 of 78 %. To assess the model's robustness, we examined fibers from a genetically modified tree line known for longer fibers. The outcomes were comparable to previous manual measurements. Additionally, we created a user-friendly web application for image analysis and provided the code for use on Google Colab. Conclusion: By leveraging YOLOv8's advances, this work provides a deep learning solution to enable efficient quantification and analysis of wood cells suitable for practical applications.
Dynamical System Identification, Model Selection and Model Uncertainty Quantification by Bayesian Inference
Jan 30, 2024This study presents a Bayesian maximum \textit{a~posteriori} (MAP) framework for dynamical system identification from time-series data. This is shown to be equivalent to a generalized zeroth-order Tikhonov regularization, providing a rational justification for the choice of the residual and regularization terms, respectively, from the negative logarithms of the likelihood and prior distributions. In addition to the estimation of model coefficients, the Bayesian interpretation gives access to the full apparatus for Bayesian inference, including the ranking of models, the quantification of model uncertainties and the estimation of unknown (nuisance) hyperparameters. Two Bayesian algorithms, joint maximum \textit{a~posteriori} (JMAP) and variational Bayesian approximation (VBA), are compared to the popular SINDy algorithm for thresholded least-squares regression, by application to several dynamical systems with added noise. For multivariate Gaussian likelihood and prior distributions, the Bayesian formulation gives Gaussian posterior and evidence distributions, in which the numerator terms can be expressed in terms of the Mahalanobis distance or ``Gaussian norm'' $||\vy-\hat{\vy}||^2_{M^{-1}} = (\vy-\hat{\vy})^\top {M^{-1}} (\vy-\hat{\vy})$, where $\vy$ is a vector variable, $\hat{\vy}$ is its estimator and $M$ is the covariance matrix. The posterior Gaussian norm is shown to provide a robust metric for quantitative model selection.
SmartFRZ: An Efficient Training Framework using Attention-Based Layer Freezing
Jan 30, 2024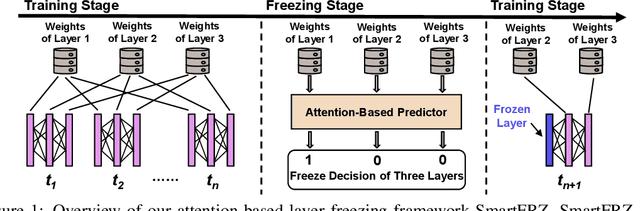

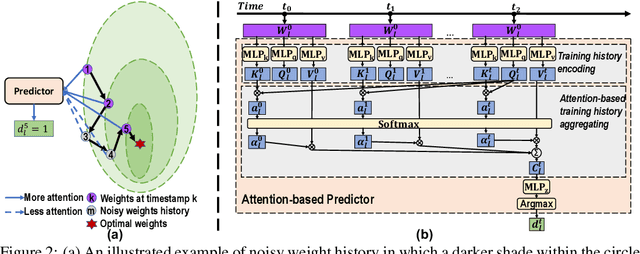
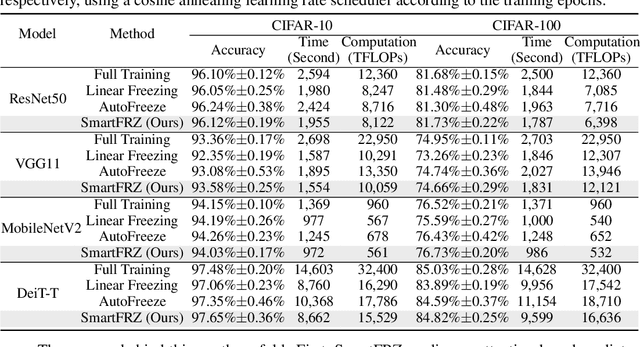
There has been a proliferation of artificial intelligence applications, where model training is key to promising high-quality services for these applications. However, the model training process is both time-intensive and energy-intensive, inevitably affecting the user's demand for application efficiency. Layer freezing, an efficient model training technique, has been proposed to improve training efficiency. Although existing layer freezing methods demonstrate the great potential to reduce model training costs, they still remain shortcomings such as lacking generalizability and compromised accuracy. For instance, existing layer freezing methods either require the freeze configurations to be manually defined before training, which does not apply to different networks, or use heuristic freezing criteria that is hard to guarantee decent accuracy in different scenarios. Therefore, there lacks a generic and smart layer freezing method that can automatically perform ``in-situation'' layer freezing for different networks during training processes. To this end, we propose a generic and efficient training framework (SmartFRZ). The core proposed technique in SmartFRZ is attention-guided layer freezing, which can automatically select the appropriate layers to freeze without compromising accuracy. Experimental results show that SmartFRZ effectively reduces the amount of computation in training and achieves significant training acceleration, and outperforms the state-of-the-art layer freezing approaches.
Speeding up and reducing memory usage for scientific machine learning via mixed precision
Jan 30, 2024Scientific machine learning (SciML) has emerged as a versatile approach to address complex computational science and engineering problems. Within this field, physics-informed neural networks (PINNs) and deep operator networks (DeepONets) stand out as the leading techniques for solving partial differential equations by incorporating both physical equations and experimental data. However, training PINNs and DeepONets requires significant computational resources, including long computational times and large amounts of memory. In search of computational efficiency, training neural networks using half precision (float16) rather than the conventional single (float32) or double (float64) precision has gained substantial interest, given the inherent benefits of reduced computational time and memory consumed. However, we find that float16 cannot be applied to SciML methods, because of gradient divergence at the start of training, weight updates going to zero, and the inability to converge to a local minima. To overcome these limitations, we explore mixed precision, which is an approach that combines the float16 and float32 numerical formats to reduce memory usage and increase computational speed. Our experiments showcase that mixed precision training not only substantially decreases training times and memory demands but also maintains model accuracy. We also reinforce our empirical observations with a theoretical analysis. The research has broad implications for SciML in various computational applications.
AttentionLut: Attention Fusion-based Canonical Polyadic LUT for Real-time Image Enhancement
Jan 03, 2024Recently, many algorithms have employed image-adaptive lookup tables (LUTs) to achieve real-time image enhancement. Nonetheless, a prevailing trend among existing methods has been the employment of linear combinations of basic LUTs to formulate image-adaptive LUTs, which limits the generalization ability of these methods. To address this limitation, we propose a novel framework named AttentionLut for real-time image enhancement, which utilizes the attention mechanism to generate image-adaptive LUTs. Our proposed framework consists of three lightweight modules. We begin by employing the global image context feature module to extract image-adaptive features. Subsequently, the attention fusion module integrates the image feature with the priori attention feature obtained during training to generate image-adaptive canonical polyadic tensors. Finally, the canonical polyadic reconstruction module is deployed to reconstruct image-adaptive residual 3DLUT, which is subsequently utilized for enhancing input images. Experiments on the benchmark MIT-Adobe FiveK dataset demonstrate that the proposed method achieves better enhancement performance quantitatively and qualitatively than the state-of-the-art methods.
EndoGaussian: Gaussian Splatting for Deformable Surgical Scene Reconstruction
Jan 23, 2024Reconstructing deformable tissues from endoscopic stereo videos is essential in many downstream surgical applications. However, existing methods suffer from slow inference speed, which greatly limits their practical use. In this paper, we introduce EndoGaussian, a real-time surgical scene reconstruction framework that builds on 3D Gaussian Splatting. Our framework represents dynamic surgical scenes as canonical Gaussians and a time-dependent deformation field, which predicts Gaussian deformations at novel timestamps. Due to the efficient Gaussian representation and parallel rendering pipeline, our framework significantly accelerates the rendering speed compared to previous methods. In addition, we design the deformation field as the combination of a lightweight encoding voxel and an extremely tiny MLP, allowing for efficient Gaussian tracking with a minor rendering burden. Furthermore, we design a holistic Gaussian initialization method to fully leverage the surface distribution prior, achieved by searching informative points from across the input image sequence. Experiments on public endoscope datasets demonstrate that our method can achieve real-time rendering speed (195 FPS real-time, 100$\times$ gain) while maintaining the state-of-the-art reconstruction quality (35.925 PSNR) and the fastest training speed (within 2 min/scene), showing significant promise for intraoperative surgery applications. Code is available at: \url{https://yifliu3.github.io/EndoGaussian/}.
Time-Transformer: Integrating Local and Global Features for Better Time Series Generation
Dec 18, 2023Generating time series data is a promising approach to address data deficiency problems. However, it is also challenging due to the complex temporal properties of time series data, including local correlations as well as global dependencies. Most existing generative models have failed to effectively learn both the local and global properties of time series data. To address this open problem, we propose a novel time series generative model named 'Time-Transformer AAE', which consists of an adversarial autoencoder (AAE) and a newly designed architecture named 'Time-Transformer' within the decoder. The Time-Transformer first simultaneously learns local and global features in a layer-wise parallel design, combining the abilities of Temporal Convolutional Networks and Transformer in extracting local features and global dependencies respectively. Second, a bidirectional cross attention is proposed to provide complementary guidance across the two branches and achieve proper fusion between local and global features. Experimental results demonstrate that our model can outperform existing state-of-the-art models in 5 out of 6 datasets, specifically on those with data containing both global and local properties. Furthermore, we highlight our model's advantage on handling this kind of data via an artificial dataset. Finally, we show our model's ability to address a real-world problem: data augmentation to support learning with small datasets and imbalanced datasets.