 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Streaming End-to-End ASR based on Blockwise Non-Autoregressive Models
Jul 20, 2021
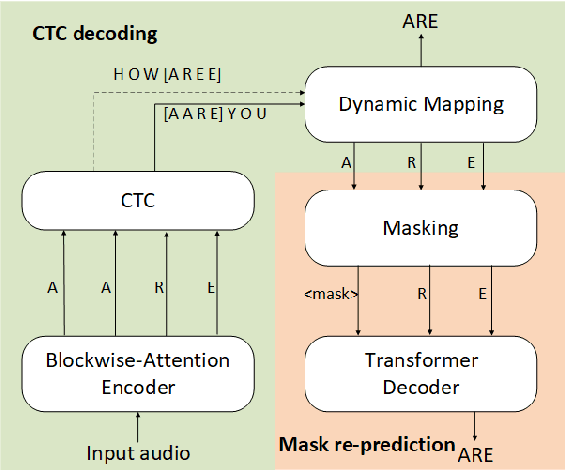
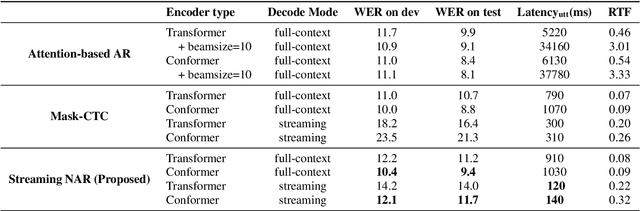
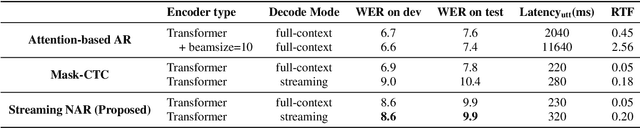
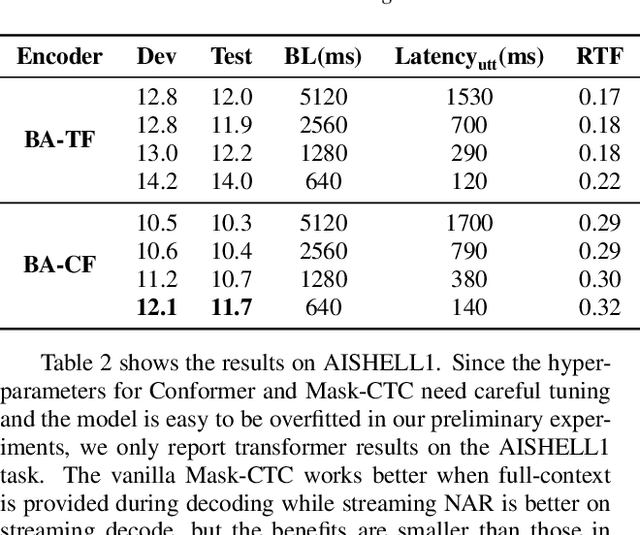
Non-autoregressive (NAR) modeling has gained more and more attention in speech processing. With recent state-of-the-art attention-based automatic speech recognition (ASR) structure, NAR can realize promising real-time factor (RTF) improvement with only small degradation of accuracy compared to the autoregressive (AR) models. However, the recognition inference needs to wait for the completion of a full speech utterance, which limits their applications on low latency scenarios. To address this issue, we propose a novel end-to-end streaming NAR speech recognition system by combining blockwise-attention and connectionist temporal classification with mask-predict (Mask-CTC) NAR. During inference, the input audio is separated into small blocks and then processed in a blockwise streaming way. To address the insertion and deletion error at the edge of the output of each block, we apply an overlapping decoding strategy with a dynamic mapping trick that can produce more coherent sentences. Experimental results show that the proposed method improves online ASR recognition in low latency conditions compared to vanilla Mask-CTC. Moreover, it can achieve a much faster inference speed compared to the AR attention-based models. All of our codes will be publicly available at https://github.com/espnet/espnet.
Value Function is All You Need: A Unified Learning Framework for Ride Hailing Platforms
May 20, 2021
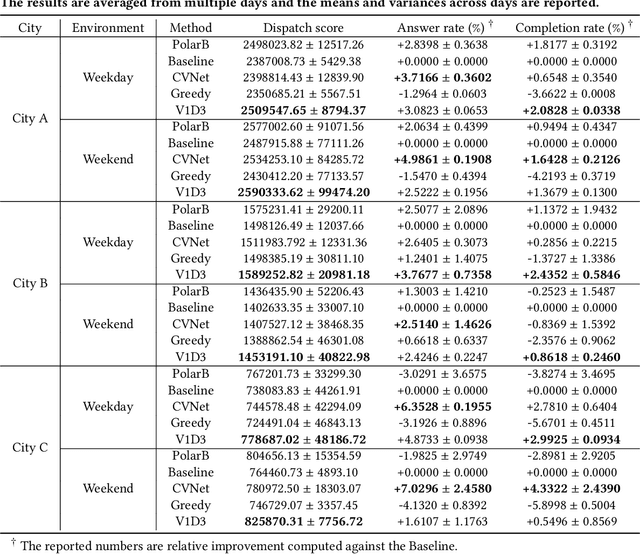
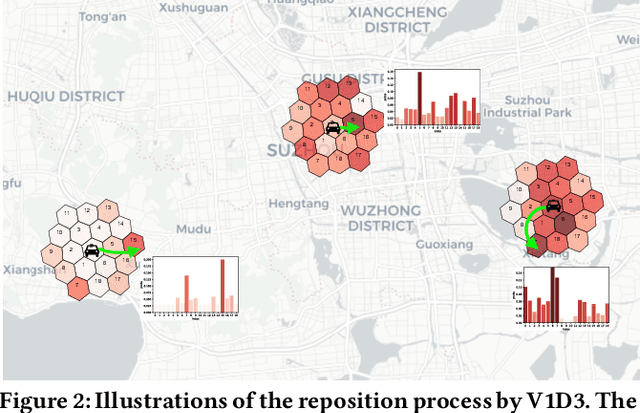
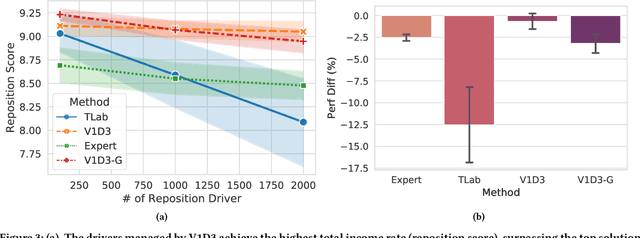
Large ride-hailing platforms, such as DiDi, Uber and Lyft, connect tens of thousands of vehicles in a city to millions of ride demands throughout the day, providing great promises for improving transportation efficiency through the tasks of order dispatching and vehicle repositioning. Existing studies, however, usually consider the two tasks in simplified settings that hardly address the complex interactions between the two, the real-time fluctuations between supply and demand, and the necessary coordinations due to the large-scale nature of the problem. In this paper we propose a unified value-based dynamic learning framework (V1D3) for tackling both tasks. At the center of the framework is a globally shared value function that is updated continuously using online experiences generated from real-time platform transactions. To improve the sample-efficiency and the robustness, we further propose a novel periodic ensemble method combining the fast online learning with a large-scale offline training scheme that leverages the abundant historical driver trajectory data. This allows the proposed framework to adapt quickly to the highly dynamic environment, to generalize robustly to recurrent patterns and to drive implicit coordinations among the population of managed vehicles. Extensive experiments based on real-world datasets show considerably improvements over other recently proposed methods on both tasks. Particularly, V1D3 outperforms the first prize winners of both dispatching and repositioning tracks in the KDD Cup 2020 RL competition, achieving state-of-the-art results on improving both total driver income and user experience related metrics.
ViT-Inception-GAN for Image Colourising
Jun 11, 2021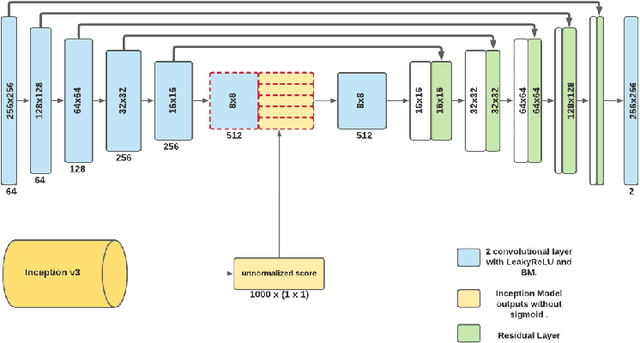

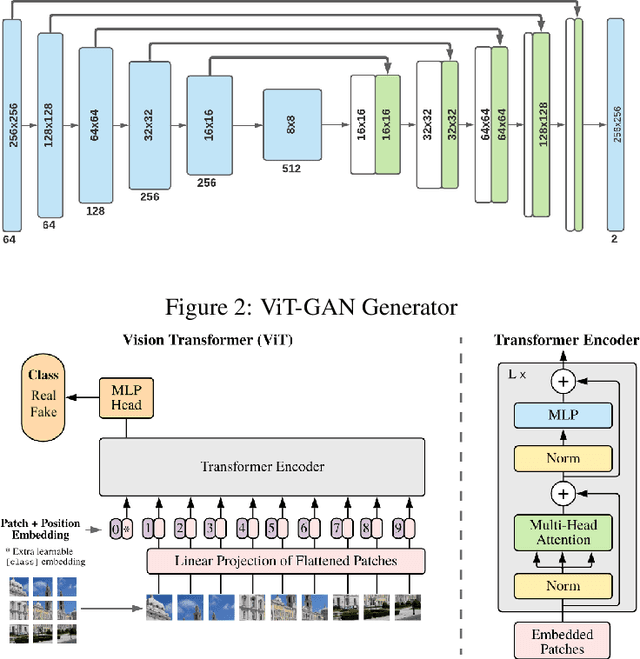

Studies involving colourising images has been garnering researchers' keen attention over time, assisted by significant advances in various Machine Learning techniques and compute power availability. Traditionally, colourising images have been an intricate task that gave a substantial degree of freedom during the assignment of chromatic information. In our proposed method, we attempt to colourise images using Vision Transformer - Inception - Generative Adversarial Network (ViT-I-GAN), which has an Inception-v3 fusion embedding in the generator. For a stable and robust network, we have used Vision Transformer (ViT) as the discriminator. We trained the model on the Unsplash and the COCO dataset for demonstrating the improvement made by the Inception-v3 embedding. We have compared the results between ViT-GANs with and without Inception-v3 embedding.
Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis
Apr 10, 2021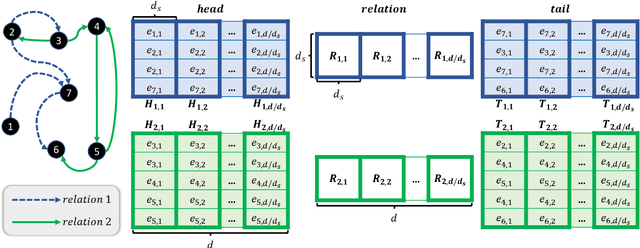
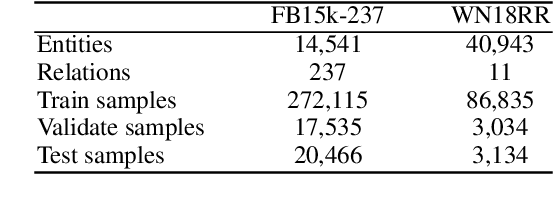
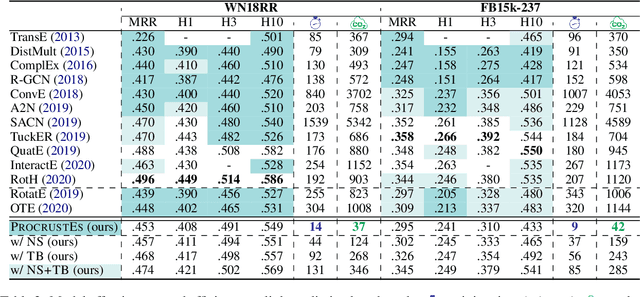
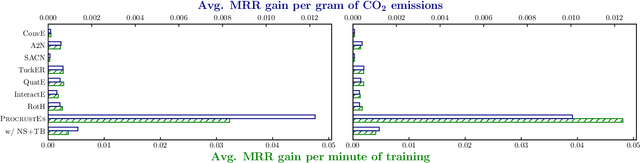
Knowledge Graph Embeddings (KGEs) have been intensively explored in recent years due to their promise for a wide range of applications. However, existing studies focus on improving the final model performance without acknowledging the computational cost of the proposed approaches, in terms of execution time and environmental impact. This paper proposes a simple yet effective KGE framework which can reduce the training time and carbon footprint by orders of magnitudes compared with state-of-the-art approaches, while producing competitive performance. We highlight three technical innovations: full batch learning via relational matrices, closed-form Orthogonal Procrustes Analysis for KGEs, and non-negative-sampling training. In addition, as the first KGE method whose entity embeddings also store full relation information, our trained models encode rich semantics and are highly interpretable. Comprehensive experiments and ablation studies involving 13 strong baselines and two standard datasets verify the effectiveness and efficiency of our algorithm.
Similarity metrics for Different Market Scenarios in Abides
Jul 20, 2021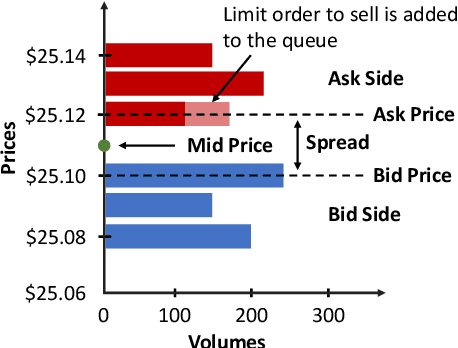
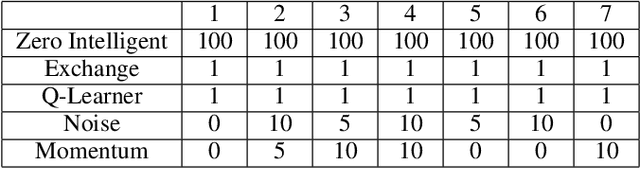
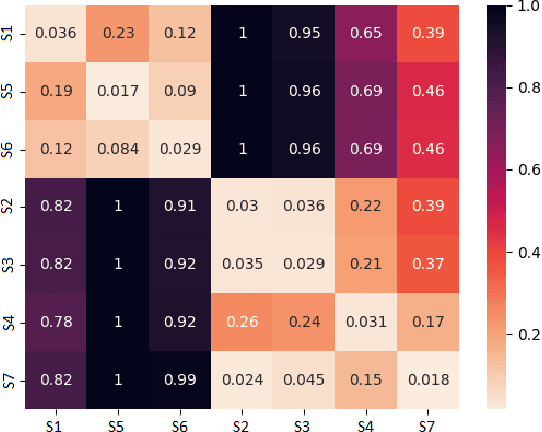
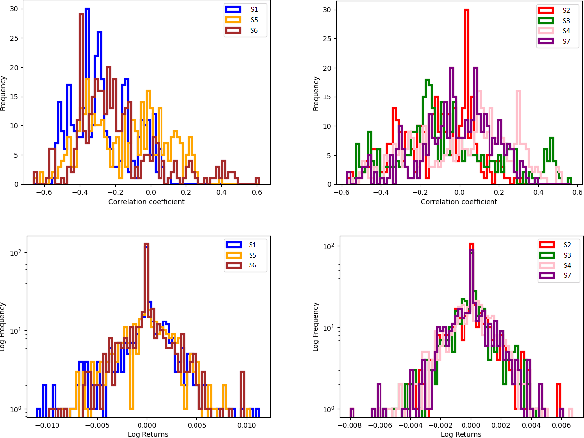
Markov Decision Processes (MDPs) are an effective way to formally describe many Machine Learning problems. In fact, recently MDPs have also emerged as a powerful framework to model financial trading tasks. For example, financial MDPs can model different market scenarios. However, the learning of a (near-)optimal policy for each of these financial MDPs can be a very time-consuming process, especially when nothing is known about the policy to begin with. An alternative approach is to find a similar financial MDP for which we have already learned its policy, and then reuse such policy in the learning of a new policy for a new financial MDP. Such a knowledge transfer between market scenarios raises several issues. On the one hand, how to measure the similarity between financial MDPs. On the other hand, how to use this similarity measurement to effectively transfer the knowledge between financial MDPs. This paper addresses both of these issues. Regarding the first one, this paper analyzes the use of three similarity metrics based on conceptual, structural and performance aspects of the financial MDPs. Regarding the second one, this paper uses Probabilistic Policy Reuse to balance the exploitation/exploration in the learning of a new financial MDP according to the similarity of the previous financial MDPs whose knowledge is reused.
Understanding Human Innate Immune System Dependencies using Graph Neural Networks
Aug 05, 2021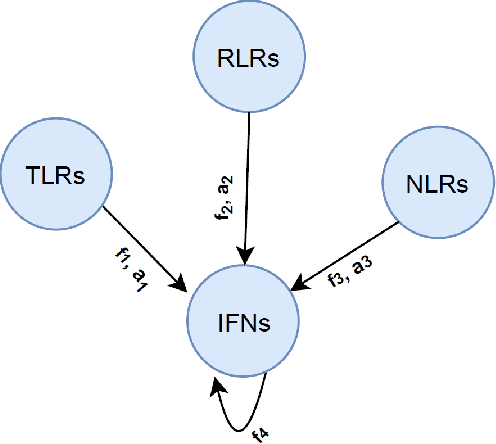
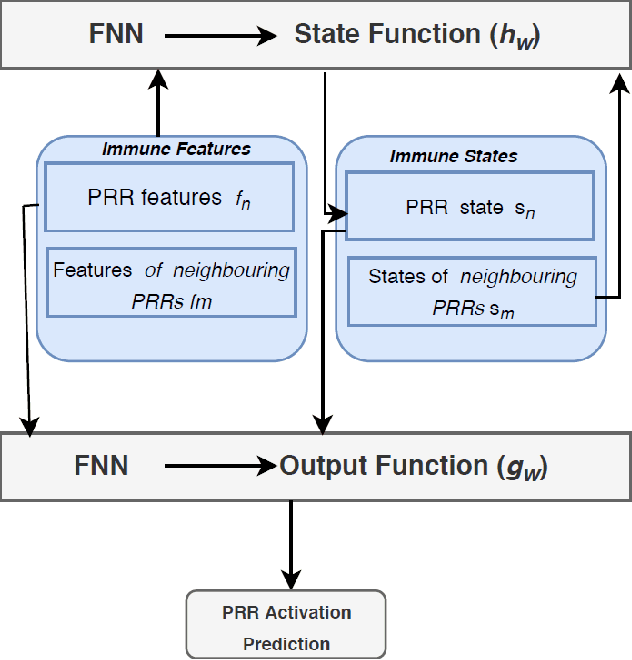
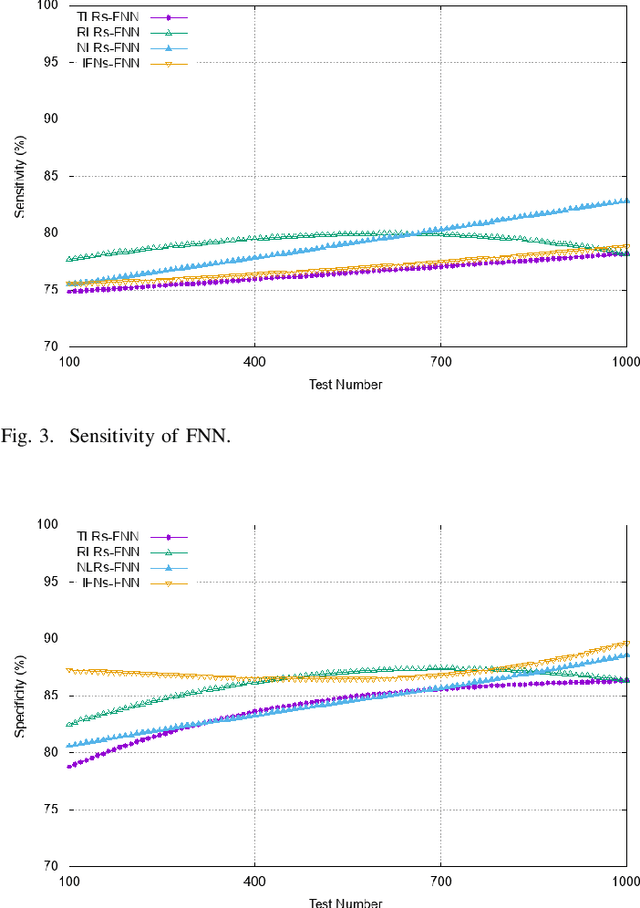
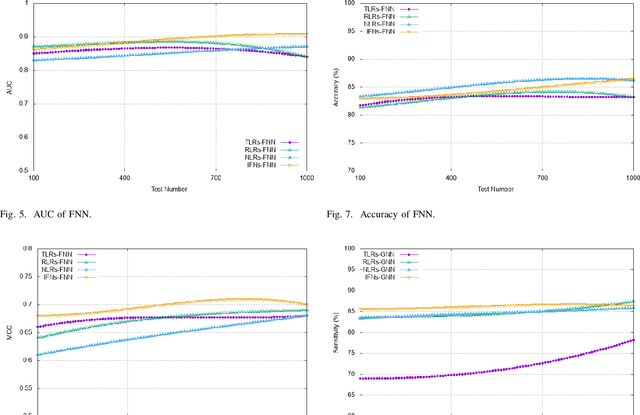
Since the rapid outbreak of Covid-19 and with no approved vaccines to date, profound research interest has emerged to understand the innate immune response to viruses. This understanding can help to inhibit virus replication, prolong adaptive immune response, accelerated virus clearance, and tissue recovery, a key milestone to propose a vaccine to combat coronaviruses (CoVs), e.g., Covid-19. Although an innate immune system triggers inflammatory responses against CoVs upon recognition of viruses, however, a vaccine is the ultimate protection against CoV spread. The development of this vaccine is time-consuming and requires a deep understanding of the innate immune response system. In this work, we propose a graph neural network-based model that exploits the interactions between pattern recognition receptors (PRRs), i.e., the human immune response system. These interactions can help to recognize pathogen-associated molecular patterns (PAMPs) to predict the activation requirements of each PRR. The immune response information of each PRR is derived from combining its historical PAMPs activation coupled with the modeled effect on the same from PRRs in its neighborhood. On one hand, this work can help to understand how long Covid-19 can confer immunity where a strong immune response means people already been infected can safely return to work. On the other hand, this GNN-based understanding can also abode well for vaccine development efforts. Our proposal has been evaluated using CoVs immune response dataset, with results showing an average IFNs activation prediction accuracy of 90%, compared to 85% using feed-forward neural networks.
Classification Confidence Estimation with Test-Time Data-Augmentation
Jun 30, 2020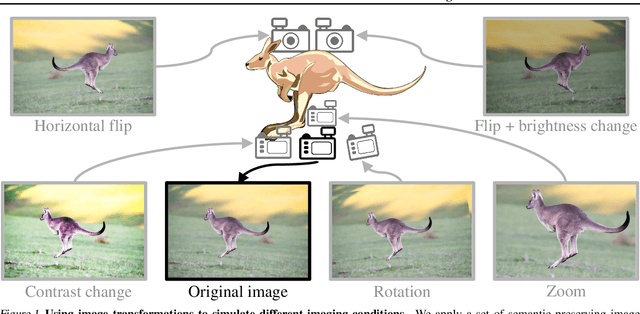
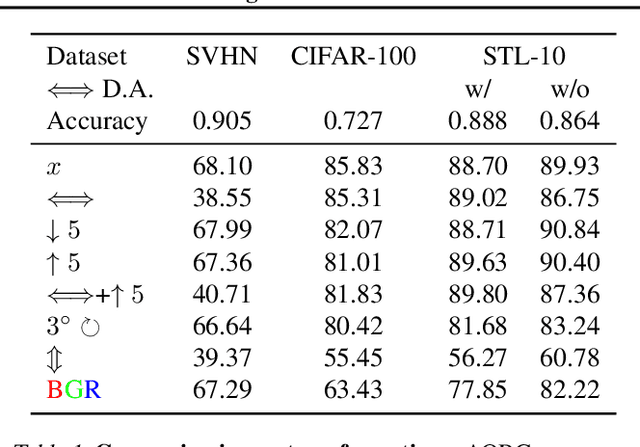
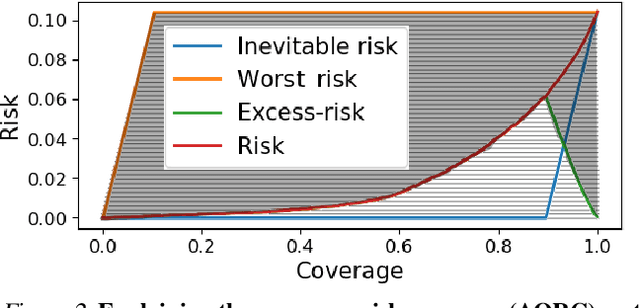
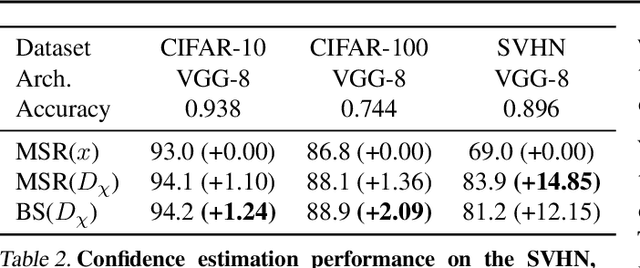
Machine learning plays an increasingly significant role in many aspects of our lives (including medicine, transportation, security, justice and other domains), making the potential consequences of false predictions increasingly devastating. These consequences may be mitigated if we can automatically flag such false predictions and potentially assign them to alternative, more reliable mechanisms, that are possibly more costly and involve human attention. This suggests the task of detecting errors, which we tackle in this paper for the case of visual classification. To this end, we propose a novel approach for classification confidence estimation. We apply a set of semantics-preserving image transformations to the input image, and show how the resulting image sets can be used to estimate confidence in the classifier's prediction. We demonstrate the potential of our approach by extensively evaluating it on a wide variety of classifier architectures and datasets, including ResNext/ImageNet, achieving state of the art performance. This paper constitutes a significant revision of our earlier work in this direction (Bahat & Shakhnarovich, 2018).
Differentiable Adaptive Computation Time for Visual Reasoning
May 22, 2020
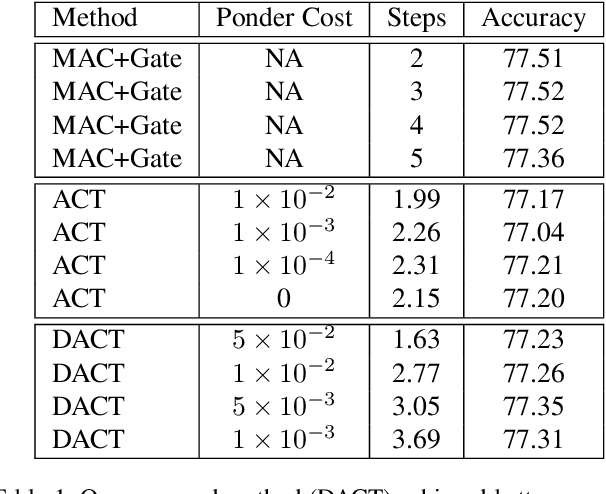
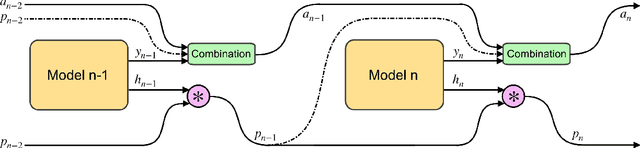
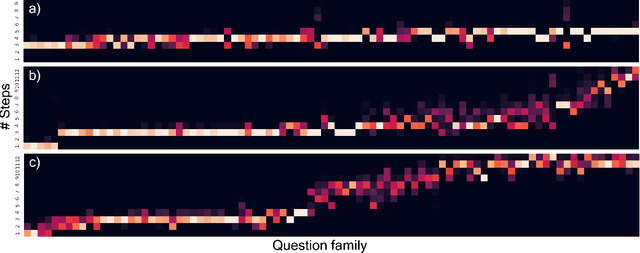
This paper presents a novel attention-based algorithm for achieving adaptive computation called DACT, which, unlike existing ones, is end-to-end differentiable. Our method can be used in conjunction with many networks; in particular, we study its application to the widely known MAC architecture, obtaining a significant reduction in the number of recurrent steps needed to achieve similar accuracies, therefore improving its performance to computation ratio. Furthermore, we show that by increasing the maximum number of steps used, we surpass the accuracy of even our best non-adaptive MAC in the CLEVR dataset, demonstrating that our approach is able to control the number of steps without significant loss of performance. Additional advantages provided by our approach include considerably improving interpretability by discarding useless steps and providing more insights into the underlying reasoning process. Finally, we present adaptive computation as an equivalent to an ensemble of models, similar to a mixture of expert formulation. Both the code and the configuration files for our experiments are made available to support further research in this area.
Learning to Act Safely with Limited Exposure and Almost Sure Certainty
May 25, 2021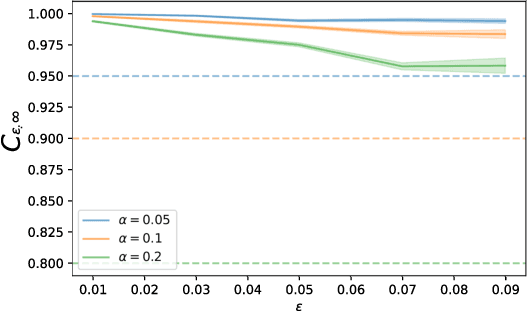
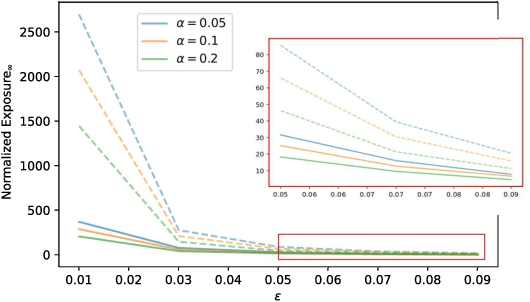
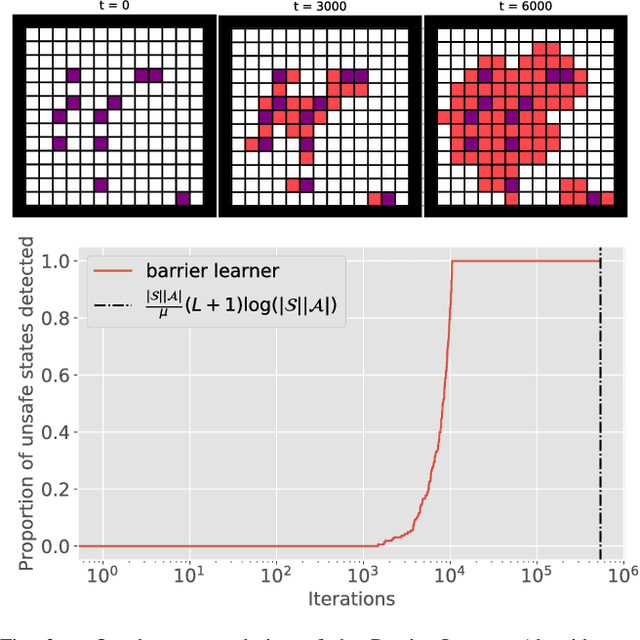

This paper aims to put forward the concept that learning to take safe actions in unknown environments, even with probability one guarantees, can be achieved without the need for an unbounded number of exploratory trials, provided that one is willing to navigate trade-offs between optimality, level of exposure to unsafe events, and the maximum detection time of unsafe actions. We illustrate this concept in two complementary settings. We first focus on the canonical multi-armed bandit problem and seek to study the intrinsic trade-offs of learning safety in the presence of uncertainty. Under mild assumptions on sufficient exploration, we provide an algorithm that provably detects all unsafe machines in an (expected) finite number of rounds. The analysis also unveils a trade-off between the number of rounds needed to secure the environment and the probability of discarding safe machines. We then consider the problem of finding optimal policies for a Markov Decision Process (MDP) with almost sure constraints. We show that the (action) value function satisfies a barrier-based decomposition which allows for the identification of feasible policies independently of the reward process. Using this decomposition, we develop a Barrier-learning algorithm, that identifies such unsafe state-action pairs in a finite expected number of steps. Our analysis further highlights a trade-off between the time lag for the underlying MDP necessary to detect unsafe actions, and the level of exposure to unsafe events. Simulations corroborate our theoretical findings, further illustrating the aforementioned trade-offs, and suggesting that safety constraints can further speed up the learning process.
Explanations for Monotonic Classifiers
Jun 01, 2021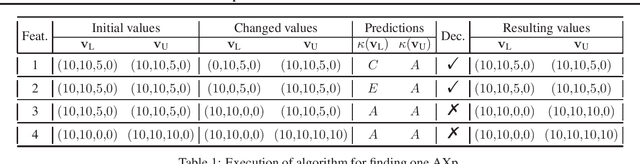
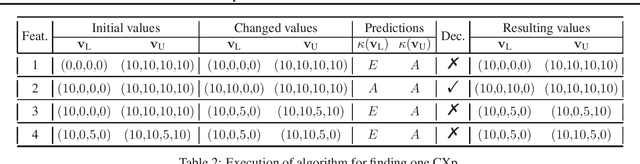
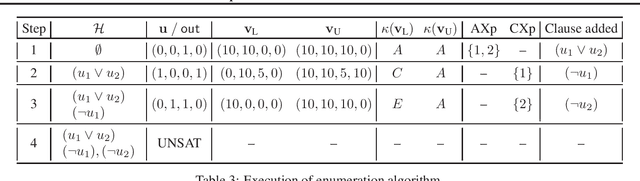

In many classification tasks there is a requirement of monotonicity. Concretely, if all else remains constant, increasing (resp. decreasing) the value of one or more features must not decrease (resp. increase) the value of the prediction. Despite comprehensive efforts on learning monotonic classifiers, dedicated approaches for explaining monotonic classifiers are scarce and classifier-specific. This paper describes novel algorithms for the computation of one formal explanation of a (black-box) monotonic classifier. These novel algorithms are polynomial in the run time complexity of the classifier and the number of features. Furthermore, the paper presents a practically efficient model-agnostic algorithm for enumerating formal explanations.