 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multi-Agent LLM Architectures for Financial Document Processing: A Comparative Study of Orchestration Patterns, Cost-Accuracy Tradeoffs and Production Scaling Strategies
Mar 24, 2026The adoption of large language models (LLMs) for structured information extraction from financial documents has accelerated rapidly, yet production deployments face fundamental architectural decisions with limited empirical guidance. We present a systematic benchmark comparing four multi-agent orchestration architectures: sequential pipeline, parallel fan-out with merge, hierarchical supervisor-worker and reflexive self-correcting loop. These are evaluated across five frontier and open-weight LLMs on a corpus of 10,000 SEC filings (10-K, 10-Q and 8-K forms). Our evaluation spans 25 extraction field types covering governance structures, executive compensation and financial metrics, measured along five axes: field-level F1, document-level accuracy, end-to-end latency, cost per document and token efficiency. We find that reflexive architectures achieve the highest field-level F1 (0.943) but at 2.3x the cost of sequential baselines, while hierarchical architectures occupy the most favorable position on the cost-accuracy Pareto frontier (F1 0.921 at 1.4x cost). We further present ablation studies on semantic caching, model routing and adaptive retry strategies, demonstrating that hybrid configurations can recover 89\% of the reflexive architecture's accuracy gains at only 1.15x baseline cost. Our scaling analysis from 1K to 100K documents per day reveals non-obvious throughput-accuracy degradation curves that inform capacity planning. These findings provide actionable guidance for practitioners deploying multi-agent LLM systems in regulated financial environments.
Comparative Analysis of Transformers for Modeling Tabular Data: A Casestudy using Industry Scale Dataset
Nov 24, 2023We perform a comparative analysis of transformer-based models designed for modeling tabular data, specifically on an industry-scale dataset. While earlier studies demonstrated promising outcomes on smaller public or synthetic datasets, the effectiveness did not extend to larger industry-scale datasets. The challenges identified include handling high-dimensional data, the necessity for efficient pre-processing of categorical and numerical features, and addressing substantial computational requirements. To overcome the identified challenges, the study conducts an extensive examination of various transformer-based models using both synthetic datasets and the default prediction Kaggle dataset (2022) from American Express. The paper presents crucial insights into optimal data pre-processing, compares pre-training and direct supervised learning methods, discusses strategies for managing categorical and numerical features, and highlights trade-offs between computational resources and performance. Focusing on temporal financial data modeling, the research aims to facilitate the systematic development and deployment of transformer-based models in real-world scenarios, emphasizing scalability.
ViT-Inception-GAN for Image Colourising
Jun 11, 2021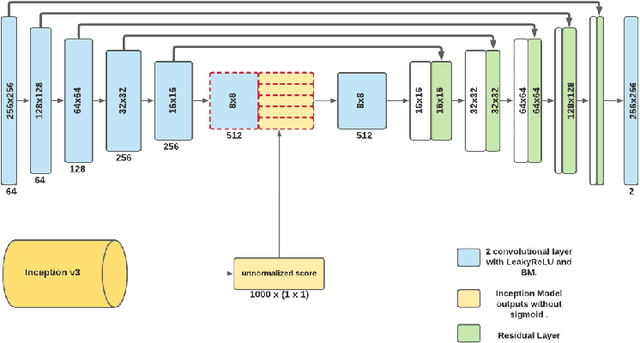

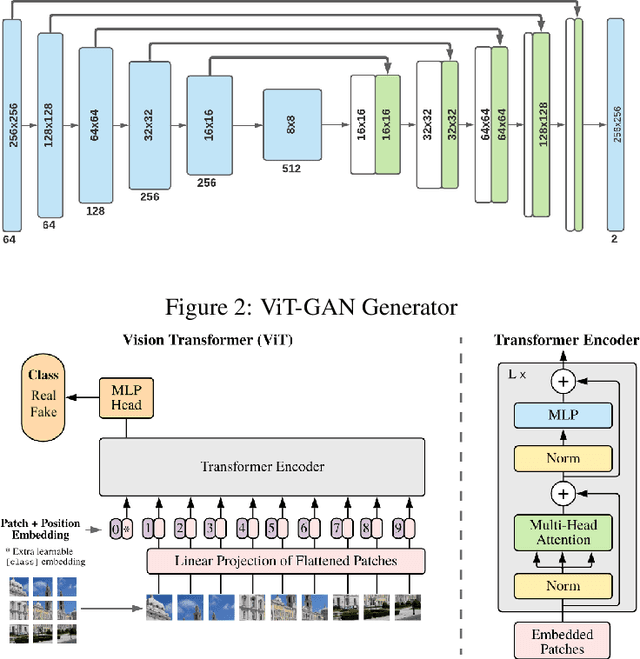

Studies involving colourising images has been garnering researchers' keen attention over time, assisted by significant advances in various Machine Learning techniques and compute power availability. Traditionally, colourising images have been an intricate task that gave a substantial degree of freedom during the assignment of chromatic information. In our proposed method, we attempt to colourise images using Vision Transformer - Inception - Generative Adversarial Network (ViT-I-GAN), which has an Inception-v3 fusion embedding in the generator. For a stable and robust network, we have used Vision Transformer (ViT) as the discriminator. We trained the model on the Unsplash and the COCO dataset for demonstrating the improvement made by the Inception-v3 embedding. We have compared the results between ViT-GANs with and without Inception-v3 embedding.