 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatial Constraint Generation for Motion Planning in Dynamic Environments
Oct 27, 2021
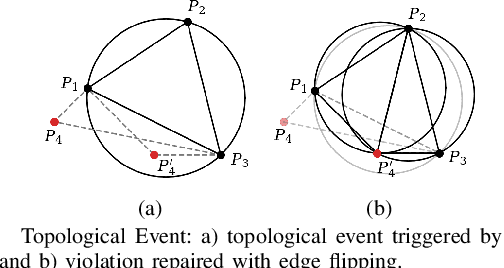
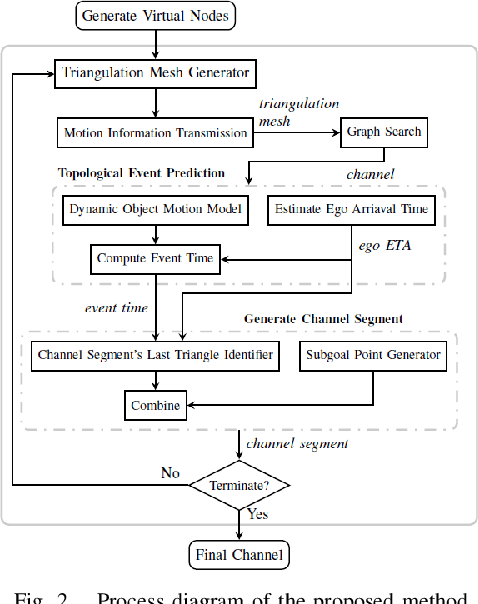
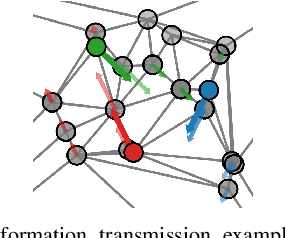
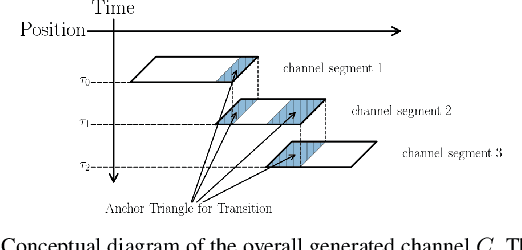
This paper presents a novel method to generate spatial constraints for motion planning in dynamic environments. Motion planning methods for autonomous driving and mobile robots typically need to rely on the spatial constraints imposed by a map-based global planner to generate a collision-free trajectory. These methods may fail without an offline map or where the map is invalid due to dynamic changes in the environment such as road obstruction, construction, and traffic congestion. To address this problem, triangulation-based methods can be used to obtain a spatial constraint. However, the existing methods fall short when dealing with dynamic environments and may lead the motion planner to an unrecoverable state. In this paper, we propose a new method to generate a sequence of channels across different triangulation mesh topologies to serve as the spatial constraints. This can be applied to motion planning of autonomous vehicles or robots in cluttered, unstructured environments. The proposed method is evaluated and compared with other triangulation-based methods in synthetic and complex scenarios collected from a real-world autonomous driving dataset. We have shown that the proposed method results in a more stable, long-term plan with a higher task completion rate, faster arrival time, a higher rate of successful plans, and fewer collisions compared to existing methods.
A 3D Non-Stationary Geometry-Based Stochastic Model for Industrial Automation Wireless Communication Systems
Aug 14, 2021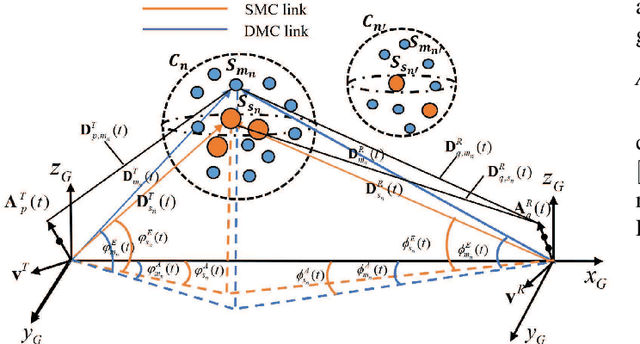
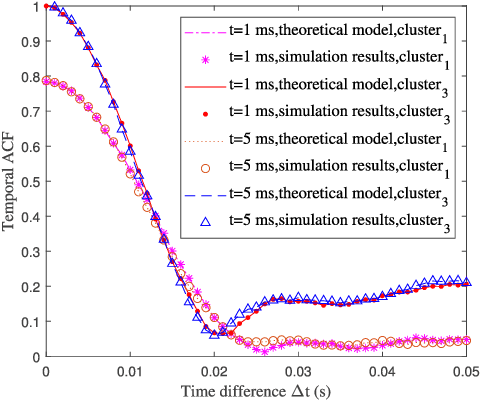
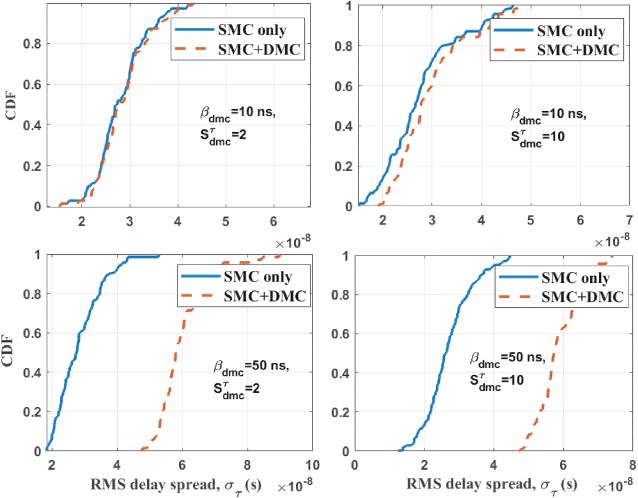
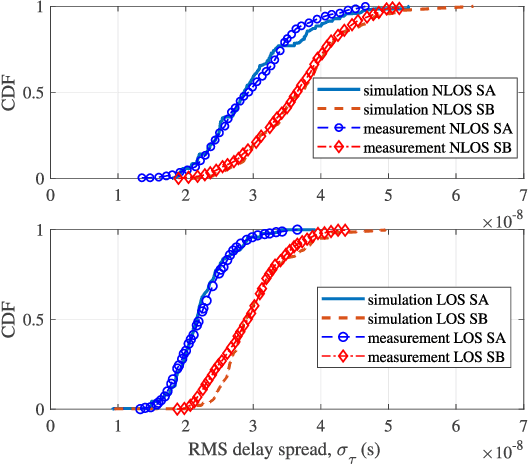
Industrial automation is one of the key application scenarios of the fifth (5G) wireless communication network. The high requirements of industrial communication systems for latency and reliability lead to the need for industrial channel models to support massive multiple-input multipleoutput (MIMO) and millimeter wave communication. In addition, due to the complex environment, huge communication equipment, and numerous metal scatterers, industrial channels have special rich dense multipath components (DMCs). Considering these characteristics, a novel three dimensional (3D) non-stationary geometry-based stochastic model (GBSM) for industrial automation wireless channel is proposed in this paper. Channel characteristics including the transfer function, time-varying space-time-frequency correlation function (STFCF), and root mean square (RMS) delay spread, model parameters including delay scaling factor and power decay factor are studied and analyzed. Besides, according to the indoor factory scenario classification of the 3rd Generation Partnership Project (3GPP) TR 38.901, two sub-scenarios considering the clutter density are simulated. Simulated cumulative distribution functions (CDFs) of RMS delay spread show a good consistency with the measurement data.
Research and application of time series algorithms in centralized purchasing data
Nov 01, 2019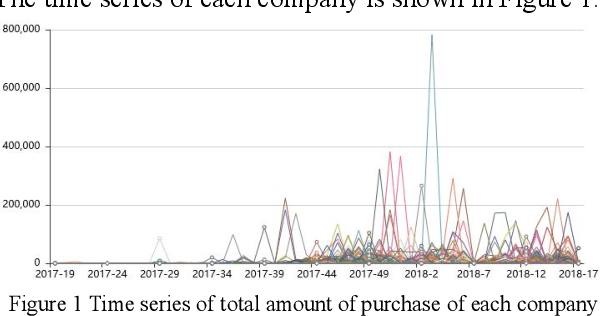
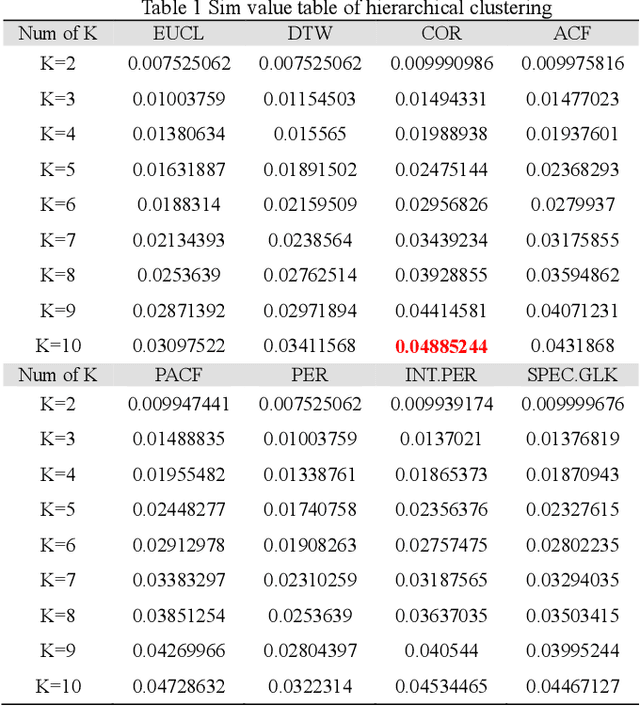
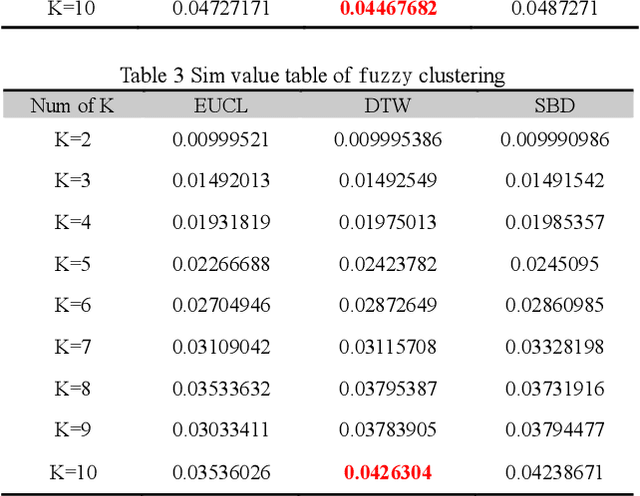
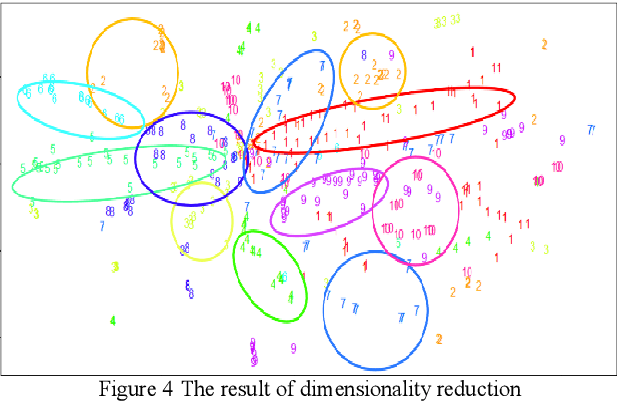
Based on the online transaction data of COSCO group's centralized procurement platform, this paper studies the clustering method of time series type data. The different methods of similarity calculation, different clustering methods with different K values are analysed, and the best clustering method suitable for centralized purchasing data is determined. The company list under the corresponding cluster is obtained. The time series motif discovery algorithm is used to model the centroid of each cluster. Through ARIMA method, we also made 12 periods of prediction for the centroid of each category. This paper constructs a matrix of "Customer Lifecycle Theory - Five Elements of Marketing ", and puts forward corresponding marketing suggestions for customers at different life cycle stages.
Method for making multi-attribute decisions in wargames by combining intuitionistic fuzzy numbers with reinforcement learning
Sep 06, 2021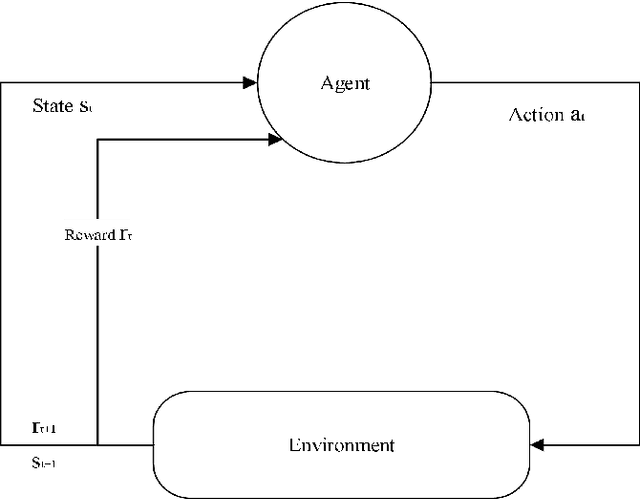
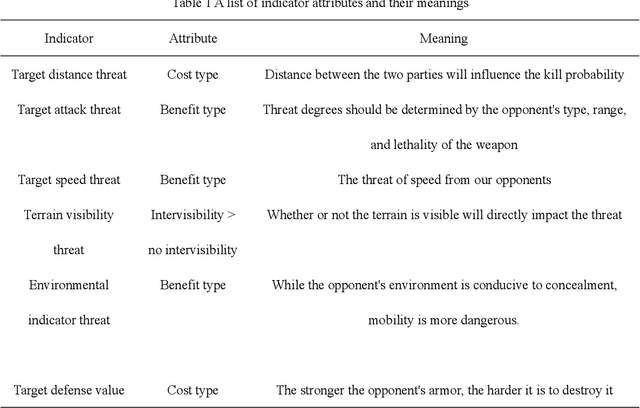

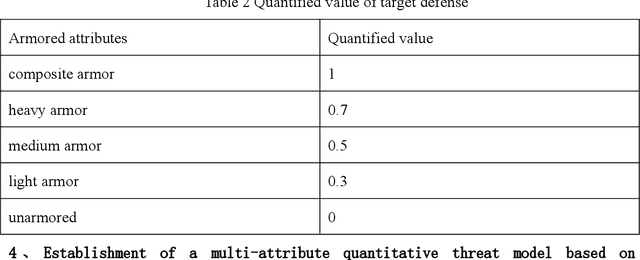
Researchers are increasingly focusing on intelligent games as a hot research area.The article proposes an algorithm that combines the multi-attribute management and reinforcement learning methods, and that combined their effect on wargaming, it solves the problem of the agent's low rate of winning against specific rules and its inability to quickly converge during intelligent wargame training.At the same time, this paper studied a multi-attribute decision making and reinforcement learning algorithm in a wargame simulation environment, and obtained data on red and blue conflict.Calculate the weight of each attribute based on the intuitionistic fuzzy number weight calculations. Then determine the threat posed by each opponent's chess pieces.Using the red side reinforcement learning reward function, the AC framework is trained on the reward function, and an algorithm combining multi-attribute decision-making with reinforcement learning is obtained. A simulation experiment confirms that the algorithm of multi-attribute decision-making combined with reinforcement learning presented in this paper is significantly more intelligent than the pure reinforcement learning algorithm.By resolving the shortcomings of the agent's neural network, coupled with sparse rewards in large-map combat games, this robust algorithm effectively reduces the difficulties of convergence. It is also the first time in this field that an algorithm design for intelligent wargaming combines multi-attribute decision making with reinforcement learning.Attempt interdisciplinary cross-innovation in the academic field, like designing intelligent wargames and improving reinforcement learning algorithms.
Diversified Sampling for Batched Bayesian Optimization with Determinantal Point Processes
Oct 22, 2021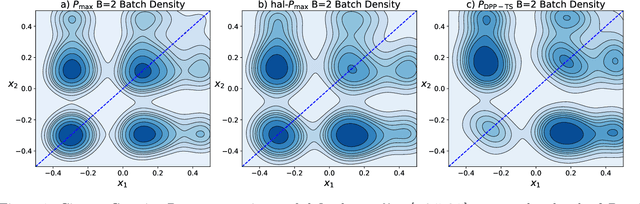
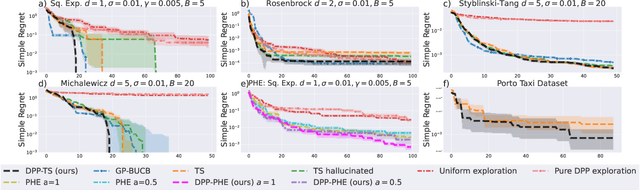
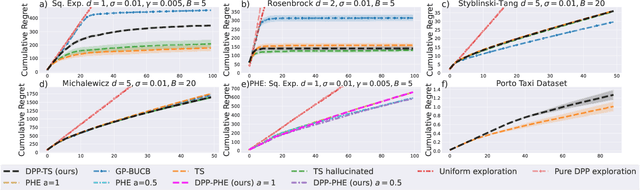
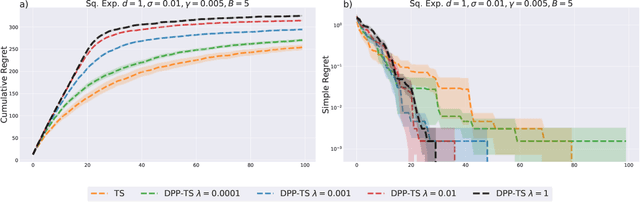
In Bayesian Optimization (BO) we study black-box function optimization with noisy point evaluations and Bayesian priors. Convergence of BO can be greatly sped up by batching, where multiple evaluations of the black-box function are performed in a single round. The main difficulty in this setting is to propose at the same time diverse and informative batches of evaluation points. In this work, we introduce DPP-Batch Bayesian Optimization (DPP-BBO), a universal framework for inducing batch diversity in sampling based BO by leveraging the repulsive properties of Determinantal Point Processes (DPP) to naturally diversify the batch sampling procedure. We illustrate this framework by formulating DPP-Thompson Sampling (DPP-TS) as a variant of the popular Thompson Sampling (TS) algorithm and introducing a Markov Chain Monte Carlo procedure to sample from it. We then prove novel Bayesian simple regret bounds for both classical batched TS as well as our counterpart DPP-TS, with the latter bound being tighter. Our real-world, as well as synthetic, experiments demonstrate improved performance of DPP-BBO over classical batching methods with Gaussian process and Cox process models.
Multivariate Time Series Forecasting Based on Causal Inference with Transfer Entropy and Graph Neural Network
May 03, 2020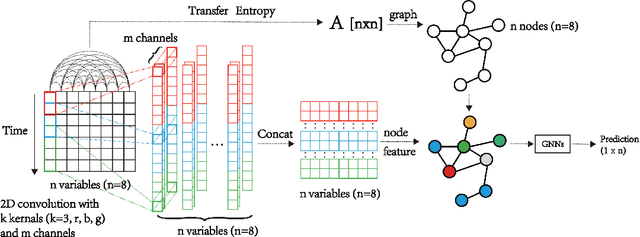
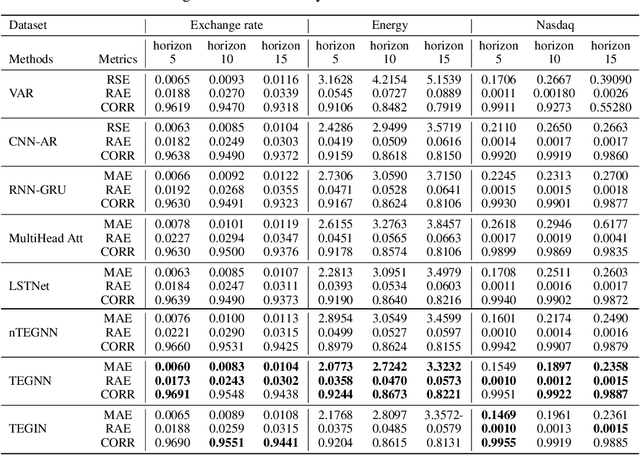
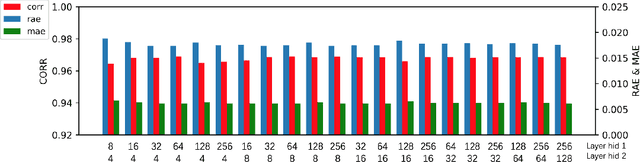
Multivariate time series (MTS) forecasting is an important problem in many fields. Accurate forecasting results can effectively help decision-making and reduce subjectivity. To date, many MTS forecasting methods have been proposed and widely applied. However, these methods assume that the value to be predicted of a single variable is related to all other variables, which makes it difficult to select the true key variable in high-dimensional situations. To address the above issue, a novel end-to-end deep learning model, termed transfer entropy graph neural network (TEGNN) is proposed in this paper. For accurate variable selection, the transfer entropy (TE) graph is introduced to characterize the causal information among variables, in which each variable is regarded as a graph node. In addition, convolutional neural network (CNN) filters with different perception scales are used for time series feature extraction. What is more, graph neural network (GNN) is adopted to tackle the embedding and forecasting problem of graph structure composed of MTS. MTS data collected from the real world are used to evaluate the prediction performance of TEGNN. Our comprehensive experiments demonstrate that the proposed TEGNN consistently outperforms state-of-the-art MTS forecasting baselines.
One Proxy Device Is Enough for Hardware-Aware Neural Architecture Search
Nov 01, 2021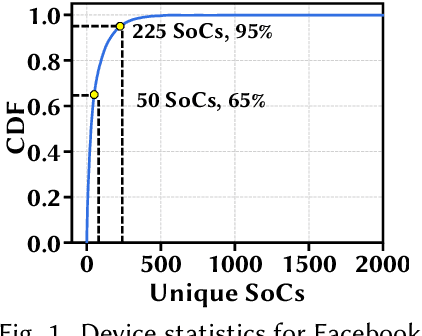
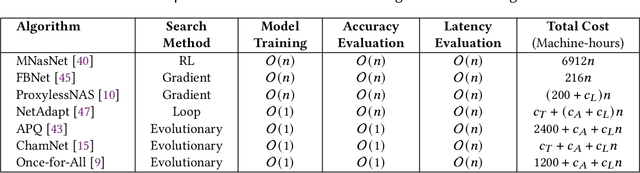
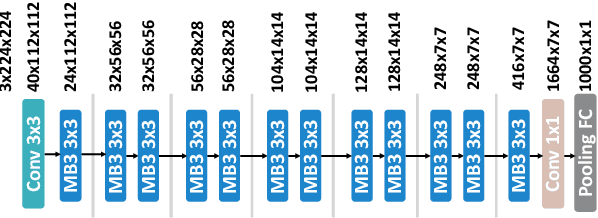

Convolutional neural networks (CNNs) are used in numerous real-world applications such as vision-based autonomous driving and video content analysis. To run CNN inference on various target devices, hardware-aware neural architecture search (NAS) is crucial. A key requirement of efficient hardware-aware NAS is the fast evaluation of inference latencies in order to rank different architectures. While building a latency predictor for each target device has been commonly used in state of the art, this is a very time-consuming process, lacking scalability in the presence of extremely diverse devices. In this work, we address the scalability challenge by exploiting latency monotonicity -- the architecture latency rankings on different devices are often correlated. When strong latency monotonicity exists, we can re-use architectures searched for one proxy device on new target devices, without losing optimality. In the absence of strong latency monotonicity, we propose an efficient proxy adaptation technique to significantly boost the latency monotonicity. Finally, we validate our approach and conduct experiments with devices of different platforms on multiple mainstream search spaces, including MobileNet-V2, MobileNet-V3, NAS-Bench-201, ProxylessNAS and FBNet. Our results highlight that, by using just one proxy device, we can find almost the same Pareto-optimal architectures as the existing per-device NAS, while avoiding the prohibitive cost of building a latency predictor for each device.
* Accepted by the ACM SIGMETRICS 2022. Published in the Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 5, no. 3, Article 34, December 2021
Cognitively Inspired Learning of Incremental Drifting Concepts
Oct 09, 2021
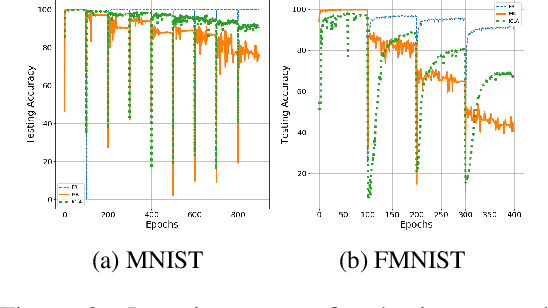
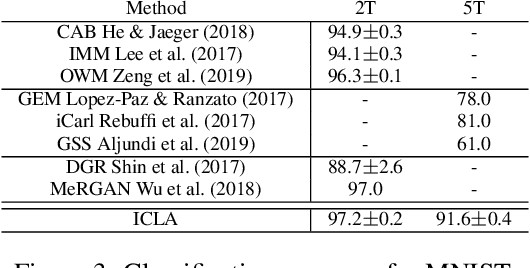
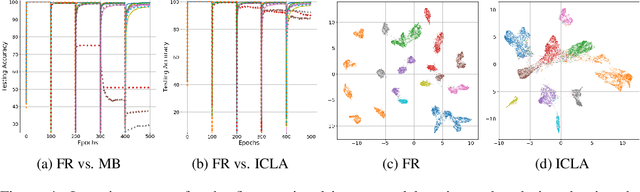
Humans continually expand their learned knowledge to new domains and learn new concepts without any interference with past learned experiences. In contrast, machine learning models perform poorly in a continual learning setting, where input data distribution changes over time. Inspired by the nervous system learning mechanisms, we develop a computational model that enables a deep neural network to learn new concepts and expand its learned knowledge to new domains incrementally in a continual learning setting. We rely on the Parallel Distributed Processing theory to encode abstract concepts in an embedding space in terms of a multimodal distribution. This embedding space is modeled by internal data representations in a hidden network layer. We also leverage the Complementary Learning Systems theory to equip the model with a memory mechanism to overcome catastrophic forgetting through implementing pseudo-rehearsal. Our model can generate pseudo-data points for experience replay and accumulate new experiences to past learned experiences without causing cross-task interference.
Customs Fraud Detection in the Presence of Concept Drift
Sep 29, 2021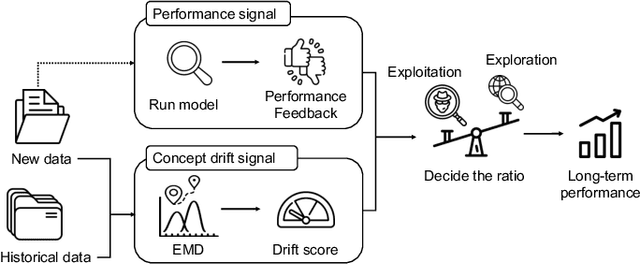
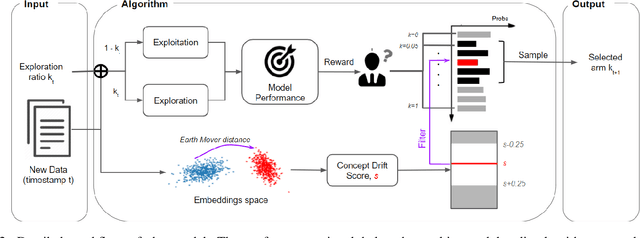
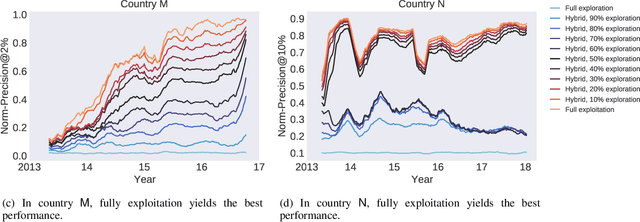
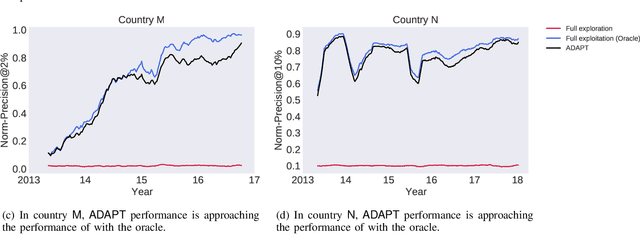
Capturing the changing trade pattern is critical in customs fraud detection. As new goods are imported and novel frauds arise, a drift-aware fraud detection system is needed to detect both known frauds and unknown frauds within a limited budget. The current paper proposes ADAPT, an adaptive selection method that controls the balance between exploitation and exploration strategies used for customs fraud detection. ADAPT makes use of the model performance trends and the amount of concept drift to determine the best exploration ratio at every time. Experiments on data from four countries over several years show that each country requires a different amount of exploration for maintaining its fraud detection system. We find the system with ADAPT can gradually adapt to the dataset and find the appropriate amount of exploration ratio with high performance.
(Almost) Free Incentivized Exploration from Decentralized Learning Agents
Oct 27, 2021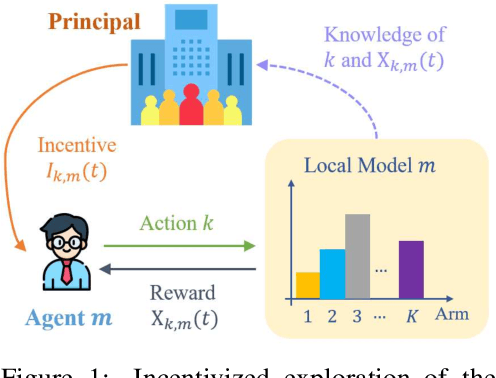

Incentivized exploration in multi-armed bandits (MAB) has witnessed increasing interests and many progresses in recent years, where a principal offers bonuses to agents to do explorations on her behalf. However, almost all existing studies are confined to temporary myopic agents. In this work, we break this barrier and study incentivized exploration with multiple and long-term strategic agents, who have more complicated behaviors that often appear in real-world applications. An important observation of this work is that strategic agents' intrinsic needs of learning benefit (instead of harming) the principal's explorations by providing "free pulls". Moreover, it turns out that increasing the population of agents significantly lowers the principal's burden of incentivizing. The key and somewhat surprising insight revealed from our results is that when there are sufficiently many learning agents involved, the exploration process of the principal can be (almost) free. Our main results are built upon three novel components which may be of independent interest: (1) a simple yet provably effective incentive-provision strategy; (2) a carefully crafted best arm identification algorithm for rewards aggregated under unequal confidences; (3) a high-probability finite-time lower bound of UCB algorithms. Experimental results are provided to complement the theoretical analysis.